本文主要演示了如何使用阿里云向量检索服务Milvus版与通义千问VL大模型,提取图片特征,并使用多模态Embedding模型,快速实现多模态搜索。
基于灵积(Dashscope)模型服务上的通义千问 API以及Embedding API来接入图片、文本等非结构化数据Embedding为向量的能力。
通义千问VL大模型介绍《通义千问VL API详情》
通义多模态向量模型介绍《Multimodal-Embedding API详情》
前提条件
-
已创建阿里云Milvus实例。具体操作,请参见快速创建Milvus实例。
-
已开通服务并获得API-KEY。具体操作,请参见开通DashScope并创建API-KEY。
该示例的运行环境为python3.9
python3 -m pip install dashscope pymilvus==2.5.0
wget https://github.com/milvus-io/pymilvus-assets/releases/download/imagedata/reverse_image_search.zip
unzip -q -o reverse_image_search.zip
示例代码
在本文示例中,我们先将示例图片通过通义千问VL提取图片描述,存储在image_description中,然后将图片描述和图片通过多模态Embedding模型分别转换为向量存储在image_embedding和text_embedding中。
备注:在该示例中,仅以数据集前200张图片作为演示
import base64
import csv
import dashscope
import os
import pandas as pd
import sys
import time
from tqdm import tqdm
from pymilvus import (
connections,
FieldSchema,
CollectionSchema,
DataType,
Collection,
MilvusException,
utility,
)
from http import HTTPStatus
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class FeatureExtractor:
def __init__(self, DASHSCOPE_API_KEY):
self._api_key = DASHSCOPE_API_KEY # 使用环境变量存储API密钥
def __call__(self, input_data, input_type):
if input_type not in ("image", "text"):
raise ValueError("Invalid input type. Must be 'image' or 'text'.")
try:
if input_type == "image":
_, ext = os.path.splitext(input_data)
image_format = ext.lstrip(".").lower()
with open(input_data, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
input_data = f"data:image/{image_format};base64,{base64_image}"
payload = [{"image": input_data}]
else:
payload = [{"text": input_data}]
resp = dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=payload,
api_key=self._api_key,
)
if resp.status_code == HTTPStatus.OK:
return resp.output["embeddings"][0]["embedding"]
else:
raise RuntimeError(
f"API调用失败,状态码: {resp.status_code}, 错误信息: {resp.message}"
)
except Exception as e:
logger.error(f"处理失败: {str(e)}")
raise
class FeatureExtractorVL:
def __init__(self, DASHSCOPE_API_KEY):
self._api_key = DASHSCOPE_API_KEY # 使用环境变量存储API密钥
def __call__(self, input_data, input_type):
if input_type not in ("image"):
raise ValueError("Invalid input type. Must be 'image'.")
try:
if input_type == "image":
payload=[
{
"role": "system",
"content": [{"type":"text","text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
# {"image": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"},
{"image": input_data},
{"text": "先用50字内的文字描述这张图片,然后再给出5个关键词"}
],
}
]
resp = dashscope.MultiModalConversation.call(
model="qwen-vl-plus",
messages=payload,
api_key=self._api_key,
)
if resp.status_code == HTTPStatus.OK:
return resp.output["choices"][0]["message"].content[0]["text"]
else:
raise RuntimeError(
f"API调用失败,状态码: {resp.status_code}, 错误信息: {resp.message}"
)
except Exception as e:
logger.error(f"处理失败: {str(e)}")
raise
class MilvusClient:
def __init__(self, MILVUS_TOKEN, MILVUS_HOST, MILVUS_PORT, INDEX, COLLECTION_NAME):
self._token = MILVUS_TOKEN
self._host = MILVUS_HOST
self._port = MILVUS_PORT
self._index = INDEX
self._collection_name = COLLECTION_NAME
self._connect()
self._create_collection_if_not_exists()
def _connect(self):
try:
connections.connect(alias="default", host=self._host, port=self._port, token=self._token)
logger.info("Connected to Milvus successfully.")
except Exception as e:
logger.error(f"连接Milvus失败: {str(e)}")
sys.exit(1)
def _collection_exists(self):
return self._collection_name in utility.list_collections()
def _create_collection_if_not_exists(self):
try:
if not self._collection_exists():
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="origin", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="image_description", dtype=DataType.VARCHAR, max_length=1024),
FieldSchema(name="image_embedding", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldSchema(name="text_embedding", dtype=DataType.FLOAT_VECTOR, dim=1024)
]
schema = CollectionSchema(fields)
self._collection = Collection(self._collection_name, schema)
if self._index == 'IVF_FLAT':
self._create_ivf_index()
else:
self._create_hnsw_index()
logger.info("Collection created successfully.")
else:
self._collection = Collection(self._collection_name)
logger.info("Collection already exists.")
except Exception as e:
logger.error(f"创建或加载集合失败: {str(e)}")
sys.exit(1)
def _create_ivf_index(self):
index_params = {
"index_type": "IVF_FLAT",
"params": {
"nlist": 1024, # Number of clusters for the index
},
"metric_type": "L2",
}
self._collection.create_index("image_embedding", index_params)
self._collection.create_index("text_embedding", index_params)
logger.info("Index created successfully.")
def _create_hnsw_index(self):
index_params = {
"index_type": "HNSW",
"params": {
"M": 64, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 100, # Number of candidate neighbors considered for connection during index construction
},
"metric_type": "L2",
}
self._collection.create_index("image_embedding", index_params)
self._collection.create_index("text_embedding", index_params)
logger.info("Index created successfully.")
def insert(self, data):
try:
self._collection.insert(data)
self._collection.load()
logger.info("数据插入并加载成功.")
except MilvusException as e:
logger.error(f"插入数据失败: {str(e)}")
raise
def search(self, query_embedding, feild, limit=3):
try:
if self._index == 'IVF_FLAT':
param={"metric_type": "L2", "params": {"nprobe": 10}}
else:
param={"metric_type": "L2", "params": {"ef": 10}}
result = self._collection.search(
data=[query_embedding],
anns_field=feild,
param=param,
limit=limit,
output_fields=["origin", "image_description"],
)
return [{"id": hit.id, "distance": hit.distance, "origin": hit.origin, "image_description": hit.image_description} for hit in result[0]]
except Exception as e:
logger.error(f"搜索失败: {str(e)}")
return None
def load_image_embeddings(extractor, extractorVL, csv_path):
df = pd.read_csv(csv_path)
image_embeddings = {}
for image_path in tqdm(df["path"].tolist()[:200], desc="生成图像embedding"): # 仅用前100张图进行演示
try:
desc = extractorVL(image_path, "image")
image_embeddings[image_path] = [desc, extractor(image_path, "image"), extractor(desc, "text")]
time.sleep(1) # 控制API调用频率
except Exception as e:
logger.warning(f"处理{image_path}失败,已跳过: {str(e)}")
return [{"origin": k, 'image_description':v[0], "image_embedding": v[1], 'text_embedding': v[2]} for k, v in image_embeddings.items()]
数据准备
if __name__ == "__main__":
MILVUS_HOST = "c-xxxxxxxxxxxx.milvus.aliyuncs.com"
MILVUS_PORT = "19530"
MILVUS_TOKEN = "root:password"
COLLECTION_NAME = "multimodal_search"
INDEX = "IVF_FLAT" # IVF_FLAT OR HNSW
# Step1:初始化Milvus客户端
milvus_client = MilvusClient(MILVUS_TOKEN, MILVUS_HOST, MILVUS_PORT, INDEX, COLLECTION_NAME)
DASHSCOPE_API_KEY = ""
# Step2:初始化千问VL大模型与多模态Embedding模型
extractor = FeatureExtractor(DASHSCOPE_API_KEY)
extractorVL = FeatureExtractorVL(DASHSCOPE_API_KEY)
# Step3:将图片数据集Embedding后插入到Milvus
embeddings = load_image_embeddings(extractor, extractorVL, "reverse_image_search.csv")
milvus_client.insert(embeddings)
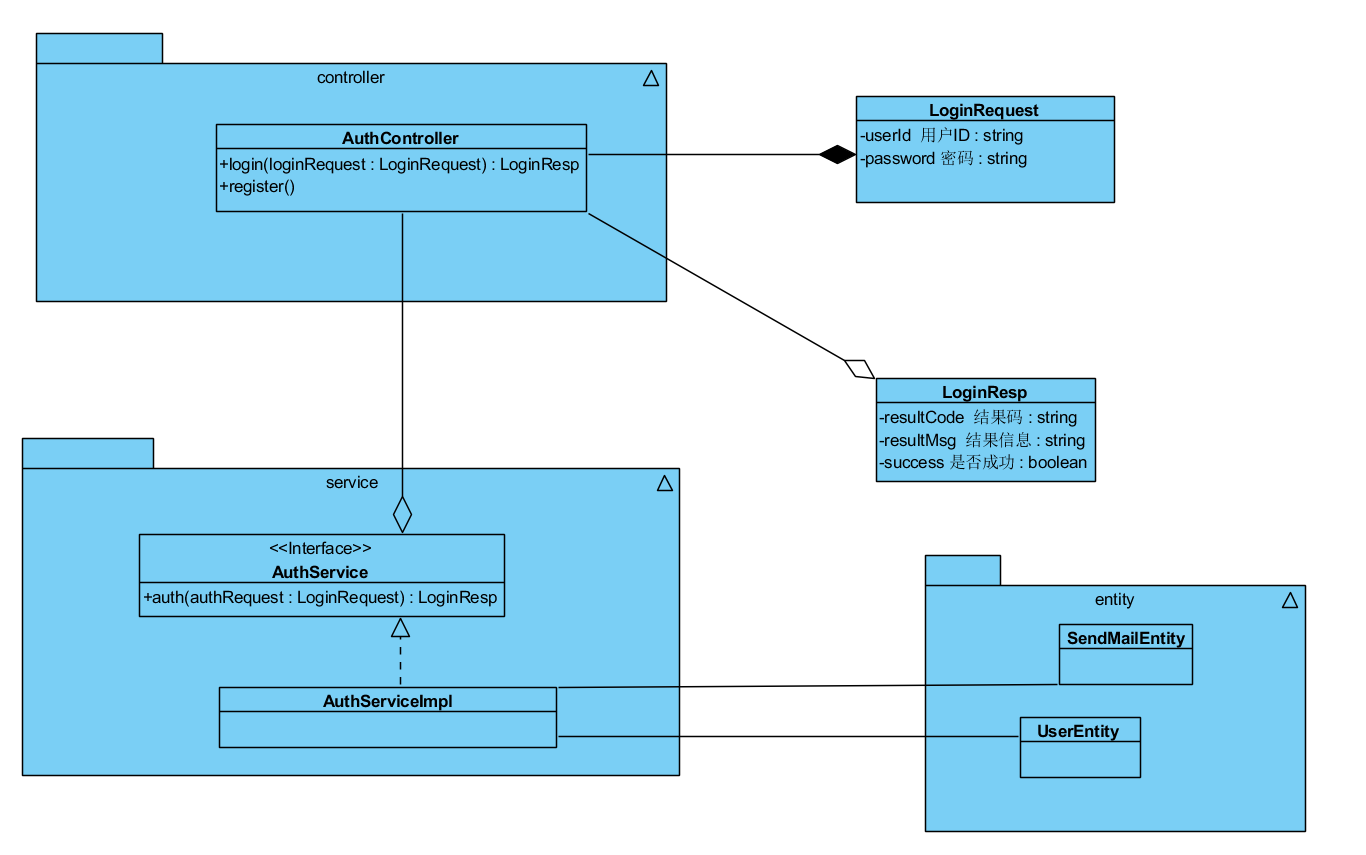
在Step1中将Collection创建完成后,可以在控制台登录Attu,查看Collection Schema信息,如下图所示。
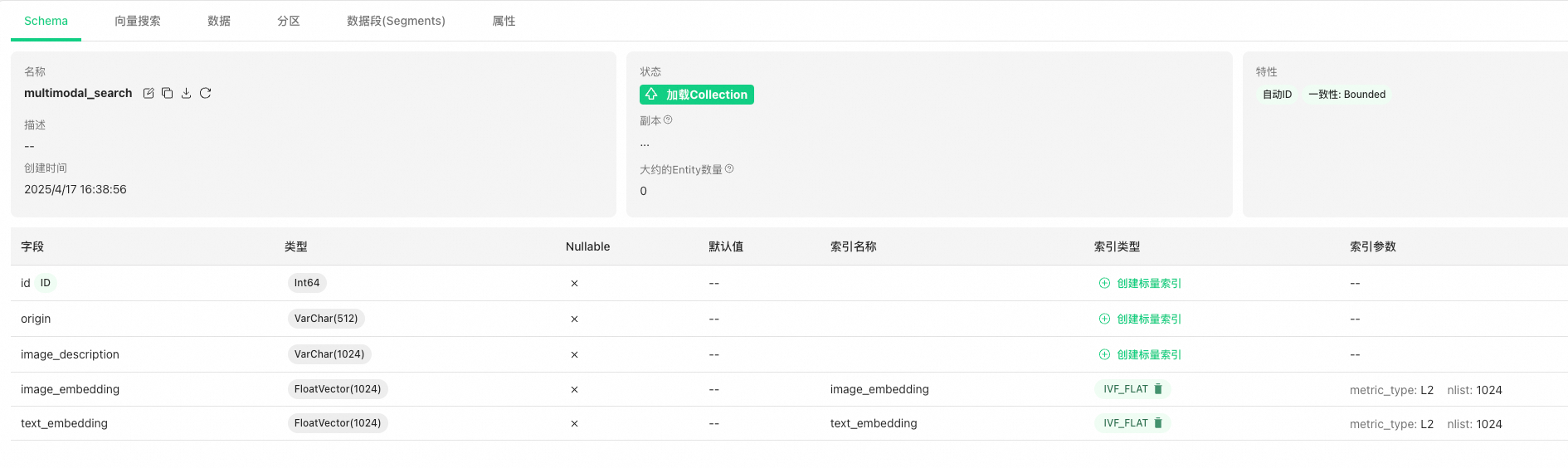
在完成Step3后,可以在Attu中查看插入数据,此时图片数据已经过通义千问VL大模型提取描述特征,并Embedding为向量。
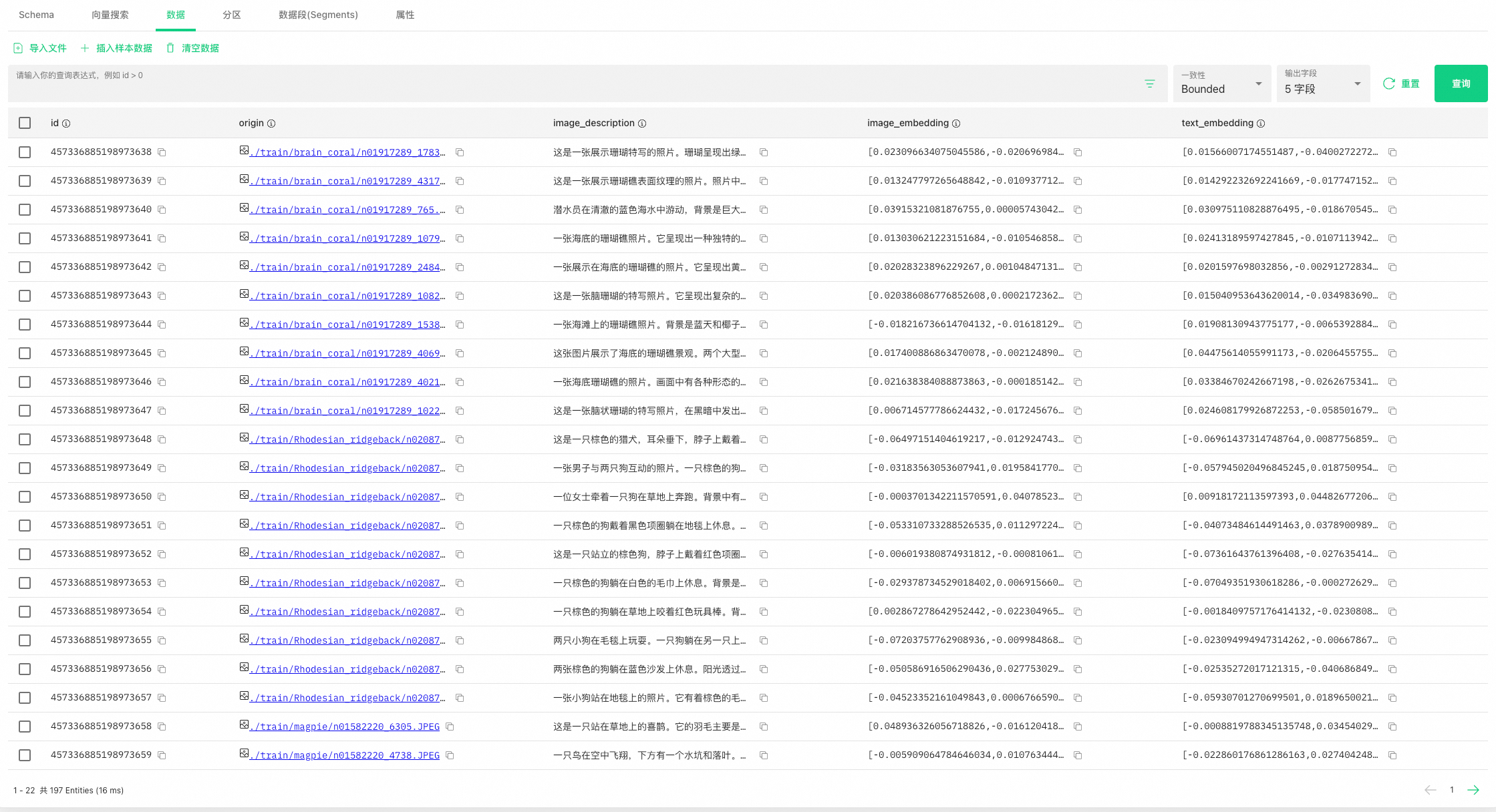
可以看出下图经过通义千问VL大模型提取后,文本总结为“站在海滩上的人穿着牛仔裤和绿色靴子。沙滩上有水迹覆盖。关键词:海滩、脚印、沙地、鞋子、裤子”,用文字非常形象的描述了这张图片的特征。

图:jean/n03594734_9714.JPEG
多模态量检索:以文搜图
在下面这个这个示例中,查询文本query为"棕色的狗",将query通过多模态向量模型Embedding以后,分别在image_embedding和text_embedding上进行以文搜图和以文搜文,可以得到不同的检索结果。
注意:由于大模型产出结果存在一定的随机性,本示例结果可能无法完全一致的复现。
if __name__ == "__main__":
MILVUS_HOST = "c-xxxxxxxxxxxx.milvus.aliyuncs.com"
MILVUS_PORT = "19530"
MILVUS_TOKEN = "root:password"
COLLECTION_NAME = "multimodal_search"
INDEX = "IVF_FLAT" # IVF_FLAT OR HNSW
# Step1:初始化Milvus客户端
milvus_client = MilvusClient(MILVUS_TOKEN, MILVUS_HOST, MILVUS_PORT, INDEX, COLLECTION_NAME)
DASHSCOPE_API_KEY = ""
# Step2:初始化多模态Embedding模型
extractor = FeatureExtractor(DASHSCOPE_API_KEY)
# Step4:多模态搜索示例,以文搜图和以文搜文
text_query = "棕色的狗"
text_embedding = extractor(text_query, "text")
text_results_1 = milvus_client.search(text_embedding, feild = 'image_embedding')
logger.info(f"以文搜图查询结果: {text_results_1}")
text_results_2 = milvus_client.search(text_embedding, feild = 'text_embedding')
logger.info(f"以文搜文查询结果: {text_results_2}")
"""
以文搜图查询结果
{'id': 457336885198973657, 'distance': 1.338853359222412, 'origin': './train/Rhodesian_ridgeback/n02087394_9675.JPEG', 'image_description': '一张小狗站在地毯上的照片。它有着棕色的毛发和蓝色的眼睛。\n关键词:小狗、地毯、眼睛、毛色、站立'},
{'id': 457336885198973648, 'distance': 1.3568601608276367, 'origin': './train/Rhodesian_ridgeback/n02087394_6382.JPEG', 'image_description': '这是一只棕色的猎犬,耳朵垂下,脖子上戴着项圈。它正直视前方。\n\n关键词:狗、棕色、猎犬、耳朵、项链'},
{'id': 457336885198973655, 'distance': 1.3838427066802979, 'origin': './train/Rhodesian_ridgeback/n02087394_5846.JPEG', 'image_description': '两只小狗在毛毯上玩耍。一只狗躺在另一只上面,背景中有一个玩具熊。\n\n关键词:小狗、玩闹、毛毯、玩具熊、互动'}
"""
"""
以文搜文查询结果
[{'id': 457336885198973739, 'distance': 0.6969608068466187, 'origin': './train/mongoose/n02137549_7552.JPEG', 'image_description': '这是一张棕色的小动物的特写照片。它有着圆润的脸庞和大大的眼睛。\n\n关键词:小动物、棕毛、圆形脸、大眼、自然背景'},
{'id': 457336885198973648, 'distance': 0.7110348343849182, 'origin': './train/Rhodesian_ridgeback/n02087394_6382.JPEG', 'image_description': '这是一只棕色的猎犬,耳朵垂下,脖子上戴着项圈。它正直视前方。\n\n关键词:狗、棕色、猎犬、耳朵、项链'},
{'id': 457336885198973707, 'distance': 0.7725887298583984, 'origin': './train/lion/n02129165_19310.JPEG', 'image_description': '这是一张狮子的特写照片。它有着浓密的鬃毛和锐利的眼神。\n\n关键词:狮子、眼神、鬃毛、自然环境、野生动物'}
"""
多模态向量检索:以图搜文
在下面这个这个示例中,我们使用test中的狮子图片进行相似性检索,分别进行以图搜图和以图搜文。

图:lion/n02129165_13728.JPEG
注意:由于大模型产出结果存在一定的随机性,本示例结果可能无法完全一致的复现。
if __name__ == "__main__":
MILVUS_HOST = "c-xxxxxxxxxxxx.milvus.aliyuncs.com"
MILVUS_PORT = "19530"
MILVUS_TOKEN = "root:password"
COLLECTION_NAME = "multimodal_search"
INDEX = "IVF_FLAT" # IVF_FLAT OR HNSW
# Step1:初始化Milvus客户端
milvus_client = MilvusClient(MILVUS_TOKEN, MILVUS_HOST, MILVUS_PORT, INDEX, COLLECTION_NAME)
DASHSCOPE_API_KEY = ""
# Step2:初始化多模态Embedding模型
extractor = FeatureExtractor(DASHSCOPE_API_KEY)
# Step5:多模态搜索示例,以图搜图和以图搜文
image_query_path = "./test/lion/n02129165_13728.JPEG"
image_embedding = extractor(image_query_path, "image")
image_results_1 = milvus_client.search(image_embedding, feild = 'image_embedding')
logger.info(f"以图搜图查询结果: {image_results_1}")
image_results_2 = milvus_client.search(image_embedding, feild = 'text_embedding')
logger.info(f"以图搜文查询结果: {image_results_2}")
"""
以图搜图查询结果
{'id': 457336885198973702, 'distance': 0.23892249166965485, 'origin': './train/lion/n02129165_19953.JPEG', 'image_description': '这是一只雄壮的狮子站在岩石旁,背景是树木和灌木丛。阳光洒在它的身上。\n\n关键词:狮子、岩石、森林、阳光、野性'},
{'id': 457336885198973704, 'distance': 0.4113130569458008, 'origin': './train/lion/n02129165_1142.JPEG', 'image_description': '一只狮子在茂密的绿色植物中休息。背景是竹子和树木。\n\n关键词:狮子、草地、绿植、树干、自然环境'},
{'id': 457336885198973699, 'distance': 0.5206397175788879, 'origin': './train/lion/n02129165_16.JPEG', 'image_description': '图中是一对狮子在草地上站立。雄狮鬃毛浓密,雌狮则显得更为瘦弱。\n\n关键词:狮子、草地、雄性、雌性、自然环境'}
"""
"""
以图搜文查询结果
{'id': 457336885198973704, 'distance': 1.0935896635055542, 'origin': './train/lion/n02129165_1142.JPEG', 'image_description': '一只狮子在茂密的绿色植物中休息。背景是竹子和树木。\n\n关键词:狮子、草地、绿植、树干、自然环境'},
{'id': 457336885198973702, 'distance': 1.2102885246276855, 'origin': './train/lion/n02129165_19953.JPEG', 'image_description': '这是一只雄壮的狮子站在岩石旁,背景是树木和灌木丛。阳光洒在它的身上。\n\n关键词:狮子、岩石、森林、阳光、野性'},
{'id': 457336885198973707, 'distance': 1.2725986242294312, 'origin': './train/lion/n02129165_19310.JPEG', 'image_description': '这是一张狮子的特写照片。它有着浓密的鬃毛和锐利的眼神。\n\n关键词:狮子、眼神、鬃毛、自然环境、野生动物'}
"""
import base64
import csv
import dashscope
import os
import pandas as pd
import sys
import time
from tqdm import tqdm
from pymilvus import (
connections,
FieldSchema,
CollectionSchema,
DataType,
Collection,
MilvusException,
utility
)
from http import HTTPStatus
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class FeatureExtractor:
def __init__(self):
self._api_key = os.getenv("DASHSCOPE_API_KEY") # 使用环境变量存储API密钥
def __call__(self, input_data, input_type):
if input_type not in ("image", "text"):
raise ValueError("Invalid input type. Must be 'image' or 'text'.")
try:
if input_type == "image":
_, ext = os.path.splitext(input_data)
image_format = ext.lstrip(".").lower()
with open(input_data, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
input_data = f"data:image/{image_format};base64,{base64_image}"
payload = [{"image": input_data}]
else:
payload = [{"text": input_data}]
resp = dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=payload,
api_key=self._api_key,
)
if resp.status_code == HTTPStatus.OK:
return resp.output["embeddings"][0]["embedding"]
else:
raise RuntimeError(
f"API调用失败,状态码: {resp.status_code}, 错误信息: {resp.message}"
)
except Exception as e:
logger.error(f"处理失败: {str(e)}")
raise
class MilvusClient:
def __init__(self):
self._token = os.getenv("MILVUS_TOKEN")
self._host = os.getenv("MILVUS_HOST")
self._port = os.getenv("MILVUS_PORT", "19530")
self._collection_name = "multimodal_search"
self._connect()
self._create_collection_if_not_exists()
def _connect(self):
try:
connections.connect(alias="default", host=self._host, port=self._port, token=self._token)
logger.info("Connected to Milvus successfully.")
except Exception as e:
logger.error(f"连接Milvus失败: {str(e)}")
sys.exit(1)
def _collection_exists(self):
return self._collection_name in utility.list_collections()
def _create_index(self):
index_params = {
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
"metric_type": "L2",
}
self._collection.create_index("embedding", index_params)
logger.info("Index created successfully.")
def _create_collection_if_not_exists(self):
try:
if not self._collection_exists():
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldSchema(name="origin", dtype=DataType.VARCHAR, max_length=512),
]
schema = CollectionSchema(fields)
self._collection = Collection(self._collection_name, schema)
self._create_index()
logger.info("Collection created successfully.")
else:
self._collection = Collection(self._collection_name)
logger.info("Collection already exists.")
except Exception as e:
logger.error(f"创建或加载集合失败: {str(e)}")
sys.exit(1)
def insert(self, data):
try:
self._collection.insert(data)
self._collection.load()
logger.info("数据插入并加载成功.")
except MilvusException as e:
logger.error(f"插入数据失败: {str(e)}")
raise
def search(self, query_embedding, limit=10):
try:
result = self._collection.search(
data=[query_embedding],
anns_field="embedding",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=limit,
output_fields=["origin"],
)
return [{"id": hit.id, "distance": hit.distance, "origin": hit.origin} for hit in result[0]]
except Exception as e:
logger.error(f"搜索失败: {str(e)}")
return None
def load_image_embeddings(extractor, csv_path):
df = pd.read_csv(csv_path)
image_embeddings = {}
for image_path in tqdm(df["path"].tolist(), desc="生成图像嵌入"):
try:
image_embeddings[image_path] = extractor(image_path, "image")
time.sleep(0.6) # 控制API调用频率
except Exception as e:
logger.warning(f"处理{image_path}失败,已跳过: {str(e)}")
return [{"origin": k, "embedding": v} for k, v in image_embeddings.items()]
def main():
# 初始化Milvus客户端
milvus_client = MilvusClient()
# 初始化特征提取器
extractor = FeatureExtractor()
## 1. 将图片数据集Embedding后插入到Milvus
embeddings = load_image_embeddings(extractor, "reverse_image_search.csv")
milvus_client.insert(embeddings)
# 2. 执行搜索测试
# 示例:以文搜图
text_query = "木质折叠椅"
text_embedding = extractor(text_query, "text")
text_results = milvus_client.search(text_embedding)
logger.info(f"以文搜图查询结果: {text_results}")
# 示例:以图搜图
image_query_path = "./test/Airedale/n02096051_4092.JPEG"
image_embedding = extractor(image_query_path, "image")
image_results = milvus_client.search(image_embedding)
logger.info(f"以图搜图查询结果: {image_results}")
if __name__ == "__main__":
main()