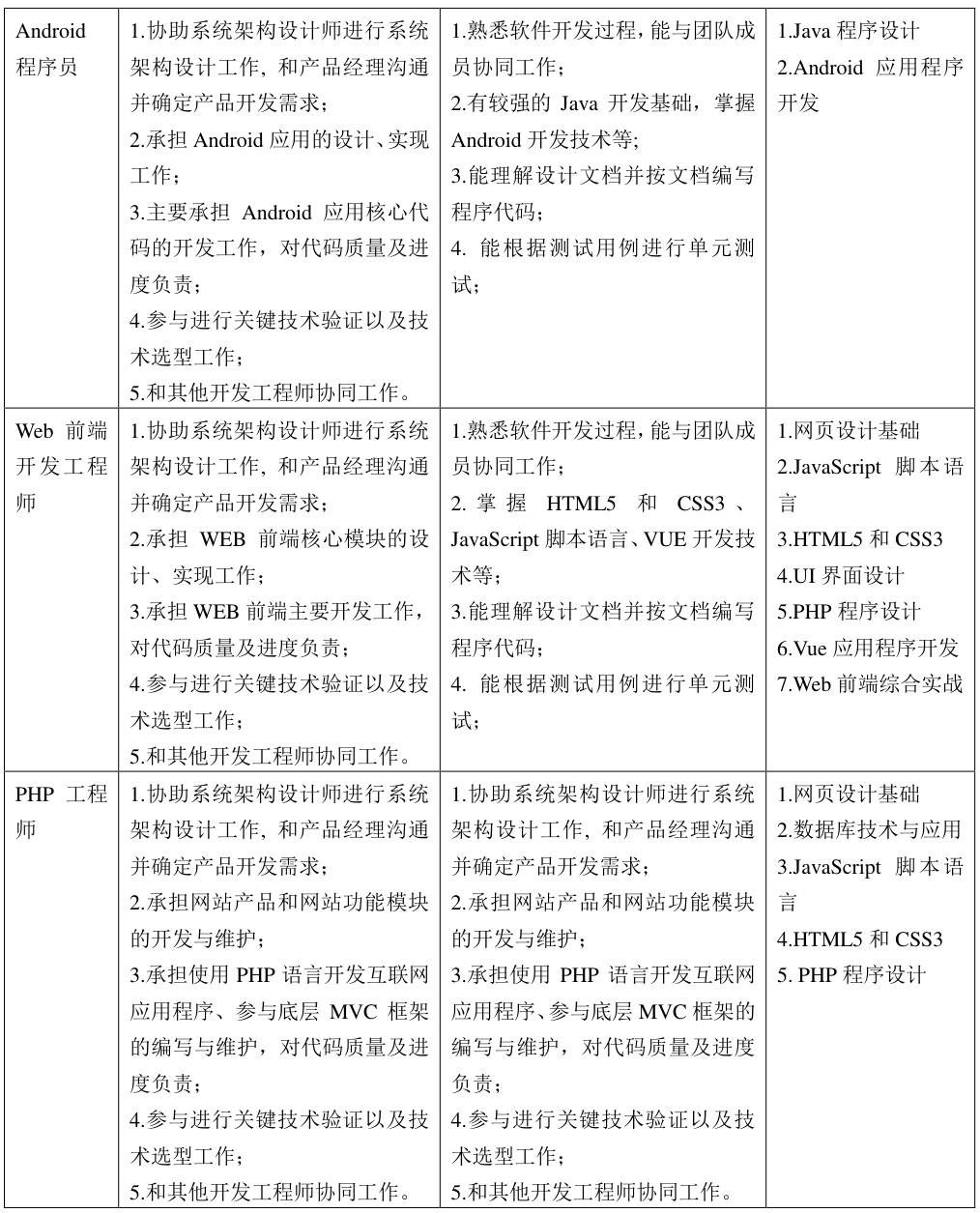
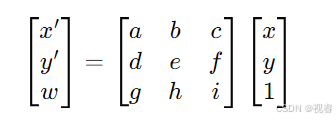解决容器 GPU 设备映射问题,实现 AI 应用加速
🔗 官方文档:NVIDIA Container Toolkit GitHub
常见错误排查
若在运行测试容器时遇到以下错误:
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]
或
docker: Error response from daemon: unknown or invalid runtime name: nvidia
请按本教程完成 NVIDIA Container Toolkit 的安装与配置。
一、环境准备
1.1 验证 NVIDIA 驱动状态
nvidia-smi
预期输出(注意右上角显示的 CUDA 版本):
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-------------------------------+----------------------+----------------------+
问题处理:
-
若命令未找到或提示驱动未安装,请访问 NVIDIA 驱动下载中心
-
Ubuntu 快速安装驱动命令:
sudo apt install nvidia-driver-550-server
二、安装 NVIDIA Container Toolkit
2.1 添加官方软件源
# 安装必要工具
sudo apt-get update
sudo apt-get install -y curl gnupg
# 导入 NVIDIA GPG 密钥
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
# 添加软件源(适配 Ubuntu 24.04)
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
2.2 安装 Toolkit 组件
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
📘 官方安装指南:NVIDIA Container Toolkit Installation Docs
三、配置 Docker 运行时
3.1 生成运行时配置
sudo nvidia-ctk runtime configure --runtime=docker
该命令会自动修改 Docker 配置文件 /etc/docker/daemon.json,添加以下内容:
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
3.2 重启 Docker 服务
sudo systemctl restart docker
四、功能验证
4.1 运行 GPU 测试容器
docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
关键验证点:
- 容器内输出的 GPU 信息与宿主机
nvidia-smi一致 - 无任何错误提示
成功输出示例:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-------------------------------+----------------------+----------------------+
五、高级配置技巧
5.1 指定 GPU 数量
# 仅使用 2 块 GPU
docker run --rm --gpus 2 nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
# 按设备序列号指定
docker run --rm --gpus '"device=0,1"' nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
5.2 持久化模式设置
# 启用持久化模式(防止 GPU 休眠)
sudo nvidia-smi -pm 1
🔧 GPU 管理工具:nvidia-smi 官方文档
六、使用场景
NVIDIA Container Toolkit 适用于以下典型容器化 AI 应用场景:
-
✅ 大模型推理部署:如部署 LLaMA、ChatGLM、BERT 等模型,使用 GPU 显著提升响应速度与并发处理能力。
-
✅ 深度学习训练任务:如使用 PyTorch、TensorFlow、JAX 等框架在容器中进行分布式训练,便于复现实验环境。
-
✅ 多模型并行服务:结合
--gpus参数可以精确分配 GPU 资源,实现在单机多服务并行部署,提升资源利用率。 -
✅ 视频处理与 AI 编解码:结合 FFmpeg + CUDA / TensorRT 加速视频转码、超分辨率、目标检测等任务。
-
✅ 开发调试环境隔离:避免主机污染、实现多人多项目的 GPU 环境解耦,提升研发效率与可维护性。
七、总结
-
Docker 原生不支持 GPU,需要借助 NVIDIA Container Toolkit 提供的运行时扩展
nvidia-container-runtime实现 GPU 透传。 -
容器运行时可获得 几乎无性能损耗的 GPU 使用能力,适用于从研发到生产的多种场景。
-
配置过程主要包括三步:安装驱动 → 安装 Toolkit → 配置 Docker,每一步都可通过
nvidia-smi验证效果。 -
支持灵活的 GPU 指定方式,便于构建资源隔离的 AI 工作负载。
💡 提示:Toolkit 安装后,
docker run --gpus all成为使用 GPU 容器的标准入口,请确保测试成功后再部署正式任务。