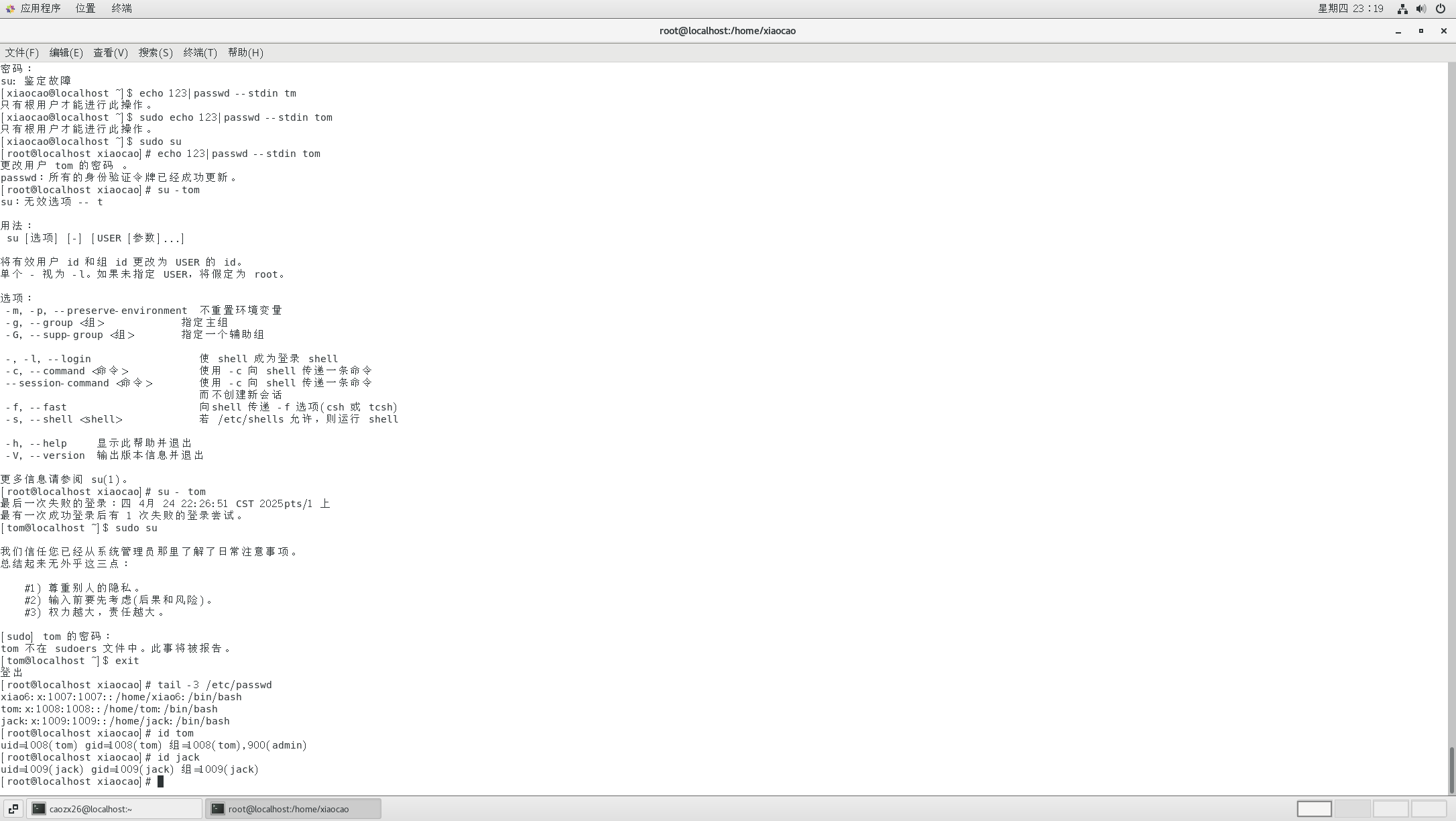
我们将BASE_URL 设置为 "https://oi-wiki.org/" 后脚本就会自动开始抓取该url及其子页面的所有内容,并将统一子页面的放在一个文件夹中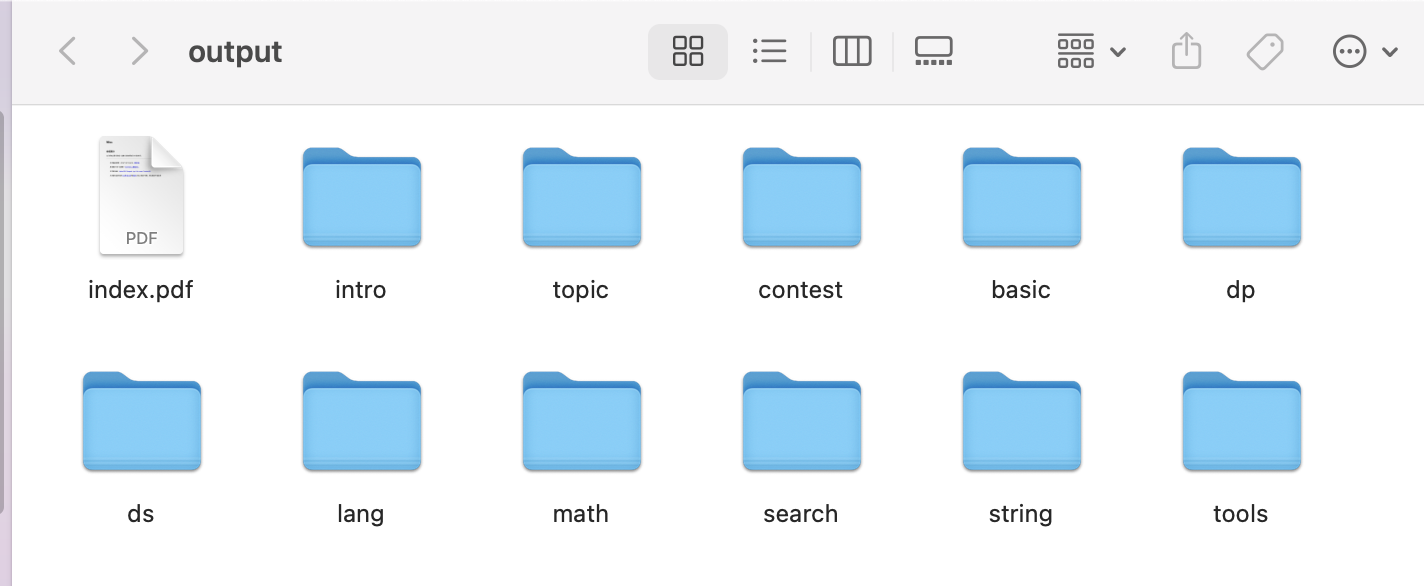
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import os
import pdfkit
from urllib3.exceptions import InsecureRequestWarning
# 禁用SSL警告
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
# 配置wkhtmltopdf路径
config = pdfkit.configuration(wkhtmltopdf='/usr/local/bin/wkhtmltopdf')
BASE_URL = "https://oi-wiki.org/"
DOMAIN = urlparse(BASE_URL).netloc
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9"
}
visited = set()
queue = [BASE_URL]
def is_valid_url(url):
parsed = urlparse(url)
return (
parsed.netloc == DOMAIN and
not parsed.fragment and
not url.endswith(('.zip', '.pdf', '.jpg', '.png'))
)
def extract_links(html, base_url):
soup = BeautifulSoup(html, 'html.parser')
links = []
for a in soup.find_all('a', href=True):
full_url = urljoin(base_url, a['href']).split('#')[0]
if is_valid_url(full_url) and full_url not in visited:
links.append(full_url)
visited.add(full_url)
return links
def fetch_page(url):
try:
print(f"[*] 抓取中: {url}")
res = requests.get(url, headers=headers, verify=False, timeout=30)
res.encoding = 'utf-8'
return res.text
except Exception as e:
print(f"[!] 抓取失败: {url} - {str(e)}")
return None
def clean_html(html, url):
soup = BeautifulSoup(html, 'html.parser')
# 移除所有顶部导航和侧边栏相关元素
for tag in soup.select('.navbar, .page-toc, .sidebar, footer, .giscus, .page-footer, .page-actions'):
tag.decompose()
# 仅保留主内容区域
main_content = soup.select_one('main article') or soup.select_one('article') or soup
# 修正资源路径
for tag in main_content.find_all(['img', 'a']):
for attr in ['href', 'src']:
if tag.has_attr(attr):
tag[attr] = urljoin(url, tag[attr])
# 获取有效标题(使用最后一个有效路径段)
title_parts = urlparse(url).path.strip('/').split('/')
title = title_parts[-1].replace('-', ' ').title() if title_parts else "Document"
return f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>{title}</title>
<style>
body {{
font-family: 'Noto Sans CJK SC', Arial, sans-serif;
line-height: 1.6;
margin: 2em;
}}
/* 保持原有样式 */
</style>
</head>
<body>
<h1>{title}</h1>
{main_content}
</body>
</html>
"""
def save_as_pdf(html, url):
parsed = urlparse(url)
path_segments = [seg for seg in parsed.path.strip('/').split('/') if seg]
if len(path_segments) > 1:
dir_path = os.path.join('output', *path_segments[:-1])
filename = f"{path_segments[-1]}.pdf"
else:
dir_path = 'output'
filename = "index.pdf"
os.makedirs(dir_path, exist_ok=True)
full_path = os.path.join(dir_path, filename)
try:
pdfkit.from_string(html, full_path, configuration=config, options={
'encoding': "UTF-8",
'enable-local-file-access': None,
'quiet': '' # 隐藏控制台输出
})
print(f"[√] 已保存: {full_path}")
except Exception as e:
print(f"[!] PDF生成失败: {full_path} - {str(e)}")
def crawl():
while queue:
current_url = queue.pop(0)
html = fetch_page(current_url)
if not html:
continue
new_links = extract_links(html, current_url)
queue.extend(new_links)
cleaned_html = clean_html(html, current_url)
save_as_pdf(cleaned_html, current_url)
if __name__ == "__main__":
print("🚀 启动爬虫,目标站点:", BASE_URL)
visited.add(BASE_URL)
crawl()
print("✅ 所有内容已保存至 output/ 目录")