SpringCloud Alibaba全集文章目录:
零、手把手教你搭建SpringCloudAlibaba项目
一、手把手教你搭建SpringCloud Alibaba之生产者与消费者
二、手把手教你搭建SpringCloudAlibaba之Nacos服务注册中心
三、手把手教你搭建SpringCloudAlibaba之Nacos服务配置中心
四、手把手教你搭建SpringCloudAlibaba之Nacos服务集群配置
五、手把手教你搭建SpringCloudAlibaba之Nacos服务持久化配置
六、手把手教你搭建SpringCloudAlibaba之Sentinel实现流量实时监控
七、手把手教你搭建SpringCloudAlibaba之Sentinel实现流量控制
八、手把手教你搭建SpringCloudAlibaba之Sentinel服务降级之慢调用
九、手把手教你搭建SpringCloudAlibaba之Sentinel热点key限流
十、手把手教你搭建SpringCloudAlibaba之Sentinel系统保护规则
十一、手把手教你搭建SpringCloudAlibaba之Sentinel服务熔断
十二、手把手教你搭建SpringCloudAlibaba之Sentinel规则持久化
十三、手把手教你搭建SpringCloudAlibaba之Seata分布式事务
点击跳转学习 -------------->手把手教你搭建SpringCloud项目
熔断降级
概述 (来自官网)
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用别的模块,可能是另外的一个远程服务、数据库,或者第三方 API 等。例如,支付的时候,可能需要远程调用银联提供的 API;查询某个商品的价格,可能需要进行数据库查询。然而,这个被依赖服务的稳定性是不能保证的。如果依赖的服务出现了不稳定的情况,请求的响应时间变长,那么调用服务的方法的响应时间也会变长,线程会产生堆积,最终可能耗尽业务自身的线程池,服务本身也变得不可用。
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的某一环不稳定,就可能会层层级联,最终导致整个链路都不可用。因此我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
注意:本文档针对 Sentinel 1.8.0 及以上版本。1.8.0 版本对熔断降级特性进行了全新的改进升级,请使用最新版本以更好地利用熔断降级的能力。
什么是雪崩?
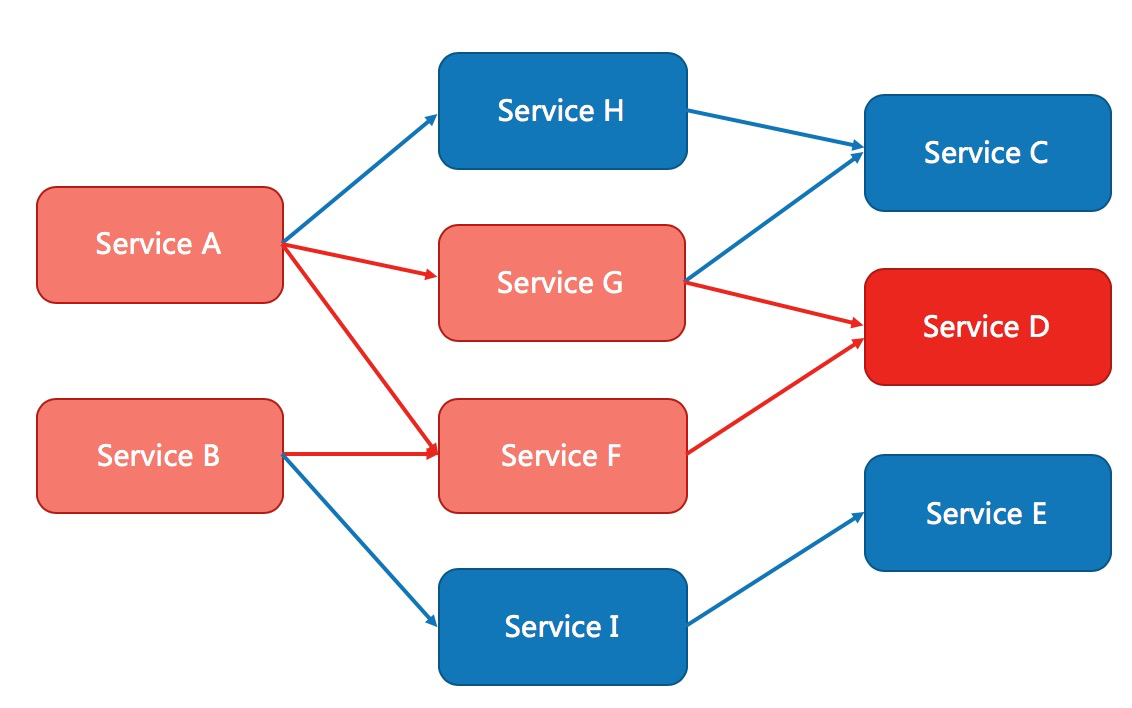
复杂的分布式体系结构中的应用程序,有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。为了让我们更好的了解学习,看下图:

由上图我们可以看到请求需要调用A、H、P、I 四个服务 ,如果一切顺利则没有什么问题,关键是如果服务I服务超时会出现什么情况呢?如下图:

会出现如图雪崩的现象,我们称之为服务雪崩。
什么是服务雪崩?
多个为服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”。
如果扇出的链路上某一个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所以的“雪崩效应”
对于高流量的应用来说,单一的后端依赖可能会导致所有的服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延时进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序和系统。所以,通常当你发现一个模块下的某一个实例失败后,这时候这个模块依然还会接受流量,然后这个问题的模块该调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
雪崩发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,或是某 台机器的资源耗尽。我们无法完全杜绝雪崩源头的发生,只有做好足够的容错,保证在一个服务发生问 题,不会影响到其它服务的正常运行。也就是"雪落而不雪崩"。
熔断策略
Sentinel 提供以下几种熔断策略:
慢调用比例
- 慢调用比例 (
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
异常比例
- 异常比例 (
ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。
异常数
- 异常数 (
ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
Sentinel在1.8.0版本对熔断降级做了大的调整,可以定义任意时长的熔断时间,引入了半开启恢复支持。下面梳理下相关特性。
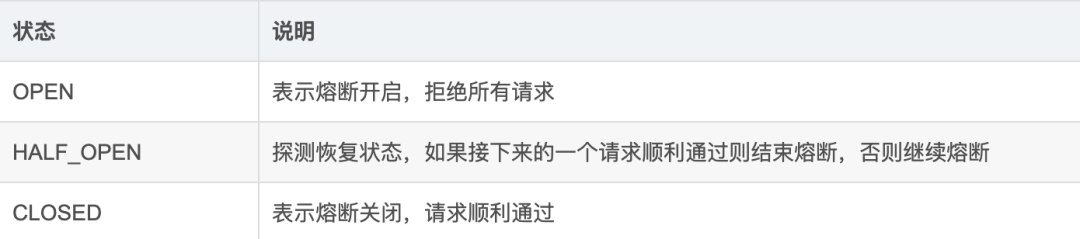
熔断状态
熔断有三种状态,分别为OPEN、HALF_OPEN、CLOSED
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,以请求快速失败,避免影响到其他资源而导致级联错误。
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出DegradeException)
半开的状态系统自动去检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可用。这个跟Hystrix是类似的。
慢调用比例示例
代码展示
1、慢调用比例
在FlowLimitController的类中新增testD方法,暂停1秒钟,如下图:
@GetMapping("/testD")
public String testD(){
try {
//暂停几秒钟线程
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) { e.printStackTrace();
}
log.info("testD 测试RT");
return "------testD";
}我们先访问一下testD是可以成功访问的,如下图:
配置示例
然后我们配置Sentinel的testD接口的降级当中的RT(慢调用)规则。如下图:
慢调用:业务的响应时长(RT)大于指定时长的请求认为为慢调用。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断,看下边的一个配置事例,如下图:
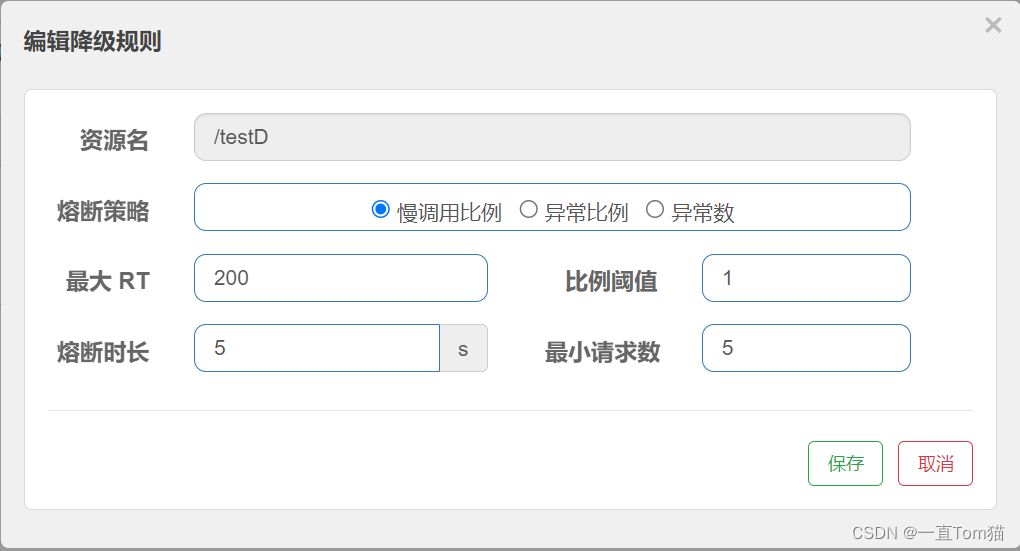
解读:RT超过200ms的调用是慢调用,如果每秒请求量超过5次,并且慢调用比例高于0.5,则触发熔断,熔断的时长为5秒。然后进入half-open状态,放行一次请求做测试,如果接下来的这个请求顺利通过,则结束熔断,否则继续熔断。
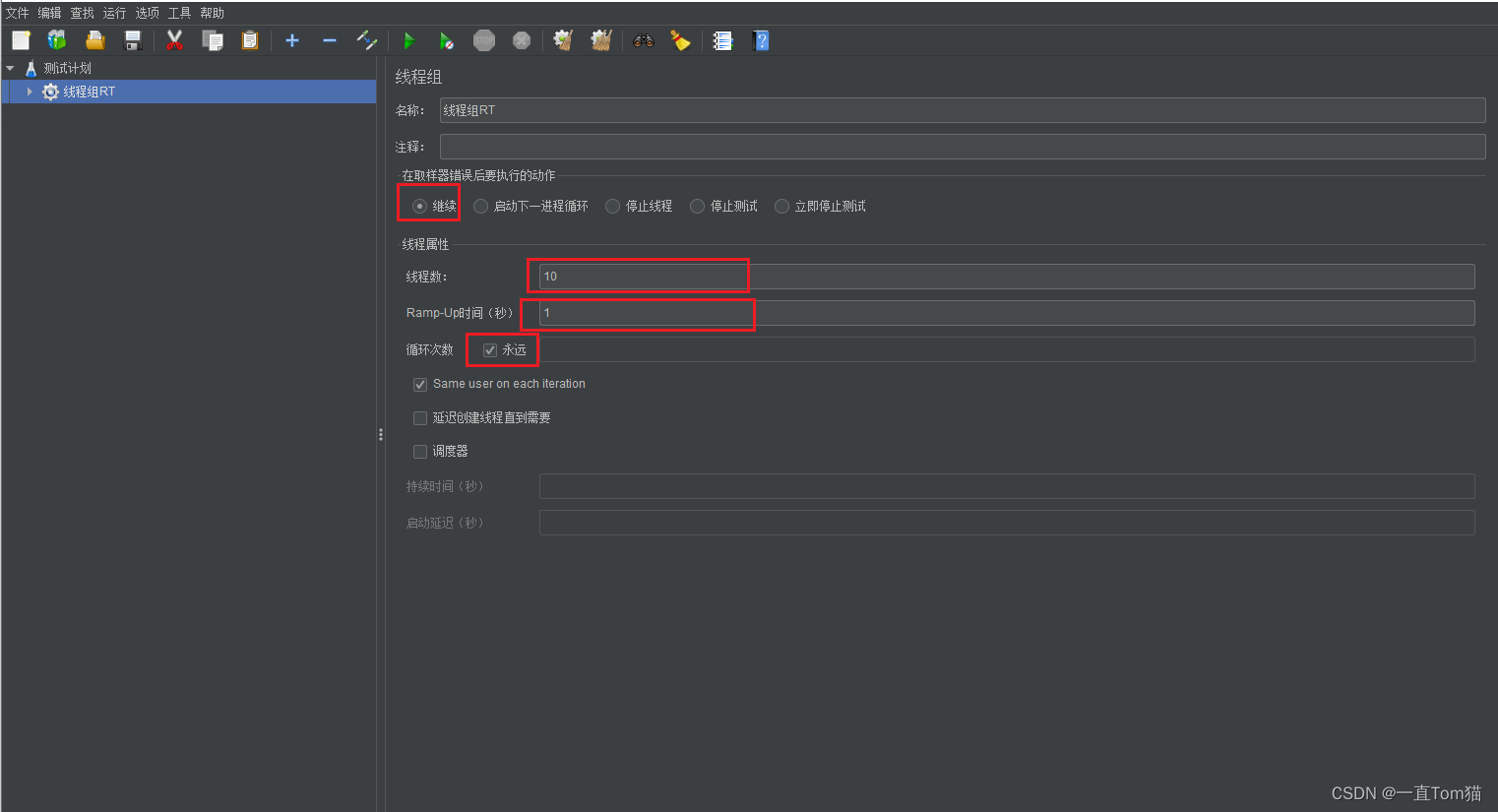
我们如何完成这个测试呢?接下来就用到了测试工具JMeter。我们首先在测试计划中添加一个线程组,如下图:
新建一个名称为线程组RT,一秒内发送10个线程进行请求,并且永远循环,如下图:
然后我们在配置http请求,如下图:

配置服务器的ip和端口号,再配置Http请求的方式和请求的路径,如下图:

我们点击绿色按钮,开始测试
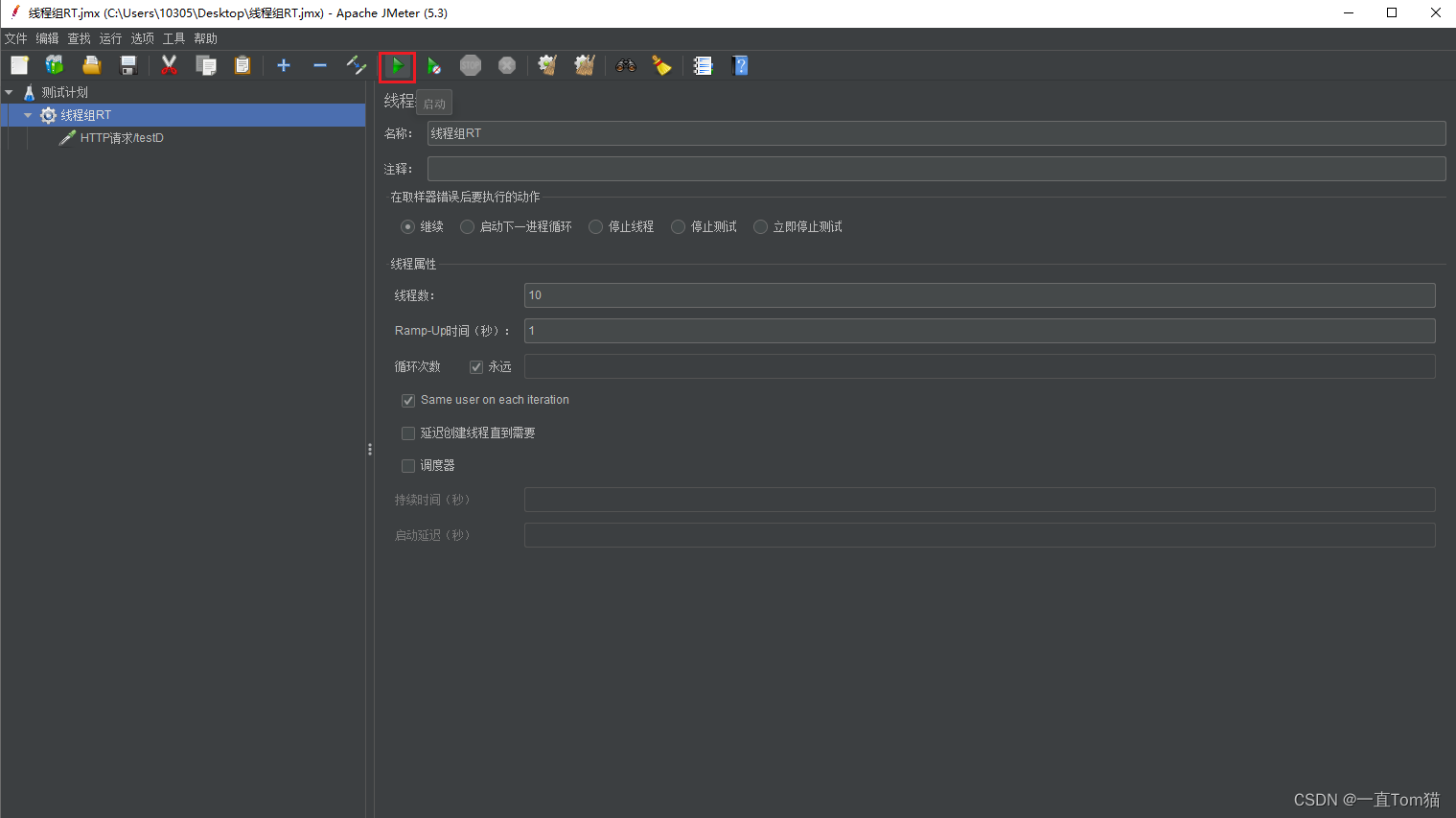
首先我们先访问一下testD是可以成功访问的,如下图:
我们在testD方法中,设置了睡眠1秒钟,请求时长肯定超过了我们设置的慢调用时长200毫秒,我们设置的线程组每秒的线程数10个,也超过了我们设置的每秒5个请求数。那接下就看一下是都可以降级成功。
可以看到我们控制台输出了我们请求的10个线程数。
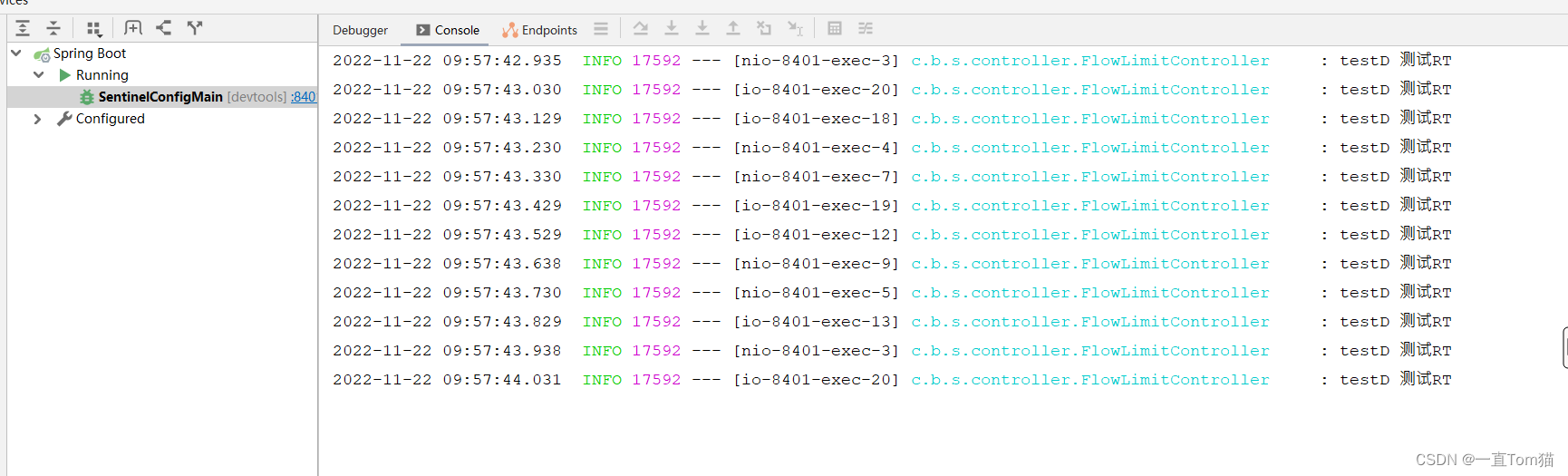
然后我们访问testD方法,无法访问。可以看到成功抛出了限流的异常。如下图。
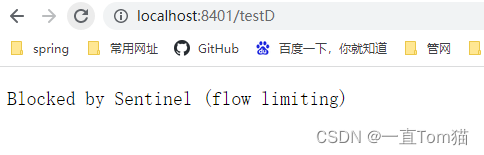
那我们的降级规则中的RT(慢调用)就配置成功了。
在我们测试的过程中,有时是可以访问到testD方法的,如下图:
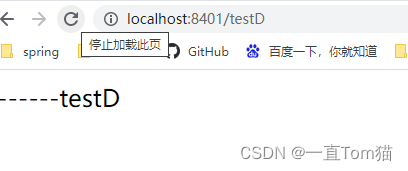
为什么会有时候就可以访问成功呢?
是因为我们碰巧是在熔断的时长为5秒结束之后。然后进入half-open状态,放行一次请求做测试,那碰巧我们手动请求了,所以通过了,则结束熔断。但是我们JMeter一直在循环调用,所以立马出现了熔断,所以又不能访问了,抛出了异常。