最近有个数据归集的需求用到了多数据源,在业务库保存后同时向归集库插入或数据。之前好像还没做过这块的东西,简单记录下防止下次又忘记了~
踩过的几个坑都是某些知识点不熟悉导致的,而且都是框架配置相关的..
先上代码,再扯淡
两个库都是mysql,不同数据库应该就是配置不一样,使用的druid数据库连接池
一、修改properties配置文件中的数据库信息
#jdbc configure
connection.url=${db.url}
connection.username=${db.username}
connection.password=${db.password}
connection.driver=${connection.driver_class}
#删掉此配置 退回单数据源
connection.url2=${tradding.db.url2}
connection.username2=${tradding.db.username2}
connection.password2=${tradding.db.password2}
connection.driver2=${connection.driver_class2}二、创建@DataSourceAnnotation 注解使用于aop进行数据源的切换
package cn.xxx.datasource;
import java.lang.annotation.*;
/**
* @author zj
* @creatTime 2022-11-22
* @description
*/
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataSourceAnnotation {
String value();
String primary = "primary";
String secend= "secend";
}
三、创建动态数据源DynamicDataSource继承AbstractRoutingDataSource
package cn.xxx.datasource;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* @author zj
* @creatTime 2022-11-18
* @description 配置多个数据源
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
* 数据源标识,保存在线程变量中,避免多线程操作数据源时互相干扰
*/
private static final ThreadLocal<String> key = new ThreadLocal<String>();
@Override
protected Object determineCurrentLookupKey() {
return key.get();
}
/**
* 设置数据源
*
* @param dataSource 数据源名称
*/
public static void setDataSource(String dataSource) {
key.set(dataSource);
}
/**
* 获取数据源
*
* @return
*/
public static String getDatasource() {
return key.get();
}
/**
* 清除数据源
*/
public static void clearDataSource() {
key.remove();
}
}
四、创建一个aop切面作用于目标方法上
package cn.xxx.datasource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.aop.AfterReturningAdvice;
import org.springframework.aop.MethodBeforeAdvice;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
/**
* @author zj
* @creatTime 2022-11-22
* @description
*/
@Component
public class DynamicDataSourceAspect implements MethodBeforeAdvice, AfterReturningAdvice {
Logger log = LoggerFactory.getLogger(DynamicDataSourceAspect.class);
@Override
public void afterReturning(Object o, Method method, Object[] objects, Object o1) throws Throwable {
//这里做一个判断,有使用DataSourceAnnotation注解时才关闭数据源,有一个主要的数据源,就没有必要每次都去关闭
if (method.isAnnotationPresent(DataSourceAnnotation.class)) {
DynamicDataSource.clearDataSource();
log.debug("数据源已关闭");
}
}
/**
* 拦截目标方法,获取由@DataSourceAnnotation指定的数据源标识,设置到线程存储中以便切换数据源
*/
@Override
public void before(Method method, Object[] objects, Object o) throws Throwable {
if (method.isAnnotationPresent(DataSourceAnnotation.class)) {
DataSourceAnnotation dataSourceAnnotation = method.getAnnotation(DataSourceAnnotation.class);
DynamicDataSource.setDataSource(dataSourceAnnotation.value());
log.debug("数据源切换为:" + DynamicDataSource.getDatasource());
}
}
}
五、spring-config.xml配置多数据源
<!-- 数据源1 -->
<bean id="dataSourcePrimary" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${connection.url}"/>
<property name="username" value="${connection.username}"/>
<property name="password" value="${connection.password}"/>
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${druid.initialSize}"/>
<property name="minIdle" value="${druid.minIdle}"/>
<property name="maxActive" value="${druid.maxActive}"/>
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${druid.maxWait}"/>
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${druid.validationQuery}" />
<property name="testWhileIdle" value="${druid.testWhileIdle}" />
<property name="testOnBorrow" value="${druid.testOnBorrow}" />
<property name="testOnReturn" value="${druid.testOnReturn}" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="${druid.filters}" />
</bean>
<!-- 数据源2 -->
<bean id="dataSourceSecend" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${connection.url2}"/>
<property name="username" value="${connection.username2}"/>
<property name="password" value="${connection.password2}"/>
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${druid.initialSize}"/>
<property name="minIdle" value="${druid.minIdle}"/>
<property name="maxActive" value="${druid.maxActive}"/>
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${druid.maxWait}"/>
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${druid.validationQuery}" />
<property name="testWhileIdle" value="${druid.testWhileIdle}" />
<property name="testOnBorrow" value="${druid.testOnBorrow}" />
<property name="testOnReturn" value="${druid.testOnReturn}" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="${druid.filters}" />
</bean>
<!-- 动态数据源配置 如果之前没有这块那这个id直接用原数据源的名称,然后把原来数据源重命名,这样有些配置就不会漏改。。-->
<bean id="dataSource" class="cn.pinming.datasource.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- 主库-1 -->
<entry key="primary" value-ref="dataSourcePrimary"/>
<!-- 副库-2 -->
<entry key="secend" value-ref="dataSourceSecend"/>
</map>
</property>
<!--默认数据源-->
<property name="defaultTargetDataSource" ref="dataSourcePrimary"/>
</bean>六、配置事务和AOP
<!--事务管理器配置-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="doReweight" propagation="REQUIRES_NEW"/>
<tx:method name="doClear*" propagation="REQUIRES_NEW"/>
<tx:method name="doSend*" propagation="REQUIRES_NEW"/>
<tx:method name="doBatchSave*" propagation="REQUIRES_NEW"/>
<tx:method name="time*" propagation="REQUIRES_NEW"/>
<!--hibernate4必须配置为开启事务 否则 getCurrentSession()获取不到-->
<tx:method name="get*" propagation="REQUIRED" read-only="true"/>
<tx:method name="count*" propagation="REQUIRED" read-only="true"/>
<tx:method name="find*" propagation="REQUIRED" read-only="true"/>
<tx:method name="search*" propagation="REQUIRED" read-only="true"/>
<tx:method name="select*" propagation="REQUIRED" read-only="true"/>
<tx:method name="package*" propagation="REQUIRED" read-only="true"/>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<bean id="dynamicDataSourceAspect" class="cn.pinming.datasource.DynamicDataSourceAspect">
</bean>
<!--设置切面 com.test.service.*.impl.*()-->
<aop:config proxy-target-class="true">
<aop:pointcut id="myPointcut" expression="execution(* cn.xxx.test.service.TestSourceService.*(..))"/>
<aop:advisor advice-ref="dynamicDataSourceAspect" pointcut-ref="myPointcut" order="1"/>
<!--把事务控制在Service层-->
<aop:advisor advice-ref="txAdvice" pointcut-ref="myPointcut" order="2"/>
</aop:config>这里需要注意的是order值越小,优先级越高,所以切换数据源order的值要比事务切面的值小,否则会出现数据源切换失败!
七、切换数据源,实际使用
在需要切换为非默认数据的方法上加@DataSourceAnnotation(DataSourceAnnotation.secend)就可以完成数据源的切换了。
controller层:
/**
* @author zj
* @creatTime 2022-11-18
* @description
*/
@Controller
public class TestController {
@Autowired
private TPProjectMapper projectMapper;
@Autowired
private TestSourceService testSourceService;
@RequestMapping("/ocx/saveOrUpdateTest")
@ResponseBody
public Result saveOrUpdateTest(){
Result result = new Result();
//先测试插入 监督库
TPProject project = new TPProject();
project.setProjectId(111221212L);
project.setProjectName("test测试多数据源——监督库");
ContextFacade.initEntity(project);
projectMapper.insert(project);
//再测试插入 交易库
testSourceService.saveOrUpdateTest();
//再测试修改 监督库
TPProject project1 = projectMapper.selectByPrimaryKey(111221212L);
project1.setProjectId(111221212L);
project1.setProjectName("test测试多数据源——监督库__二次修改结果");
projectMapper.updateByPrimaryKey(project1);
return result;
}
}service层:
package cn.xxx.test.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author zj
* @creatTime 2022-11-18
* @description
*/
@Service
public class TestSourceService {
@Autowired
private TPProjectMapper tpProjectMapper;
@DataSourceAnnotation(DataSourceAnnotation.secend)
public Result saveOrUpdateTest(){
Result result = new Result();
TPProject project = new TPProject();
project.setProjectId(111221213L);
project.setProjectName("test测试多数据源——交易库");
ContextFacade.initEntity(project);
tpProjectMapper.insert(project);
return result;
}
}
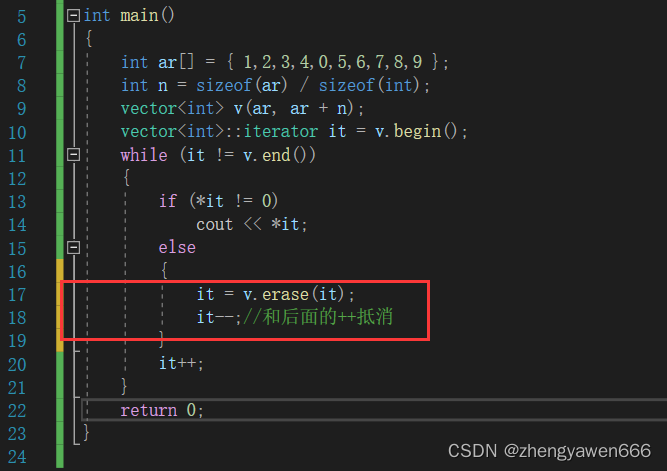
八、结果
主库:

副库:

这里为了方便用了同一个表,只是不同数据库,所以mapper和sql也一样的,实际根据需求来就行。
九、Other
1、SpringAOP切面类不运行的问题 ,注意配置写在spring-config.xml而不是spring-mvc.xml中。
2、aop:pointcut的配置说明
<aop:pointcut expression="execution(* com.aop.service..*(..))"
其中expression="execution(* com.aop.service..*(..))"的配置规则如下:
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern?name-pattern(param-pattern) throws-pattern?)
execution(方法的操作权限 返回值类型模式 方法所在的包 方法名 (参数名) 异常)
参数名(参数模式)稍微复杂一些:
() 匹配不带参数的方法,
(..) 匹配任何数量(零个或多个)参数。
(*) 模式匹配采用任何类型的一个参数的方法
(*,String) 匹配一个带有两个参数的方法。第一个可以是任何类型,而第二个必须是String
返回值,方法名,参数名,必须有,其他可选
执行任何公共方法:
execution(public * *(..))
执行名称以以下开头的任何方法set:
execution(* set*(..))
执行AccountService接口定义的任何方法:
execution(* com.xyz.service.AccountService.*(..))
执行service包中定义的任何方法:
execution(* com.xyz.service.*.*(..))
执行服务包或其子包中定义的任何方法:
execution(* com.xyz.service..*.*(..))