1 数据库
Milvus 在集合之上引入了数据库层,为管理和组织数据提供了更有效的方式,同时支持多租户。
1.1 什么是数据库
在 Milvus 中,数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,你可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。例如,创建一个数据库用于存储用户 A 的数据,另一个数据库用于存储用户 B 的数据。
1.2 创建数据库
可以使用 Milvus RESTful API 或 SDK 以编程方式创建数据。
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus" # 用户名:密码
)
client.create_database(
db_name="my_database_1"
)
还可以在创建数据库时为其设置属性。下面的示例设置了数据库的副本数量。
client.create_database(
db_name="my_database_2",
properties={
"database.replica.number": 3
}
)
1.3 查看数据库
您可以使用 Milvus RESTful API 或 SDK 列出所有现有数据库并查看其详细信息。
# 列出所有现有数据库
client.list_databases()
# 输出
# ['default', 'my_database_1', 'my_database_2']
# 检查数据库详细信息
client.describe_database(
db_name="default"
)
# 输出
# {"name": "default"}1.4 管理数据库属性
每个数据库都有自己的属性,您可以在创建数据库时设置数据库属性,也可以更改和删除任何现有数据库的属性。下表列出了可能的数据库属性。
| 属性名称 | 类型 | 属性描述 |
|---|---|---|
|
| 整数 | 指定数据库的副本数量。 |
|
| 字符串 | 与指定数据库关联的资源组名称,以通用分隔列表形式显示。 |
|
| 整数 | 指定数据库的最大磁盘空间大小(MB)。 |
|
| 整数 | 指定数据库中允许的最大 Collections 数量。 |
|
| 布尔 | 是否强制指定的数据库拒绝写操作。 |
|
| 布尔 | 是否强制指定的数据库拒绝读取操作。 |
1.4.1 更改数据库属性
可以通过以下方式更改现有数据库的属性。下面的示例限制了可以在数据库中创建的 Collections 数量。
client.alter_database_properties(
db_name: "my_database_1",
properties: {
"database.max.collections": 10
}
)
1.4.2 删除数据库属性
还可以通过如下方式删除数据库属性来重置该属性。下面的示例删除了可以在数据库中创建的 Collection 数量限制。
client.drop_database_properties(
db_name: "my_database_1",
property_keys: [
"database.max.collections"
]
)
1.5 使用数据库
可以在不断开与 Milvus 连接的情况下从一个数据库切换到另一个数据库。RESTful API 不支持此操作符。
client.use_database(
db_name="my_database_2"
)
1.6 删除数据库
一旦不再需要数据库,就可以删除数据库。请注意
- 不能丢弃默认数据库。
- 在丢弃数据库之前,需要先丢弃数据库中的所有 Collections。
client.drop_database(
db_name="my_database_2"
)
你可以使用 Milvus RESTful API 或 SDK 以编程方式创建数据。
2 Collections 说明
在 Milvus 中,您可以创建多个 Collections 来管理数据,并将数据作为实体插入到 Collections 中。Collections 和实体类似于关系数据库中的表和记录。本页将帮助你了解集合和相关概念。
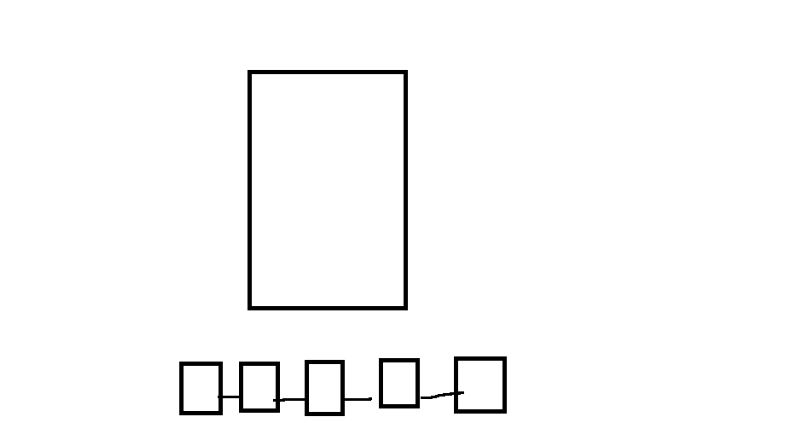
Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。下图显示了一个有 8 列和 6 个实体的 Collection。

2.1 Schema 和字段
在描述一个对象时,我们通常会提到它的属性,如大小、重量和位置。您可以将这些属性用作 Collection 中的字段。每个字段都有各种约束属性,例如向量字段的数据类型和维度。通过创建字段并定义其顺序,可以形成一个 Collections Schema。应在要插入的实体中包含所有 Schema 定义的字段。
2.2 主键和 AutoId
与关系数据库中的主字段类似,Collection 也有一个主字段,用于将实体与其他实体区分开来。主字段中的每个值都是全局唯一的,并与一个特定实体相对应。
如上图所示,名为id的字段是主字段,第一个 ID0对应一个名为 "冠状病毒的死亡率并不重要"的实体。不会有其他实体的主字段是 0。
主字段只接受整数或字符串。插入实体时,默认情况下应包含主字段值。但是,如果在创建 Collections 时启用了AutoId,Milvus 将在插入数据时生成这些值。在这种情况下,请从要插入的实体中排除主字段值。
2.3 索引
为特定字段创建索引可提高搜索效率。建议您为服务所依赖的所有字段创建索引,其中向量字段的索引是强制性的。
2.4 实体
实体是指在 Collections 中共享同一组字段的数据记录。同一行中所有字段的值构成一个实体。您可以根据需要在 Collections 中插入任意数量的实体。但是,随着实体数量的增加,所占用的内存大小也会增加,从而影响搜索性能。
2.5 加载和释放
加载集合是在集合中进行相似性搜索和查询的前提。加载 Collections 时,Milvus 会将所有索引文件和每个字段中的原始数据加载到内存中,以便快速响应搜索和查询。搜索和查询是内存密集型操作。为节约成本,建议您释放当前不使用的 Collections。
2.6 搜索和查询
创建索引并加载 Collections 后,就可以通过输入一个或多个查询向量开始相似性搜索。例如,当接收到搜索请求中携带的查询向量表示时,Milvus 会使用指定的度量类型来衡量查询向量与目标 Collections 中的向量之间的相似性,然后再返回与查询语义相似的向量。
还可以在搜索和查询中加入元数据过滤功能,以提高搜索结果的相关性。请注意,元数据过滤条件在查询中是必须的,但在搜索中是可选的。
- 基本 ANN 搜索
- 过滤搜索
- 范围搜索
- 分组搜索
- 混合搜索
- 搜索迭代器
- 查询
- 全文搜索
- 文本匹配
此外,Milvus 还提供了提高搜索性能和效率的增强功能。这些增强功能默认为禁用,您可以根据自己的服务要求启用和使用它们。它们是
- 使用 Partition Key
- 使用 mmap
- 集群压缩
2.7 分区
分区是集合的子集,与其父集合共享相同的字段集,每个分区包含一个实体子集。通过将实体分配到不同的分区,可以创建实体组。你可以在特定分区中进行搜索和查询,让 Milvus 忽略其他分区中的实体,提高搜索效率。
2.8 分片
分片是 Collections 的水平切片。每个分片对应一个数据输入通道。每个 Collections 默认都有一个分片。创建 Collections 时,可以根据预期吞吐量和要插入 Collections 的数据量设置适当的分片数量。
2.9 别名
可以为您的集合创建别名。一个集合可以有多个别名,但集合不能共享一个别名。收到针对某个 Collection 的请求后,Milvus 会根据所提供的名称定位该 Collection。如果所提供名称的 Collection 不存在,Milvus 会继续定位所提供名称的别名。你可以使用 Collections 别名来调整代码以适应不同的情况。
2.10 函数
您可以为 Milvus 设置函数,以便在创建 Collections 时派生字段。例如,全文搜索功能使用用户定义函数从特定 varchar 字段推导出稀疏向量字段。
2.11 一致性级别
分布式数据库系统通常使用一致性级别来定义跨数据节点和副本的数据相同性。在创建 Collections 或在 Collections 中进行相似性搜索时,可以分别设置不同的一致性级别。适用的一致性级别有强、有限制的不稳定性、会话和最终。