具体业务场景方案分析
问题背景:

虽然强制走写库,避免了主从延迟带来的读库数据不一致问题,但是增加了写库的QPS,带来了巨大压力,所以通过限流来保护db,但这样会降低QPS。
业务上暂时不清楚,所以现在从技术层面讨论读库能分担压力的可行方案。
结论:
改走读库,但是
采用降低主从延迟 来尽量保证读的数据为最新
并使用 redis缓存标记法 ,来识别 是否走写库
问题分析:
走读库,无法避免的是数据不一致问题,对于这个问题,可以从两个方面并行解决:
具体方案选型参考下文
1.降低主从延迟
主从延迟降的越低,读的时候越不容易读不到最新数据。
降低的方案在下文详细介绍,具体方案分析需要结合业务来分析梳理,这里先不重要讨论
2.走从库,但兜底主库逻辑——即redis缓存标记法
这里重点讨论这个。
这个时候我们主要解决的问题是两个:
- 缓存 与写库db 数据一致性的问题
- 缓存的数据 与 读库db 的数据哪个是最新的判断问题
redis缓存标记法具体方案分析:
步骤:
写操作 :写redis、更新master
读操作:读redis,读slave
方案:
Aredis上记录标记格式(key=业务代号:数据库:表:主键ID; value = 过期时间)过期时间:预估的主库和从库同步延迟的时间
Bredis上记录标记格式(key=业务代号:数据库:表:主键ID; value = 更新时间)
Credis上记录标记格式(key=业务代号:数据库:表:主键ID; value = 自增ID)
方案A
由于过期时间:预估的主库和从库同步延迟的时间,这个无法准确预估,而现在我们是希望能准确判断读到的数据是否是延迟,因此不考虑。
方案B

对于方案B,我们在redis记录的是这条数据最新更新的时间Tredis_up,而数据库中数据更新的时候会生成数据更新的时间,那么通过比对slave 查出的 数据更新 Tslave_up
之间的大小,就可以判断 是否需要再走写库。
但这里有两个问题,先写redis,还是先写mysql,下面分别分析
B1 先写redis,后写mysql
具体操作:写redis的时候java生成当前的时间Tredis_up写进redis ,然后再更新数据库,这个时候数据库中的更新时间得用Tredis_up
分析:此操作可以保证redis中记录的就是最新的数据,防止写入redis失败的情况。
希望通过Tredis_u==Tslave_up来判断是否延迟,
即认为Tredis_u==Tslave_up代表没有延迟
数据一致性问题:此时其实无法通过判断Tslave_up ==Tredis_u来判断是否有延迟,是否需要走写库,
因为Tslave_up==Tredis_up 时候,可能是延迟(比如高并发场景,Tredis_up值和master数据库中的最新值不一样),也可能没有延迟(理想情况)
B2先写mysql,后写redis
具体操作:先更新数据库,再写redis的时候用这条数据的更新时间
分析:此操作不可以保证redis中记录的就是最新的数据,不能避免写入redis失败的情况。
希望通过Tredis_u==Tslave_up来判断是否延迟,
即认为Tredis_u==Tslave_up代表没有延迟
数据一致性问题:此时其实无法通过判断Tslave_up == Tredis_u来判断是否有延迟,是否需要走写库,
因为 Tslave_up==Tredis_up 时候,可能是延迟(比如redis更新晚了,或者更新失败),也可能没有延迟(理想情况)
方案C
以上方案的问题在于:
无法保证db,缓存数据一致性(就不用谈redis数据和slave数据的比较)
那么就有了方案C,可以设置value的值为自增版本号:versionId,同时存到这数据的字段中,那么就可以比对slave中的versionId和redis中的versionId是否相等即可。

写库具体操作:
1.先通过redis为这条数据生成一个自增字段versionId,并存下来
2.更新db数据,并写入versionId
3.比较新的versionId是否 大于原有的versionId——解决线程不安全问题、并发问题
4.如果新的versionId大于原有的versionId,那就顺利更新,否则重新在redis中生成版本号versionId,并更新
读库:
1.读slave
2.读redis
3.比较versionId:相等ok;不相等就再走写库
tip:这里需要注意一点的是我们的value不能是时间,而应该是redis生成的一个分布式自增Id
这样既解决redis与db数据一致性问题,也可以保证redis中value的值 与 读库db 的数据哪个是最新的判断问题。
问题保障:
1.redis生成分布式自增id——保证分布式环境下id不冲突
2.redis的单线程——保证单机高并发下线程安全
3.自增id——保证redis保存最新id
带来的问题:
1.由于引入了redis,所以吞吐量会降低一点,——但是考虑到大流量场景下,从库分担压力 带来效益会高于 redis引入带来的负面影响
其他待优化:~~~~~~~~~~~
综上,方案C可行,可以保证缓存,db一致性,且缓存的数据为最新的。因为版本号递增。
——————————————————————————————
主从延迟问题
在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
这里补充实际延迟情况:比如多少QPS~延迟多久
1)、MySQL数据库主从同步延迟原理mysql主从同步原理:主库针对写操作,顺序写binlog,从库单线程去主库顺序读”写操作的binlog”,从库取到binlog在本地原样执行(随机写),来保证主从数据逻辑上一致。mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。有朋友会问:“主库上那个相同的DDL也需要执行10分,为什么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。
2)、MySQL数据库主从同步延迟是怎么产生的?当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。首要原因:数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高次要原因:读写binlog带来的性能影响,网络传输延迟。
延迟的原因:
1、内存配置过小或者 iops 配置(这个指的是 io capacity,sas 盘和 ssd 盘配置有区别)不当。
2、主库 TPS 过高,主库写入频繁,从库压力跟不上导致延时
产生的DDL数量超过slave一个sql线程所能承受的范围
4、主库执行大事务导致延迟
比如在主库执行一个大的 update、delete、insert … select 的事务操作,产生大量的 binlog 传送到只读节点,只读节点需要花费与主库相同的时间来完成该事务操作,进而导致了只读节点的延迟。
解决方法:
拆分大事务:增加缓存,异步写入数据库,减少直接对db的大量写入,减少大事务
5.与slave的大型query语句产生了锁等待
数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高次要原因:读写binlog带来的性能影响,网络传输延迟。
6、其它情况,如对无主键表的删除。
用户在删除数据的时候,由于表主键的缺少,同时删除条件没有索引,或者删除的条件过滤性极差,导致 slave 出现 hang 住,会严重的影响生产环境的稳定性。
只读实例出现延迟后的排查思路
- 看只读节点 IOPS 定位是否存在资源瓶颈
- 看只读节点的 binlog 增长量定位是否存在大事务
- 看只读节点的 comdml 性能指标,对比主节点的 comdml 定位是否是主库写入压力过高导致
- 看只读节点 show full processlist,判断是否有 Waiting for table metadata lock 和 alter,repair,create 等 ddl 操作。
主从延迟的解决方案:
1)、架构方面
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
4.不同业务的mysql物理上放在不同机器,分散压力。
5.使用比主库更好的硬件设备作为slave总结,mysql压力小,延迟自然会变小。
2)、硬件方面
1.采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
2.存储用ssd或者盘阵或者san,提升随机写的性能。
3.主从间保证处在同一个交换机下面,并且是万兆环境。
总结,硬件强劲,延迟自然会变小。一句话,缩小延迟的解决方案就是花钱和花时间。
3)、数据库自身特性
1、sync_binlog在slave端设置为0
2、–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
3、直接禁用slave端的binlog
4、slave端,如果使用的存储引擎是innodb,innodb_flush_log_at_trx_commit =2
1、sync_binlog=1 oMySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
如果sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的情况下,系统才有可能丢失1个事务的数据。但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。虽然可以通过group commit的补丁缓解,但是刷新的频率过高对IO的影响也非常大。
对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是2或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。默认情况下,并不是每次写入时都将binlog与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能binlog中最后的语句丢失了。要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使binlog在每N次binlog写入后与硬盘同步。即使sync_binlog设置为1,出现崩溃时,也有可能表内容和binlog内容之间存在不一致性。
2、innodb_flush_log_at_trx_commit (这个很管用)抱怨Innodb比MyISAM慢 100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据。
5.设置主从同步方式为半同步(得至少一个slave响应) & 并行复制(多线程拉binlog)
缺点:写请求的时延将会增加,吞吐量将会降低,但因为是半同步,不是全同步,所以可以衡量一下影响
4)应用层面
1.大事务拆分成为小事务进行批量提交,这样只读节点就可以迅速的完成事务的执行,不会造成数据的延迟
2.分库分表降低数据库压力
3.mysql中的sql优化、锁优化、事务隔离级别优化,降低压力
读写分离数据不一致解决方案:
A降低主从延时方案

B延时无法改变时的方案:
1.避免插入后就马上读。
插入数据时立马查询可能查不到,重写代码。
2.业务能够接受可以不解决 ,sleep几毫秒再查
3.选择性强制读主
对于需要强一致的场景,我们可以将其的读请求都操作主库
4.借助redis 缓存标记法
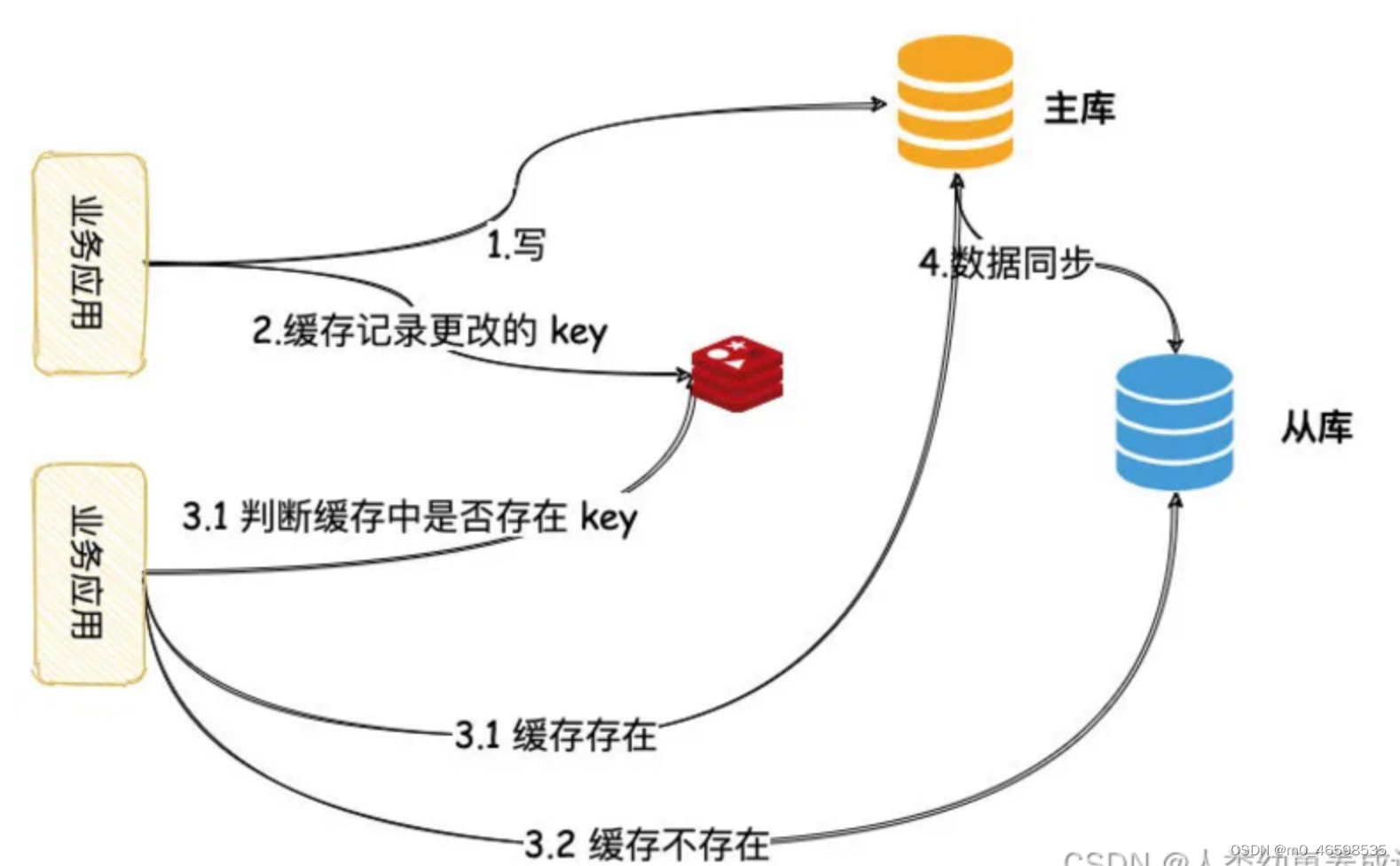
1)A发起写请求,更新了主库,但在缓存中设置一个标记,代表此数据已经更新,标记格式(业务代号:数据库:表:主键ID)根据自己业务场景。
2)设置此标记,要加上过期时间,可以为预估的主库和从库同步延迟的时间
3)B发起读请求的时候,先判断此请求的业务在缓存中有没有更新标记
4)如果存在标记,走主库;如果没有走从库。
5.本地缓存标记
1)用户A发起写请求,更新了主库,并在客户端设置标记,过期时间,如:cookies
2)用户A再发起读请求时,带上这个本地标记在后端
3)后端在处理请求时,获取请求传过来的数据,看有没有这个标记(如:cookies)
4)有这个业务标记,走主库;没有走从库。
这个方案就保证了用户A的读请求肯定是数据一致的,而且没有性能问题,因为标记是本地客户端传过去的。
但其他用户在本地客户端是没有这个标记的,他们走的就是从库了。那其他用户不就看不到这个数据了吗?说的对,其他用户是看不到,但看不到的时间很短,过个1~10秒就能够看到。
但这个方案解决了当前用户的数据一致性的问题,如上面举的例子,写文章,然后到文章列表,本用户是能够看到的。其他用户暂时看不到是没有关系的。
![[附源码]java毕业设计校园新闻管理系统](https://img-blog.csdnimg.cn/a3b3b8a6ea434b0bb354d8be13c193f2.png)





![P8842 [传智杯 #4 初赛] 小卡与质数2 垃圾筛](https://img-blog.csdnimg.cn/e7422edde9ef4442990c9a9854218771.png)