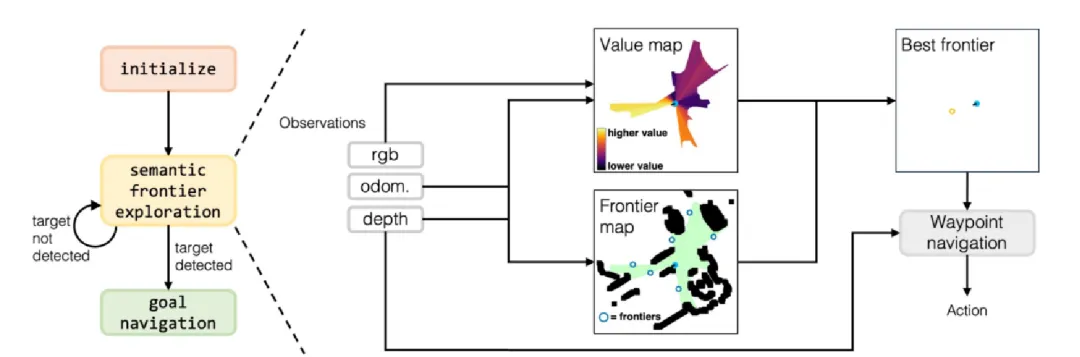
numpy的底层是ndarray,也就是矩阵结构
对于ndarray结构来说,里面所有的元素必须是同一类型的 如果不是的话,会自动的向下进行转换
list = [1,2,3,4,5]
array = np.array(list)
array
输出:array([1, 2, 3, 4, 5])1.1 ndarray基本属性操作
type(array):
获取变量
array的数据类型。在这个例子中,
array是一个 NumPy 数组,所以返回的类型是numpy.ndarray。
array.dtype:
获取数组
array中元素的数据类型。在这个例子中,数组的元素类型是
int32。
array.itemsize:
用于获取数组
array中每个元素的字节大小。在这个例子中,每个元素占用 4 个字节。
array.shape:
用于获取数组
array的形状。在这个例子中,返回
(5,),表示它是一个包含 5 个元素的一维数组。
array.size:
用于获取数组
array中元素的总数。在这个例子中,返回5。
array.ndim:
用于获取数组
array的维度数。在这个例子中,数组是一维的,所以返回 1。
array.fill(0):
用于将数组
array中的所有元素值设置为 0。在这个例子中,执行完这个操作后,数组
array中的所有元素都被填充为 0。
1.2 索引和切片
同Python,索引用逗号(低维到高维),切片用冒号(左到右)
array = np.array([[1,2,3],[4,5,6],[7,8,9]])
array[1,2] --> 6
array[1:2] ---> array([[4, 5, 6]])
array[1,0:2] --> array([4, 5])1.3 array.copy()
实现ndarray的深拷贝
1.4 bool类型索引
基于数组中元素的布尔值(True 或 False)来选择数组的子集
myarray = np.array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
mask = np.array([0,1,0,1,0,2,0,1,3,4],dtype=bool)
myarray[mask] ---> array([10, 30, 50, 70, 80, 90])1.5 np.where()
找出满足特定条件的元素的索引
np.where(myarray > 20) ---> array([3, 4, 5, 6, 7, 8, 9], dtype=int64)1.6 创建元素数据类型
使用dtype
np.array([1,2,3,4,5],dtype=np.float32)
np.array([1,2.2,'ss'],dtype = object)
np.array([0,1,0,1,0,2,0,1,3,4],dtype=bool)1.6.1 数值类型转换
法一:np.asarray()
返回新的ndarray
myarray = np.array([1,2,3,4,5])
myarray2 = np.asarray(myarray,dtype = np.float32)法一:.astype()
在原有ndarray上进行转变
myarray.astype(np.float32)1.7 array数组的数值计算
myarray = np.array([[1,2,3],[4,5,6]])1.7.1 求和
多维数组指定axis
np.sum(myarray,axis=0) ---> array([5, 7, 9])
myarray.sum(axis=0) ---> array([5, 7, 9])
np.sum(myarray,axis=1) ---> array([6, 15])
np.sum(myarray,axis=-1) ---> array([6, 15])
1.7.2 求积
myarray.prod() ---> 720
myarray.prod(axis=0) ---> array([ 4, 10, 18])1.7.3 求最小/最大
myarray.min(axis=1) ---> array([1, 4])
myarray.max(axis=0) ---> array([4, 5, 6])
myarray.argmax(axis=0) ---> array([1, 1, 1], dtype=int64)
1.7.4 求均值,方差,标准差
myarray.mean(axis=0) ---> array([2.5, 3.5, 4.5])
myarray.std(axis=0) #标准差 ---> array([1.5, 1.5, 1.5])
myarray.var() #方差 ---> 2.91666666666666651.7.5 clip()
将数组中的元素限制在指定的最小值和最大值之间。如果数组中的元素超出了这个范围,它们将被设置为最接近的边界值。这个方法不会修改原始数组,而是返回一个新的数组。
myarray.clip(2,4) ---> array([[2, 2, 3],[4, 4, 4]])1.7.6 精度
float_array = np.array([1.4021013 , 1.27661159, 1.58309714, 1.76959385, 1.50449721,
1.24388527, 1.6721506 , 1.04341644, 1.09239404, 1.26755543])1.7.6.1 四舍五入
float_array.round() ---> array([1., 1., 2., 2., 2., 1., 2., 1., 1., 1.])1.7.6.2 精确小数点后几位
np.sort(myarray, axis=0) ---> array([[0.3, 3.5, 1.3],[1.3, 5.2, 2.6]])float_array.round(decimals=1) ---> array([1.4, 1.3, 1.6, 1.8, 1.5, 1.2, 1.7, 1. , 1.1, 1.3])1.8 排序
myarray = np.array([[1.3,3.5,2.6],
[0.3,5.2,1.3]])1.8.1 np.sort()
返回一个新的、元素按升序排列的数组。默认情况下,进行一维排序
np.sort(myarray) ---> array([[1.3, 2.6, 3.5],[0.3, 1.3, 5.2]])指定轴
np.sort(myarray,axis=0) ---> array([[0.3, 3.5, 1.3],[1.3, 5.2, 2.6]])1.8.2 np.argsort()
返回的是原数组元素排序后的对应位置索引
np.argsort(myarray) ---> array([[0, 2, 1],[0, 2, 1]], dtype=int64)1.8.3 np.searchsorted()
返回values数组中能够插入到myarray2中位置索引(myarray2必须是排好序的)
myarray2 = array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444, 5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])
values = np.array([2.4,3.5,8.6])
np.searchsorted(myarray2,values) ---> array([3, 4, 8], dtype=int64)1.8.4 np.lexsort()
使用字典序排序对数组 tang_array 进行多键排序。
首先根据第一个键排序,如果第一个键相同,则根据第二个键排序。
myarray = np.array([[1,0,6],[1,7,0],[2,3,1],[2,4,0]])
index = np.lexsort((-1*myarray[:,0],myarray[:,2])) ---> array([3, 1, 2, 0], dtype=int64)
myarray = myarray[index] ---> array([[2, 4, 0],[1, 7, 0],[2, 3, 1],[1, 0, 6]])1.9 数组形状操作
myarray = array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])1.9.1 改变形状
总体大小不改变
myarray.reshape(1,10) ---> array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])1.9.2 改变维度
1.9.2.1 扩维
使用np.newaxis
myarray = array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) ---> (10,)
myarray2 = myarray[np.newaxis,:] ---> (1,10)
myarray3 = myarray[:,np.newaxis,np.newaxis] ---> (10,1,1)1.9.2.2 降维
.squeeze()
把空维度压缩
myarray4 = myarray3.squeeze() ---> (10,).flatten()
将多维转变成1维,不改变原来数组维度
a --> array([[ 123, 456, 678],
[3214, 456, 134]])
a.flatten() --> array([ 123, 456, 678, 3214, 456, 134]).ravel()
将多维转变成1维,改变原来数组维度
a.ravel() --> array([ 123, 456, 678, 3214, 456, 134])1.9.3 转置
.transpose() 或 .T
myarray = array([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
myarray.transpose() ---> array([[0, 5],[1, 6],[2, 7],[3, 8],[4, 9]])
myarray.T ---> array([[0, 5],[1, 6],[2, 7],[3, 8],[4, 9]])1.10 数组的连接
a = np.array([[123,456,678],[3214,456,134]])
b = np.array([[122,4126,2578],[3114,450,11]])1.10.1 np.concatenate()
np.concatenate((a,b))
输出:array([[ 123, 456, 678],
[3214, 456, 134],
[ 122, 4126, 2578],
[3114, 450, 11]])
np.concatenate((a,b),axis=1)
输出:array([[ 123, 456, 678, 122, 4126, 2578],
[3214, 456, 134, 3114, 450, 11]])1.10.2 np.vstack()
按行堆叠数组
np.vstack((a,b))
输出:array([[ 123, 456, 678],
[3214, 456, 134],
[ 122, 4126, 2578],
[3114, 450, 11]])1.10.3 np.hstack()
按列堆叠数组
np.hstack((a,b))
输出:array([[ 123, 456, 678, 122, 4126, 2578],
[3214, 456, 134, 3114, 450, 11]])1.11 构造数组
1.11.1 np.arange()
三个参数
start:序列的起始值(包含)。默认为 0。
stop:序列的结束值(不包含)。必须指定。
step:序列的步长。默认为 1。
np.arange(10) --> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1,10,2) --> array([1, 3, 5, 7, 9])
np.arange(2,20,2,dtype=np.float32) --> array([ 2., 4., 6., 8., 10., 12., 14., 16., 18.], dtype=float32)1.11.2 np.linspace()
生成等间隔数字
np.linspace(0,10,5) --> array([ 0. , 2.5, 5. , 7.5, 10. ])1.11.3 np.logspace()
生成对数尺度上等间隔数字,默认以10为底
np.logspace(0,10,5) --> array([ 1. , 1.77827941, 3.16227766, 5.62341325, 10. ])1.11.4 np.meshgrid()
生成坐标矩阵。
接受多个一维数组作为输入,并返回相同数量的二维数组。
生成两个二维数组 X 和 Y,其中 X 的每一行都是 x,而 Y 的每一列都是 y
x = np.linspace(-10,10,5) --> array([-10., -5., 0., 5., 10.])
y= np.linspace(-10,10,5) --> array([-10., -5., 0., 5., 10.])
x,y = np.meshgrid(x,y)
x:array([[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.],
[-10., -5., 0., 5., 10.]])
y:array([[-10., -10., -10., -10., -10.],
[ -5., -5., -5., -5., -5.],
[ 0., 0., 0., 0., 0.],
[ 5., 5., 5., 5., 5.],
[ 10., 10., 10., 10., 10.]])1.11.5 np.r_[]
允许使用类似于 Python 切片的语法来创建行向量
np.r_[0:10:4] <==> np.arange(0, 10, 4) --> array([0, 4, 8])1.11.6 np.c_[]
允许使用类似于 Python 切片的语法来创建列向量
np.c_[0:10:1]
输出:array([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]])1.11.7 zeros ()
np.zeros(3)
np.zeros((3,3)) #往里传元组1.11.8 ones()
np.ones((2,4,5)) * 5
输出:array([[[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.]],
[[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.],
[5., 5., 5., 5., 5.]]])1.11.9 empty()
创建一个指定形状和数据类型的未初始化数组。这意味着数组中的元素是随机的。
np.empty(5)
输出:array([7.74860419e-304, 7.74860419e-304, 7.74860419e-304, 7.74860419e-304,
7.74860419e-304])
1.11.10 fill()
原地操作,直接将数组 a 中的所有元素值设置为 1
a.fill(1)1.11.11 zeros_like() / ones_like()
zeros_like():创建一个与 tarray 形状和数据类型相同,但所有元素都是 0 的数组。
ones_like():创建一个与 tarray 形状和数据类型相同,但所有元素都是 1 的数组。
np.ones_like(tarray)1.11.12 identity()
创建一个的n x n的单位矩阵
np.identity(5)
输出:array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])1.12 运算
x = np.array([5,5])
y = np.array([2,2])1.12.1 multiply()
矩阵各元素相乘
np.multiply(x,y) --> array([10, 10])1.12.2 dot()
矩阵内积
np.dot(x,y) --> 201.12.3 x*y
x是一维,y不限
y是一维,x不限
x= np.array([1,2,3])
y = np.array([[1,2,3],[4, 5,6]])
print(y*x)
输出:[[ 1 4 9][ 4 10 18]]1.12.4 logical_and / logical_or / logical_not
np.logical_and(x, y):
计算两个数组
x和y的逐元素逻辑与(AND)操作。结果数组中,只有当
x和y对应位置的元素都为True时,结果才为True。
np.logical_or(x, y):
计算两个数组
x和y的逐元素逻辑或(OR)操作。结果数组中,只要
x或y对应位置的元素有一个为True,结果就为True。
np.logical_not(y):
计算数组
y的逐元素逻辑非(NOT)操作。结果数组中,
y中为True的元素变为False,为False的元素变为True。
1.13 随机模块
1.13.1 np.random.rand()
生成一个在区间 [0, 1) 内均匀分布的样本数组。
np.random.rand(3, 4) #生成一个 3x4 的数组。1.13.2 np.random.randint()
生成一个给定范围内的随机整数数组。
这个函数接受至少两个参数:low 和 high,表示生成随机整数的范围(包括 low,不包括 high)。
np.random.randint(10,size=(5,4))
输出:array([[1, 9, 1, 3],
[1, 3, 2, 6],
[3, 1, 2, 1],
[1, 4, 6, 4],
[7, 6, 9, 0]])1.13.3 np.random.random_sample()
这个函数是 np.random.rand() 的别名,两者功能完全相同。
1.13.4 np.random.normal()
生成一个给定均值和标准差的正态分布样本数组。
mu, sigma = 0,0.1
#生成一个包含 10 个服从均值为 0、标准差为 0.1 的正态分布的随机数的数组
np.random.normal(mu,sigma,10) 1.13.5 np.random.randn()
生成一个或多个服从标准正态分布(均值为 0,标准差为 1)的随机样本值
np.random.randn(3, 4)1.13.6 np.set_printoptions()
允许自定义数组打印时的格式,例如,你可以设置打印时显示的最大行数、最大列数、浮点数的精度等。
np.set_printoptions(precision=2)
mu, sigma = 0,0.1
np.random.normal(mu,sigma,10)
输出:array([-0.09, 0.2 , 0.04, 0.04, -0.16, 0.1 , 0.09, 0.06, -0.07, -0.28])1.13.7 np.random.shuffle()
打乱数组中元素顺序
myarray = np.arange(10) --> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.random.shuffle(myarray) --> array([9, 7, 2, 4, 0, 5, 6, 1, 3, 8])1.13.8 随机种子
通过指定一个种子值,你可以确保每次运行代码时生成的随机数序列是相同的。
#在使用random前加上
np.random.seed(1)1.14 读写数据
1.14.1 读txt文件数据
%%writefile practice.txt
1 2 3 4 5 6
7 8 9 10 11 12with open('tang.txt') as f:
for line in f:
files = line.split()
cur_data = [float(x) for x in files]
data.append(cur_data)
data = np.array(data)等价于
data = np.loadtxt('practice.txt')--------------------------------------------------------------------------------------------------------------------------------
%%writefile practice2.txt
a,b,c,d,e,f
1, 2, 3, 4, 5, 6
7, 8, 9, 10, 11, 12
- skiprows:去掉几行
- delimiter=',':分隔符
- usecols = (0,1,4):指定使用哪几列
data = np.loadtxt('practice2.txt',delimiter=',',skiprows=1,usecols=(1))
输出:array([2., 8.])保存数据到文件
np.savetxt('practice3.txt',data,fmt='%.2f',delimiter=',')1.14.2 读npy文件数据
写入文件
array1 = np.array([[1,2,3],[4,5,6]])
np.save('array1.npy',array1)读取文件
array = np.load('array1.npy')
输出:array([[1, 2, 3],
[4, 5, 6]])压缩文件
array2 = np.arange(10)np.savez('arrayz.npz',a=array1,b=array2)读取压缩文件
data = np.load('tang.npz')
data['a'] --> array([[1, 2, 3],[4, 5, 6]])
data['b'] --> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
![[MySQL] 事务管理(二) 事务的隔离性底层](https://i-blog.csdnimg.cn/direct/9a78a348f89d49c0b289a2caa2e10146.png)