本文分为两个部分:
- DOCA及BlueField介绍
- 如何运行DOCA应用,这里以DNS_Filter为例子做大致介绍。
DOCA及BlueField介绍:
现代企业数据中心是软件定义的、完全可编程的基础设施,旨在服务于跨云、核心和边缘环境的高度分布式应用工作负载。尽管软件定义的数据中心提供了类似云的灵活性和敏捷性,但它们往往会消耗大量的CPU资源,进而降低服务器和数据中心的整体效率。通过利用DPU(Data Processing Uint)和DOCA(Data Center Infrastructure on a Chip Architecture),可以实现硬件加速的软件定义基础设施,从而显著提升数据中心的性能和灵活性。
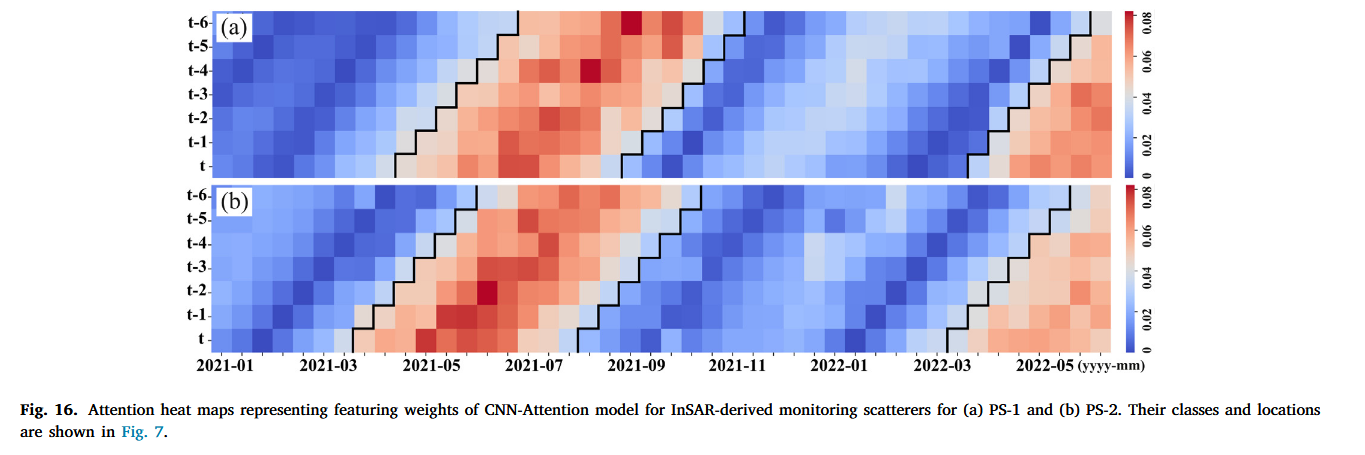
DPU被定义为一种可编程的网络系统级芯片(SoC),它集成了从网络端口到PCI Express(PCIe)接口的所有主要功能。NVIDIA于2020年进入DPU市场,并推出了BlueField系列产品。已发布的BlueField-2能够作为智能网卡和存储控制器使用,支持高达200Gbps的以太网端口和高带宽的PCIe接口。BlueField-3于2022年上市,而更强大的BlueField-4预计将在2024年推出。
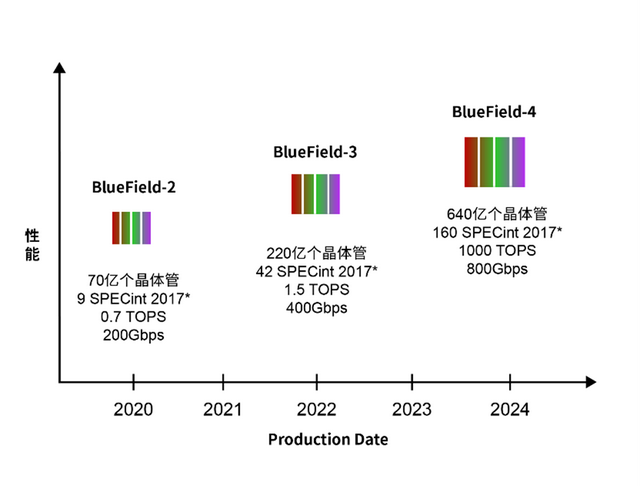
图1
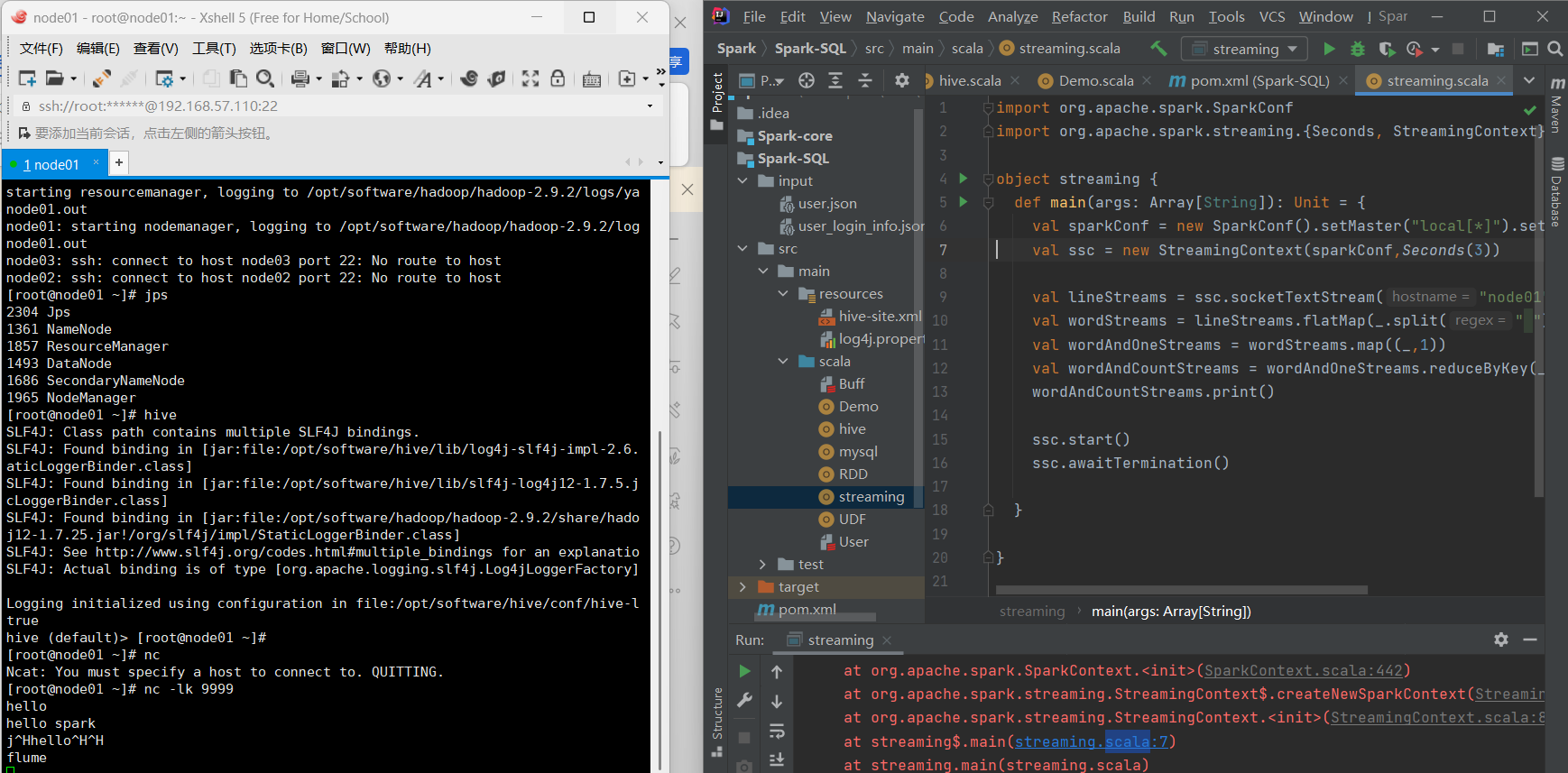
不同于传统的服务器处理器,DPU(Data Processing Uint)专为网络数据包处理而设计。尽管其架构有所不同,但大多数DPU都包含一个可编程的数据平面,以及用于控制平面和应用代码的CPU核心。与使用CPU核心相比,DPU的专用数据路径不仅更高效,而且性能显著提升。
如图所示,BlueField架构本质上将网卡子系统(基于ConnectX)与可编程数据路径、用于加密、压缩和正则表达式的硬件加速器,以及用于控制平面的Arm控制器融为一体。在BlueField-3中,包含16个核心的可编程包处理器能够处理多达256个线程,实现了在Arm核心上零负载的数据路径处理。在许多应用中,数据路径可以自主处理已知的网络流量,而Arm核心则负责处理新流量等异常情况及控制平面功能。
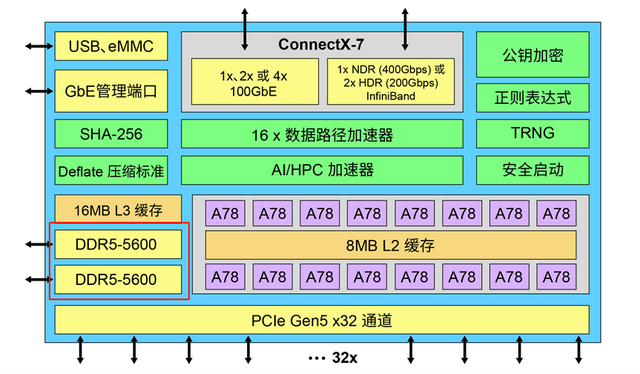
图2
尽管DPU具备显著的优势,但由于需要用户编写底层代码,其早期应用仅限于少数用户群体。为了解决这一限制,并推动独立软件供应商(ISV)、服务提供商和学术界更广泛地采用DPU,NVIDIA开发了DOCA(Data Center On A Chip Architecture)。
DOCA是一个由库文件、运行时组件和服务组成的框架,构建在一套经过验证的驱动程序之上。其中一些库与开源项目相关,而另一些则是NVIDIA独有的。正如CUDA为GPU编程提供了抽象化一样,DOCA为DPU编程提供了更高级别的抽象化。
图3
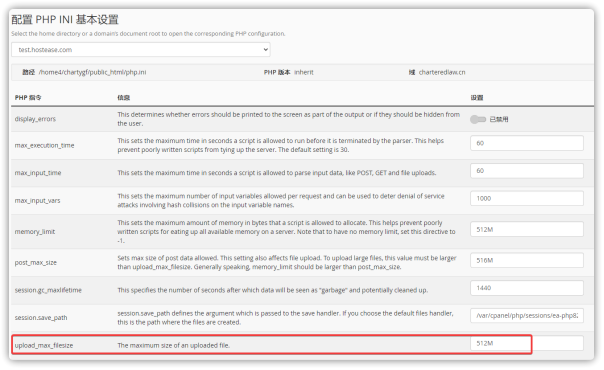
如上图所示,DOCA软件栈包括驱动程序、库、服务代理和参考应用。NVIDIA 提供的软件栈包含两部分内容,一部分是面向开发者的 DOCA SDK,另一部分是用于实现开箱即用部署的 DOCA Runtime 软件。
从软件栈上层看,流量网关库能够实现一个建立在数据路径 SFT 上的硬件加速网关,为过滤和分发网络流量的网关应用提供了更高级别的抽象化。在存储方面,DOCA 支持用户态库开源 SPDK。在 HPC 和 AI 方面,DOCA 初期加入了作为运行时组件的统一集合通信(UCC)库,在未来版本中还将加入 SDK 支持。
DOCA应用体验:
DNS过滤应用程序被设计为在BlueField-2 DPU实例上运行。DPU拦截来自网络的流量(入站流量),并根据流量分类来决定是将其传递给Arm处理器(根据列表类型过滤接收到的数据包),还是通过发夹转发到出口端口,整个系统设计如图4所示。
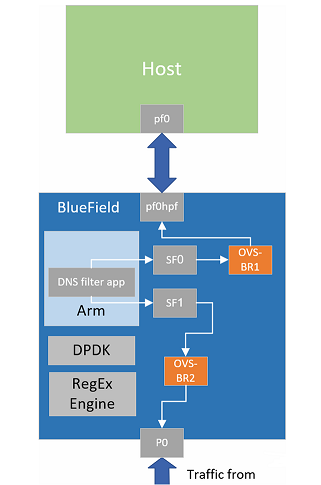
图4
DNS过滤器运行在DOCA Flow之上,用于对DNS请求进行分类。然后,它利用硬件正则表达式引擎,根据域名列表规则(编译后的正则表达式)查找匹配项。
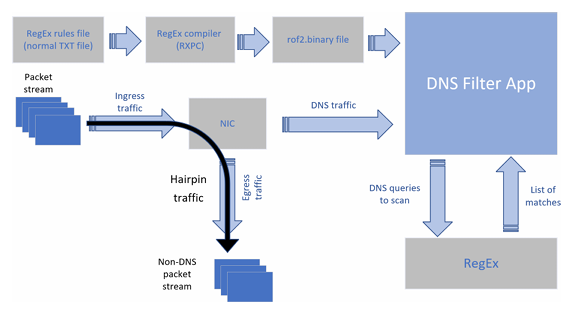
图5
以下是DNS过滤应用程序的工作流程:
- 用户将正则表达式列表规则文件编译成
rof2.binary文件。 - 正则表达式二进制规则文件被加载到正则表达式引擎中。
- 通过管道识别入站数据包类型,这些管道封装了流规则匹配模式和动作。
- DNS过滤应用程序为每个端口构建三个管道:DNS丢弃管道、DNS转发管道和发夹管道。除了丢弃管道外,每个管道只包含一个条目。丢弃管道在运行时包含许多条目,每个条目代表一个被丢弃的数据包。在应用程序初始化和配置之后,接受任何流量之前,管道是空的。
- 丢弃管道匹配已经被阻止的DNS数据包以丢弃它们。发夹管道匹配每个数据包(无遗漏)。丢弃管道作为根管道,DNS转发管道作为丢弃管道的转发未命中组件,发夹管道作为DNS转发管道的转发未命中组件。
操作流程:
1.解析应用程序参数。
doca_argp_init();
a).初始化arg解析器资源。
b).注册DOCA通用旗帜。
Register_dns_filter_params();
c).注册DNS过滤器应用程序标志。
doca_argp_start();
d).解析DPDK标志并调用rte_eal_init()函数。
e)解析应用程序标记。
2.DPDK初始化。
dpdk_init();
a).初始化DPDK端口,包括mempool分配。
b).如果需要,可以初始化发夹队列。
c).将每个端口的发夹队列绑定到其对等端口。
3.DNS过滤器初始化。
dns_filter_init();
a).DOCA流量和DOCA流量端口初始化。
b).为两个端口创建发夹管道。该管道包括一个与每种类型的数据包匹配的条目(无遗漏), 并通过发夹将其转发到出口端口。
c).为两个端口创建DNS转发管道。构建的管道有一个条目用于匹配DNS流量并将其 转发到Arm。此外,如果DNS条目不匹配(例如,对于每个非DNS包,包将被转发), 则使用hairpin管道进行转发。
d).创建掉包管道,作为两个端口的根管道。开始时,管道是空的。但随着应用程序的 运行,它会添加掉包的条目。此外,DNS转发管道用于转发,如果掉包管道条目不匹 配。
e).DOCA RegEx初始化。
f).用已编译的规则文件配置RegEx。
4.处理和过滤DNS包。
dns_worker_lcores_run()
a).Arm上接收到的所有数据包都是DNS数据包,而非DNS数 据包则通过使用允许 过滤DNS数据包的发夹转发到出口端口。
b).提取您所查询的DNS。
c).将DNS查询作为作业发送到RegEx引擎:
d).根据RegEx响应筛选DNS包。
e).如果需要,可通过向DNS删除管道添加条目来阻止数据包。
5.DNS过滤器被销毁。
dns filter destroy();
a).释放所有分配的资源。
b).释放提供所有DOCA RegEx资源。
6.Arg解析器销毁。
doca_argp_destroy()
a).释放DPDK资源。
具体步骤:DNS过滤器示例二进制文件位置/opt/mellanox/doca/applications/ dns_filter/bin/doca_dns_filter,
构建所有应用程序:
打开终端并导航到应用程序目录:
cd /opt/mellanox/doca/applications/
使用Meson构建系统进行配置:
meson build
使用Ninja构建所有应用程序:
ninja -C build
如果仅构建DNS过滤器应用程序:
编辑构建选项:/opt/mellanox/doca/applications/meson_option.txt。
将 enable_all_applications 设置为 false。
将 enable_dns_filter 设置为 true。
运行与步骤2相同的命令来配置和构建:
meson build
ninja -C build
注意:
构建成功后,doca_dns_filter二进制文件将创建在./build/dns_filter/src/目录下。
应用实例:
这里使用文本文件指定列表来添加url,并创建签名数据库将其添加到dpi引擎,使用dpdk库中的状态表模块可以识别分类入口数据流量。
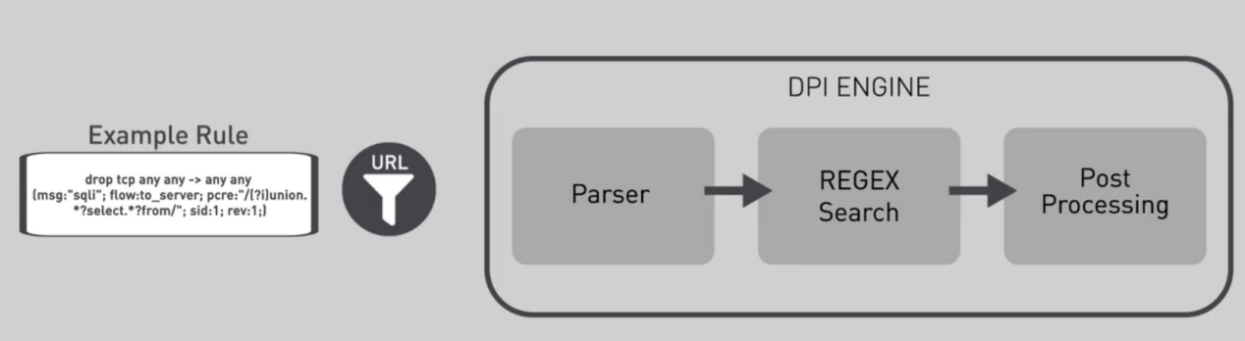
图6

图7
现在让我们将此数据包从对端服务器发送到 DPU

图8
我们可以看到,DPU 已将数据包识别为匹配签名ID 1

图9
当尝试访问被阻止的 URL时,将会被识别和过滤流量,随后的数据包将被丢弃。主机完全不知道该过程并于此过程隔离。
图10
总结一下DNS过滤器应用程序的包处理流程:
- 每个接收到的数据包首先与丢弃管道进行匹配检查。如果匹配成功,则数据包被丢弃。
- 如果在丢弃管道中没有匹配(未命中),则数据包会被检查与DNS转发管道进行匹配。如果在DNS转发管道中匹配成功,数据包将被转发到处理器。
- 如果在DNS转发管道中仍然没有匹配(再次未命中),数据包将被转发到发夹管道进行匹配处理。
这种处理流程确保了数据包根据预定义的规则进行分类和处理,优化了DNS流量的管理和安全性。
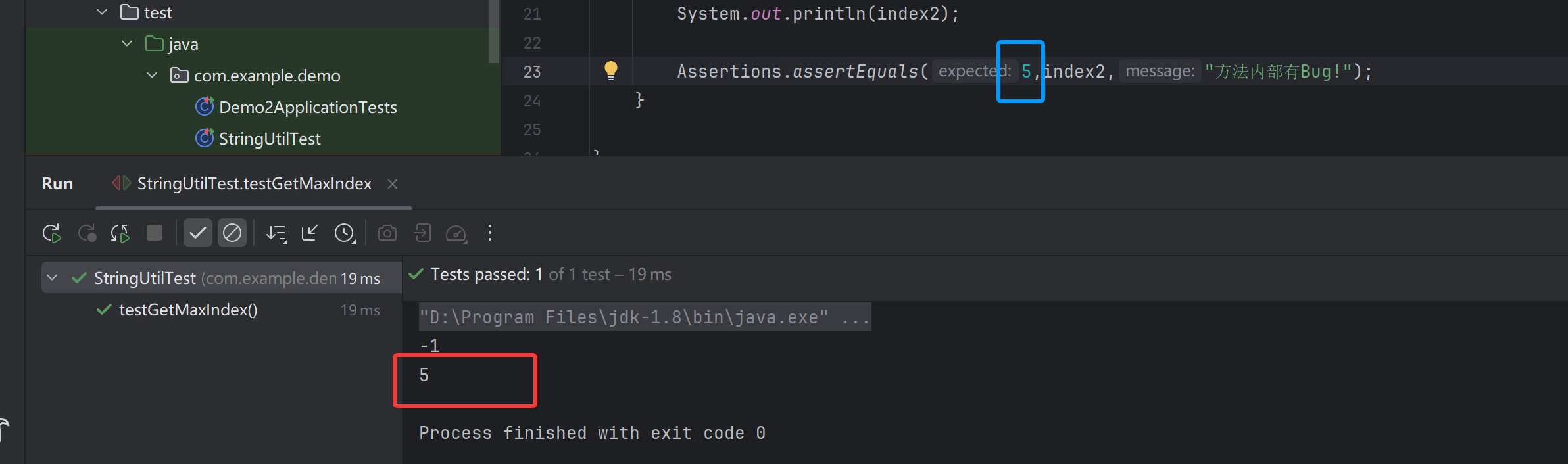

![[Java] 泛型](https://i-blog.csdnimg.cn/direct/911a2ff91a594165a7a304322a2075e3.png)