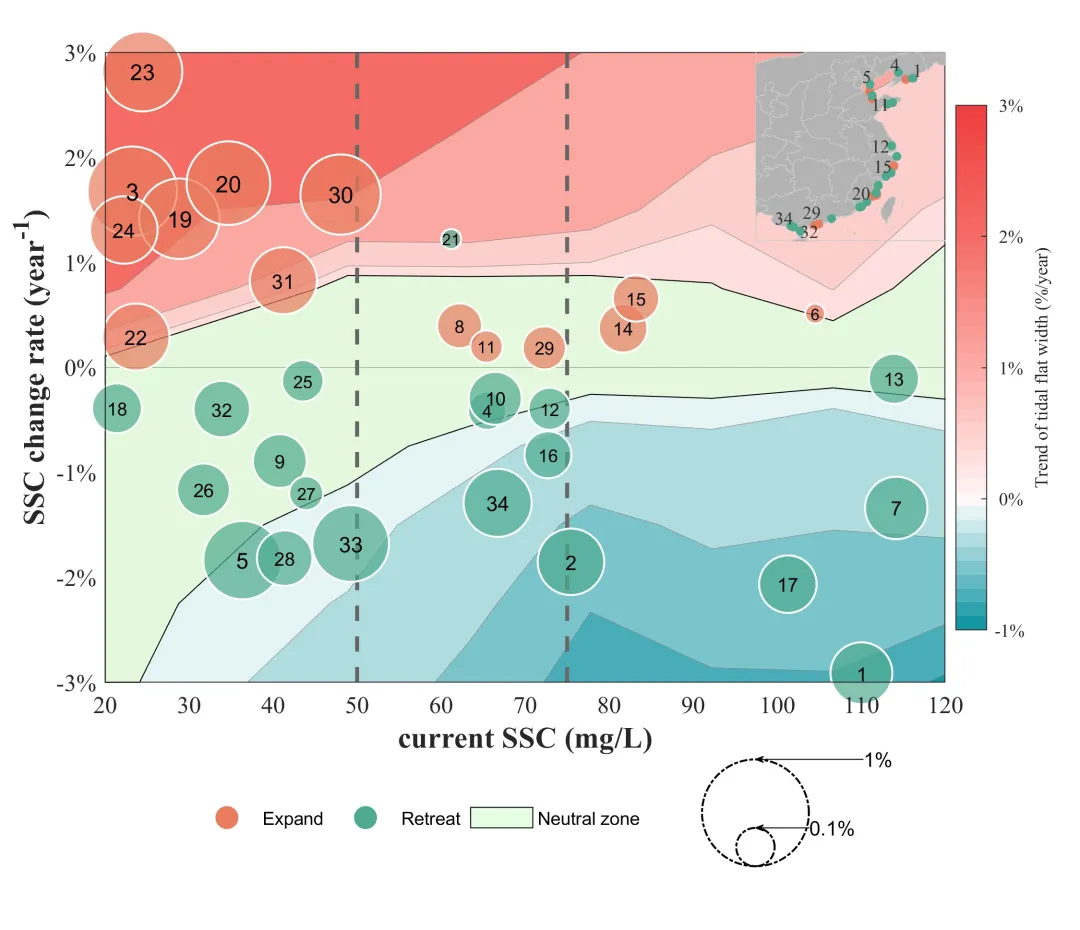
UniGoal的提出了一个通用的零样本目标导航框架,能够统一处理多种类型的导航任务
(如对象类别导航、实例图像目标导航和文本目标导航),而无需针对特定任务进行训练或微调。
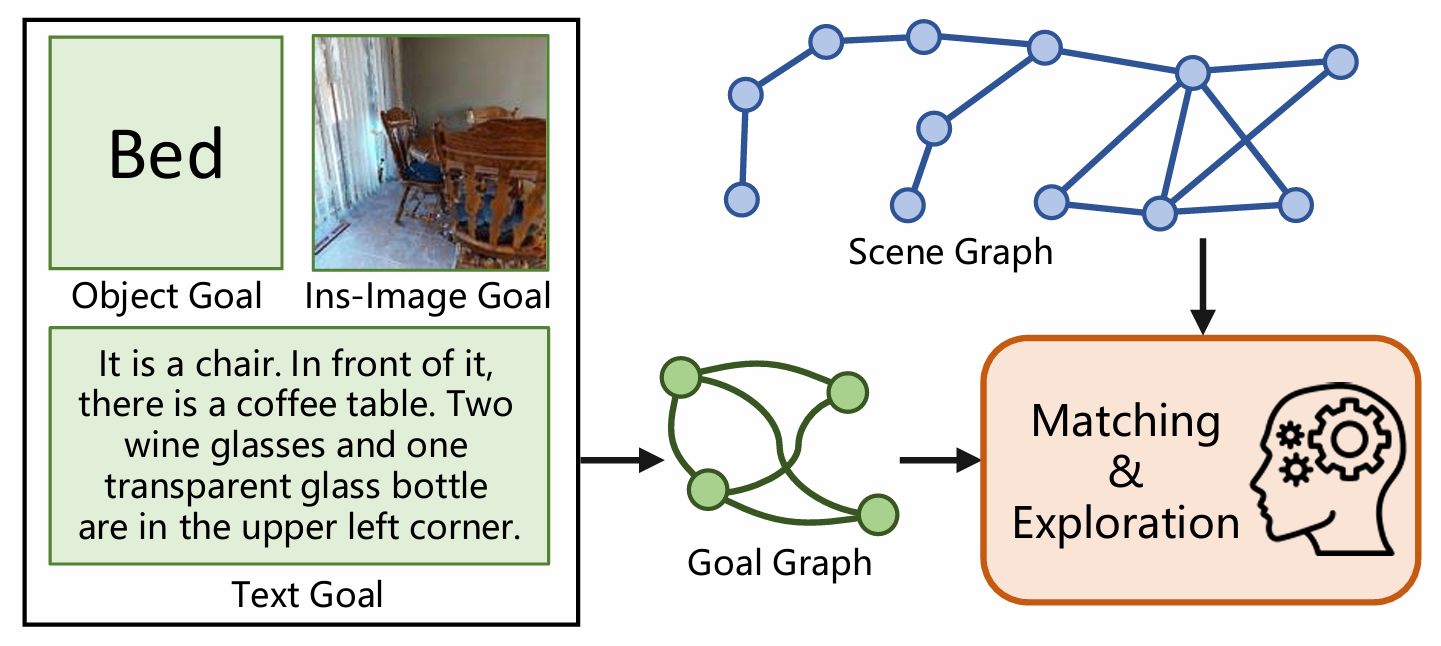
它的特点是 图匹配与多阶段探索策略!!!
论文地址:UniGoal: Towards Universal Zero-shot Goal-oriented Navigation
开源地址:https://github.com/bagh2178/UniGoal
1、模型框架
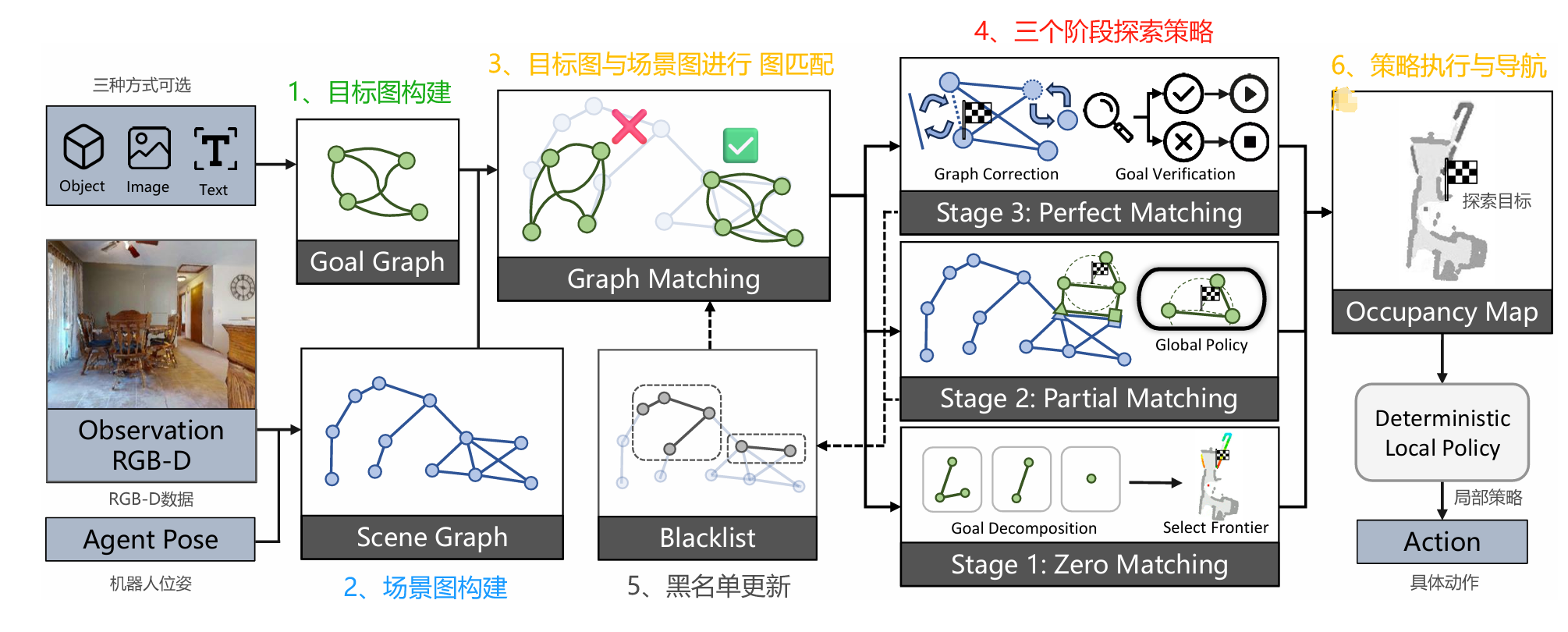
UniGoal的模型框架,如下图所示:
-
目标图构建:根据导航任务类型(对象类别、实例图像或文本描述),构建目标图。
-
场景图构建:代理接收RGB-D图像和姿态信息,实时构建和更新场景图。
-
图匹配:在场景图和目标图之间进行匹配,计算匹配分数 S,反映目标匹配程度。
-
黑名单更新:记录失败的匹配节点和边,避免重复探索。
-
多阶段探索策略:
-
阶段1(零匹配):匹配分数低,扩展探索区域,通过目标图分解和前沿选择确定探索方向。
-
阶段2(部分匹配):匹配分数中等,利用已观察到的部分目标图推理剩余部分位置,通过坐标投影和锚点对齐生成探索目标。
-
阶段3(完美匹配):匹配分数高且中心对象匹配,验证目标正确性,成功则任务完成,否则更新黑名单。
-
-
策略执行:全局策略生成长期探索目标,确定性局部策略将其转换为具体动作。
2、目标导向导航
目标导向导航任务是指:机器人需要在未知的环境中导航到一个指定的目标。
这个目标可以是:
-
对象类别(Object-goal Navigation, ON):比如“找到一把椅子”。
-
实例图像(Instance-image-goal Navigation, IIN):比如“找到与这张图片中相同的那把椅子”。
-
文本描述(Text-goal Navigation, TN):比如“找到那个靠窗、旁边有桌子的椅子”。

对于IIN和TN任务,目标不仅包含一个中心对象 o,还包含与其他相关对象的关系描述。
而对于ON任务,目标直接就是对象类别o=g。
机器人在执行任务时会接收到带有姿态信息的RGB-D视频流(即包含颜色和深度信息的图像序列),并在每次接收到新的观测数据时执行一个动作 a,动作集合 A 包括向前移动、向左转、向右转和停止。
任务的成功完成条件是:机器人在少于 T 步内停在距离目标对象 o 少于 r 米的范围内。
2、通用零样本目标导向导航问题
在研究通用零样本目标导向导航问题,这需要满足以下两个条件:
-
通用性(Universal):设计的方法需要能够通用地处理上述三种导航子任务(ON、IIN、TN),在切换任务时不需要对方法本身进行任何修改。
-
零样本性(Zero-shot):目标可以通过自由形式的语言或图像来指定,且导航方法不需要针对特定任务进行任何训练或微调,从而具备强大的泛化能力。
为了满足上述要求,UniGoal提出了一个基于大型语言模型(LLM)的通用零样本导航框架。
-
利用LLM进行零样本决策:由于任务需要极强的泛化能力,因此采用LLM来进行零样本决策。LLM具有丰富的知识和强大的推理能力,能够帮助代理在未知环境中进行导航决策。
-
统一的图表示:为了使LLM能够感知视觉信息并统一表示不同类型的导航目标,文章提出将场景和目标都表示为图结构,即场景图(Scene Graph)和目标图(Goal Graph)。这种图表示方式能够保留场景和目标的结构化信息,便于后续的推理和决策。
-
基于图的场景理解和决策:在每一步导航过程中,通过将场景图和目标图作为提示提供给LLM,使LLM能够基于图结构进行场景理解、图匹配和决策制定,从而生成合理的探索动作。
通过这种设计,UniGoal框架能够在无需针对特定任务进行训练或微调的情况下,处理多种类型的导航任务,展现出强大的通用性和泛化能力。
3、图的定义与构建
-
图的定义:图 G=(V,E) 由节点 V 和边 E 组成。节点表示对象,边表示对象间的关系。边仅存在于空间上或语义相关对象对之间。节点和边的内容以文本形式描述。
-
场景图的构建:由于代理初始化于未知环境,并持续探索场景,因此场景图 Gt 随着时间逐步构建。每当代理接收到新的RGB-D观测数据时,场景图就会扩展。具体构建方法参考了SG-Nav的工作。
-
目标图的构建:对于不同类型的目标 g(对象类别、实例图像和文本描述),采用不同的方法将其转换为目标图 Gg。
例如,对于对象类别目标,目标图仅包含一个节点,无边。
对于实例图像目标,使用Grounded SAM识别图像中的所有对象,并使用VLM识别对象间的关系以构建边。
对于文本描述目标,提示LLM识别文本中的对象和它们之间的关系以构建图。
4、图匹配方法
-
匹配的目的:通过图匹配确定目标或其相关对象是否被观察到,从而为后续的场景探索策略提供依据。
-
匹配的策略:提出了三种匹配指标,分别从节点、边和拓扑结构三个方面,计算场景图Gt 和 目标图 Gg之间的相似性分数。
-
节点匹配和边匹配:分别提取节点和边的嵌入,计算它们之间的相似性矩阵,然后通过二分图匹配确定匹配的节点对和边对。相似性矩阵中小于阈值 τ 的值会被设置为-1,以禁止对应节点或边对的匹配。
-
拓扑匹配:计算两个图之间的拓扑结构相似性。具体来说,先找到场景图中与目标图匹配的最小子图,然后计算该子图与目标图之间的归一化编辑距离,从而得到拓扑相似性分数。
-
最终匹配分数:将节点、边和拓扑的相似性分数进行平均,得到最终的匹配分数 S。该分数反映了目标在场景中被观察到的程度。
-
通过构建场景图和目标图,并运用图匹配技术,机器人能够在未知环境中识别目标对象及其相关对象。
这种图表示方法不仅保留了丰富的结构化信息,还为后续的场景探索策略提供了决策依据。
5、多阶段场景探索策略
该策略基于图匹配的分数,机器人在不同阶段采取不同的行动来寻找目标。
整个探索过程分为三个阶段:零匹配阶段、部分匹配阶段和完美匹配阶段。
下面图片是展示UniGoal的决策过程。这里的“Switch”表示阶段转换的点。“S-Goal”表示每个阶段预测的长期目标。
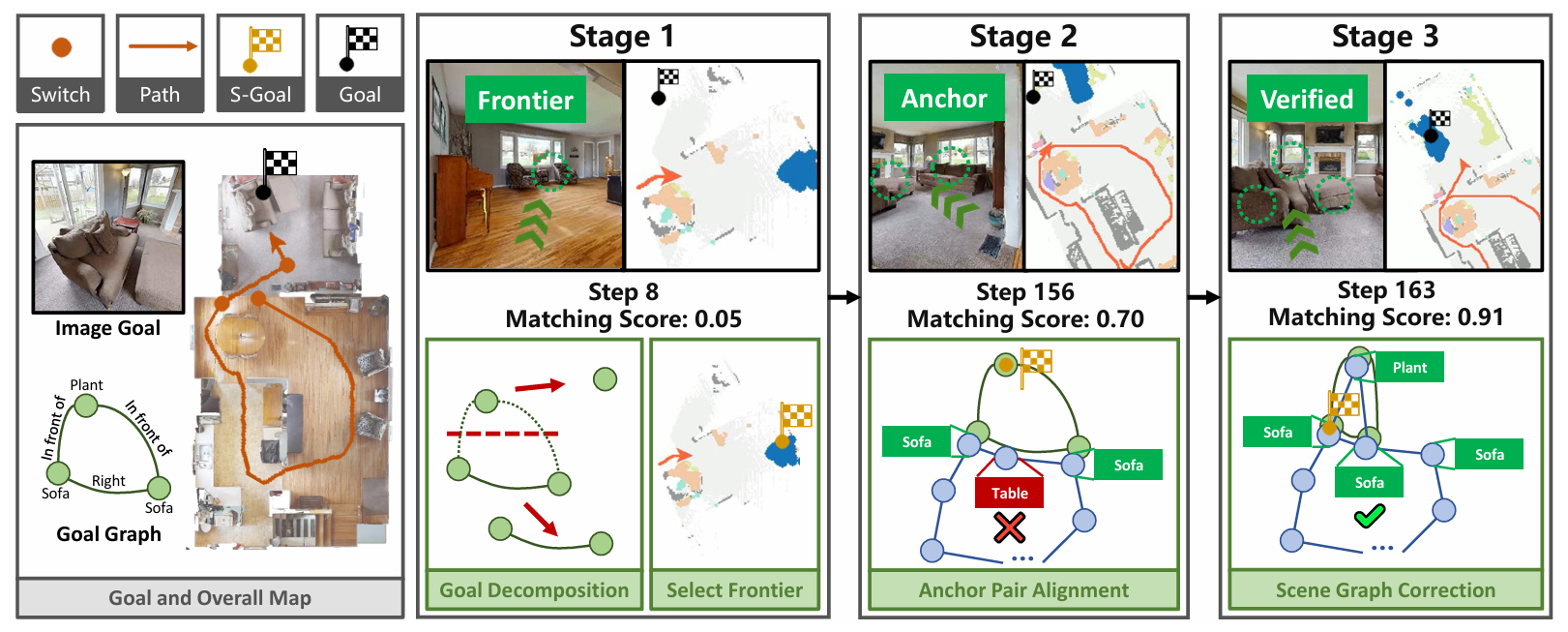
阶段1:零匹配阶段
-
情况描述:当匹配分数 S 小于阈值 σ1 时,认为目标图中的元素几乎没有被观察到。此时,代理需要扩展其探索区域,寻找目标图中的元素。
-
挑战:目标可能是一个复杂的图,包含多个内部关联较弱的子图。例如,目标图可能包含“桌子、椅子、窗户、窗帘”等多个子图,每个子图内部关联性强,但子图之间关联性弱。
-
解决方案:
-
目标图分解:通过大型语言模型(LLM)将复杂的目标图分解为多个内部关联的子图。例如,将目标图分解为“[桌子,椅子]”和“[窗户,窗帘]”两个子图。
-
文本描述转换:为每个子图生成文本描述,例如将“[桌子,椅子]”子图转换为“桌子旁边有椅子”。
-
前沿选择:调用前沿选择方法(如SG-Nav中的方法),根据子图的文本描述和场景图的语义关系,选择探索的前沿点。
-
前沿评分:通过LLM预测每个前沿点与子图的最可能位置的距离,并根据距离和前沿点到代理的距离计算评分,选择评分最高的前沿点作为长期探索目标。
-
通俗来说,这一阶段就像是在一个完全陌生的房间里寻找一个复杂的家具组合。由于对房间一无所知,代理人需要先分解任务,逐步探索房间的不同区域。
阶段2:部分匹配阶段
-
情况描述:随着代理的探索,目标图的部分元素逐渐被观察到,匹配分数 S 逐渐增加。当 S 超过 σ1 且至少存在一个锚点对(即场景图和目标图中的一对匹配节点或边)时,进入部分匹配阶段。
-
挑战:需要利用已观察到的部分目标图和场景图的重叠部分,推理出剩余部分的目标位置。
-
解决方案:
-
坐标投影:将目标图的中心对象节点投影到坐标原点(0, 0),并利用目标图中节点间的空间关系,通过深度优先搜索(DFS)和LLM推理,逐步推断出目标图中其他节点的坐标。
-
锚点对对齐:将场景图和目标图的锚点对对齐,计算坐标转换矩阵 P,将目标图的其余节点投影到场景图的坐标系中。
-
探索目标生成:为每个锚点对生成探索目标,即投影节点的最小外接圆的圆心,确保探索目标到最远节点的距离最小。
-
通俗来说,这一阶段就像是在房间里找到了部分家具组合(如桌子和椅子),并利用这些已知信息推断出其他家具(如窗户和窗帘)可能的位置。
下面是阶段3:部分匹配阶段(坐标投影和锚点对齐)细节信息:
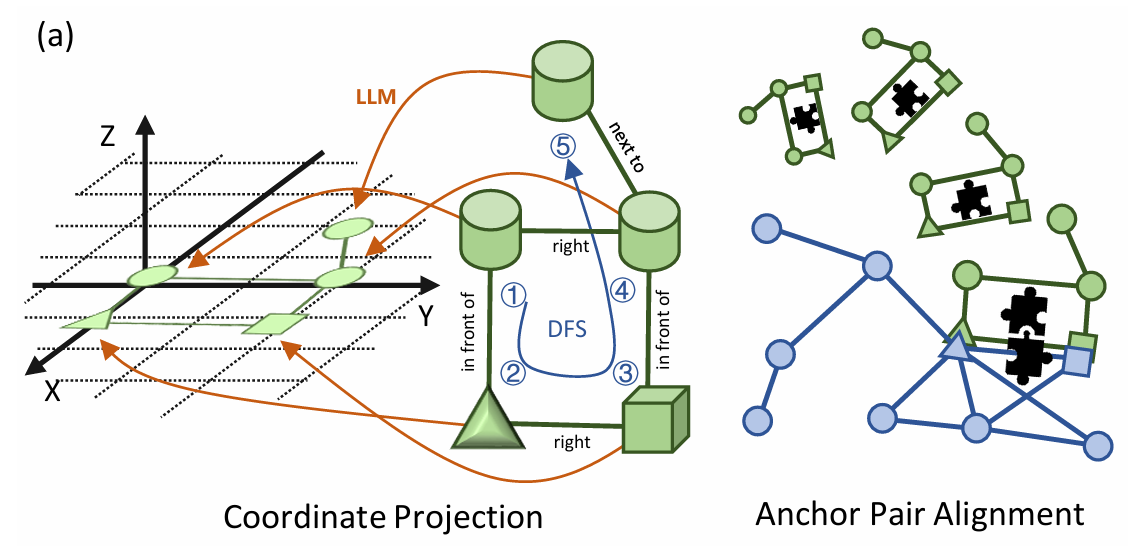
-
坐标投影:首先将目标图的中心对象节点投影到坐标原点(0, 0)。然后,利用目标图中节点间的关系,通过深度优先搜索(DFS)和大型语言模型(LLM)推理,逐步推断出目标图中其他节点的坐标。
-
例如,若已知一个节点的坐标和其与另一个节点的空间关系(如“在...前面”或“在...右侧”),可通过LLM推断出另一个节点的坐标。
-
锚点对齐:找到场景图和目标图中的锚点对(匹配的节点或边),将目标图的坐标系与场景图的坐标系对齐。通过计算坐标转换矩阵,将目标图的其余节点投影到场景图的坐标系中,从而确定探索目标的位置。
阶段3:完美匹配阶段
-
情况描述:当匹配分数 S 超过 σ2 且目标图的中心对象 o 被匹配时,进入完美匹配阶段。
-
挑战:需要确保匹配的中心对象正确,并避免感知错误。
-
解决方案:
-
场景图校正:对场景图中距离中心对象 o 一定范围内的节点和边进行校正,通过信息传播和LLM聚合更新节点和边的描述。
-
目标验证:通过多个置信度指标(如校正后的节点和边的比例、关键点匹配度、图匹配分数和路径长度)验证目标是否正确。如果置信度超过阈值,则确认目标;否则,排除当前匹配。
-
通俗来说,这一阶段就像是在房间里找到了目标家具组合,并验证其是否符合描述。
下面是阶段3:完美匹配(场景图校正)细节信息:
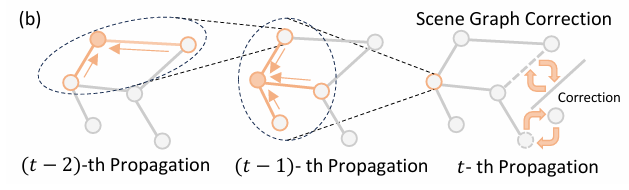
在接近目标时,对场景图中目标附近的节点和边进行修正。
通过多次信息传播和LLM推理,更新节点和边的描述,修正可能存在的感知错误。
例如,若新观测的图像显示椅子是棕色的,但场景图中描述为绿色,则修正场景图中的颜色描述。
6、黑名单机制
黑名单机制的定义和目的
-
定义:黑名单机制是一种防止代理(如机器人)在导航过程中重复探索无效区域的策略。
-
目的:避免在图匹配过程中反复尝试那些已经失败的节点和边,提高导航效率和鲁棒性。
黑名单机制的初始化和更新
-
初始化:黑名单初始为空。
-
更新规则:在两种情况下会将节点和边加入黑名单:
-
当阶段2(部分匹配阶段)的所有锚点对都无法进入阶段3(完美匹配阶段)时,将这些锚点对涉及的节点和边加入黑名单。
-
当阶段3的目标验证失败时,将所有匹配的节点和边加入黑名单。
-
节点和边的移除
-
修正后的移除:如果在阶段3的场景图修正过程中,某些节点或边被修正,那么这些节点和边以及它们的连接节点和边将从黑名单中移除。
通俗易懂的类比
黑名单机制可以类比为我们在日常生活中避免走冤枉路的策略。
例如,当你在一个陌生的城市寻找某个地址时,如果你发现某条路走不通或者带你到了错误的地方,你就会记住这条路,下次不会再走。这个机制帮助代理避免在无效区域浪费时间,提高导航效率。
7、Prompts提示语设计
提示语(Prompts)在UniGoal方法中起着至关重要的作用。它们被设计为指导大型语言模型(LLM)执行特定任务的指令。
这些任务包括从图像或文本中构建目标图、分解复杂的目标图、选择探索的前沿点、校正场景图以及验证目标等。
以下是具体的提示语类型及其内容:
1. 实例图像目标(Instance-image-goal)的提示语
-
任务:从图像中识别对象之间的空间关系。
-
提示语格式:
你是一个能够推断物体之间空间关系的AI助手。你需要猜测在图像中{object1}和{object2}之间的空间关系。用一个单词或短语回答关系。 -
参数替换:
-
{object1}和{object2}:图像中的两个对象。 -
{image}:目标图像。
-
-
示例:
你是一个能够推断物体之间空间关系的AI助手。你需要猜测在图像中椅子和桌子之间的空间关系。用一个单词或短语回答关系。 -
预期输出:一个单词或短语,描述两个对象之间的空间关系(如“在...前面”、“在...后面”等)。
2. 文本目标(Text-goal)的提示语
-
任务:从文本描述中识别对象和它们之间的关系。
-
提示语格式:
你是一个能够从描述中识别物体和关系的AI助手。你需要将以下文本中的物体和关系以指定格式列出:{’nodes’: [{’id’: ’book’}, {’id’: ’table’}], ’edges’: [{’source’: ’book’, ’target’: ’table’, ’type’: ’on’},]} -
参数替换:
-
{text}:文本描述的目标。
-
-
示例:
你是一个能够从描述中识别物体和关系的AI助手。你需要将以下文本中的物体和关系以指定格式列出:厕所是白色的,周围有白色的门,墙壁和地板上有米色的瓷砖。 -
预期输出:一个包含节点(对象)和边(关系)的JSON格式字符串。
3. 目标图分解的提示语
-
任务:将复杂的目标图分解为多个内部关联的子图。
-
提示语格式:
你是一个具有常识的AI助手。你需要根据相关性将以下物体{}分成多个子集,每个子集内的物体高度相关,不同子集的物体系相关性较低。你的回答应为二维数组格式:[[object1, object2,...,objectn], [...],...,[...]] -
参数替换:
-
{}:目标图中的对象列表。
-
-
示例:
你是一个具有常识的AI助手。你需要根据相关性将以下物体[椅子, 沙发, 床, 植物]分成多个子集,每个子集内的物体高度相关,不同子集的物体系相关性较低。你的回答应为二维数组格式:[[object1, object2,...,objectn], [...],...,[...]] -
预期输出:一个二维数组,每个子数组包含一个子图中的对象。
4. 前沿评分的提示语
-
任务:预测对象与子图之间的最可能距离。
-
提示语格式:
你是一个具有常识的AI助手。你需要预测{object}和{subgraph}之间的最可能距离(以米为单位)。 -
参数替换:
-
{object}:场景图中的对象。 -
{subgraph}:目标图的子图描述。
-
-
示例:
你是一个具有常识的AI助手。你需要预测椅子和[桌子, 椅子]子图之间的最可能距离(以米为单位)。 -
预期输出:一个数字,表示对象与子图之间的最可能距离(以米为单位)。
5. 场景图校正的提示语
-
任务:基于场景图和新观测的图像,修正节点或边的描述。
-
提示语格式:
你是一个能够详细描述室内场景图节点或边的AI助手。现在,请根据场景图{graph}和新观测的图像{image},给出{}的更详细描述,以便识别场景图中的可能错误。 -
参数替换:
-
{}:需要修正的节点或边。 -
{graph}:局部场景图。 -
{image}:新观测的图像描述。
-
-
示例:
你是一个能够详细描述室内场景图节点或边的AI助手。现在,请根据场景图{'nodes': [{'id': 'chair'}, {'id': 'table'}], 'edges': [{'source': 'chair', 'target': 'table', 'type': 'in front of'}]}和新观测的图像“一张带靠垫的木椅”,给出“椅子”的更详细描述,以便识别场景图中的可能错误。 -
预期输出:一个更详细的节点或边的描述,可能包含修正后的属性或关系。
这些提示语设计用于充分利用LLM的知识和推理能力,完成从目标识别到场景理解和决策制定的各个环节。通过精心设计的提示语,UniGoal方法能够有效地指导LLM完成复杂的导航任务。
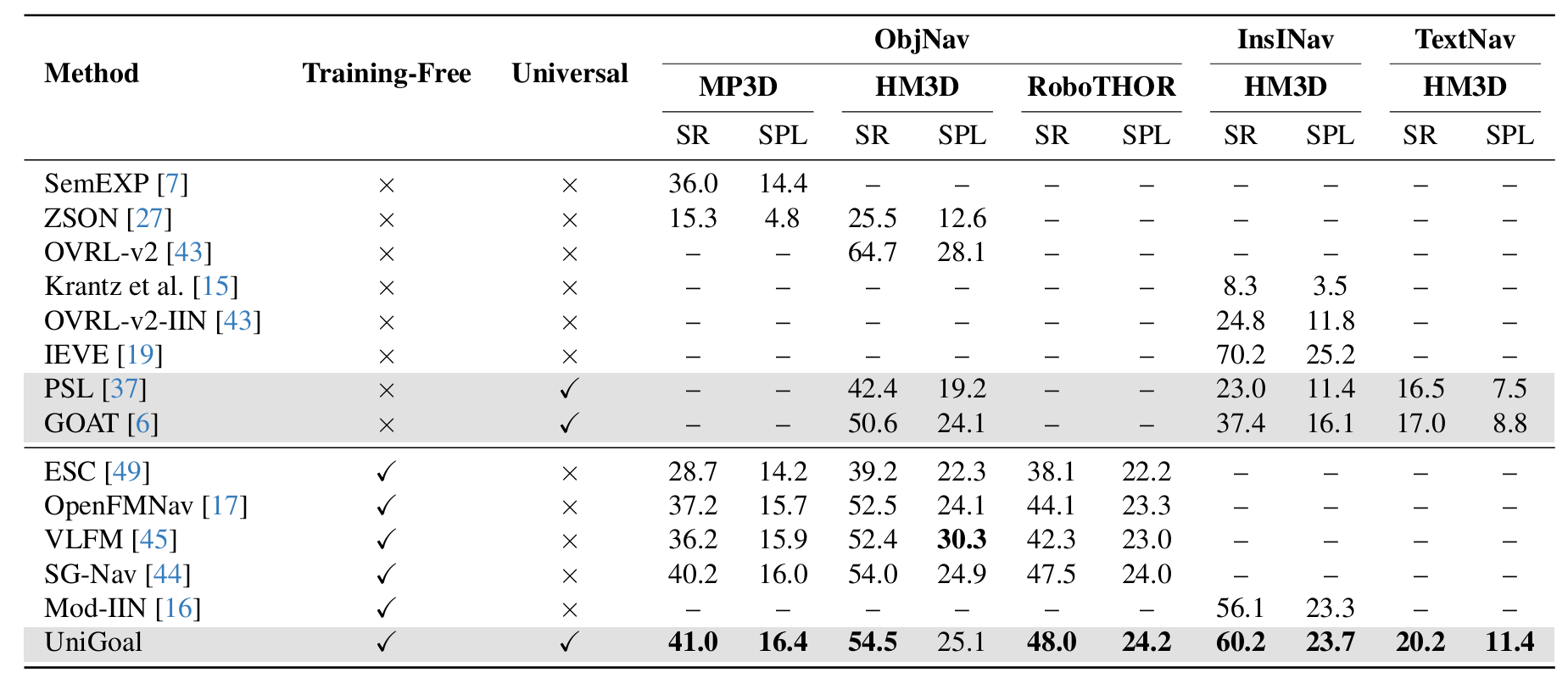
8、实验与验证
-
数据集:在多个数据集上评估UniGoal方法,包括MatterPort3D(MP3D)、Habitat-Matterport 3D(HM3D)和RoboTHOR。这些数据集提供了丰富的3D室内环境,用于测试不同类型的导航任务。
-
评估指标:使用成功 rate(SR)和成功 rate加权路径长度(SPL)作为评估指标。SR表示成功导航的剧集比例,SPL衡量路径与最优路径的接近程度。
-
比较方法:与多种现有方法进行比较,包括监督方法(如SemEXP、ZSON、OVRL-v2)、零样本方法(如ESC、OpenFMNav、VLFM、SG-Nav)和通用方法(如PSL、GOAT)。
下面表格,是在MP3D、HM3D和RoboTHOR上,进行对象目标导航、实例图像目标导航和文本目标导航的结果。
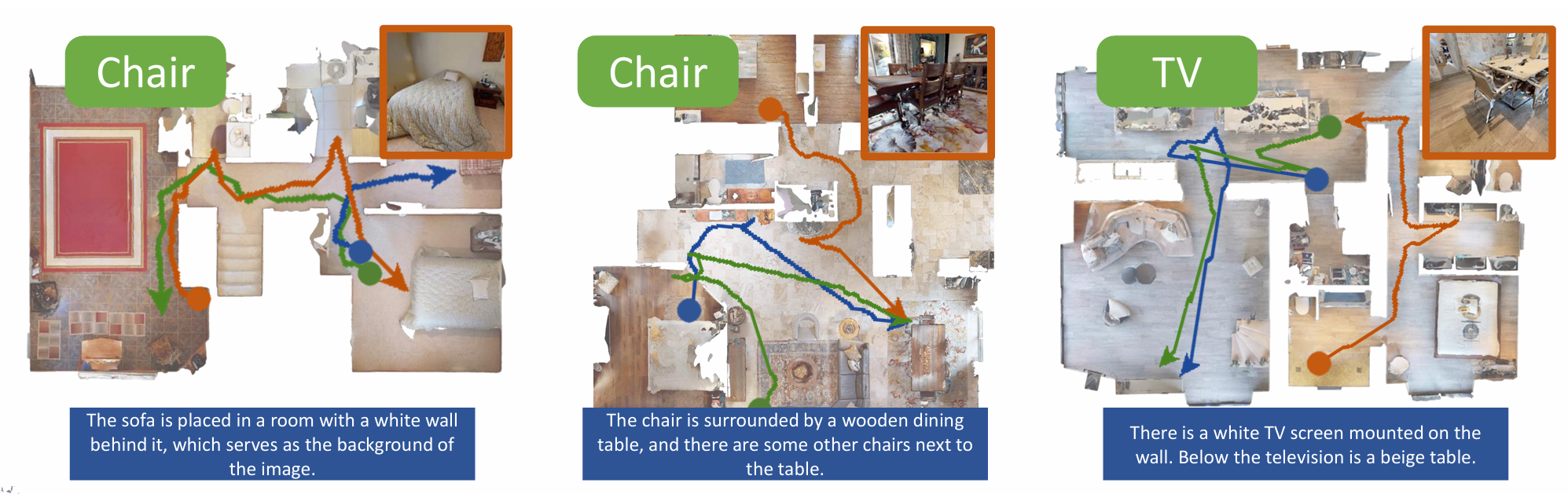
看一下导航路径可视化,可视化了多个场景的 ON(绿色)、IIN(橙色)和 TN(蓝色)路径。
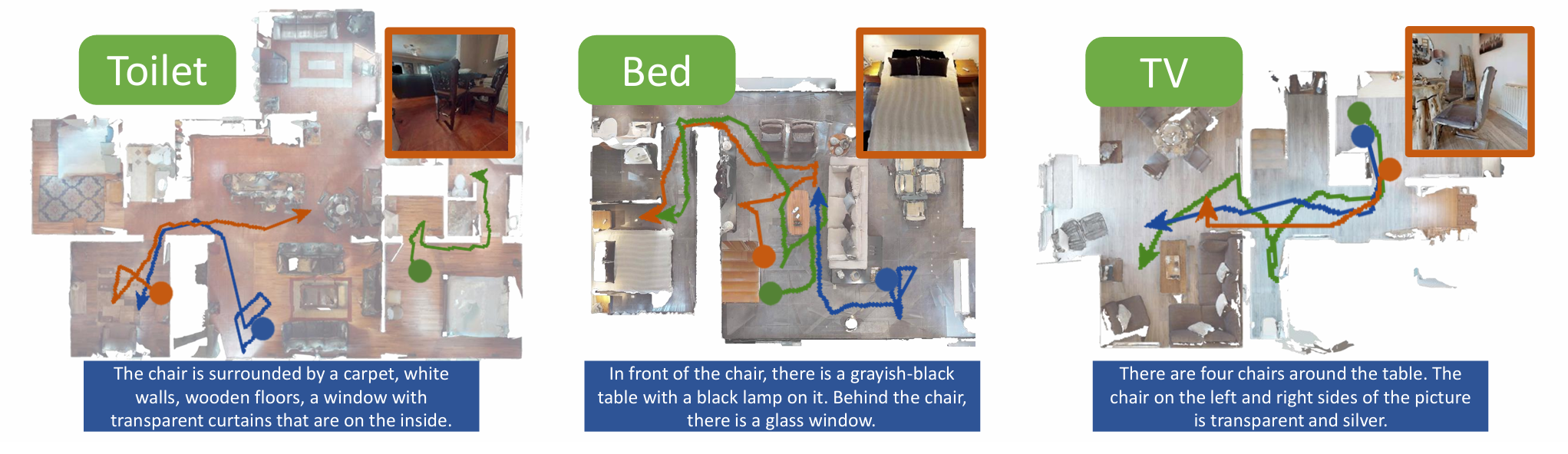
分享完成~