1.CPA介绍
CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。
关于CPA-Enhancer的详细介绍可以看论文:[2403.11220v3] CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations

Input Image
│
▼
[Conv + BN + ReLU](通用预处理)
│
├─► 分支1:多尺度卷积提取
├─► 分支2:亮度补偿模块
├─► 分支3:注意力增强机制(通道注意力+空间注意力)
└─► 分支4:上下文结构感知(Transformer 模块等)
│
▼
[特征融合 + 残差连接]
│
▼
Enhanced Feature Map → YOLOv8 Backbone
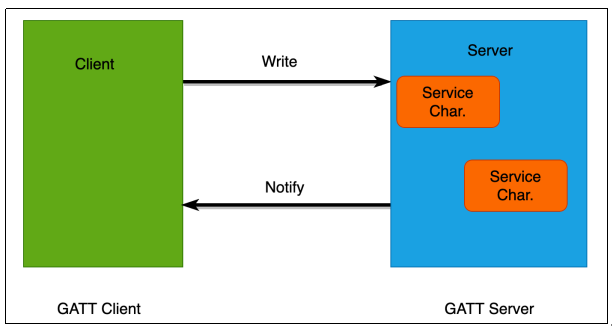
CPA 处理图像的核心机制
1. 多尺度特征提取(Multi-Scale Extraction)
- 使用多个不同尺寸的卷积核(如 1x1, 3x3, 5x5)或金字塔结构提取局部+全局特征;
- 有效增强图像纹理信息和边缘结构;
- 防止小目标被弱特征淹没。
2. 亮度与对比度增强(Light & Contrast Enhancement)
- 模仿传统图像增强方法(如 CLAHE、Gamma 校正等)思想,但使用神经网络完成:
-
- 网络自动学习一套光照补偿策略;
- 增强图像暗部细节;
- 保留高光部分结构。
3. 上下文感知(Context-Aware Attention)
- 利用注意力机制(如 SE、CBAM、Transformer-style Attention)增强重要区域;
- 学习图像中哪些部分应该被重点关注(如前景物体、边缘);
- 抑制背景冗余信息。
4. 结构保留增强(Structure-Aware Enhancement)
- 保持图像结构(如边缘、角点)不被模糊化;
- 可能引入边缘检测或梯度引导模块,增强空间纹理信息;
- 可引入残差连接,减少特征漂移。
2.将CPA-Enhancer融合进YOLOv8
2.1 步骤一:放代码
首先找到如下的目录'ultralytics/nn',然后在这个目录下创建一个'Addmodules'文件夹,然后在这个目录下创建一个Enhancer.py文件,文件名字可以根据你自己的习惯起,然后将CPA-Enhancer的核心代码复制进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numbers
from einops import rearrange
from einops.layers.torch import Rearrange
__all__ = ['CPA_arch']
class RFAConv(nn.Module): # 基于Group Conv实现的RFAConv
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1):
super().__init__()
self.kernel_size = kernel_size
self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1,
groups=in_channel, bias=False))
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2,
stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU())
self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self, x):
b, c = x.shape[0:2]
weight = self.get_weight(x)
h, w = weight.shape[2:]
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h w
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h,
w) # b c*kernel**2,h,w -> b c k**2 h w 获得感受野空间特征
weighted_data = feature * weighted
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,
# b c k**2 h w -> b c h*k w*k
n2=self.kernel_size)
return self.conv(conv_data)
class Downsample(nn.Module):
def __init__(self, n_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2))
def forward(self, x):
return self.body(x)
class Upsample(nn.Module):
def __init__(self, n_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat * 2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2))
def forward(self, x): # (b,c,h,w)
return self.body(x) # (b,c/2,h*2,w*2)
class SpatialAttention(nn.Module):
def __init__(self):
super(SpatialAttention, self).__init__()
self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect', bias=True)
def forward(self, x): # x:[b,c,h,w]
x_avg = torch.mean(x, dim=1, keepdim=True) # (b,1,h,w)
x_max, _ = torch.max(x, dim=1, keepdim=True) # (b,1,h,w)
x2 = torch.concat([x_avg, x_max], dim=1) # (b,2,h,w)
sattn = self.sa(x2) # 7x7conv (b,1,h,w)
return sattn * x
class ChannelAttention(nn.Module):
def __init__(self, dim, reduction=8):
super(ChannelAttention, self).__init__()
self.gap = nn.AdaptiveAvgPool2d(1)
self.ca = nn.Sequential(
nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True), # Relu
nn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True),
)
def forward(self, x): # x:[b,c,h,w]
x_gap = self.gap(x) # [b,c,1,1]
cattn = self.ca(x_gap) # [b,c,1,1]
return cattn * x
class Channel_Shuffle(nn.Module):
def __init__(self, num_groups):
super(Channel_Shuffle, self).__init__()
self.num_groups = num_groups
def forward(self, x):
batch_size, chs, h, w = x.shape
chs_per_group = chs // self.num_groups
x = torch.reshape(x, (batch_size, self.num_groups, chs_per_group, h, w))
# (batch_size, num_groups, chs_per_group, h, w)
x = x.transpose(1, 2) # dim_1 and dim_2
out = torch.reshape(x, (batch_size, -1, h, w))
return out
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):
super(TransformerBlock, self).__init__()
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.attn = Attention(dim, num_heads, bias)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
def to_4d(x, h, w):
return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma + 1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
device = x.device
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
result = (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight.to(device) + self.bias.to(device)
return result
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type == 'BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim * ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,
groups=hidden_features * 2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
device = x.device
self.project_in = self.project_in.to(device)
self.dwconv = self.dwconv.to(device)
self.project_out = self.project_out.to(device)
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1, dtype=torch.float32), requires_grad=True)
self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3,
bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b, c, h, w = x.shape
device = x.device
self.qkv = self.qkv.to(device)
self.qkv_dwconv = self.qkv_dwconv.to(device)
self.project_out = self.project_out.to(device)
qkv = self.qkv(x)
qkv = self.qkv_dwconv(qkv)
q, k, v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature.to(device)
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
class resblock(nn.Module):
def __init__(self, dim):
super(resblock, self).__init__()
# self.norm = LayerNorm(dim, LayerNorm_type='BiasFree')
self.body = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False),
nn.PReLU(),
nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False))
def forward(self, x):
res = self.body((x))
res += x
return res
#########################################################################
# Chain-of-Thought Prompt Generation Module (CGM)
class CotPromptParaGen(nn.Module):
def __init__(self,prompt_inch,prompt_size, num_path=3):
super(CotPromptParaGen, self).__init__()
# (128,32,32)->(64,64,64)->(32,128,128)
self.chain_prompts=nn.ModuleList([
nn.ConvTranspose2d(
in_channels=prompt_inch if idx==0 else prompt_inch//(2**idx),
out_channels=prompt_inch//(2**(idx+1)),
kernel_size=3, stride=2, padding=1
) for idx in range(num_path)
])
def forward(self,x):
prompt_params = []
prompt_params.append(x)
for pe in self.chain_prompts:
x=pe(x)
prompt_params.append(x)
return prompt_params
#########################################################################
# Content-driven Prompt Block (CPB)
class ContentDrivenPromptBlock(nn.Module):
def __init__(self, dim, prompt_dim, reduction=8, num_splits=4):
super(ContentDrivenPromptBlock, self).__init__()
self.dim = dim
self.num_splits = num_splits
self.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect', groups=dim, bias=True)
self.sigmoid = nn.Sigmoid()
self.conv3x3 = nn.Conv2d(prompt_dim, prompt_dim, kernel_size=3, stride=1, padding=1, bias=False)
self.conv1x1 = nn.Conv2d(dim, prompt_dim, kernel_size=1, stride=1, bias=False)
self.sa = SpatialAttention()
self.ca = ChannelAttention(dim, reduction)
self.myshuffle = Channel_Shuffle(2)
self.out_conv1 = nn.Conv2d(prompt_dim + dim, dim, kernel_size=1, stride=1, bias=False)
self.transformer_block = [
TransformerBlock(dim=dim // num_splits, num_heads=1, ffn_expansion_factor=2.66, bias=False,
LayerNorm_type='WithBias') for _ in range(num_splits)]
def forward(self, x, prompt_param):
# latent: (b,dim*8,h/8,w/8) prompt_param3: (1, 256, 16, 16)
x_ = x
B, C, H, W = x.shape
cattn = self.ca(x) # channel-wise attn
sattn = self.sa(x) # spatial-wise attn
pattn1 = sattn + cattn
pattn1 = pattn1.unsqueeze(dim=2) # [b,c,1,h,w]
x = x.unsqueeze(dim=2) # [b,c,1,h,w]
x2 = torch.cat([x, pattn1], dim=2) # [b,c,2,h,w]
x2 = Rearrange('b c t h w -> b (c t) h w')(x2) # [b,c*2,h,w]
x2 = self.myshuffle(x2) # [c1,c1_att,c2,c2_att,...]
pattn2 = self.pa2(x2)
pattn2 = self.conv1x1(pattn2) # [b,prompt_dim,h,w]
prompt_weight = self.sigmoid(pattn2) # Sigmod
prompt_param = F.interpolate(prompt_param, (H, W), mode="bilinear")
# (b,prompt_dim,prompt_size,prompt_size) -> (b,prompt_dim,h,w)
prompt = prompt_weight * prompt_param
prompt = self.conv3x3(prompt) # (b,prompt_dim,h,w)
inter_x = torch.cat([x_, prompt], dim=1) # (b,prompt_dim+dim,h,w)
inter_x = self.out_conv1(inter_x) # (b,dim,h,w) dim=64
splits = torch.split(inter_x, self.dim // self.num_splits, dim=1)
transformered_splits = []
for i, split in enumerate(splits):
transformered_split = self.transformer_block[i](split)
transformered_splits.append(transformered_split)
result = torch.cat(transformered_splits, dim=1)
return result
#########################################################################
# CPA_Enhancer
class CPA_arch(nn.Module):
def __init__(self, c_in=3, c_out=3, dim=4, prompt_inch=128, prompt_size=32):
super(CPA_arch, self).__init__()
self.conv0 = RFAConv(c_in, dim)
self.conv1 = RFAConv(dim, dim)
self.conv2 = RFAConv(dim * 2, dim * 2)
self.conv3 = RFAConv(dim * 4, dim * 4)
self.conv4 = RFAConv(dim * 8, dim * 8)
self.conv5 = RFAConv(dim * 8, dim * 4)
self.conv6 = RFAConv(dim * 4, dim * 2)
self.conv7 = RFAConv(dim * 2, c_out)
self.down1 = Downsample(dim)
self.down2 = Downsample(dim * 2)
self.down3 = Downsample(dim * 4)
self.prompt_param_ini = nn.Parameter(torch.rand(1, prompt_inch, prompt_size, prompt_size)) # (b,c,h,w)
self.myPromptParamGen = CotPromptParaGen(prompt_inch=prompt_inch,prompt_size=prompt_size)
self.prompt1 = ContentDrivenPromptBlock(dim=dim * 2 ** 1, prompt_dim=prompt_inch // 4, reduction=8) # !!!!
self.prompt2 = ContentDrivenPromptBlock(dim=dim * 2 ** 2, prompt_dim=prompt_inch // 2, reduction=8)
self.prompt3 = ContentDrivenPromptBlock(dim=dim * 2 ** 3, prompt_dim=prompt_inch , reduction=8)
self.up3 = Upsample(dim * 8)
self.up2 = Upsample(dim * 4)
self.up1 = Upsample(dim * 2)
def forward(self, x): # (b,c_in,h,w)
prompt_params = self.myPromptParamGen(self.prompt_param_ini)
prompt_param1 = prompt_params[2] # [1, 64, 64, 64]
prompt_param2 = prompt_params[1] # [1, 128, 32, 32]
prompt_param3 = prompt_params[0] # [1, 256, 16, 16]
x0 = self.conv0(x) # (b,dim,h,w)
x1 = self.conv1(x0) # (b,dim,h,w)
x1_down = self.down1(x1) # (b,dim,h/2,w/2)
x2 = self.conv2(x1_down) # (b,dim,h/2,w/2)
x2_down = self.down2(x2)
x3 = self.conv3(x2_down)
x3_down = self.down3(x3)
x4 = self.conv4(x3_down)
device = x4.device
self.prompt1 = self.prompt1.to(device)
self.prompt2 = self.prompt2.to(device)
self.prompt3 = self.prompt3.to(device)
x4_prompt = self.prompt3(x4, prompt_param3)
x3_up = self.up3(x4_prompt)
x5 = self.conv5(torch.cat([x3_up, x3], 1))
x5_prompt = self.prompt2(x5, prompt_param2)
x2_up = self.up2(x5_prompt)
x2_cat = torch.cat([x2_up, x2], 1)
x6 = self.conv6(x2_cat)
x6_prompt = self.prompt1(x6, prompt_param1)
x1_up = self.up1(x6_prompt)
x7 = self.conv7(torch.cat([x1_up, x1], 1))
return x7
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 3, 640, 640)
image = torch.rand(*image_size)
out = CPA_arch(3, 3, 4)
out = out(image)
print(out.size())2.2 步骤二:告诉 YOLOv8 有新东西
在Addmodules下创建一个新的py文件名字为'__init__.py',然后在其内部添加如下代码

2.3 步骤三:让 YOLOv8 认识新工具
在task.py进行导入
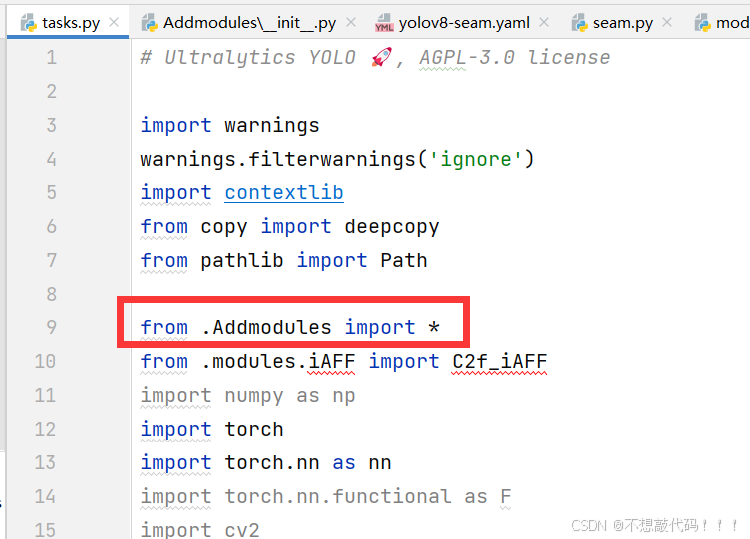
到此注册成功
2.4 步骤四:改 YOLOv8 的“说明书”
复制后面的yaml文件直接运行即可
yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, CPA_arch, []] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 8-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)