复合索引基础
MySQL中的复合索引(Composite Index)是指由多个列组成的索引。与单列索引不同、复合索引的结构更为复杂,但使用得当可以大幅提升查询性能。
复合索引的工作原理
复合索引的本质是一种有序的数据结、每个列是建立在那个索引前一列存在的情况下、那一列有序才有意义。这句话是理解复合索引的关键
以复合索引(name,sex,age)为例:
- 首先MySQL按name字段排序
- 当name相同时、才按sex排序
- 当name和sex都相同时、才按age排序
这类似于字典中的词条排序方式:先按第一个字母排序、第一个字母相同时按第二个字母排序、以此类推。
最左前缀原则
由于复合索引的这种层级结构特性、MySQL使用复合索引时必须遵循最左前缀原则
1. 查询必须从索引的最左边列开始
2. 不能跳过索引中的列
3. 如果查询条件有范围查询,则其右边的列无法使用索引优化
题目分析
让我们分析题目中的表结构:
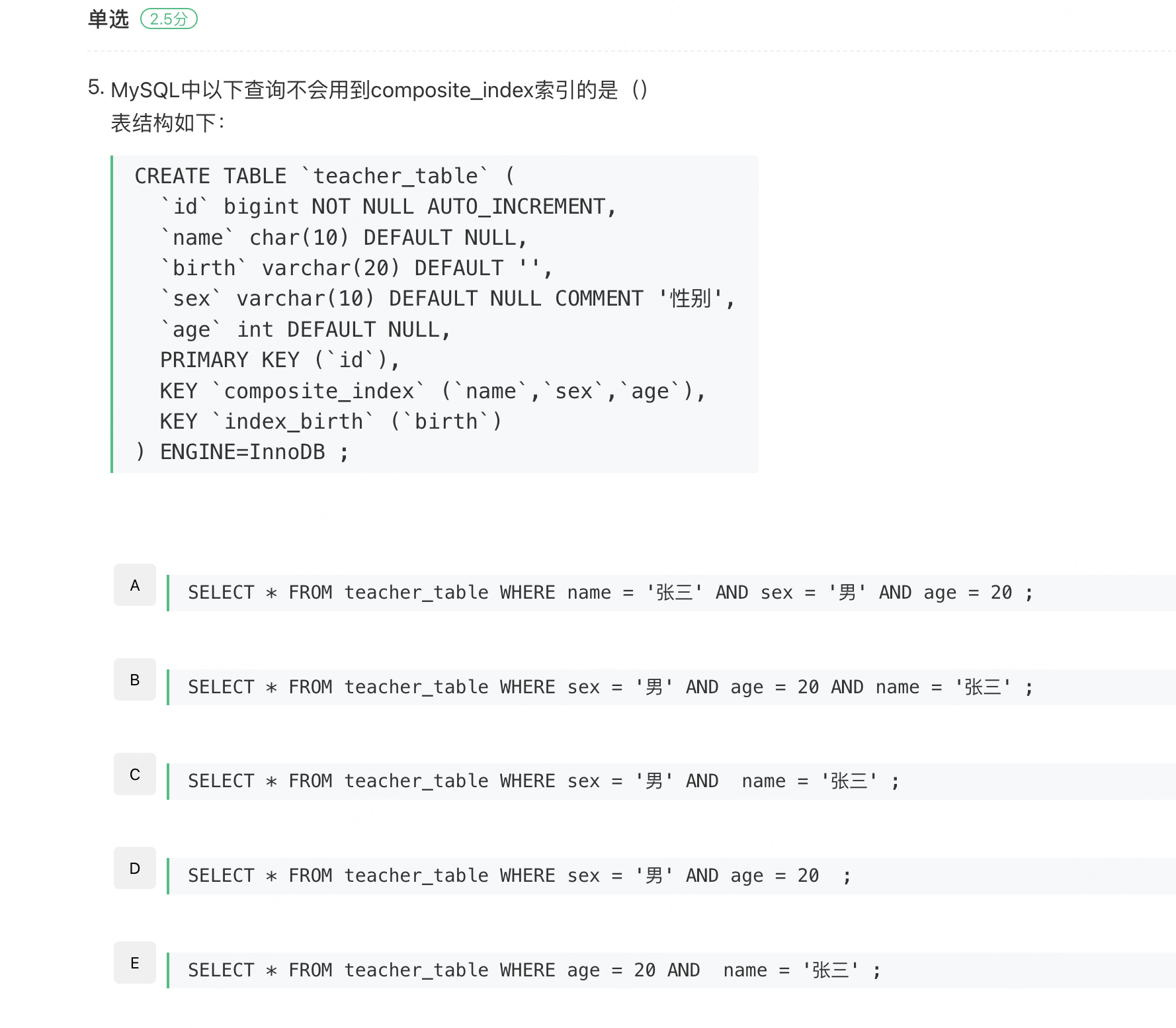
CREATE TABLE `teacher_table` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` char(10) DEFAULT NULL,
`birth` varchar(20) DEFAULT '',
`sex` varchar(10) DEFAULT NULL COMMENT '性别',
`age` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `composite_index` (`name`,`sex`,`age`),
KEY `index_birth` (`birth`)
) ENGINE=InnoDB ;这里创建了一个复合索引composite_index 包含name、sex和age三个字段。
分析各选项:
A选项:
SELECT * FROM teacher_table WHERE name = '张三' AND sex = '男' AND age = 20完全匹配复合索引的三个字段、按顺序使用、可以充分利用索引。
B选项:
SELECT * FROM teacher_table WHERE sex = '男' AND age = 20 AND name = '张三'虽然WHERE条件的顺序与索引列顺序不同、但MySQL优化器会自动调整、仍然可以使用完整的复合索引。
C选项:
SELECT * FROM teacher_table WHERE sex = '男' AND name = '张三'包含了name和sex、MySQL优化器会重排顺序、使用复合索引的前两列。
D选项:
SELECT * FROM teacher_table WHERE sex = '男' AND age = 20没有包含索引的第一列name、违反了最左前缀原则、无法使用复合索引。
E选项:
SELECT * FROM teacher_table WHERE age = 20 AND name = '张三'包含了第一列name、但跳过了中间的sex列、只能使用name一个列的索引效果。
因此D选项是无法利用复合索引的查询
总结:
D违反了最左匹配原则、导致索引失效
B中优化器会对查询条件进行重排
C包含了 name 和 sex、查询时优化器会先重排条件、然后可以使用 name 和 sex 索引
E则是先重排条件、然后使用 name 索引(因为它是索引的第一列)
算法题
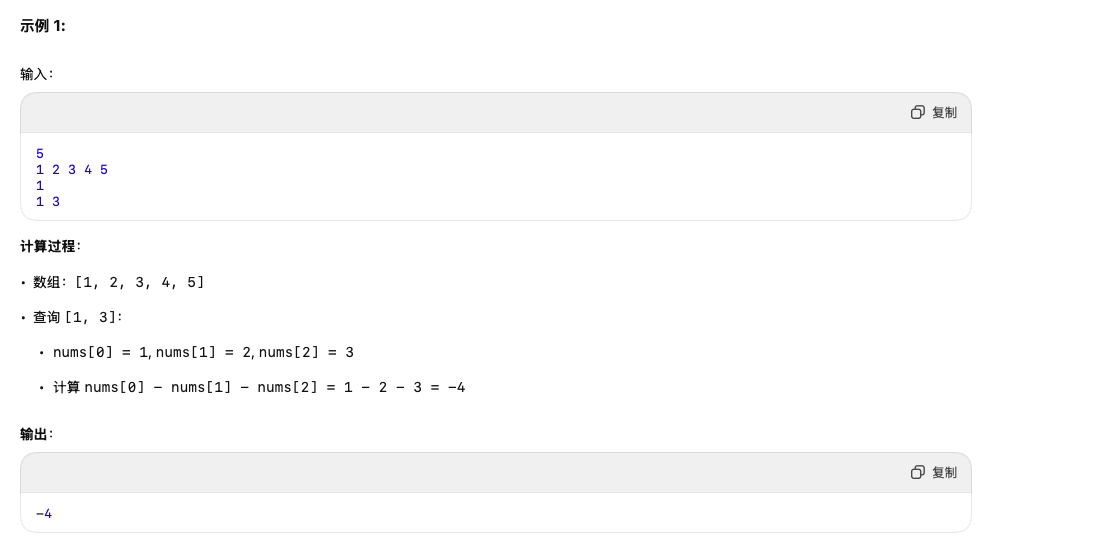
题目要求在每个查询中计算的是一个从 nums[l1] 开始、到 nums[l2]、然后依次减去到 nums[r] 的结果。具体来说每个查询 (l, r) 需要计算类似于:
也就是说给定一个区间 [l, r]、你要从 nums[l] 开始、然后依次减去 nums[l+1], nums[l+2],直到 nums[r]。
nums[l-1] - nums[l] - nums[l+1] - ... - nums[r-1]差不多就是:

我写的代码超时:
import java.util.Scanner;
// 注意类名必须为 Main, 不要有任何 package xxx 信息
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int q = sc.nextInt();
int[] nums = new int[n];
for (int i = 0; i < n; i++) {
nums[i] = sc.nextInt();
}
int result = 0;
for (int i = 0; i < q; i++) {
int l = sc.nextInt();
int r = sc.nextInt();
int currentSum = 0;
if (l == r) {
currentSum = nums[l - 1];
} else {
int digital = nums[l - 1];
int sum = 0;
for (int j = l; j < r; j++) {
sum += nums[j];
}
currentSum = digital - sum;
}
System.out.println(currentSum);
}
}
}题目优化思路:
由于每次查询的结果是计算一段区间的加减、且每次都涉及到相邻元素的减法、可以通过 前缀和 的思想来优化。所以我们构造一个辅助数组、在 O(1) 时间内处理每次查询。
优化策略:
-
前缀和数组:首先我们可以计算一个前缀和数组、表示数组 nums 中从 nums[0] 到 nums[i] 的和。这个可以在 O(n) 时间内完成。
-
计算差值数组:根据题目的要求、构建一个 差值”数组 diff[i] = nums[i] - nums[i+1](即后一个元素减去当前元素)、这样当你需要做连续的减法时、就能快速计算出结果。
-
快速查询:每次查询 (l, r)、利用 diff 数组快速得出 nums[l] - nums[l+1] - ... - nums[r] 的结果。
优化后的代码:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 数组长度
int q = sc.nextInt(); // 查询次数
int[] nums = new int[n];
// 输入数组元素
for (int i = 0; i < n; i++) {
nums[i] = sc.nextInt();
}
// 构建前缀和数组
int[] prefixSum = new int[n + 1]; // prefixSum[i] 表示 nums[0] 到 nums[i-1] 的和
for (int i = 1; i <= n; i++) {
prefixSum[i] = prefixSum[i - 1] + nums[i - 1];
}
// 处理每个查询
for (int i = 0; i < q; i++) {
int l = sc.nextInt(); // 查询的起始位置
int r = sc.nextInt(); // 查询的结束位置
// 计算区间 [l, r] 的和,并按照要求计算结果
int sum = prefixSum[r] - prefixSum[l - 1]; // 获取区间和
int currentSum = nums[l - 1] - sum; // nums[l-1] - sum
System.out.println(currentSum); // 输出结果
}
}
}测试用例: