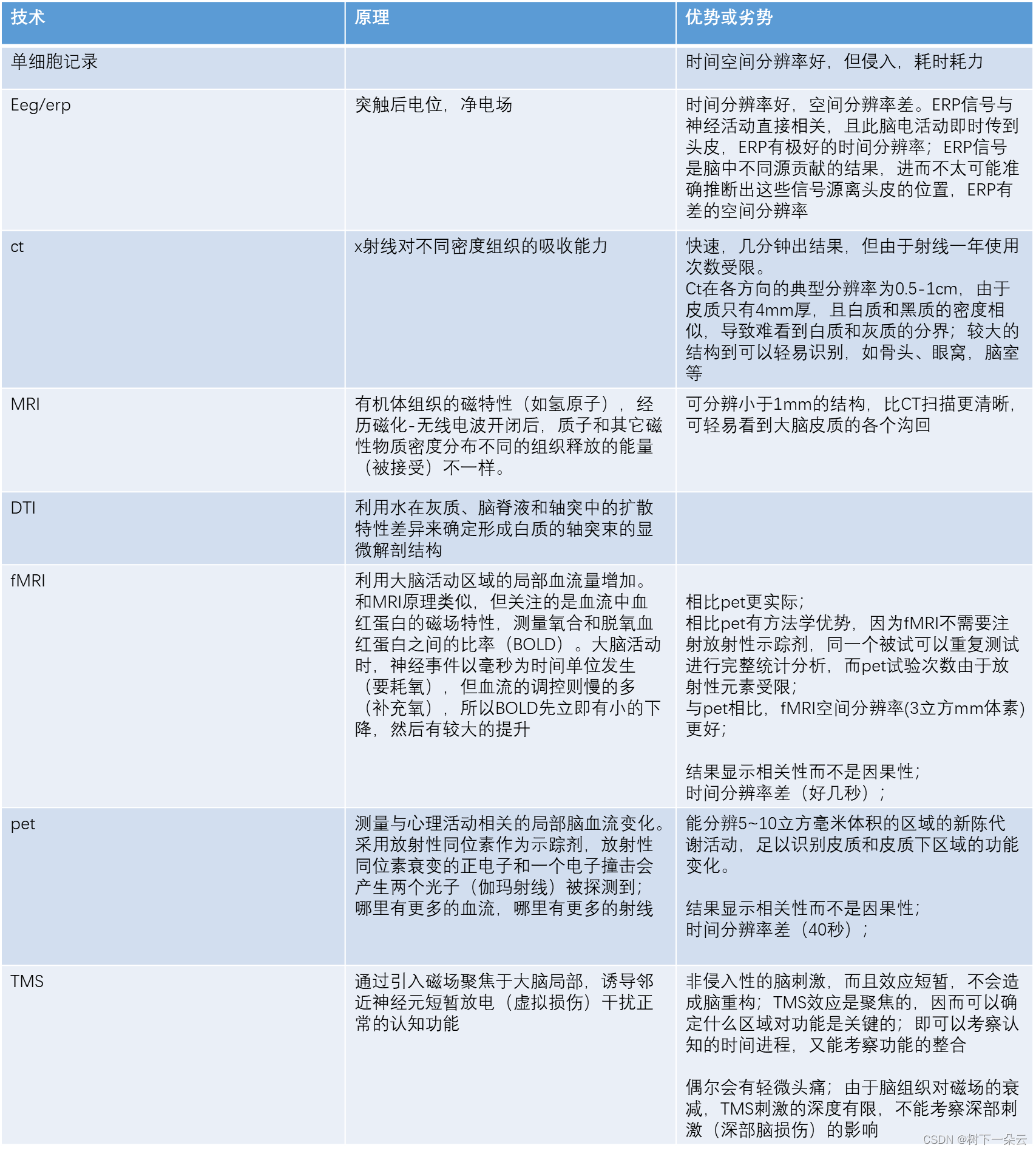
梯度下降
损失函数
绝大多数的机器学习模型都会有一个损失函数。比如常见的均方误差(Mean Squared Error)损失函数:
L ( w , b ) = 1 N ∑ i = 1 N ( y i − f ( w x i + b ) ) 2 L(w, b)=\frac{1}{N} \sum_{i=1}^{N}\left(y_{i}-f\left(w x_{i}+b\right)\right)^{2} L(w,b)=N1i=1∑N(yi−f(wxi+b))2
其中, 表示样本数据的实际目标值, 表示预测函数 根据样本数据 计算出的预测值。从几何意义上来说,它可以看成预测值和实际值的平均距离的平方。
损失函数用来衡量机器学习模型的精确度。一般来说,损失函数的值越小,模型的精确度就越高。如果要提高机器学习模型的精确度,就需要尽可能降低损失函数的值。而降低损失函数的值,我们一般采用梯度下降这个方法。所以,梯度下降的目的,就是为了最小化损失函数。
梯度下降的原理
1.确定一个小目标-预测函数

2.找到差距-代价函数
寻找损失函数的最低点,就像我们在山谷里行走,希望找到山谷里最低的地方。那么如何寻找损失函数的最低点呢?在这里,我们使用了微积分里导数,通过求出函数导数的值,从而找到函数下降的方向或者是最低点(极值点)。
损失函数里一般有两种参数,一种是控制输入信号量的权重(Weight, 简称 ),另一种是调整函数与真实值距离的偏差(Bias,简称 )。我们所要做的工作,就是通过梯度下降方法,不断地调整权重 w和偏差b,使得损失函数的值变得越来越小。
首先我们要量化数据的偏离程度(误差),例如均方误差
e 1 = ( y 1 − w ∗ x 1 ) 2 e 1 = ( w ∗ x 1 − y 1 ) 2 e 1 = w 2 ∗ x 1 2 − 2 ( w ∗ x 1 ∗ y 1 ) + y 1 2 e 1 = x 1 2 ∗ w 2 − 2 ( x 1 ∗ y 1 ) ∗ w + y 1 2 e_{1}=\left(y_{1}-w * x_{1}\right)^{2}\\e_{1}=\left(w * x_{1}-y_{1}\right)^{2}\\e_{1}=w^{2} * x_{1}^{2}-2\left(w * x_{1} * y_{1}\right)+y_{1}^{2}\\e_{1}=x_{1}^{2} * w^{2}-2\left(x_{1} * y_{1}\right) * w+y_{1}^{2} e1=(y1−w∗x1)2e1=(w∗x1−y1)2e1=w2∗x12−2(w∗x1∗y1)+y12e1=x12∗w2−2(x1∗y1)∗w+y12
我们的目标是求出所有点的误差的平均值
e 1 = x 1 2 ∗ w 2 − 2 ( x 1 ∗ y 1 ) ∗ w + y 1 2 e 2 = x 2 2 ∗ w 2 − 2 ( x 2 ∗ y 2 ) ∗ w + y 2 2 e 3 = x 3 2 ∗ w 2 − 2 ( x 3 ∗ y 3 ) ∗ w + y 3 2 ⋯ e n = x n 2 ∗ w 2 − 2 ( x n ∗ y n ) ∗ w + y n 2 e_{1}=x_{1}^{2} * w^{2}-2\left(x_{1} * y_{1}\right) * w+y_{1}^{2}\\e_{2}=x_{2}^{2} * w^{2}-2\left(x_{2} * y_{2}\right) * w+y_{2}^{2}\\e_{3}=x_{3}^{2} * w^{2}-2\left(x_{3} * y_{3}\right) * w+y_{3}^{2}\\\cdots\\e_{n}=x_{n}^{2} * w^{2}-2\left(x_{n} * y_{n}\right) * w+y_{n}^{2} e1=x12∗w2−2(x1∗y1)∗w+y12e2=x22∗w2−2(x2∗y2)∗w+y22e3=x32∗w2−2(x3∗y3)∗w+y32⋯en=xn2∗w2−2(xn∗yn)∗w+yn2
xy和样本数n都是已知的
e = 1 n ( ( x 1 2 + … + x n 2 ) ∗ w 2 + ( − 2 ∗ x 1 ∗ y 1 − … − 2 ∗ x n ∗ y n ) ∗ w + ( y 1 2 + … + y n 2 ) ) e=\frac{1}{n}\left(\left(x_{1}^{2}+\ldots+x_{n}^{2}\right) * w^{2}+\left(-2 * x_{1} * y_{1}-\ldots-2 * x_{n} * y_{n}\right) * w+\left(y_{1}^{2}+\ldots+y_{n}^{2}\right)\right) e=n1((x12+…+xn2)∗w2+(−2∗x1∗y1−…−2∗xn∗yn)∗w+(y12+…+yn2))
e = 1 n ( a ∗ w 2 + b ∗ w + c ) e=\frac{1}{n}\left(a * w^{2}+b * w+c\right) e=n1(a∗w2+b∗w+c)
这个误差函数表示学习所需要的代价,被称为代价函数

3.明确搜索方向-梯度计算
机器学习的目标就是拟合出最接近训练分布的直线,也就是找到使得误差代价最小的参数

对应在代价函数图像上就是他的最低点,寻找最低点的过程就是梯度下降的过程
在陡峭程序最大的方向走就能最快下降,这个陡峭程度就是梯度

4.学习率
这里我们用到学习率(Learning Rate) 这个概念。通过学习率,可以计算前进的距离(步长)。
我们用 表示权重的初始值, 表示更新后的权重值,用 表示学习率,则有:
w i + 1 = w i − α ∗ d L d w i w_{i+1}=w_{i}-\alpha * \frac{d L}{d w_{i}} wi+1=wi−α∗dwidL
通过学习调整权重的方式就是新w等于旧w减去斜率乘以学习率

如果学习率 设置得过大,有可能我们会错过损失函数的最小值;如果设置得过小,可能我们要迭代非常多次才能找到最小值,会耗费较多的时间。因此,在实际应用中,我们需要为学习率 设置一个合适的值。
5.循环迭代
总结:以下就是整个过程

再简单介绍一些梯度下降:
预测函数是y=wx+b,则代价函数就变成了误差e关于两个参数w和b的曲面

代价函数还可能是个波浪线,当有多个最小点存在时,机器学习的目标将是找到最低的那个也就是全局最优而不是局部最优

代价函数也可能是个起伏不定的曲面又或者是某种无法中三维图像描述的更复杂函数。代价函数将变成十维或是百维,将很难可视化地展现出来。
但无论有多少维度都可以用梯度下降法来寻找误差最小的点
梯度下降法的三种变体
1.批量梯度下降法(BGD)

他的下降过程就像上图,左侧是样本点,右侧是用等高线表示的代价函数曲面,他的运算是用全部训练样本参与运算,梯度下降十分平稳,是最原始的形式
-
优点:保证算法的精准度,找到全局最优解
-
缺点:让训练搜索过程变得很慢
2.随机梯度下降法(SGD)
下降过程十分随性,每下降一步只需要用一个样本进行计算

他的下降过程非常不平稳
-
优点:提升了计算的速度
-
缺点:牺牲了一定的精准度
3.小批量梯度下降(MBGD)
每下降一步,选用一小批样本进行计算

他的下降没有BGD的平稳有规律,但是快了很多
没有SGD速度快,但是准确了很多
梯度下降法存在的问题: 除了效率很低的BGD,无法保证找到全局最低点,很可能陷入局部最优点
有一些更加优化的算法:
AdaGrad一动态学习率:
经常更新的参数学习率就小一些,不常更新的学习率大一些,这种方法的问题就是频繁更新的学习率可能会过小,以至于逐渐消失
然后就提出了RMSProp-优化动态学习率、AfaDelta-无需设置学习率、Adam-融合AdaGrad和RMSProp、Momentum-模拟动量
伪代码表示梯度下降
用伪代码把梯度下降的过程表现出来,可以写成下面的样子:
def train(X, y, W, B, alpha, max_iters):
'‘’
选取所有的数据作为训练样本来执行梯度下降
X : 训练数据集
y : 训练数据集所对应的目标值
W : 权重向量
B : 偏差变量
alpha : 学习速率
max_iters : 梯度下降过程最大的迭代次数
'''
dW = 0 # 初始化权重向量的梯度累加器
dB = 0 # 初始化偏差向量的梯度累加器
m = X.shape[0] # 训练数据的数量
# 开始梯度下降的迭代
for i in range(max_iters):
dW = 0 # 重新设置权重向量的梯度累加器
dB = 0 # 重新设置偏差向量的梯度累加器
# 对所有的训练数据进行遍历
for j in range(m):
# 1. 遍历所有的训练数据
# 2. 计算每个训练数据的权重向量梯度w_grad和偏差向量梯度b_grad
# 3. 把w_grad和b_grad的值分别累加到dW和dB两个累加器里
W = W - alpha * (dW / m) # 更新权重的值
B = B - alpha * (dB / m) # 更新偏差的值
return W, B # 返回更新后的权重和偏差。
![[附源码]计算机毕业设计JAVA驾校管理系统](https://img-blog.csdnimg.cn/d1cae1f4aaaf4c9396a65770240f81fd.png)