Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~
论文:Differential Transformer
代码:https://github.com/microsoft/unilm/tree/master/Diff-Transformer
0、摘要
Transformer 倾向于过度分配注意力到无关的上下文。在这项工作中,本文引入了 DIFF Transformer,它放大了对相关上下文的注意力,同时消除了噪声。(大佬的表述总是那么简单朴素~)
具体来说,差分注意力机制(differential attention mechanism)将注意力分数计算为两个独立的 softmax 注意力图之间的差。减法可以消除噪声,促进稀疏注意力模式的出现。
语言建模的实验结果表明,DIFF Transformer 在模型规模和训练 tokens 的各种设置中都优于 Transformer。更有趣的是,它在实际应用中提供了显著的优势,如长上下文建模、关键信息检索、幻觉缓解、上下文学习和激活异常值的减少。
通过减少对无关上下文的干扰,DIFF Transformer 可以减轻问题回答和文本摘要中的幻觉。在上下文学习中,DIFF Transformer 不仅提高了准确率,还增强了对顺序排列的鲁棒性,这曾被认为是一个长期存在的稳定性问题。这些结果表明,DIFF Transformer 是一种非常有效且极具潜力的架构,能够推动大型语言模型的发展。(有种 ResNet 那种大道至简的感觉)
1、引言
1.1、当前挑战
(1)Transformer 的核心是注意力机制,它利用 Softmax 函数来衡量序列中各个 tokens 的重要性;
(2)最近的研究表明,大语言模型在准确检索上下文中的关键信息方面面临挑战;
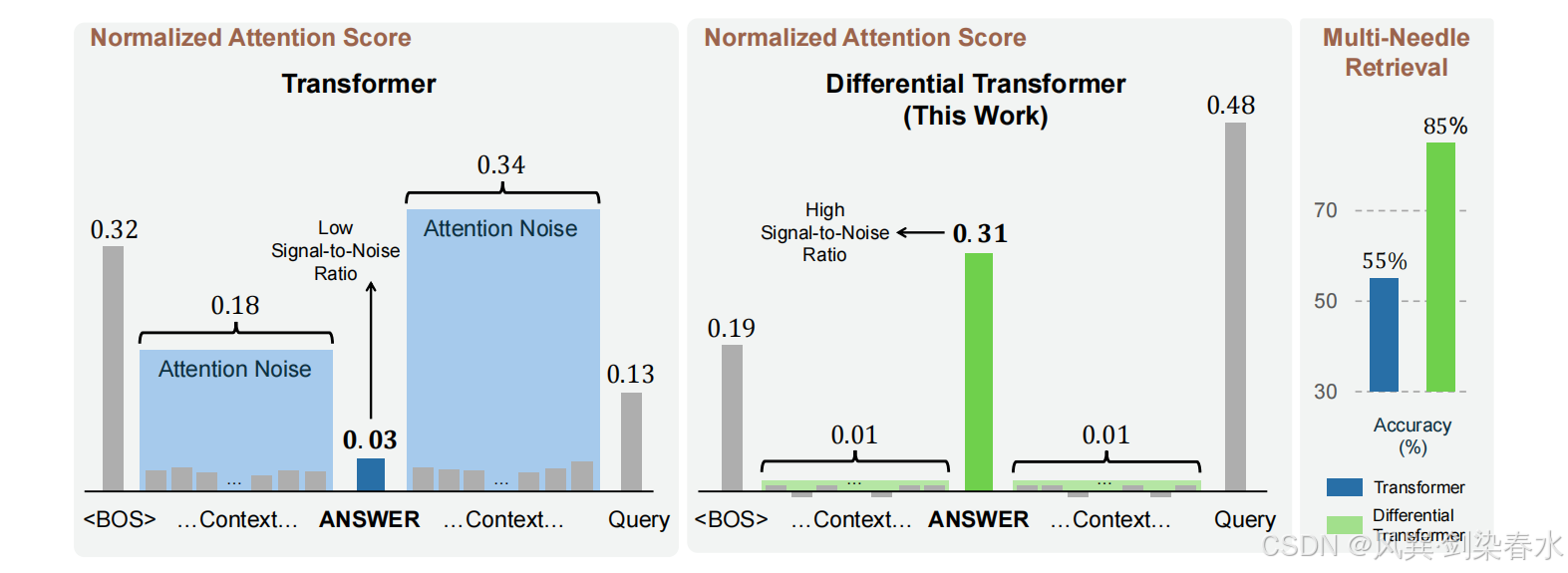
(3)Transformer 倾向于只将一小部分注意力分数分配给正确答案,而过度关注无关的上下文(如 图1 所示);
(4)分配在无关上下文上不可忽略的注意力分数,最终淹没了正确答案。本文将这些多余的分数称为注意力噪声。
Figure 1 | Transformer 经常过度关注无关的上下文:DIFF Transformer 强化了对答案片段的注意力,同时消除了噪声,从而提升了上下文建模的能力;
1.2、本文贡献
(1)介绍了差分 Transformer(DIFF Transformer),这是一种大型语言模型的基础架构。差分注意力机制被提出用于通过差分去噪,消除注意力噪声;
(2)与 Transformer 相比,DIFF Transformer 对正确答案的评分显著更高,而对无关上下文的评分则低得多, 图1右侧 显示,所提出的方法在检索能力方面取得了显著改进;
(3)规模扩展曲线表明,DIFF Transformer 只需要大约 65% 的模型大小或训练 tokens 数量,就能达到与 Transformer 相当的语言建模性能,此外,DIFF Transformer 在各种下游任务中的表现也优于 Transformer;
2、Differential Transformer
本文提出差分 Transformer(DIFF Transformer)作为序列建模的基础架构,例如大型语言模型(LLM)。本文以解码器模型为例来描述该架构,模型由 L L L 个 DIFF Transformer 层堆叠而成。
给定输入序列 x = x 1 . . . , x N x = x_1..., x_N x=x1...,xN,将输入嵌入打包到 X 0 = [ x 1 , ⋅ ⋅ ⋅ , x N ] ∈ R N × d m o d e l X^0 = [x1,···,xN ]∈\mathbb{R}^{N×d_{model}} X0=[x1,⋅⋅⋅,xN]∈RN×dmodel 中,其中 d m o d e l d_{model} dmodel 表示隐藏维度。进一步对输入进行上下文化处理,以获得输出 X L X^L XL,即 X l = D e c o d e r ( X l − 1 ) , l ∈ [ 1 , L ] X^l =Decoder(X^{l−1}),l∈[1, L] Xl=Decoder(Xl−1),l∈[1,L]。每一层由两个模块组成:一个差分注意力模块(differential attention module),随后是一个前馈网络模块(feed-forward network module)。
与 Transformer 相比,主要区别在于用差分注意力(differential attention)替换了传统的 softmax 注意力,而宏观布局保持不变。本文还采用了 pre-RMSNorm 和 SwiGLU,作为 LLaMA 之后的改进。
2.1、Differential Attention
差分注意力机制将查询向量、键向量和值向量映射到输出。利用查询向量和键向量来计算注意力分数,随后计算值向量的加权和。其关键设计在于,采用一对 Softmax 函数来消除注意力分数中的噪声。
具体来说,给定输入
X
∈
R
N
×
d
m
o
d
e
l
X \in \mathbb{R}^{N×d_{model}}
X∈RN×dmodel,首先将它们投影到查询、键和值,
Q
1
,
Q
2
,
K
1
,
K
2
∈
R
N
×
d
,
V
∈
R
N
×
2
d
Q_1,Q_2,K_1,K_2 \in \mathbb{R}^{N×d},V \in \mathbb{R}^{N×2d}
Q1,Q2,K1,K2∈RN×d,V∈RN×2d。然后,差分注意力算子
D
i
f
f
A
t
t
n
(
⋅
)
DiffAttn(·)
DiffAttn(⋅)通过以下方式计算输出:
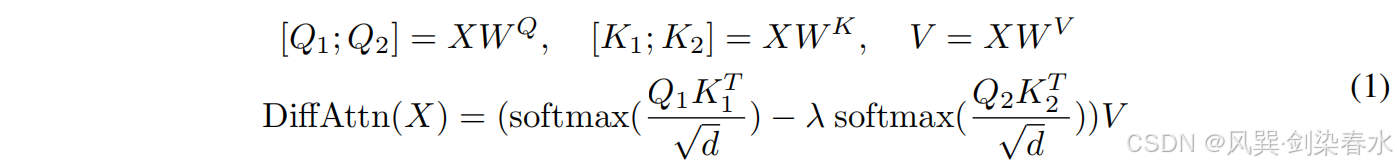
其中
W
Q
,
W
K
,
W
V
∈
R
d
m
o
d
e
l
×
2
d
W^Q,W^K,W^V \in \mathbb{R}^{d_{model}×2d}
WQ,WK,WV∈Rdmodel×2d 为参数,
λ
\lambda
λ 为可学习标量。为了同步学习动态,将标量
λ
\lambda
λ 重新参数化为:
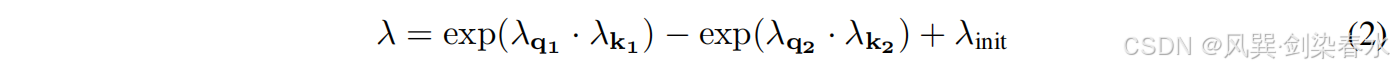
其中 λ q 1 , λ k 1 , λ q 2 , λ k 2 ∈ R d λ_{q1},λ_{k1},λ_{q2},λ_{k2} \in \mathbb{R}^d λq1,λk1,λq2,λk2∈Rd 是可学习向量, λ i n i t ∈ ( 0 , 1 ) λ_{init}∈(0,1) λinit∈(0,1) 是用于 λ \lambda λ 初始化的常数。本文通过实验发现 λ i n i t = 0.8 − 0.6 × e x p ( − 0.3 ⋅ ( l − 1 ) ) λ_{init} = 0.8−0.6×exp(−0.3·(l−1)) λinit=0.8−0.6×exp(−0.3⋅(l−1)) 在实际应用中效果良好,其中, l ∈ [ 1 , L ] l∈[1,L] l∈[1,L] 表示层索引。在实验中,它被用作默认策略。本文还探索了使用相同的 λ i n i t λ_{init} λinit(例如 0.8)对所有层进行初始化,作为另一种初始化策略。如消融研究(第 3.8 节)所示,不同的初始化策的性能相对稳健。
差分注意力机制通过计算两个 Softmax 注意力函数之间的差异来消除注意力噪声。这一思想类似于电气工程中提出的差分放大器,其中两个信号之间的差异被用作输出,从而可以抵消输入的共模噪声。Naderi 等人也证明了差分注意力机制可以使注意力矩阵的谱分布更加均衡,从而有效地解决了秩坍塌问题。此外,降噪耳机的设计也是基于类似的思想。正如附录 A 所描述的,可以直接使用 FlashAttention,这显著提高了模型的效率。
Figure 2 | 多头差分注意力:每个头使用两个 Softmax 图之间的差异来消除注意力噪声。
λ
\lambda
λ 是一个可学习的标量,初始化为
λ
i
n
i
t
λ_{init}
λinit。GroupNorm 对每个头独立应用归一化。在 GroupNorm 后使用一个固定的乘数
(
1
−
λ
i
n
i
t
)
(1-λ_{init})
(1−λinit),以使梯度流动与 Transformer 对齐;
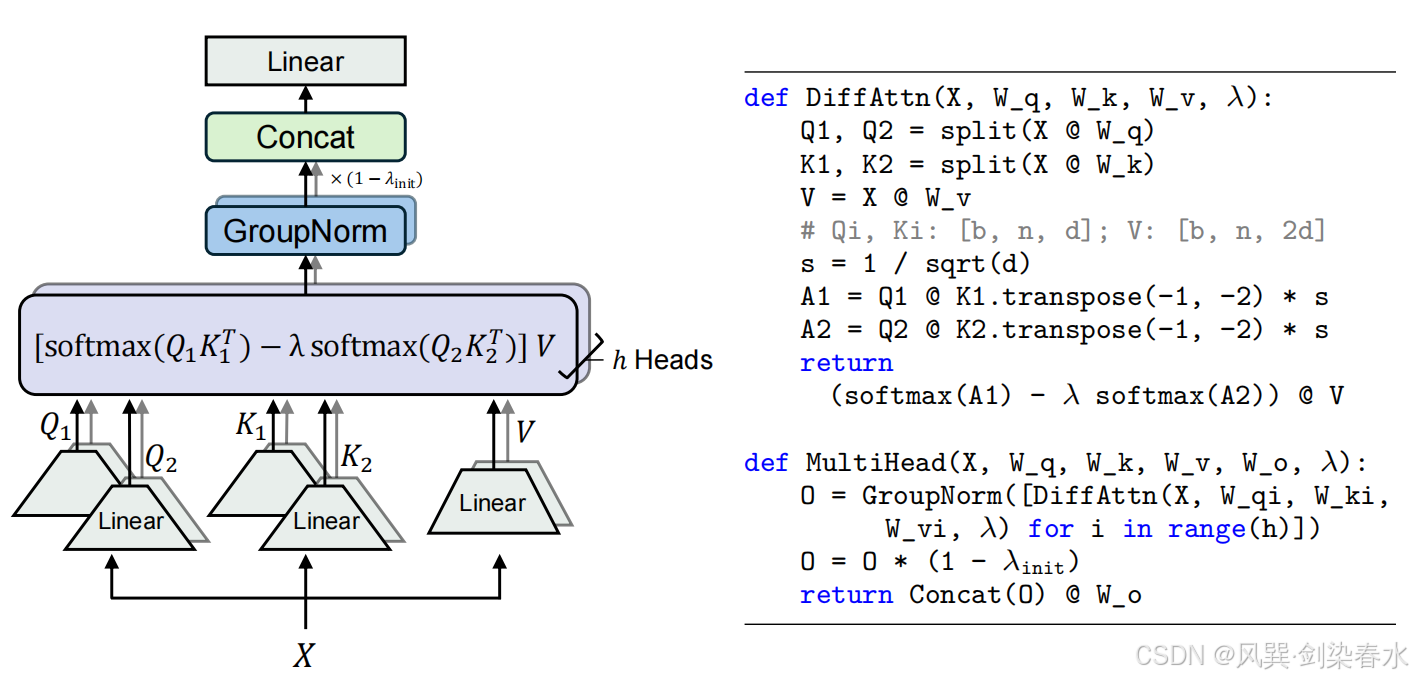
Multi-Head Differential Attention
在 Differential Transformer 中也使用了多头机制,设 h h h 表示注意力头的数量。使用不同的投影矩阵 W i Q , W i K , W i V , i ∈ [ 1 , h ] W_i^Q, W_i^K, W_i^V, i∈[1,h] WiQ,WiK,WiV,i∈[1,h] 用于不同 head。标量 λ \lambda λ 在同层的 head 之间共享。然后 head 输出被归一化并投影到最终结果,如下所示:
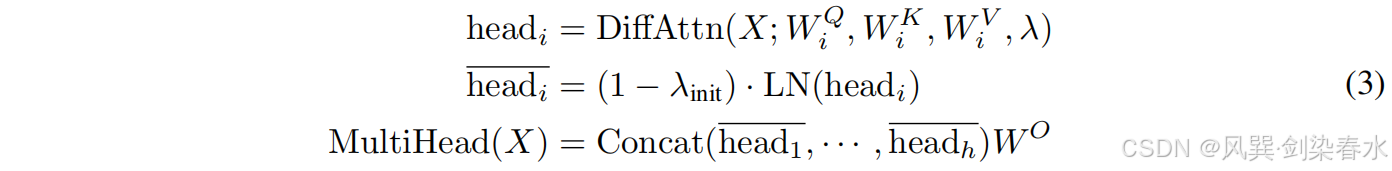
其中 λ i n i t λ_{init} λinit 是公式 (2) 中的常数标量, W O ∈ R d m o d e l × d m o d e l W^O∈R^{d_{model}×d_{model}} WO∈Rdmodel×dmodel 是一个可学习的投影矩阵, L N ( ⋅ ) LN(·) LN(⋅) 对每个头使用 RMSNorm, C o n c a t ( ⋅ ) Concat(·) Concat(⋅) 沿着通道维度将头连接在一起。
本文使用一个固定的乘数 ( 1 − λ i n i t ) (1-λ_{init}) (1−λinit) 作为 L N ( ⋅ ) LN(·) LN(⋅) 的尺度,使梯度与 Transformer 保持一致。附录 G 证明了整体梯度流与 Transformer 保持相似。这一优良特性使我们能够直接继承类似的超参数,并确保训练的稳定性。本文设头的数量为 h = d m o d e l / 2 d h = d_{model}/2d h=dmodel/2d,其中 d d d 等于 Transformer 的头维度,这样就可以对齐参数数量和计算复杂度。
Headwise Normalization
图 2 使用了 G r o u p N o r m ( ⋅ ) GroupNorm(·) GroupNorm(⋅) 来强调 L N ( ⋅ ) LN(·) LN(⋅) 是独立应用于每个头的。由于差分注意力倾向于产生更稀疏的模式,因此不同头之间的统计信息更加多样化。 L N ( ⋅ ) LN(·) LN(⋅) 操作符在拼接之前对每个头进行归一化,以改善梯度统计信息。
2.2、总体结构
整体架构由
L
L
L 层组成,每层包含一个多头差分注意力模块和一个前馈网络模块。本文将 Differential Transformer 层描述为:

其中
L
N
(
⋅
)
LN(·)
LN(⋅) 是 RMSNorm,
S
w
i
G
L
U
(
X
)
=
(
s
w
i
s
h
(
X
W
G
)
⊙
X
W
1
)
W
2
SwiGLU(X) =(swish(XW^G)⊙XW_1)W_2
SwiGLU(X)=(swish(XWG)⊙XW1)W2 和
W
G
,
W
1
∈
R
d
m
o
d
e
l
×
8
3
d
m
o
d
e
l
,
W
2
∈
R
8
3
d
m
o
d
e
l
×
d
m
o
d
e
l
W^G, W_1∈\mathbb{R}^{d_{model}×\frac{8}{3} d_{model}}, W_2∈\mathbb{R}^{\frac{8}{3}d_{model}×d_{model}}
WG,W1∈Rdmodel×38dmodel,W2∈R38dmodel×dmodel 是可学习矩阵。
3、实验与结果
本文从以下几方面对用于大型语言模型的 Differential Transformer 进行了评估。首先,在各种下游任务中将所提出的架构与 Transformer 进行比较(第3.1节),并研究扩大模型规模和训练标记数量的特性(第3.2节)。其次,将序列长度扩展至 64K,并评估其长序列建模能力(第3.3节)。第三,展示了关键信息检索、上下文幻觉评估以及上下文学习的结果(第3.4至3.6节)。第四,我们表明本文认为,与 Transformer 相比,Differential Transformer 能够减少模型激活中的异常值(第3.7节)。最后,本文针对各种设计选择进行了广泛的消融研究(第3.8节)。
3.1、语言模型评估
Table 1 | :使用 Eval Harness 来比较经过良好训练的 Transformer 语言模型的准确率。我们将 3B 模型的训练标记数量扩展到 1 万亿。StableLM-3B-4E1T 的 1T 结果取自其技术报告;

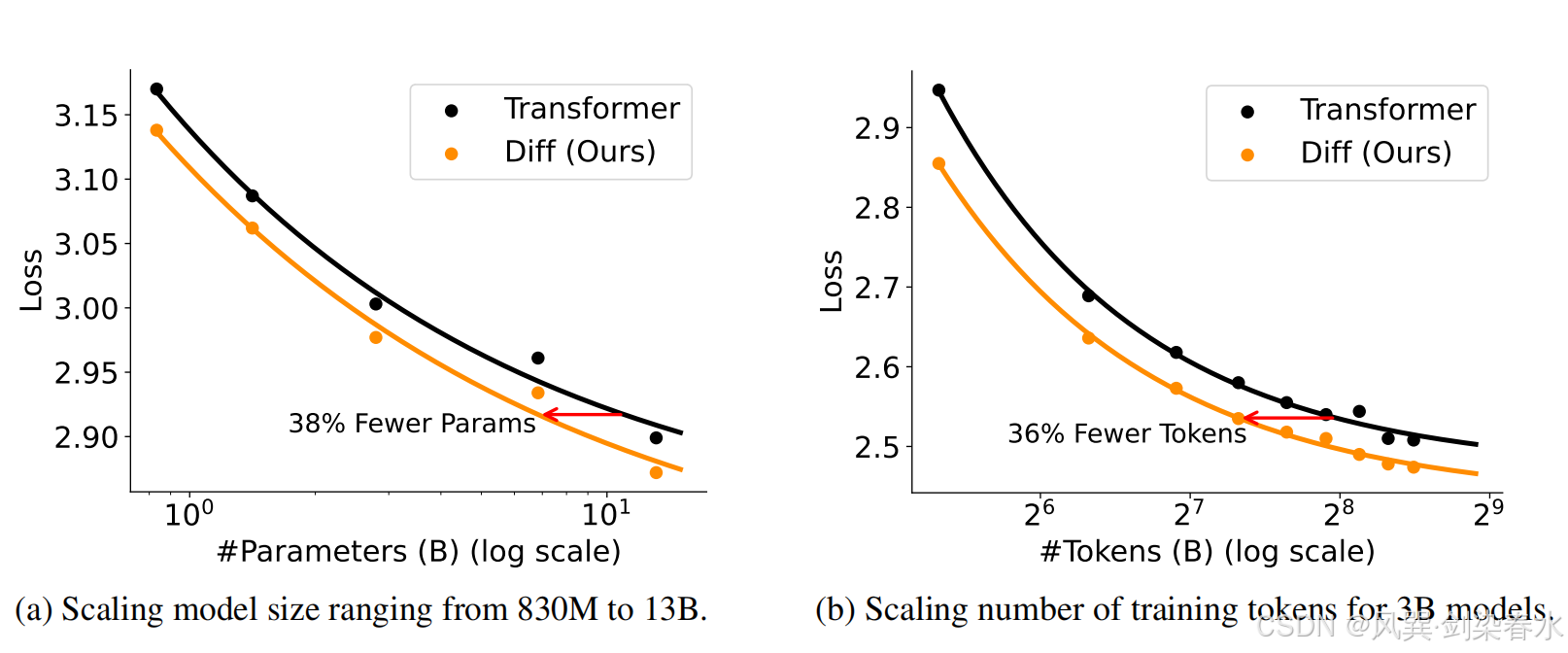
3.2、与 Transformer 相比的可扩展性
Figure 3 | 扩大参数数量和训练标记数量时的语言建模损失:DIFF Transformer 只需大约 65% 的模型规模或训练标记数量,就能达到与 Transformer 相当的性能;
3.3、长语境评估
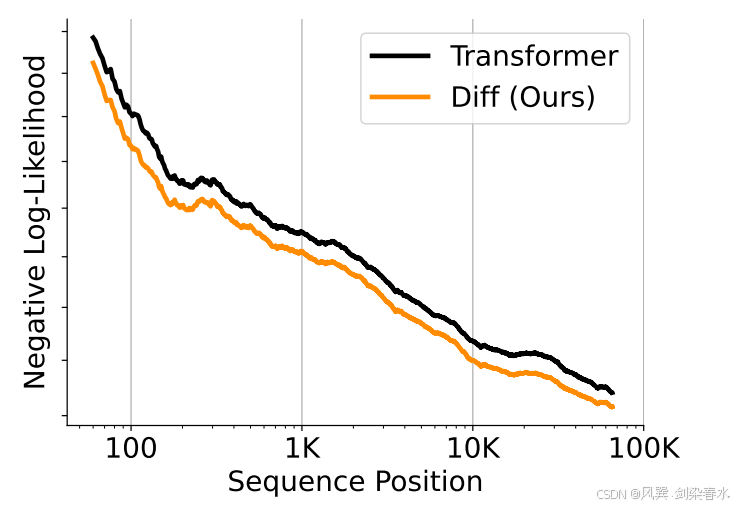
Figure 4 | 在图书数据上的累积平均负对数似然(越低越好):DIFF Transformer 更有效地利用了长文本上下文;
3.4、关键信息检索
Table 2 | 在 4K 长度下的多针检索准确率,结果对答案针的位置进行了平均:
N
N
N 表示针的数量,而
R
R
R 表示查询城市的数量;
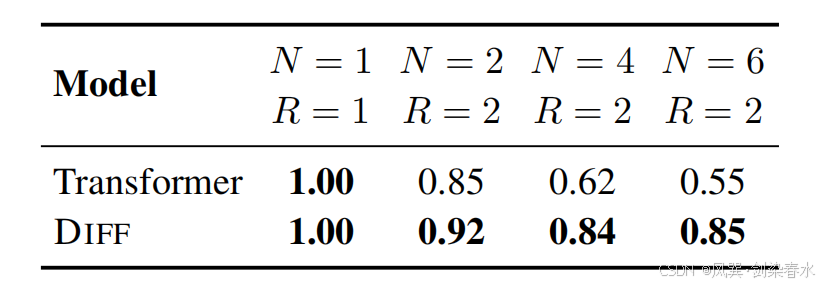
Figure 5 | 在 64K 长度下的多针检索结果:
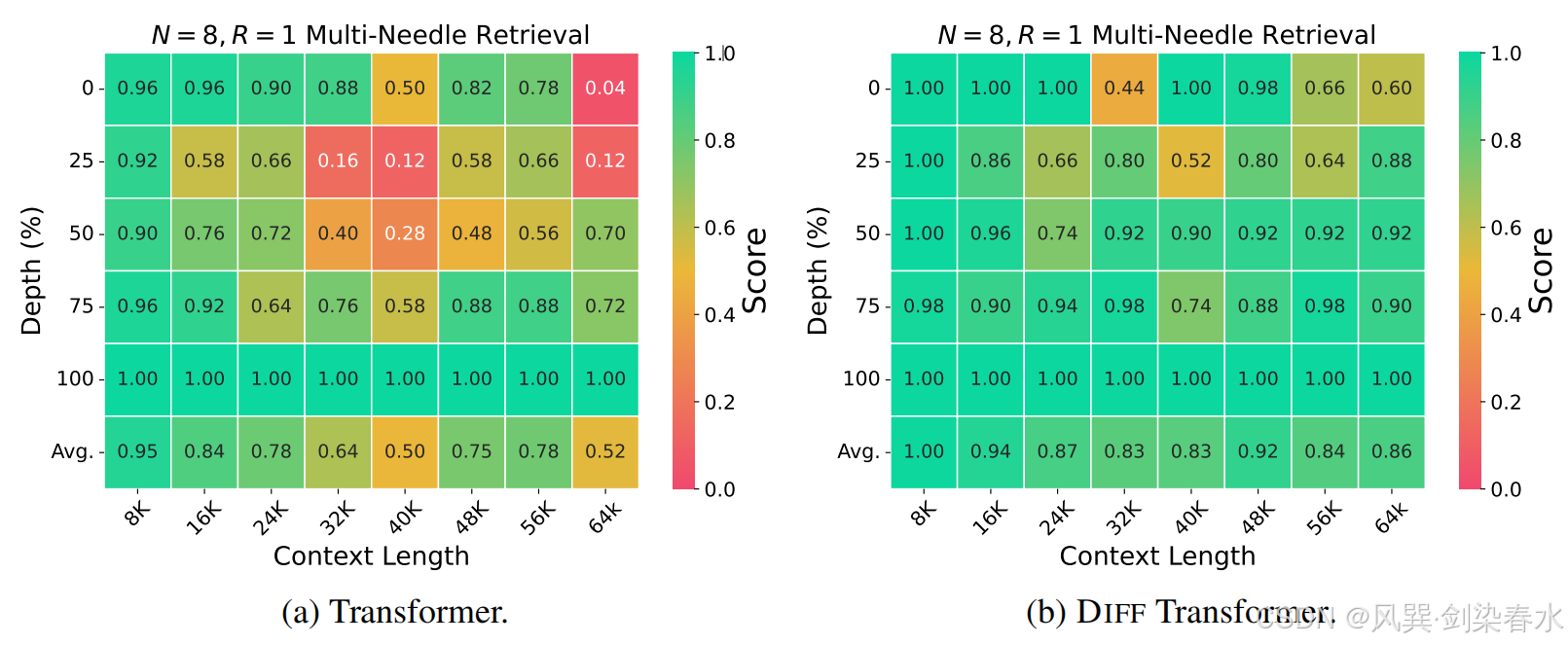
Table 3 | 在关键信息检索任务中,分配给答案片段和噪声上下文的注意力分数:目标答案被插入到上下文的不同位置(即深度),DIFF Transformer 更多地将注意力分数分配给有用的信息,并有效地消除了注意力噪声;

3.5、情境学习
从两个角度对情境学习进行评估,包括多镜头分类(many-shot classification)和情境学习(in-context learning)的鲁棒性。情境学习是语言模型的基本能力,表明模型利用输入情境的能力。
Figure 6 | 在四个数据集上的 Many-shot in-context learning 准确率:演示示例从单镜头(1-shot)开始,逐渐增加,直到总长度达到 64K 个标记,虚线表示在性能稳定后达到的平均准确率;
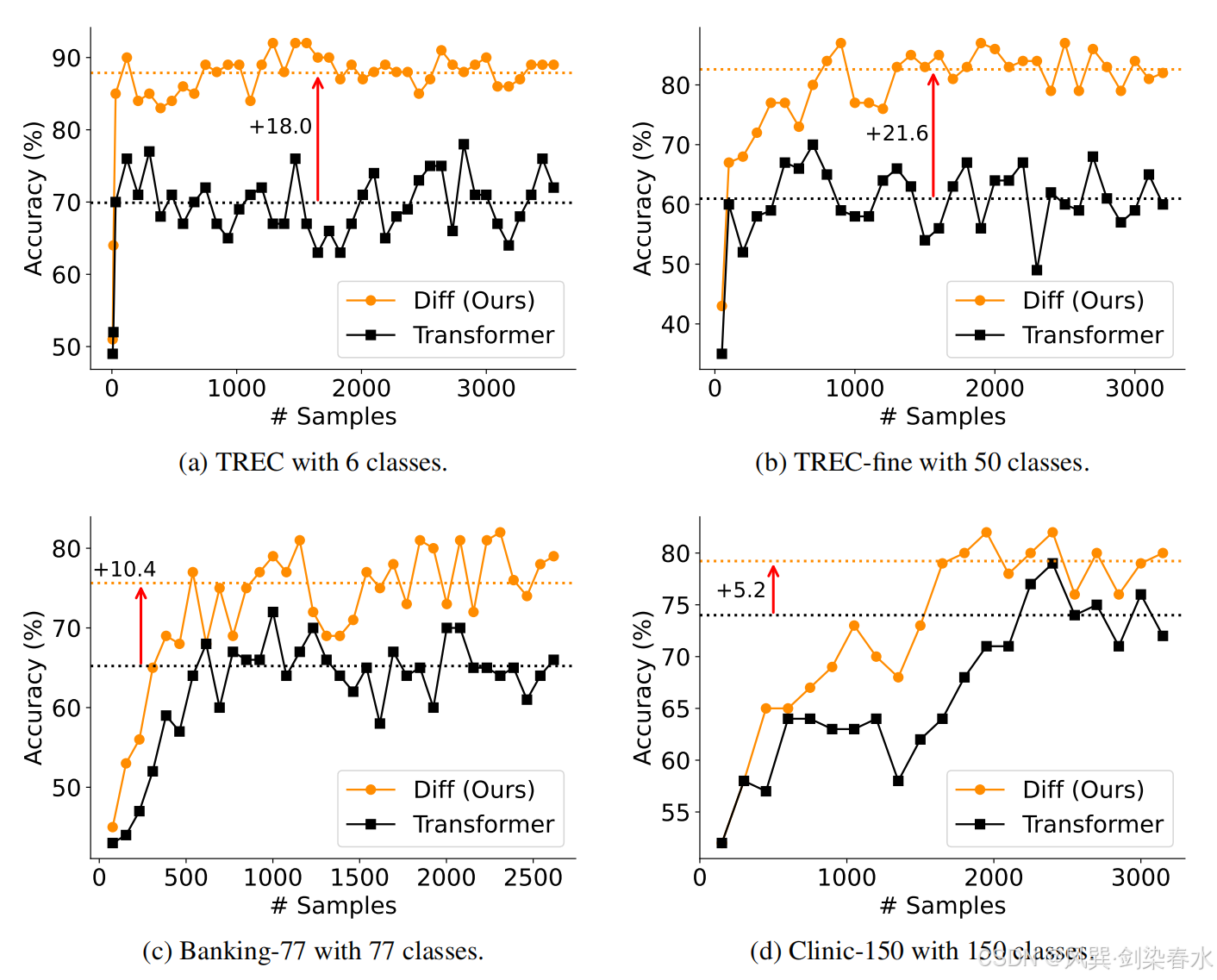
Figure 7 | 在 TREC 数据集上对上下文学习的鲁棒性进行评估:通过改变演示示例的顺序(使用不同的随机种子)来评估准确率,虚线表示最佳结果与最差结果之间的差距,较小的差距表明更强的鲁棒性,评估了两种提示格式;

3.6、上下文幻觉评估
Table 4 | 在文本摘要和问答任务中对上下文幻觉现象的评估:准确率越高,表明幻觉现象越少,本文遵循 Chuang 等人的方法,使用 GPT-4o 进行二元判断,这种方法与人工标注的结果有较高的契合度;

3.7、异常值分析
Table 5 | 注意力分数和隐藏状态的最大激活值:Top 激活值被视为激活异常值,因为它们的数值显著高于中位数,与 Transformer 相比,DIFF Transformer 减少了异常值;
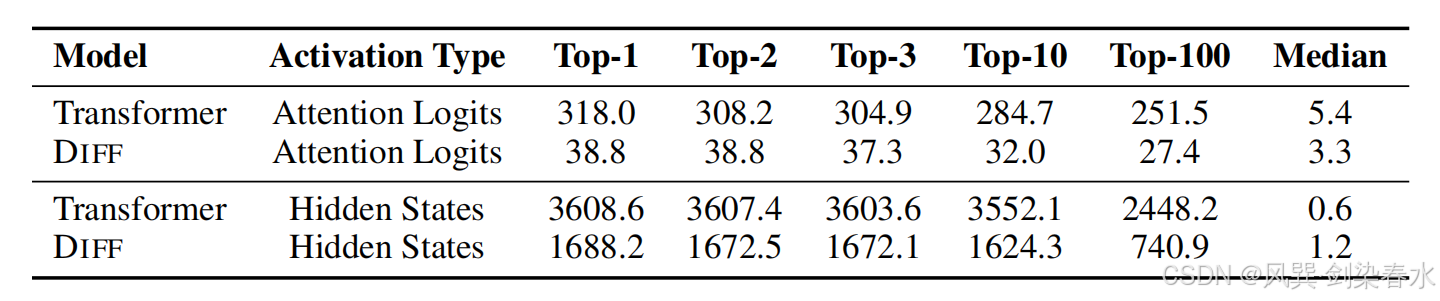
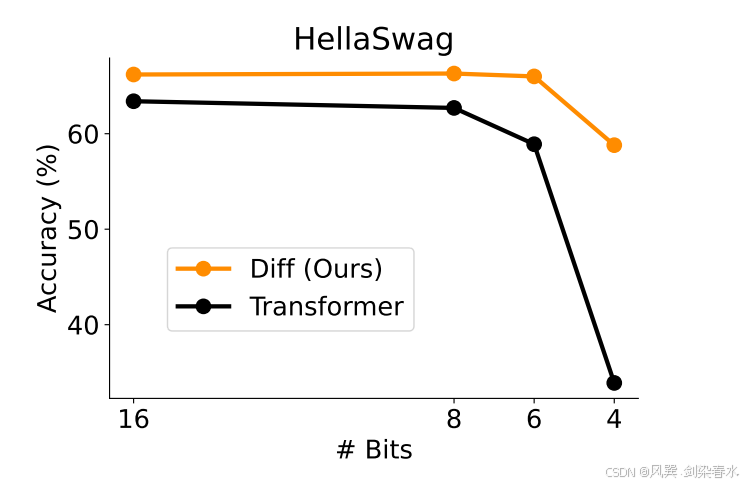
Figure 7 | HellaSwag 数据集上的 Zero-shot 准确率:本文将注意力 logit 从 16 位(即未量化)量化为 8 位、6 位和 4 位;
3.8、消融实验
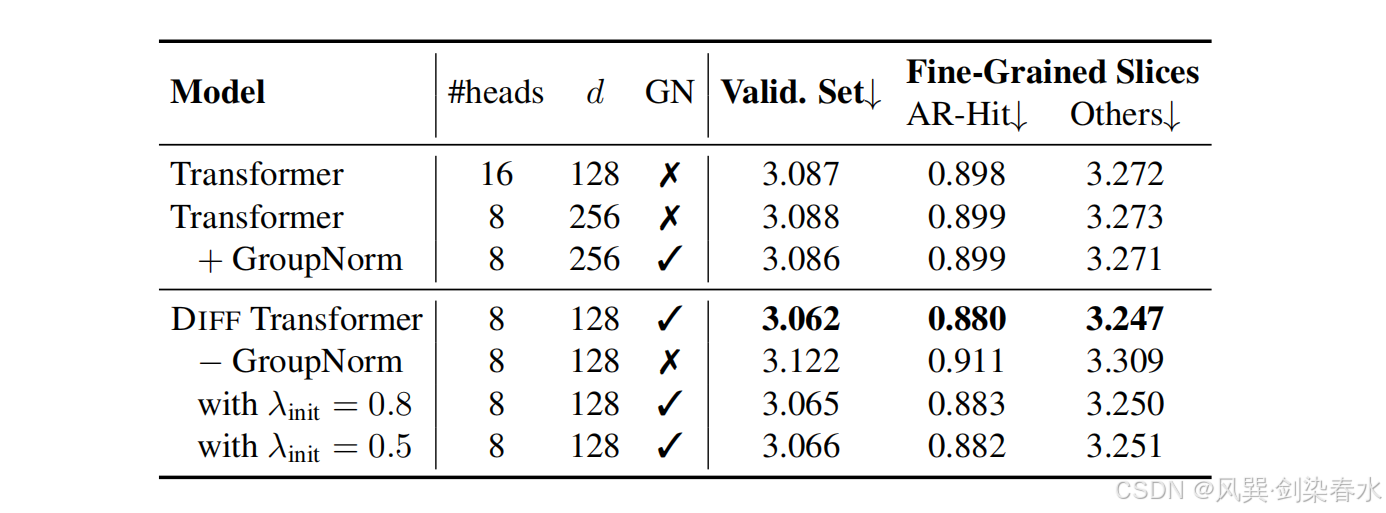
Figure 8 | 1.4B-size 模型的消融研究:在验证集上报告语言建模的损失,还遵循 Arora 等的方法,报告细粒度指标,其中 “AR-Hit” 用于评估在上下文中之前见过的 n-grams,“#Heads” 表示头的数量。“d” 是头的维度。“GN” 表示是否使用了组归一化;
试试? ٩(๑•̀ω•́๑)۶

![[c语言日寄]免费文档生成器——Doxygen在c语言程序中的使用](https://i-blog.csdnimg.cn/direct/556c5a2c798045c6aeacdb24ace3e13e.gif#pic_center)