Flink
- 高可用
- HA 依赖于zk
- Flink ON Yarn
- 两种模式
- Session模式
- Per-Job模式
- 前置说明
- Flink原理
- 数据在两个operator算子之间传递的时候有两种模式:
- Operator Chain
- TaskSlot And Sharing
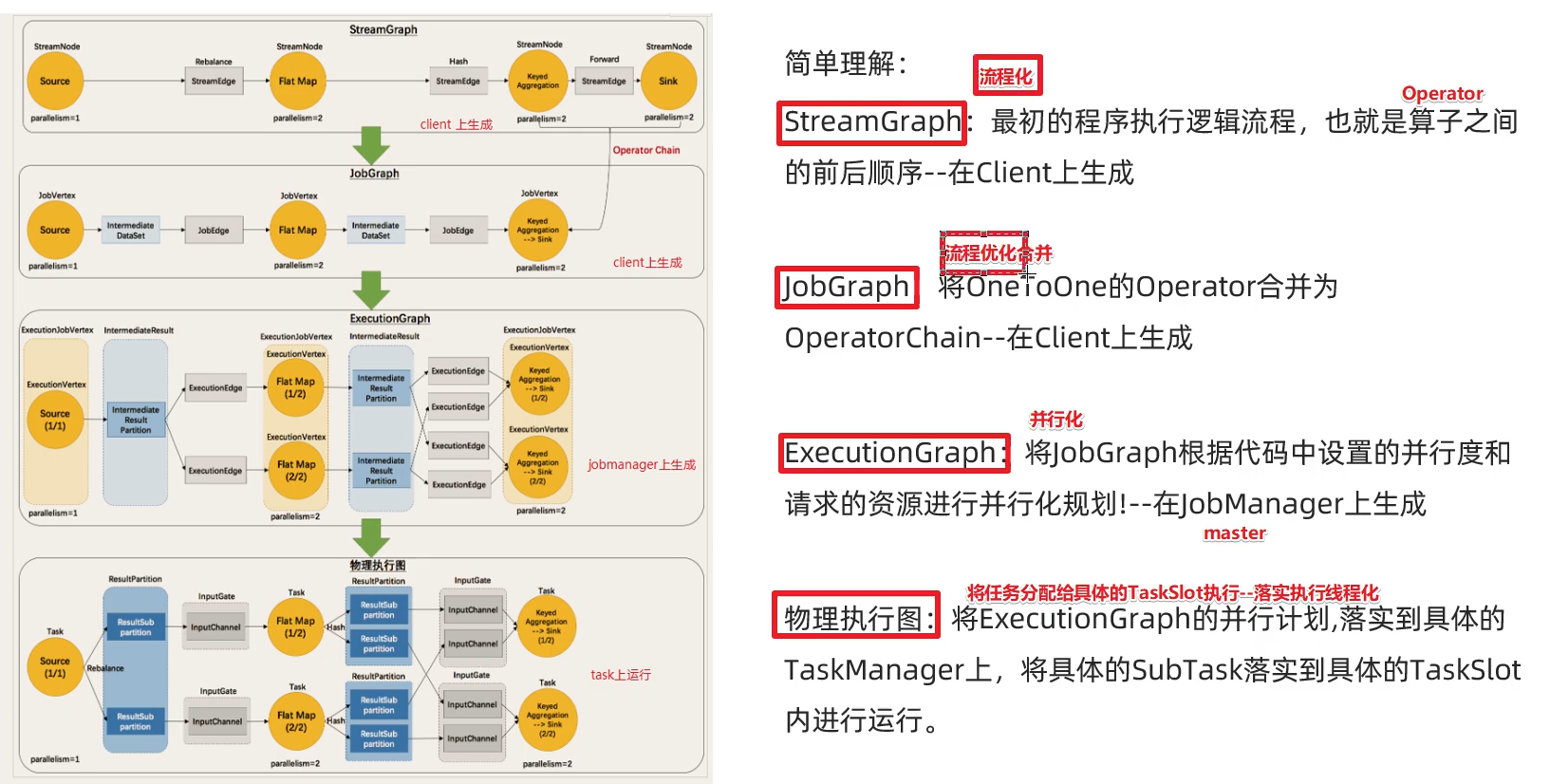
- Flink执行图(ExecutionGraph)
- API
- Source
- Transformation
- Sink
- 控制台
- 自定义Sink
- Connectors
- Flink四大基石
- Window
- Time And Watermark
- Time分类
- WaterMarker
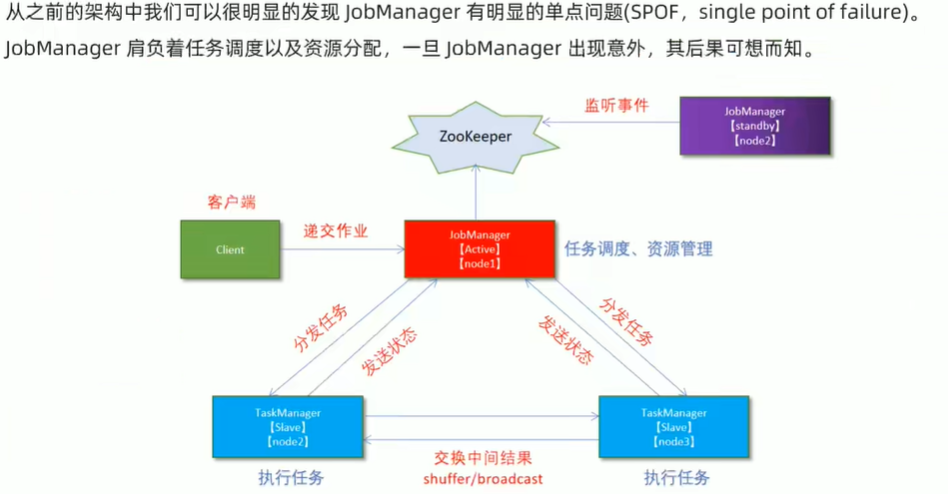
高可用
HA 依赖于zk
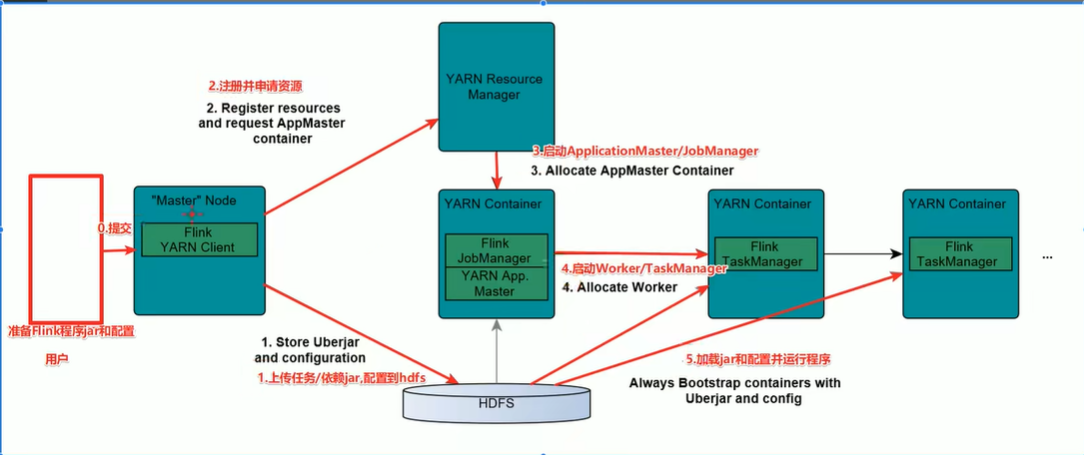
Flink ON Yarn

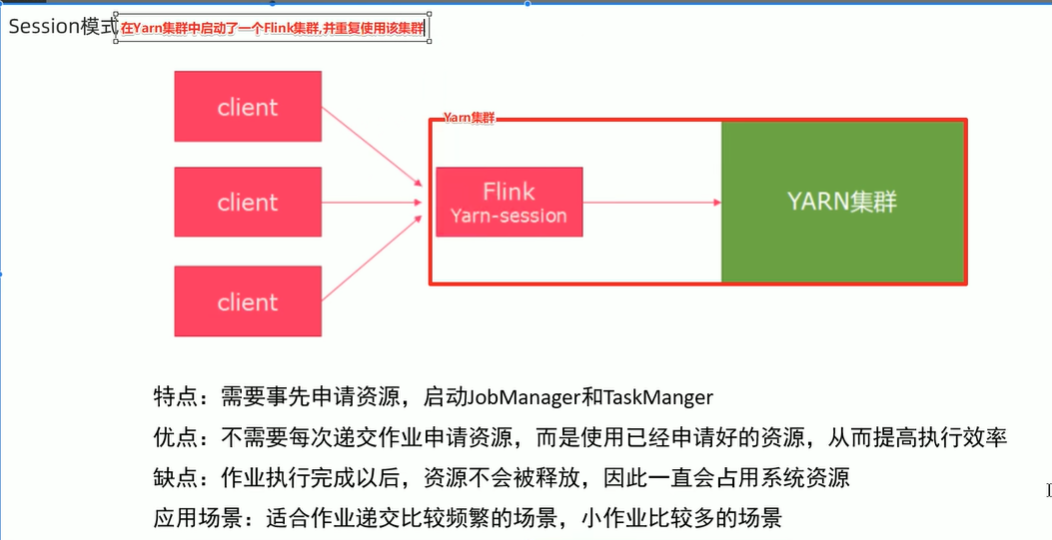
两种模式
Session模式
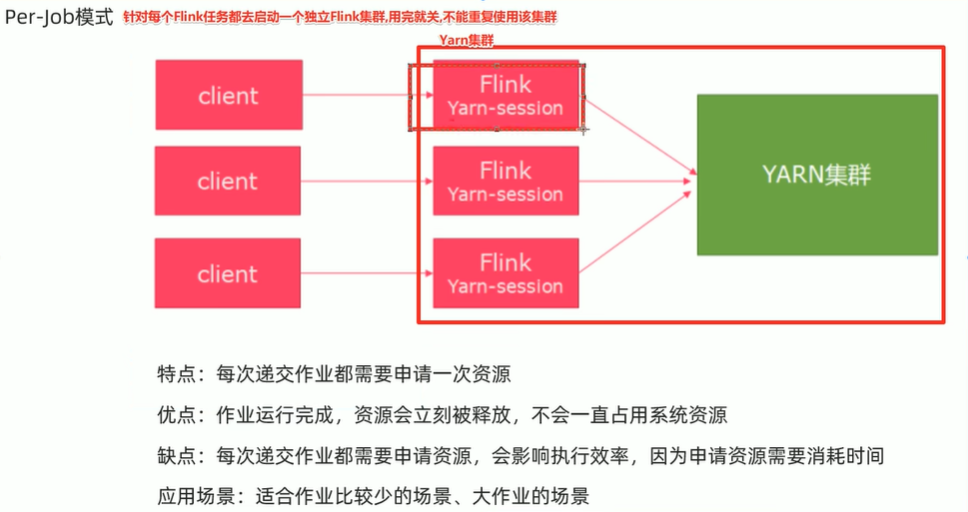
Per-Job模式
前置说明
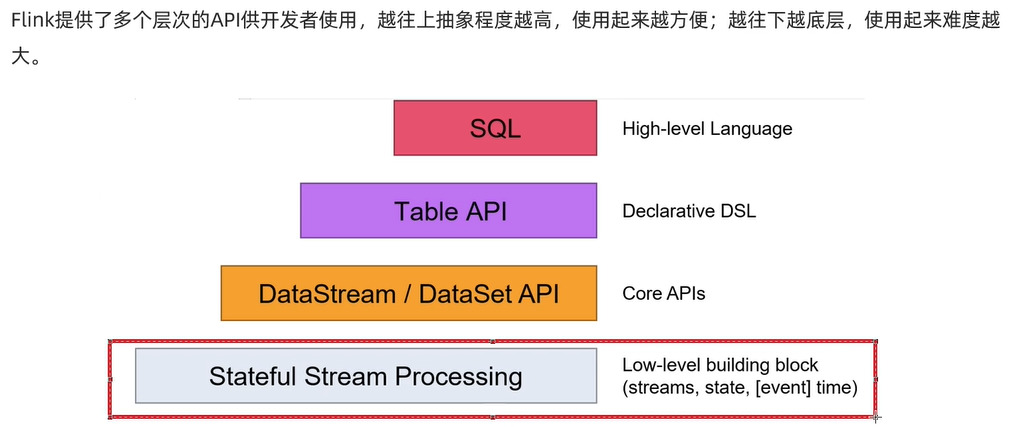
Flink原理
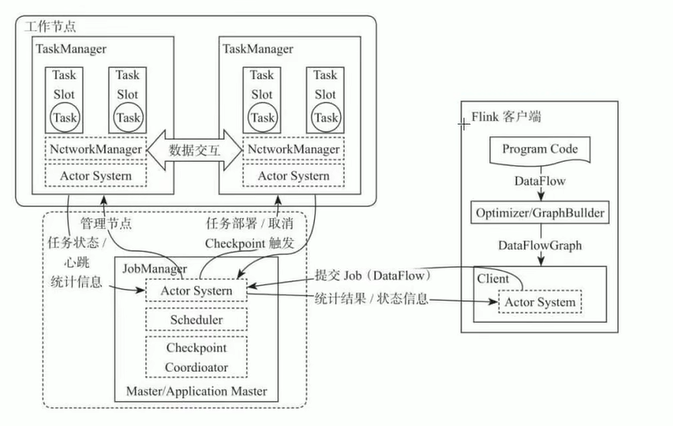
Task 属于进程 TaskSlot属于线程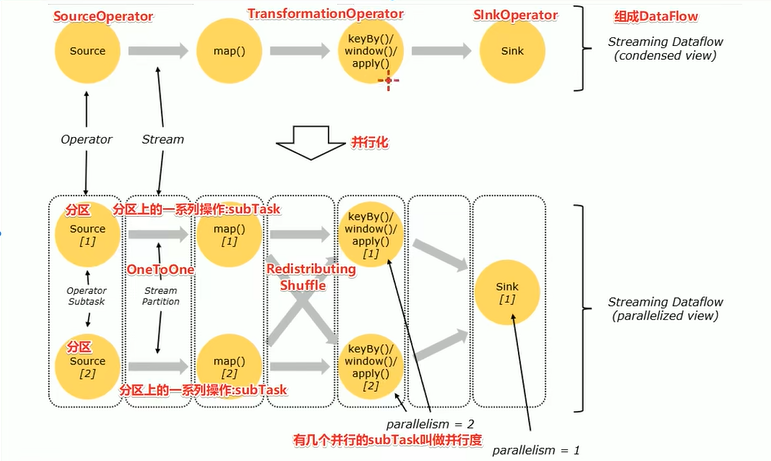
- DataFlow:Flink程序在执行的时候会被映射成一个数据流程模型
- Operator:数据流模型中得每一个操作都被称作为Operator,Operator分为:Source/Transfrom/Sink
- Partition:数据流模型是分布式的和并行的,执行中会形成1-n个分区
- SubTask:多个分区任务可以并行,每个都是运行在一个线程中的,也就是一个SubTask子任务
- Parallelism:并行度,就是可以同时执行的子任务数/分区数
数据在两个operator算子之间传递的时候有两种模式:
- One to One模式:
两个Operatior用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,他就保留的Source的分区特性,以及分区元素处理的有序性 - Redistributing模式
这种模式会改变数据的分区数;每个operator subtask会根据选择transformation把数据发送到不同的目标subtaks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区
Operator Chain
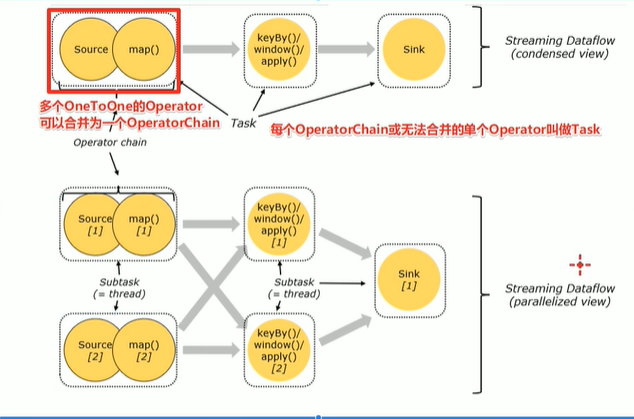
客户端在提交任务的时候对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后后的Operator称为Operator Chain,实际上就是一个执行链,
每个执行链会在TaskManager上独立的线程中执行–就是SubTask
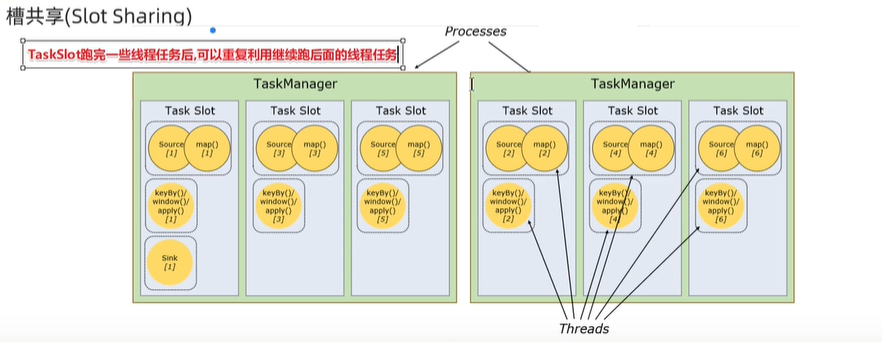
TaskSlot And Sharing
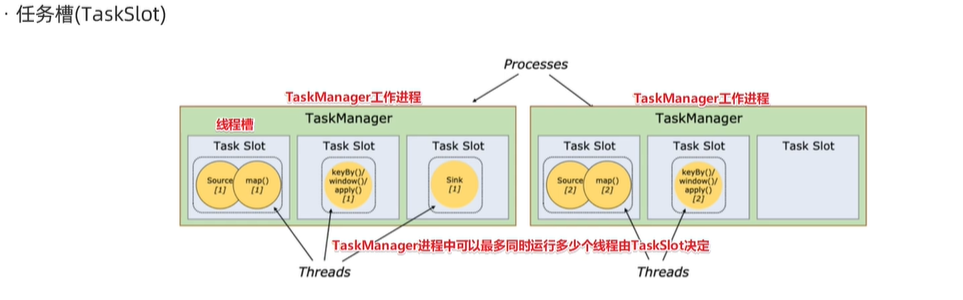
每个TaskManager是一个JVM的进程,为了控制一个TaskManager(worker)能接收多少个task,Flink通过TaskSlot来控制。TaskSloat数量是用来限制一个TaskManager工作进程中卡可以同时运行多少个工作线程,TaskSlot是一个TaskManager中的最小资源单位,一个TaskManager中有多少个TaskSlot就意味着能支持多少个并发Task处理
Flink将进程的内存进行
了划分到多个slot之后可以获得如下好处:
- TaskManager最多能同时并发执行的子任务数是可以通过TaskSlot数量控制的
- TaskSolt有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响
个人理解:分布式线程池,可复用
Flink执行图(ExecutionGraph)
API
Source
基于集合
- env.fromElements(可变参数)
- env.fromCollection(各种集合)
- env.generateSequence(开始,结束)
- env.fromSequence(开始,结束)
基于文件
env.readTextFile(本地/hdsf/文件夹)
基于Socket
env.socketTextStream(host,port)
自定义
Flink还提供了数据源接口,实现自定义数据源:
- SourceFunction:非并行度数据源(并行度只能 = 1)
- RichSourceFunction:多功能并行数据源(并行度只能 = 1)
- ParallelSourceFunction:并行数据源(并行度能够 >= 1)
- RichParallelSourceFunction: 多功能并
行数据源(并行度能够>=1)–>Kafka数据源使用欧冠的就是该接口
Transformation
- map/flatMap/keyBy/filter/reduce
- union和connect
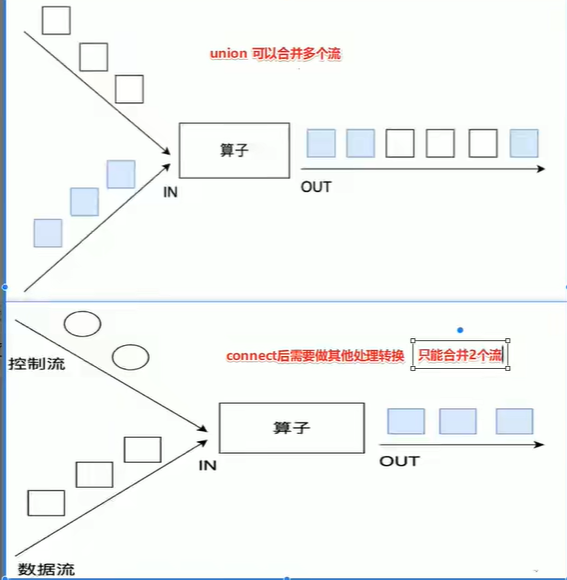
union:只能合并同类型
connect:可以合并不同类型,之后需要做其他处理,不能输出 - Side Outputs 侧流
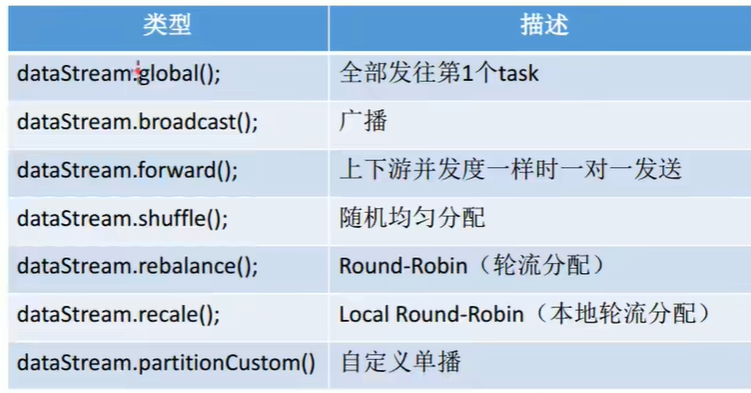
- rebalance 重平衡分区
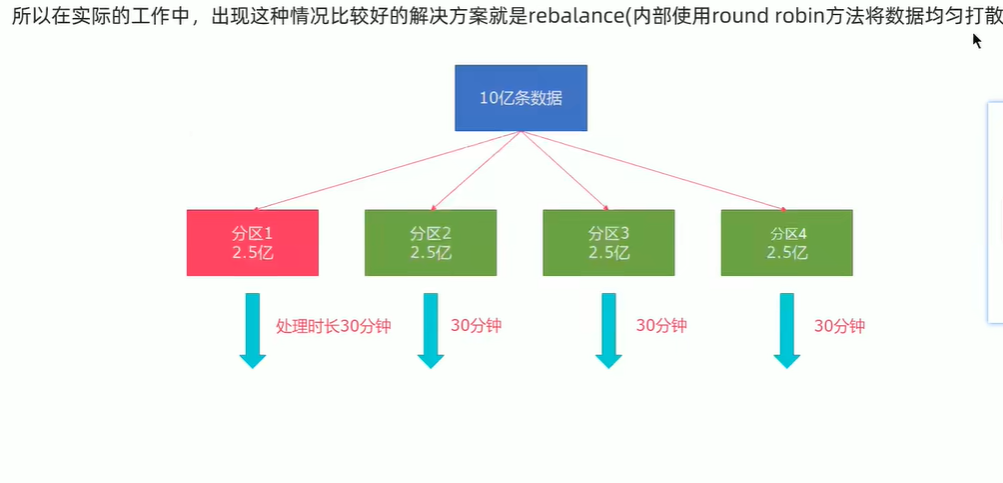
- 其他分区
Sink
控制台
- ds.print() 直接输出控制台
- ds.printToErr() 直接输出控制台红色
- ds.writeAsText(“本地/hdsf”,WriteMode.OVERWRITE)
注意输出到path的时候可以在前面设置并行度,如果
并行度>1,则path为目录
并行度=1,则path为文件夹
自定义Sink
类似于Source ,4个Sink
- SinkFunction:非并行度数据源(并行度只能 = 1)
- RichSinkFunction:多功能并行数据源(并行度只能 = 1)
- ParallelSinkFunction:并行数据源(并行度能够 >= 1)
- RichParallelSinkFunction: 多功能并
Connectors
JDBCSink,KafkaSink,RedisSink
Flink四大基石

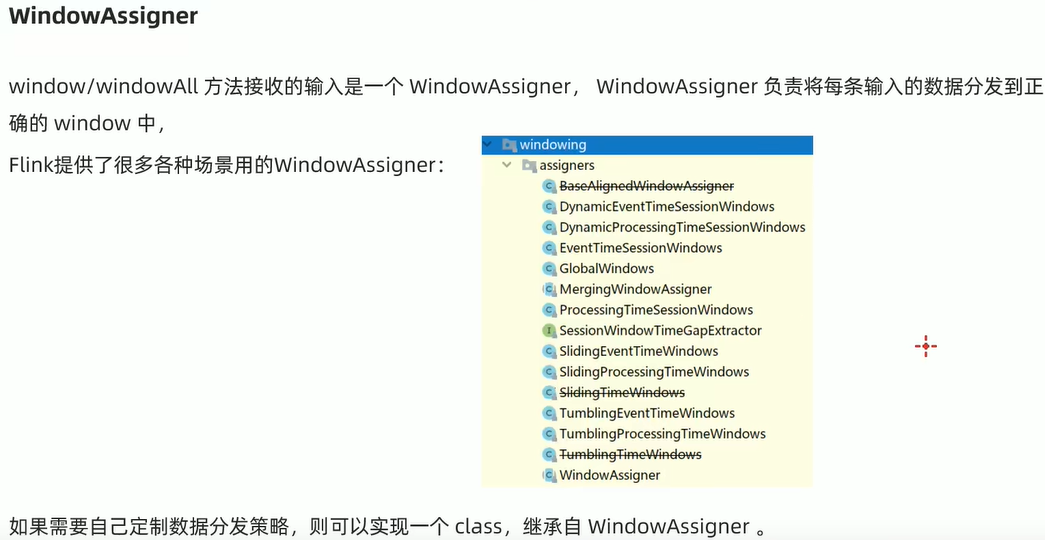
Window
window分类
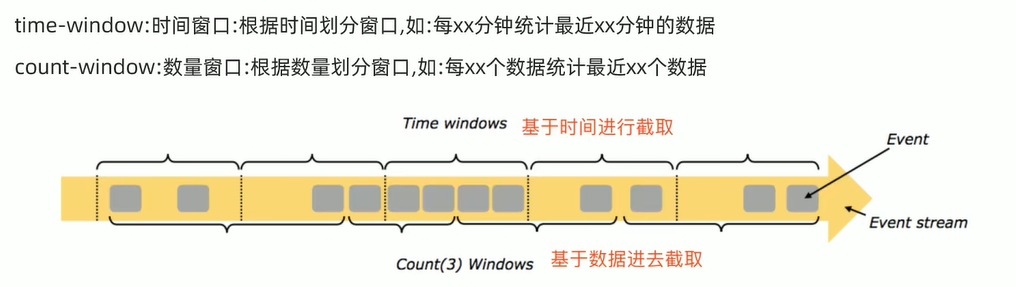
总结
- 基于时间的滚动窗口 tumbling-time-window
- 基于时间的滑动窗口 sliding-time-window
- 基于数量的滚动窗口 tumbling-count-window
- 基于数量的滑动窗口 sliding-count-window
flink还支持一个特殊的窗口:session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上一个窗口计算
使用keyby的流,应该使用window方法
未使用keyby的流,应该使用windowAll方法
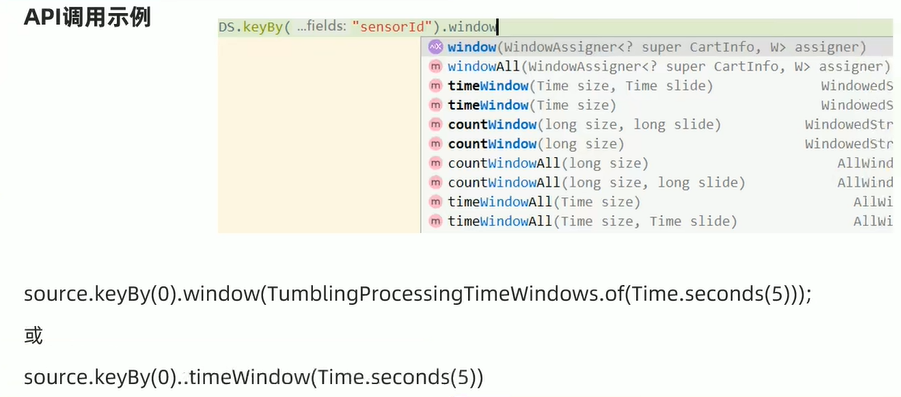
基于时间
public class CarDemo {
/**
* 需求
* nc -lk 9999
* 有如下数据表示
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
2,3
9,2
3,3
3,2
4,3
9,2
要求1:
每隔5秒钟统计一次,最近5秒内,各个路口通过红路灯汽车的数量--基于时间的滚动窗口
要求2:
每隔5秒钟统计一次,最近10秒内,各个路口通过红路灯汽车的数量--基于时间的滑动窗口
*
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = stream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(split[0], Integer.valueOf(split[1]));
}
});
KeyedStream<Tuple2<String, Integer>, String> tStream = mapStream.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> tumblingStream = tStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> slidingStream = tStream.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.sum(1);
tumblingStream.print("tumbling");
slidingStream.printToErr("sliding");
env.execute();
}
}
基于数量
public class CarDemo {
/**
* 需求
* nc -lk 9999
* 有如下数据表示
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
2,3
9,2
9,2
9,2
要求1:
统计在最近的5条消息中,各自路口通过的机车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
要求2:
统计在最近的5条消息中,各自路口通过的机车数量,相同的key每出现3次进行统计--基于时间的滑动窗口
*
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = stream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(split[0], Integer.valueOf(split[1]));
}
});
KeyedStream<Tuple2<String, Integer>, String> tStream = mapStream.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> tumblingStream = tStream.countWindow(5).sum(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> slidingStream = tStream.countWindow(5, 3).sum(1);
tumblingStream.print("tumbling");
slidingStream.printToErr("sliding");
env.execute();
}
}
会话窗口
public class CarDemo {
/**
* 需求
* nc -lk 9999
* 有如下数据表示
* 信号灯编号和通过该信号灯的车的数量
9,3
9,2
2,3
9,2
9,2
9,2
要求1:
设置会话超时时间10s,10s内没有数据到来,则触发窗口计算
*
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = stream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(split[0], Integer.valueOf(split[1]));
}
});
KeyedStream<Tuple2<String, Integer>, String> tStream = mapStream.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = tStream.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).sum(1);
sum.printToErr();
env.execute();
}
}
Time And Watermark
Time分类
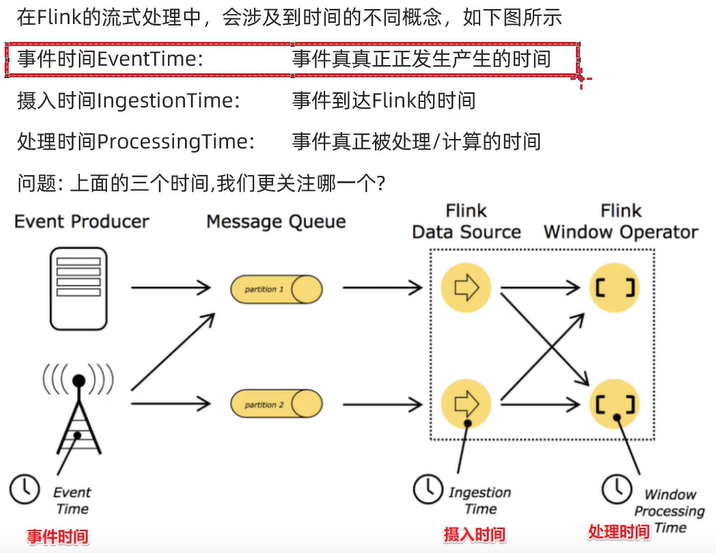



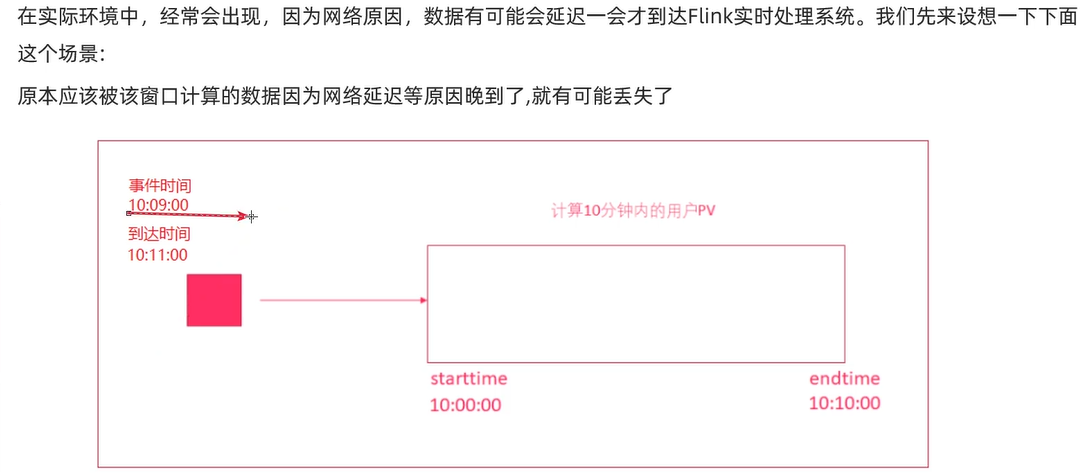

WaterMarker




WaterMarker重点
案例
public class WTOrderDemo {
public static void main(String[] args) throws Exception {
/**
* 需求
* 有订单数据,格式: ( 订单Id,用户Id,时间戳/事件时间 ,订单金额)
* 要求每隔5s,计算5s内,每个用户的订单总金额
*
* 并添加WaterMaker来解决一定程度的 数据延迟以及数据乱序 问题
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Order> orderDs = env.addSource(new SourceFunction<Order>() {
private Boolean flag = true;
@Override
public void run(SourceContext<Order> ct) throws Exception {
Random random = new Random();
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(2);
int money = random.nextInt(101);
long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;
Order order = new Order(orderId, userId, money, eventTime);
ct.collect(order);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
// TODO transformation
/**
* Flink 1.12 版本
* 每隔5s计算最近的数据球每个用户的订单总金额,要求:基于时间时间计算+WaterMarker
*
* env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 在新版本中默认就是EventTime
* 设置 WaterMarker = 当前最大事件时间 - 最大允许的延时 或 乱序时间
*/
SingleOutputStreamOperator<Order> orderDsWithWatermark = orderDs.assignTimestampsAndWatermarks(
WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 指定延时时间或乱序时间
.withTimestampAssigner(((order, timestamp) -> order.eventTime))
);
SingleOutputStreamOperator<Order> result = orderDsWithWatermark.keyBy(order -> order.userId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum("money");
result.print();
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order{
public String orderId;
public Integer userId;
public Integer money;
public Long eventTime;
}
}
测到输出机制(解决严重迟到问题)

public class WTOrderDemo {
public static void main(String[] args) throws Exception {
/**
* 需求
* 有订单数据,格式: ( 订单Id,用户Id,时间戳/事件时间 ,订单金额)
* 要求每隔5s,计算5s内,每个用户的订单总金额
*
* 并添加WaterMaker来解决一定程度的 数据延迟以及数据乱序 问题
*
* 并使用outputTag + allowedLateness 来解决数据丢失问题(严重的 数据延迟以及数据乱序 问题)
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Order> orderDs = env.addSource(new SourceFunction<Order>() {
private Boolean flag = true;
@Override
public void run(SourceContext<Order> ct) throws Exception {
Random random = new Random();
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(2);
int money = random.nextInt(101);
long eventTime = System.currentTimeMillis() - random.nextInt(20) * 1000;
Order order = new Order(orderId, userId, money, eventTime);
ct.collect(order);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
// TODO transformation
/**
* Flink 1.12 版本
* 每隔5s计算最近的数据球每个用户的订单总金额,要求:基于时间时间计算+WaterMarker
*
* env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 在新版本中默认就是EventTime
* 设置 WaterMarker = 当前最大事件时间 - 最大允许的延时 或 乱序时间
*/
// TODO 侧道输出机制,解决严重的迟到问题
OutputTag<Order> orderOutputTag = new OutputTag<>("seriousLate", TypeInformation.of(Order.class));
SingleOutputStreamOperator<Order> orderDsWithWatermark = orderDs.assignTimestampsAndWatermarks(
WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 指定延时时间或乱序时间
.withTimestampAssigner(((order, timestamp) -> order.eventTime))
);
SingleOutputStreamOperator<Order> result1 = orderDsWithWatermark.keyBy(order -> order.userId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
.sideOutputLateData(orderOutputTag)
.sum("money");
DataStream<Order> result2 = result1.getSideOutput(orderOutputTag);
result1.print("正常的数据");
result2.printToErr("迟到的数据");
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order{
public String orderId;
public Integer userId;
public Integer money;
public Long eventTime;
}
}




![[附源码]java毕业设计校园二手交易平台的设计](https://img-blog.csdnimg.cn/2c1b6ec77e274151964a6bce79b03da6.png)