目录
一、范式
二、第一范式
二、第二范式
三、第三范式
四、设计
(1)一对一关系
(2)一对多关系
(3)多对多关系
一、范式
数据库的范式是一种规则(规范),如果我们想要设计出合理的关系型数据库,我们就要遵守这些不同的规范,而这些不同的规范要求又被称之为范式。
在我们的关系型数据库中有着六种范式:第一范式(1NF)、第二范式(2NF)、第三范(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF,又称完美范式)。
在这些不同的范式中我们认为越高的范式,数据库的冗余就越小,因此普遍认为范式越高对数据之间的关系有着更好的约束性,但是这种更高的范式也可能会导致我们数据库的IO更加繁忙,因此在我们的实际开发中,我们的数据库设计只需要满足第三范式即可。
二、第一范式
定义:数据库表中的每一列都是不可分割的原子数据项,它们不能是集合,数组 ,对象等非原子数据。
注意:在关系型数据库的设计中,满足第一范式是对关系模式的基本要求。不满足第一范式的数据库就不能被称为关系数据库。
如果我们单看完定义,我们可能不太了解什么是不可分割的原子项。我们接下来可以举一个简单的例子,我们设计一张学生表,在这个学生表中,存有我们的学生的个人信息和学校信息。

我们设计出了这样的一个学生表,我们观察这个学生表的每一个列,我们可以发现,在我们的学校这一列,它其实是一个对象,是可以继续进行拆分的,我们可以将他拆分为:学校名,学校地址,学校电话,邮箱等等这些项,因此在这种还存在可以继续往下拆分的列时,我们称这个学生表是不满足第一范式的。
那么,如果我们想要让我们这张学生表是满足第一范式的话,我们该怎么做呢,其实很简单,我们只需要将我们的学校列用拆分好的列进行替代即可。
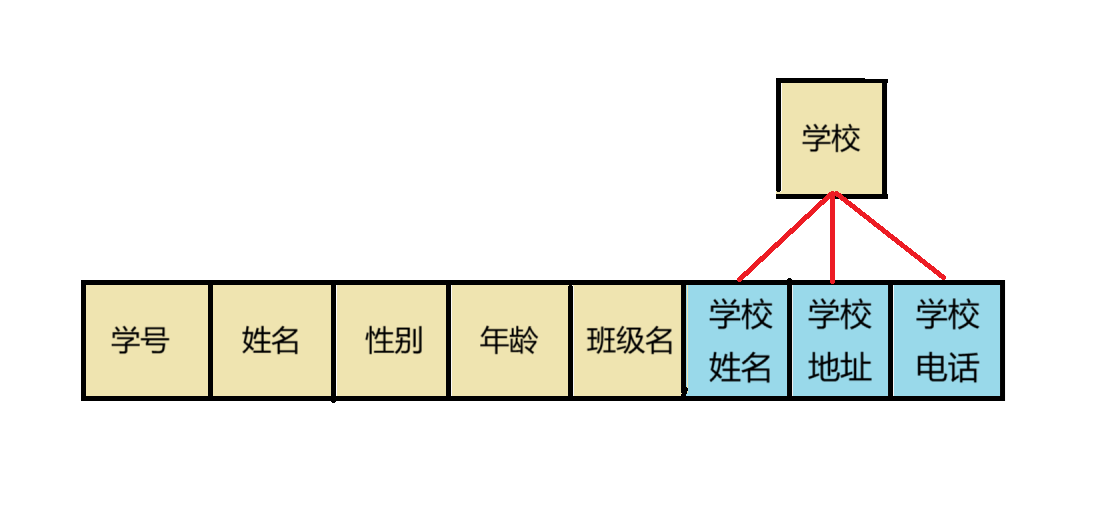
此时这样的一张新的学生表就是满足我们的第一范式了,同时我们发现我们此时的这张表的所有列都可以用基本数据类型进行表示,那么我们就可以认为,在我们的关系型数据库中如果我们的每一个列都可以用基本数据类型进行表示,那么我们就说他是天然满足第一范式的。
二、第二范式
定义:在满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖。如果我们的表中在定义了复合主键的情况下,存在部分函数依赖,我们就说它不满足第二范式。
候选键:可以唯一标识一行数据的列或列的组合,可以从候选键中选一个或者多个当做表的主键。
根据我们的定义来看,我们可能并不了解,我们其实可以对这个定义进行一个简化,那就是:在满足第一范式(1NF)的情况下,表中的每一个非主键字段都是完全函数依赖于主键字段的。
当然,在这里可能有有所迷惑什么是完全函数依赖,我们接下来可以举一个例子来解释,我们设计一张成绩表,在这张表中存入我们的学生信息,学生课程,和学生所获课程学分和成绩。在这张表中我们将学号+课程名定义成复合主键
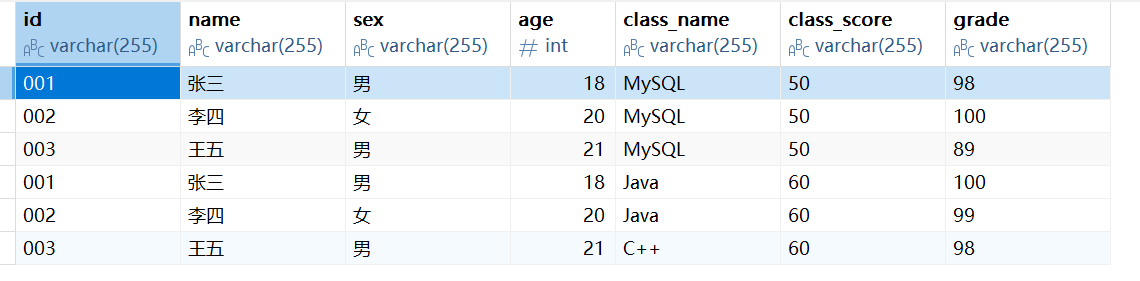
但是在这张表中我们其实可以发现,我们学生信息(学生信息中除主键外的字段)是靠我们的学号这个字段来标识的,而我们的课程信息是靠课程名这个字段标识的,我们的成绩是靠这个两个字段标识的。 在这种非主键字段,不是全部依赖一个整个主键字段而是依赖主键中部分列的情况,我们就说他存在部分函数依赖,因此它是不满足第二范式的。
并且在这种不满足部分函数依赖的情况下,它会导致许多的问题,而这些问题也就是我们为什么要引入范式的原因。
不满足第二范式可能会出现的问题,我们还是以上面设计的这张学生表来说明问题。
1、数据冗余
在上面这张表中,我们其实可以看到学生的信息在每一行中会重复出现,例如第一行和第四行的学生信息。
2、更新异常
例如如果我们要去调整Java的学分,那么我们就要更新表中所有Java的学分,但是如果在更新的过程中出现中断,导致一些数据更新成功,另一些数据更新失败,那么这样就会导致同一个Java学科会出现不同的学分,这就是我们的更新异常。
3、插入异常
如果我们想要只插入学生的学号,姓名,性别和年龄,而不插入课程名,此时就会出现插入异常,因为我们定义的主键是学号+课程名的复合主键,我们还需要添加我们的课程名
4、删除异常
当此时这个学生已经毕业了,那么我们留着他的成绩肯是没有用的,所有我们就要将他他的信息和成绩删除,但是如果我们要进行删除,我们同时也需要将课程和学分一并删除才能成功,这样就会导致了我们的数据库中的课程和学分会消失。
那么,如果我们想要解决上述问题,我们就要满足我们的第二范式,我们可以将上述的成绩表进行拆分,分为学生表,课程表,成绩表
此时我们的学生表和课程表的非关键字段是和我们的各自的主键id列,完全依赖的,同时这两个
表的每一列都可以用基本数据类型表示,那么这两个列也是天然满足第一范式的。

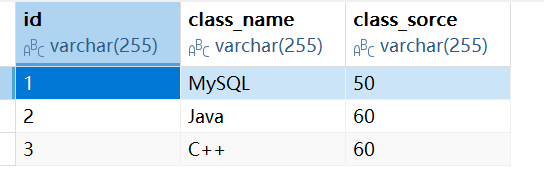
此时我们得到了上述的两个表,接下我们就可以设计得到我们的成绩表了,根据我们的学生id和课程id,得到成绩表的复合主键,根据这个复合主键的对应关系就能得到了我们哪个学生,参加了哪门考试得到了什么成绩。这样就不存在数据冗余和部分函数依赖,同时我们要单独插入或删除我们的学生信息和课程信息也是可以的。
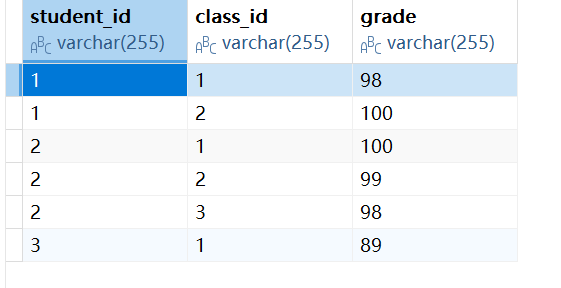
注意:我们的第二范式强调的是部分函数依赖,如果我们的表中主键只有一个列,那么我们就说它是天然满足第二范式的。
三、第三范式
定义:在满足第二范式的基础上,不存在非关键字段,对任一候选键的传递依赖。
我们来看下面这张学生表:
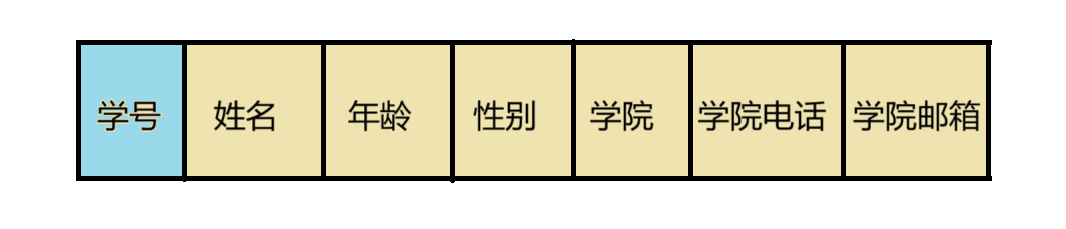
在这张表中,我们可以根据学号去得到我们学生的所在学院,同时也可以得到学院的电话和邮箱,但其实我们知道正常来说,一个学生的学号是不可能得到,他所在学院的电话和邮箱的,而这种由学号->学院->学院电话的传递关系,我们就称它为传递依赖。
而为了防止这种传递依赖我们就引入了新的规范:第三范式。
我们可以将上表拆分成两个表,学生表和学院表
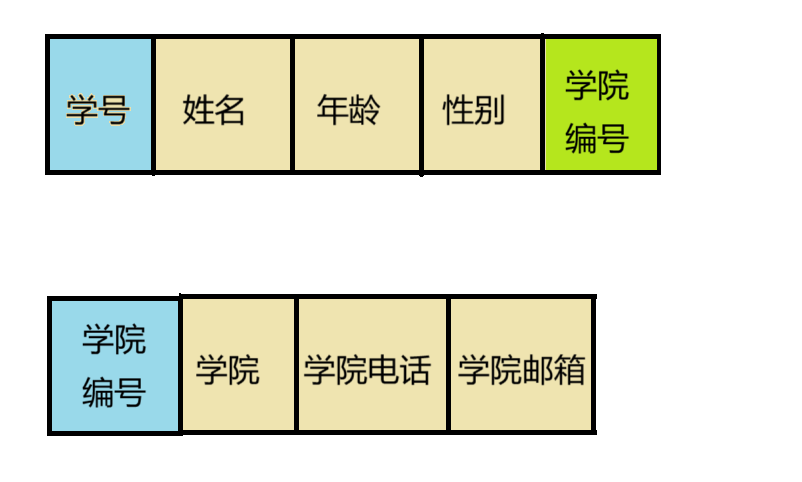
我们可以通过学院编号进行外键的链接,这样我们的学号就只能找到我们的学生信息,而学院的信息需要通过学院编号来获得, 这样就解决了我们的传递依赖。
四、设计
1、从设计上来说,我们要从现实业务中抽象得到概念类
2、然后从中确定实体和实体之间的关系,并画出E-R图
3、最后根据我们的E-R图完成我们SQL语句的编写并创建数据库
而我们这里的E-R图又称实体-关系图,它是由三个部分所组成的分别是:实体,属性,关系。
- 实体:即数据对象,用矩形框表示。
- 属性:实体的特性,用椭圆形或圆角矩形表示
- 关系:实体之间的联系,用菱形框表示,并标明关系的类型,并用直线将相关实体与关系连接起来。
而对于这种实体间的关系,由分为三种:一对一关系、一对多关系、多对多关系。
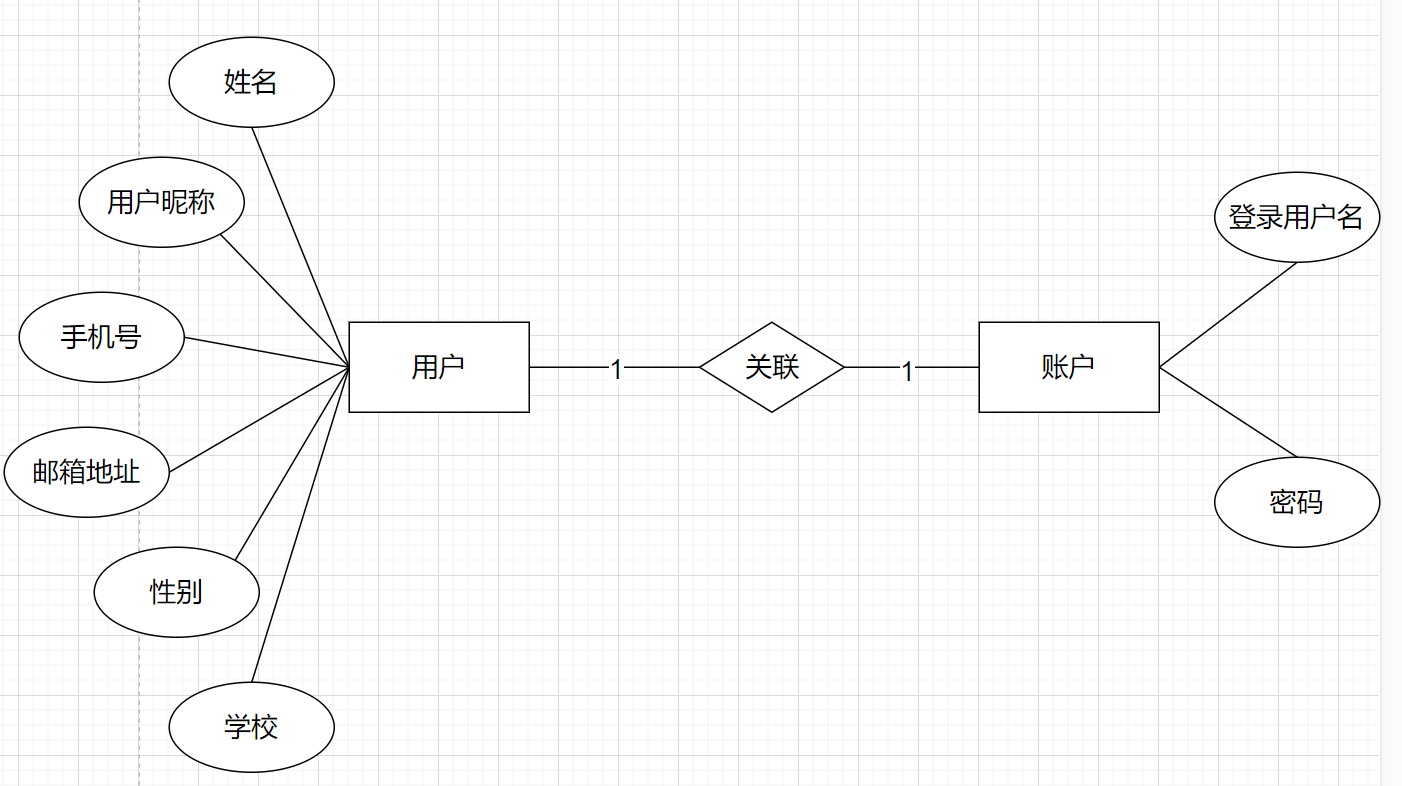
(1)一对一关系
比如我们的用户实体与账户实体就是一对一的关系。
即一个用户的信息只能登录一个账户。
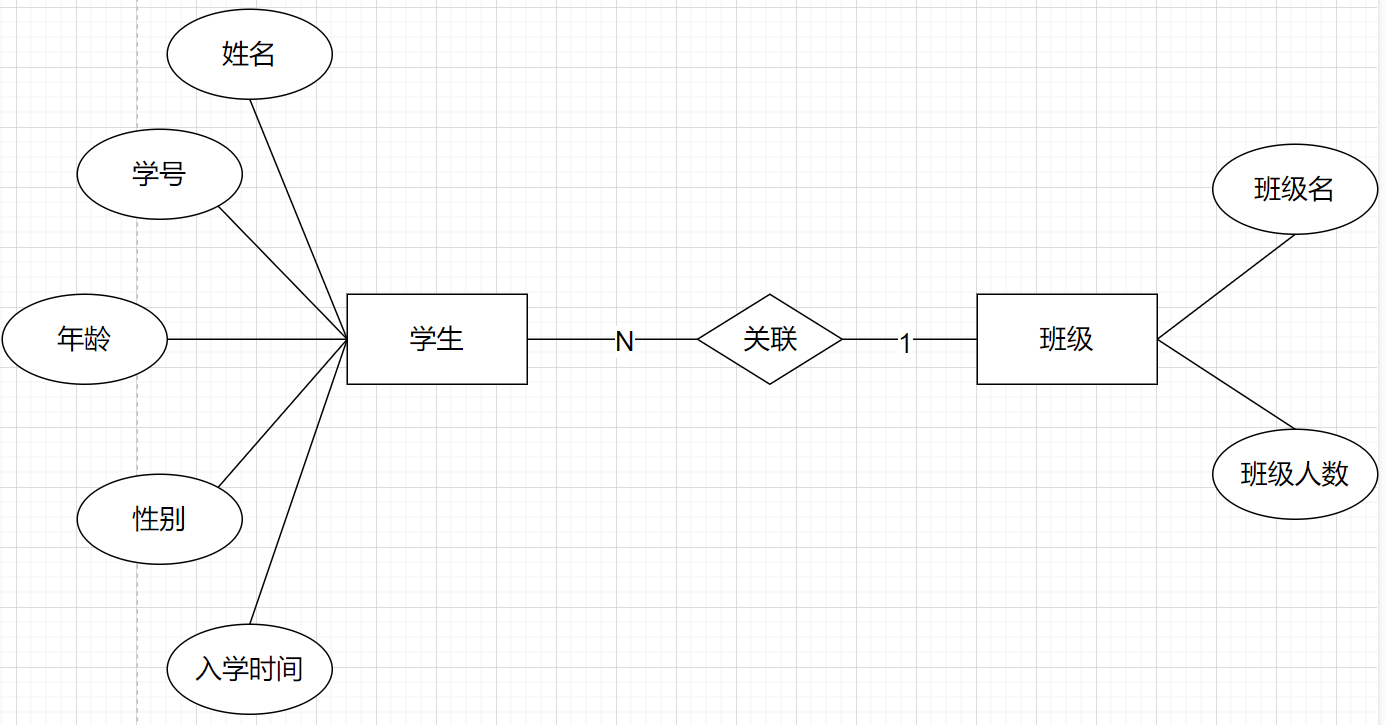
(2)一对多关系
比如我们的学生实体和班级实体,就是一对多的关系。
即一个班级里有多个学生。
(3)多对多关系
比如我们的学生实体和选课实体,就是多对多的关系
即一个学生可以选多门课程,一门课程也可以被多个学生选。
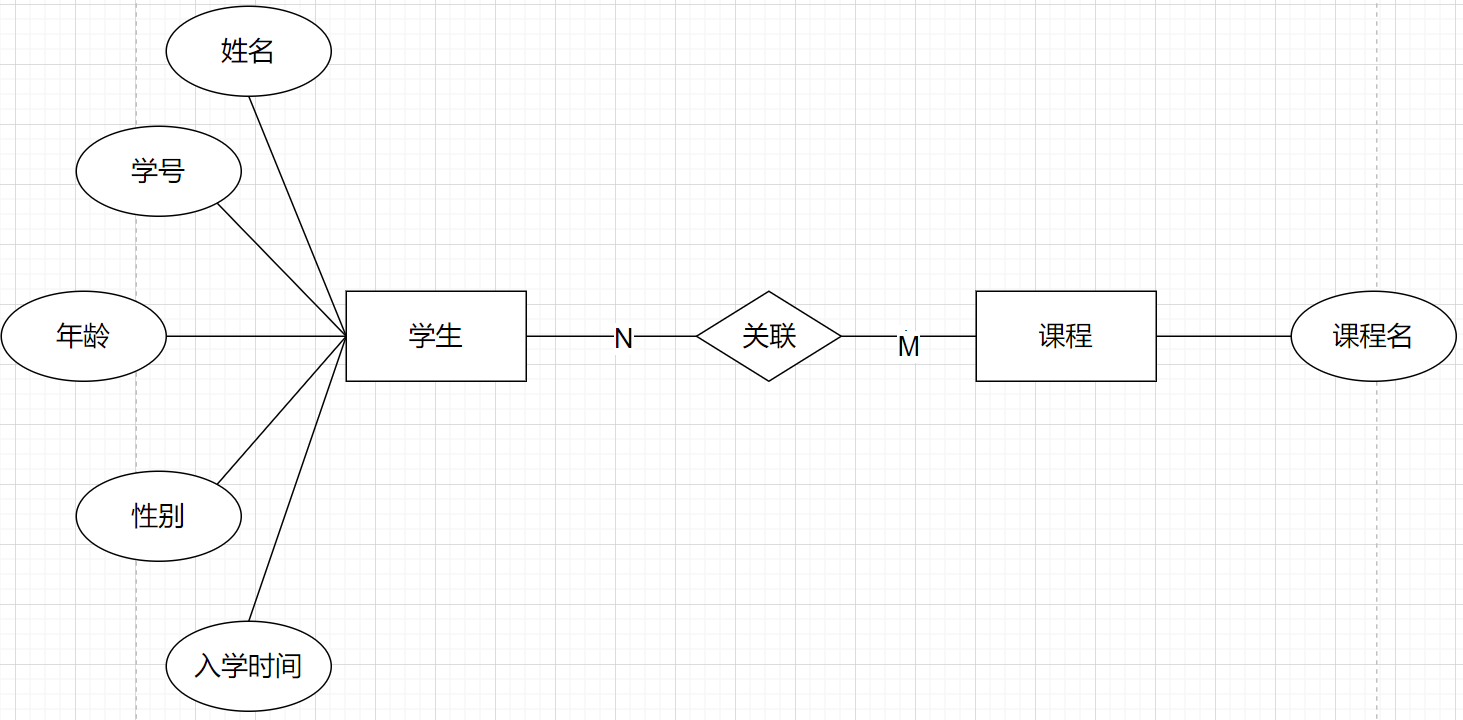
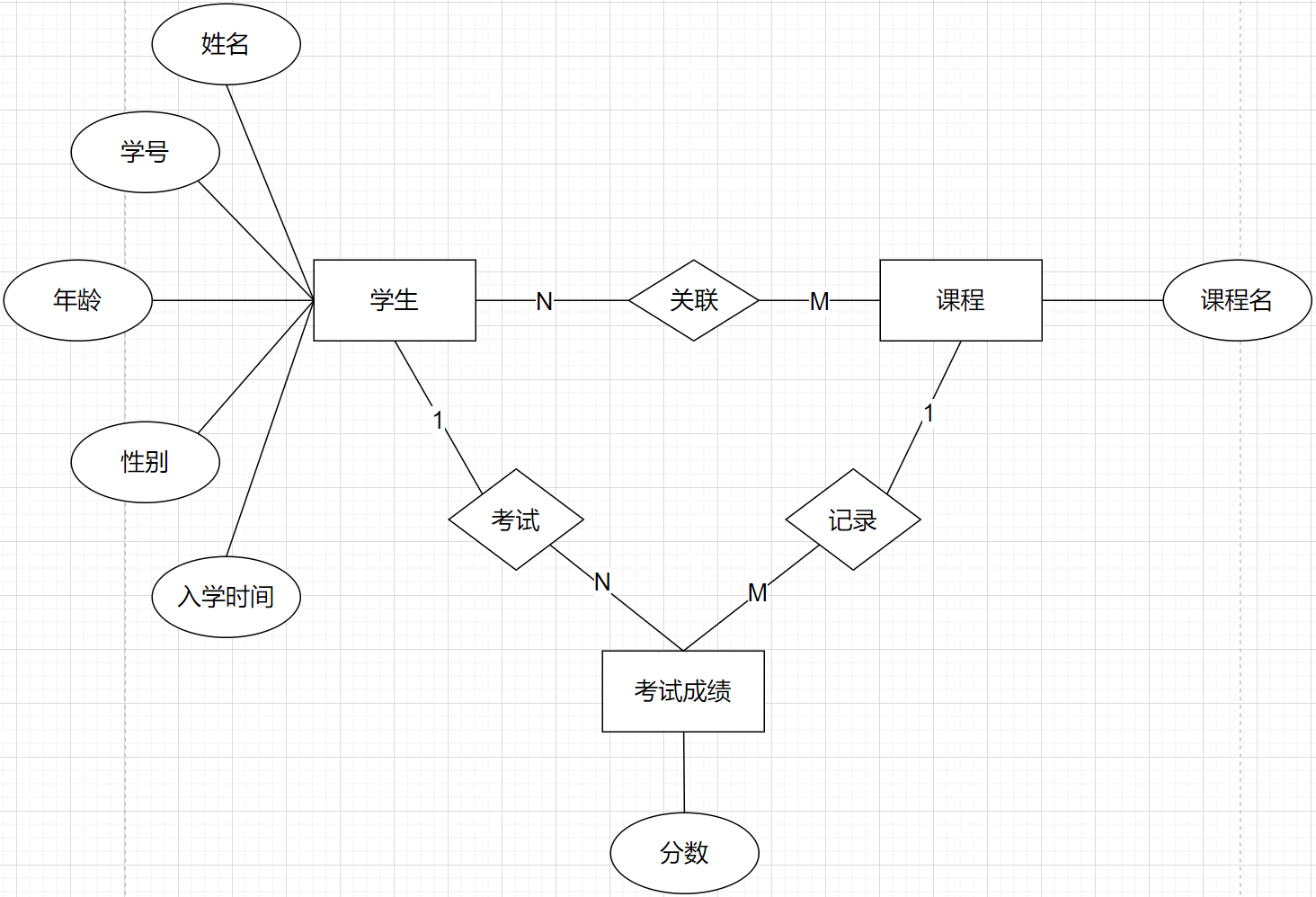
对于多对多关系,我们也可以使用中间表进行记录,比如一个学生参加了某一门课程的考试得到了相应的成绩。
好了,今天的分享就到这里了,还请大家多多关注,我们下一篇见!