《基于神经网络实现手写数字分类》
一、主要内容:
1、通过B站陈云霁老师的网课,配合书本资料,了解神经网络的基本组成和数学原理。
2、申请云平台搭建实验环境
3、基于5个不同的实验模块逐步理解实验操作步骤,并实现不同模块代码的补全
4、实验运行阶段,在MobaXterm上进行实验运行,并根据显示的准确率的高低调整实验参数的大小。
二、实验部分:
(一)模型的搭建
在B站系统的学习完《智能计算系统》对应章节的网课的后,对于神经网络的组成我有了更清晰的了解。从机器学习到神经网络的过渡,掌握了从单变量线性回归到多变量线性回归,再到感知机、神经元、激活函数,偏置等概念的深度挖掘,对于深度学习这块知识的了解有了比较明晰的轮廓。
再到后来对于不同具体组成的了解过程中,基于数学公式,对于正向传播、激活函数、损失函数、反向传播等不同概念,掌握了从数学分析的角度出发,对于不同过程中对于不同类常用激活函数和损失函数的优缺点领会深刻。
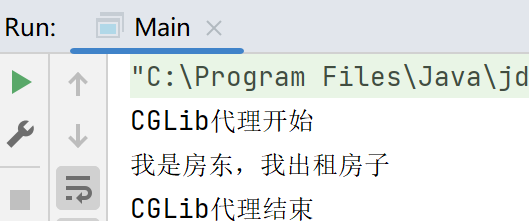
在领会底层数学原理后,基于已有代码的引导,我进行了对于layers_1.py文件当中的不同函数的代码完善,实现FullyConnectedLayer,ReLULayer,SoftmaxLossLayer代码搭建,分别对应了神经网络中的全连接层、激活层、Softmax 损失层的搭建,实现了三层神经网络的底层逻辑。
然后在mnist_mlp_cpu.py文件中,我首先填补了load_mnist 读取和预处理 MNIST 中训练数据和测试数据的对应代码
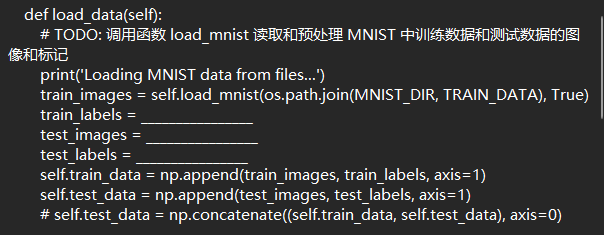
图(1)
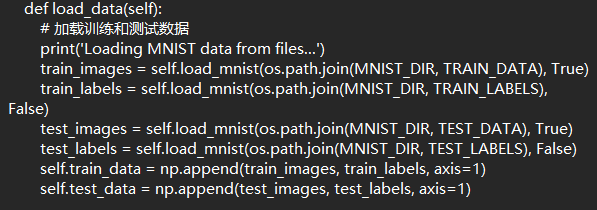
图(2):对于图(1)代码的补全
再进行了基于layer_1.py类函数对于多层感知机模型的搭建

图(3)
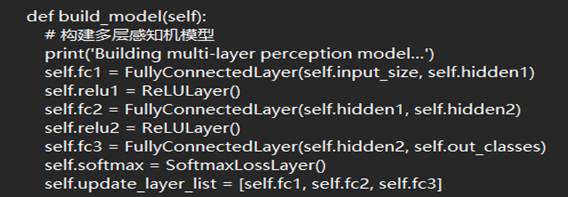
图(4):对于图(3)代码的补全
二、基于准确率对于模型的优化
在完成模型的搭建后,我对于整个模型进行了一些优化,比如说设计了学习率递减的训练模式,不过在后续验证过程中发现这对于模型准确率的影响不大,准确率依旧维持在90%,后来又设计了提取损失函数最小值的模型参数进行保存的函数,对于准确率有3个百分点的提升,最后在参数的设计上,我先是将两个全连接层的神经元个数由32、16提升到128、128,发现准确率的起伏不超过一个点,后来我修改了batch_size,也就是一次训练的样板个数,从100缩减到10-20这个区间内,准确率才再次提高了5个百分点左右,并逐步稳定在97—98%这个范围内,最后我将两个全连接层的神经元个数进行削减,削减到64、32左右,在对于准确率影响不大的基础上加快了训练速度。
在这个阶段的学习中,我额外地了解到了过拟合和正则化的概念,比如利用bagging或者Dropout方法进行正则化,提高模型的泛化能力。同时我也明白了对于数据集而言,和训练集的高度拟合并不一定意味着效果更好,而是意味着模型的泛化能力可能会变差甚至降低许多。在整个实验过程中,我在训练模型的时候有出现过损失函数为0的情况,但实际展现出来的准确率并不是最好的。

图(5)
如图(1)所示,在调整参数的情况下,使模型对于训练集数据完全拟合,但在测试集当中,并没有展现出100%的准确率。并且在后续的学习过程中,有时候损失函数的值极低,但并未等于0的情况下,对于训练集的准确率,反而有提高的趋势。如图(2)所示,该图的损失函数值为0.000001

图(6)
三、基于不同方法对于模型性能的评估
除此之外,我也对于模型精度的评估有了一定的了解,知道了不同模型适合的评估方法,比如留一法交叉验证或者是k-折交叉验证,这些模型的验证方法是从评估该模型的性能的同时考虑泛化性的角度提出的。不过这个实验操作过程中的模型评估方法只是单纯地依靠测试数据集进行准确率的计算。
四、总结
在这段学习过程中,通过B站的网课,我对于深度学习的底层概念,神经网络组成等方面有一个明确地认知。最大的感受其实是深度学习的局限性。在陈老师的课程中,在他讲完基础的人工智能发展历程,从行为主义到符号主义,再到连接主义的这个历史进程中。他提到了当下的主流是连接主义,不可避免地讲到了深度学习的一些问题。即泛化能力差,缺乏推理能力,缺乏可解释性,鲁棒性欠佳。在后续的学习过程中慢慢就会发觉,这些问题其实涵盖了整个学习过程中的不同方面,由问题产生了解决方法,然后再进一步对于深度学习的过程进行优化。
比如泛化能力差,训练模型对于训练集的拟合程度是根据损失函数值的大小进行评估的,而在具体情况中,可能体现为全连接层的层数过多,或者全连接层当中的神经元个数过多,导致高度拟合的情况出现,此时损失函数的值过小,容易导致该训练模型对于训练集过于拟合,也就是过拟合的概念的产生,在过拟合的这个问题上,对应产生了正则化的概念,可以通过适当的忽略一些神经元参数,生成子神经网络,提高模型的泛化性等方法进行优化。
然后是推理能力和可解释性的缺乏,模型基于不同的初始化参数进行训练,对于具体的图像,它是通过数学分析的方法进行概率的计算,并作出推测。这个实验的模型是多层感知机(MLP),主要是基于全连接层。而MLP的神经元网络由于是以全连接层为基础,所以每个全连接层的神经元都和上一个全连接层或者是输入层的所有神经元相连接。这也就意味着MLP主要侧重于对于图像数据的整体特征的一个提取,图像的每个像素点后都有一个神经元对应连接。
而卷积网络模型(CNN)是利用卷积核对于图像数据的特征进行提取,基于卷积核的大小样式的不同,提出的特征也会不同,与MLP不同,CNN更侧重对于局部特征的提取,这些局部特征包括图像边缘细节,这是MLP不擅长的。而在提取到图像不同位置的特征后,CNN再通过全连接层对于各类特征的进行拼图实的操作,最后计算出概率。
再者是鲁棒性欠佳,这个问题主要和正向传播与反向传播过程中的激活函数和损失函数的选择有关。在陈老师的课程中主要提到的是一些激活函数的输出值为非0均值,比如sigmoid函数,这类函数在计算的时候会导致w计算时梯度都是正的,影响神经网络的收敛。而且如果输入的实数过大的时候,sigmoid的输出无限接近于1,梯度下降十分不明显,造成梯度消失的情况的出现。所以为了提高模型的鲁棒性,可以考虑一些带负值输出的函数,比如课程里讲到的tanh函数或者leaky-Relu函数作为激活函数,以此增强代码的健壮性。
五、建议
这个学习阶段是承接了书本上一个学习阶段的一些学习结果进行的。所以其实是在一定基础上对于原来学习的深度学习知识在底层实现上有了更系统化的认知。没有什么过多的学习建议,因为基于底层的一些学习,是基于数学知识的一些推理理解。认真细致地慢慢学完就可以。正如陈云霁老师在课程中讲到的一段话,每有一个数学公式或符号的出现,就意味可能会有一部分人会因为看不懂而退走。好好学完就行,就这样。