SPARKSQL-源码剖析全流程导读
一、处理流程
spark从一条sql语句一步一步转换成物理执行结果,这中间需要经历几个阶段,如下图:
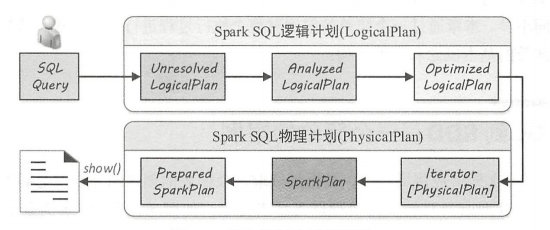
二、各阶段概述
1、Unresolved-未解析阶段
此阶段主要做了两件事:
1、将sql字符串通过antrl4转化成AST逻辑语法树
2、将AST语法树经过spark自定义访问者模式转化成logicalPlan【可以理解为精简版语法树】
该阶段语法树中仅仅是数据结构,不包含任何数据信息
2、Analyzed-分析阶段
此阶段会将上一阶段获得的逻辑语法树和元数据进行绑定,构建出更包含元数据的逻辑语法树
如果是hivesql,则此阶段会和hive-catalog进行交互
3、Optimized-优化阶段
此阶段是对分析阶段的逻辑计划做进一步优化,将应用各种优化规则对一些低效的逻辑计划进行转换
例如将原本用户不合理的sql进行优化,如谓词下推,列裁剪,子查询共用等。
4、PhysicalPlan-物理计划阶段
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树,物理算子树的节点会直接生成 RDD 或对 RDD 进行 transformation 操作;
5、Cost-Model-策略选取阶段
Cost Model 对应的就是基于代价的优化(Cost-based Optimizations,CBO,详见 SPARK-16026 ),核心思想是计算每个物理计划的代价,然后得到最优的物理计划。但是截止到spark3.0,这一部分并没有实现
5、Prepared-预提交阶段
此节点是提交前的优化,内部是同的规则作用在sparkPlan物理树,从而获得优化后的可执行的物理树
其中有个重头戏,就是spark3.0中新增功能AQE【自适应执行】,SPARK-9850 在 Spark 中提出了自适应执行的基本思想,关于功能实现不在这里过多陈述,可查看相关文献;由此可以看出AQE功能目前只能通过sparksql才能使用