从这节起,我们要循序渐进的学习InfluxDB、Cadvisor、Grafana。这三种工具组合使用可以完成对容器的各项指标实时监控,也为后面的k8s打好基础。
一、InfluxDB的介绍
InfluxDB是一种用Go编写的时间序列数据库,主要用来存储一些时间序列的数据。提供了简单、高效的HTTP读写接口,可以使用类似SQL的语言InfluxQL查询聚合数据,能够使用Tag进行快速高效的查询。
什么是时间序列的数据?从定义上来说,就是一串按时间维度索引的数据。
Influxdb应用在性能监控,应用程序指标,物联网传感器数据和实时分析等的后端存储。
二、InfluxDB的特点
InfluxDB属于典型的时间序列数据库(TSDB),而此类数据的的特点是:
- 持续高并发写入、不用更新
- 数据压缩存储
- 低延时查询
常见的时间序列数据库除了InfluxDB之外还有:opentsdb、timeScaladb、Druid等
三、InfluxDB的使用场景
常见的使用场景:
1、监控数据统计。比如每毫秒记录一下电脑内存的使用情况,进而根据统计的数据,利用图形化界面制作内润使用情况的折线图。
2、处理高写入和查询负载的时序数据,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、车联网、智慧交通、金融和IOT传感器数据采集。
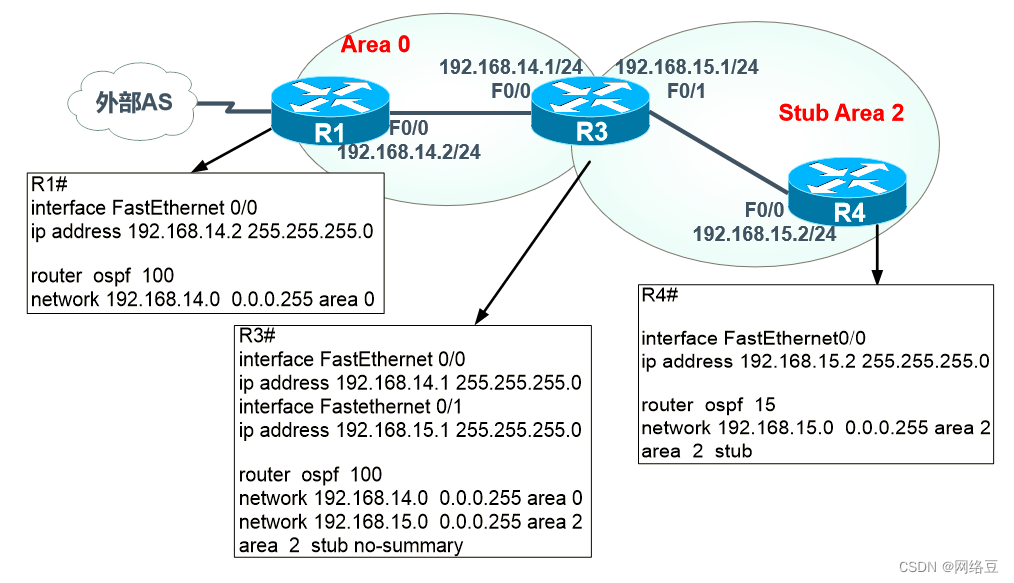
四、InfluxDB与关系型数据库的数据定义差异
| InfuxDB中的概念 | 传统数据库中的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的table表 |
| point | 表中的row行 |
其中重点说一下Point。
Point是由时间戳(time)、标签(tags)、数据(fields)三部分组成,具体的含义如下:
| point属性 | 含义 |
|---|---|
| time | 数据记录的时间,主索引,默认自动生成,相当于每行数据都具备的列 |
| tags | 相当于有索引的列。tag中存储的值的类型是字符串类型 |
| fields | value值,没有索引的列。field中存储的值得类型:字符串、浮点数(Double)、整数、布尔型。一个field value总是和一个timestamp相关联 |
五、InfluxDB的安装
(1)下载镜像
docker pull tutum/influxdb
(2)创建容器
docker run -di \
-p 8083:8083 \
-p 8086:8086 \
--expose 8090 \
--expose 8099 \
--name influxsrv \
tutum/influxdb
端口概述: 8083端口:web访问端口 8086:数据写入端口
打开浏览器 http://服务器ip:8083/

六、InfluxDB的基本操作
1、首先进入influxdb的容器
docker exec -it influxdb /bin/bash
容器已经安装了InfluxDB,在命令行里输入influx:
就进入了InfluxDB数据库环境了。
2、创建数据库
CREATE DATABASE "cadvisor"
回车创建数据库
SHOW DATABASES
查看数据库
3、创建用户并授权
创建用户
CREATE USER "cadvisor" WITH PASSWORD 'cadvisor' WITH ALL PRIVILEGES
查看用户
SHOW USRES
用户授权
grant all privileges on cadvisor to cadvisor
grant WRITE on cadvisor to cadvisor
grant READ on cadvisor to cadvisor
4、 查看采集的数据
切换到cadvisor数据库,使用以下命令查看采集的数据
SHOW MEASUREMENTS
现在我们还没有数据,如果想采集系统的数据,我们需要使用Cadvisor软件来实现。这就为下篇文章留下了埋笔。敬请期待~