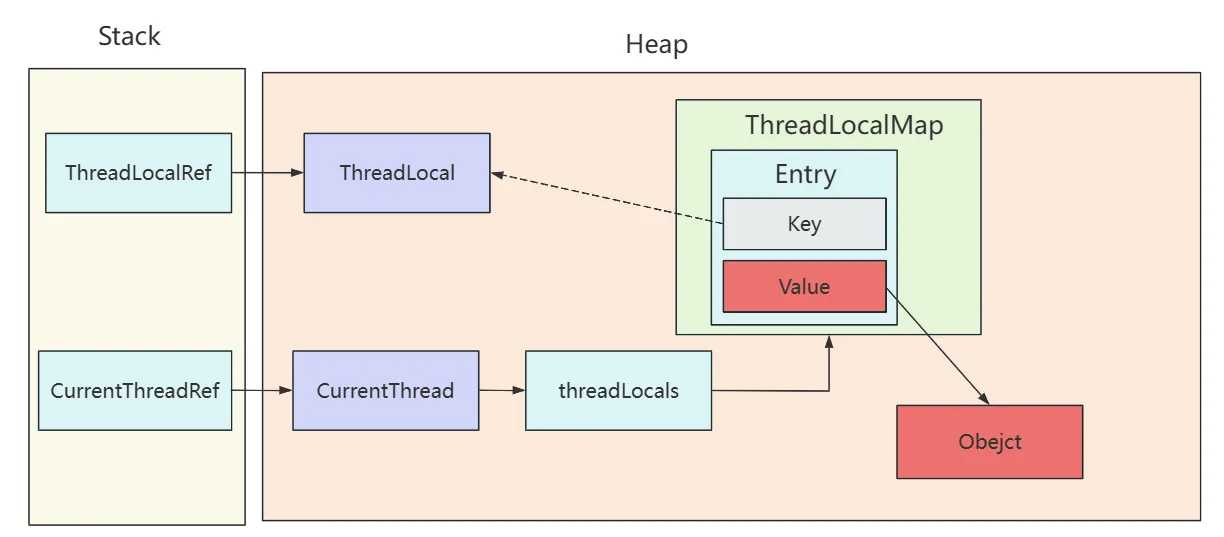
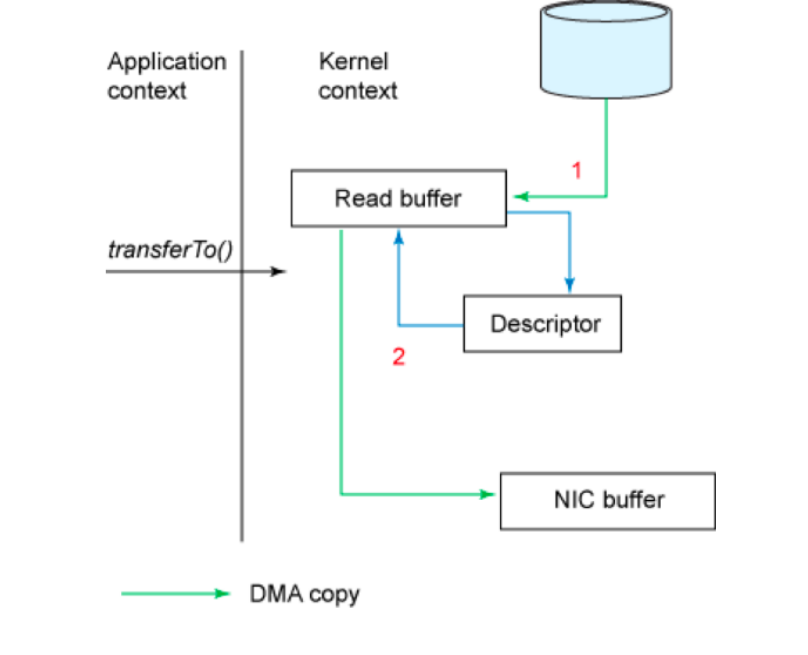
进一步探讨如何使用 Puppeteer 进行动态网页爬取,特别是如何等待页面元素加载完成、处理无限滚动加载、单页应用的路由变化以及监听接口等常见场景。
一、等待页面元素加载完成
在爬取动态网页时,确保页面元素完全加载是获取完整数据的关键。Puppeteer 提供了多种等待页面元素加载完成的方法。
1.1 使用 waitForSelector 方法
async function waitForElement() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com');
await page.waitForSelector('selector-of-element'); // 替换为实际的 CSS 选择器
console.log('元素加载完成');
// 提取元素内容
const content = await page.$eval('selector-of-element', el => el.textContent);
console.log('元素内容:', content);
await browser.close();
}
waitForElement();1.2 使用 waitForXPath 方法
async function waitForXPathElement() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com');
await page.waitForXPath('//*[@id="element-id"]'); // 替换为实际的 XPath 表达式
console.log('元素加载完成');
// 提取元素内容
const content = await page.evaluate(() => {
return document.evaluate('//*[@id="element-id"]', document).iterateNext().textContent;
});
console.log('元素内容:', content);
await browser.close();
}
waitForXPathElement();二、处理无限滚动加载
无限滚动加载是一种常见的动态网页加载方式,通过监听滚动事件动态加载更多内容。可以使用 Puppeteer 模拟滚动操作,获取所有内容。
async function handleInfiniteScroll() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com/infinite-scroll-page');
// 设置页面高度,模拟无限滚动
const prevPageHeight = await page.evaluate('document.body.scrollHeight');
let newPageHeight;
while (true) {
await page.evaluate(() => {
window.scrollTo(0, document.body.scrollHeight);
});
await page.waitForTimeout(2000); // 等待内容加载
newPageHeight = await page.evaluate('document.body.scrollHeight');
if (newPageHeight === prevPageHeight) {
break; // 如果页面高度不再变化,退出循环
}
prevPageHeight = newPageHeight;
}
// 提取内容
const contentList = await page.evaluate(() => {
return Array.from(document.querySelectorAll('selector-of-content-item')).map(item => item.textContent);
});
console.log('内容列表:', contentList);
await browser.close();
}
handleInfiniteScroll();三、单页应用的路由变化处理
单页应用(SPA)通常通过 JavaScript 动态更新页面内容而不重新加载整个页面。可以使用 Puppeteer 监听路由变化,获取不同路由下的内容。
async function handleSpaRouteChanges() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com/spa-page');
// 监听路由变化
page.on('response', async (response) => {
if (response.url().includes('api/new-route')) {
console.log('路由变化检测到,获取新内容');
// 提取新路由下的内容
const content = await page.evaluate(() => {
return document.querySelector('selector-of-new-route-content').textContent;
});
console.log('新路由内容:', content);
}
});
// 触发路由变化的操作
await page.click('selector-of-route-link');
await browser.close();
}
handleSpaRouteChanges();四、监听接口请求
在某些情况下,我们可能需要监听特定的接口请求,获取接口返回的数据。Puppeteer 提供了监听网络请求的功能。
async function listenApiRequest() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// 监听网络请求
page.on('response', async (response) => {
const url = response.url();
if (url.includes('api/data')) { // 监听特定接口
try {
const data = await response.json(); // 获取接口返回的 JSON 数据
console.log('接口数据:', data);
} catch (error) {
console.error('解析接口数据出错:', error);
}
}
});
await page.goto('https://example.com/page-with-api-calls');
// 执行触发接口请求的操作
await page.click('selector-of-api-call-trigger');
await browser.close();
}
listenApiRequest();五、完整示例:爬取动态电商网站
以下是一个完整的示例,演示如何使用 Puppeteer 爬取一个动态电商网站的商品列表,该网站使用无限滚动加载商品内容。
async function scrapeEcommerceProducts() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com/products', { waitUntil: 'networkidle2' });
// 设置页面高度,模拟无限滚动
const prevPageHeight = await page.evaluate('document.body.scrollHeight');
let newPageHeight;
const productSet = new Set(); // 使用集合避免重复
while (true) {
// 提取当前页面的商品内容
const products = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.product-item')).map(item => {
return {
title: item.querySelector('.product-title').textContent,
price: item.querySelector('.product-price').textContent
};
});
});
// 将商品信息添加到集合
products.forEach(product => productSet.add(JSON.stringify(product)));
// 滚动页面
await page.evaluate(() => {
window.scrollTo(0, document.body.scrollHeight);
});
await page.waitForTimeout(2000); // 等待内容加载
newPageHeight = await page.evaluate('document.body.scrollHeight');
if (newPageHeight === prevPageHeight) {
break; // 如果页面高度不再变化,退出循环
}
prevPageHeight = newPageHeight;
}
// 将集合转换为数组并输出
const productList = Array.from(productSet).map(item => JSON.parse(item));
console.log('商品列表:', productList);
await browser.close();
}
scrapeEcommerceProducts();六、总结
通过本文的案例和实践,深入探讨了如何使用 Puppeteer 进行动态网页爬取,包括等待页面元素加载、处理无限滚动加载、单页应用的路由变化以及监听接口请求等常见场景