二分查找:排序数据的高效检索
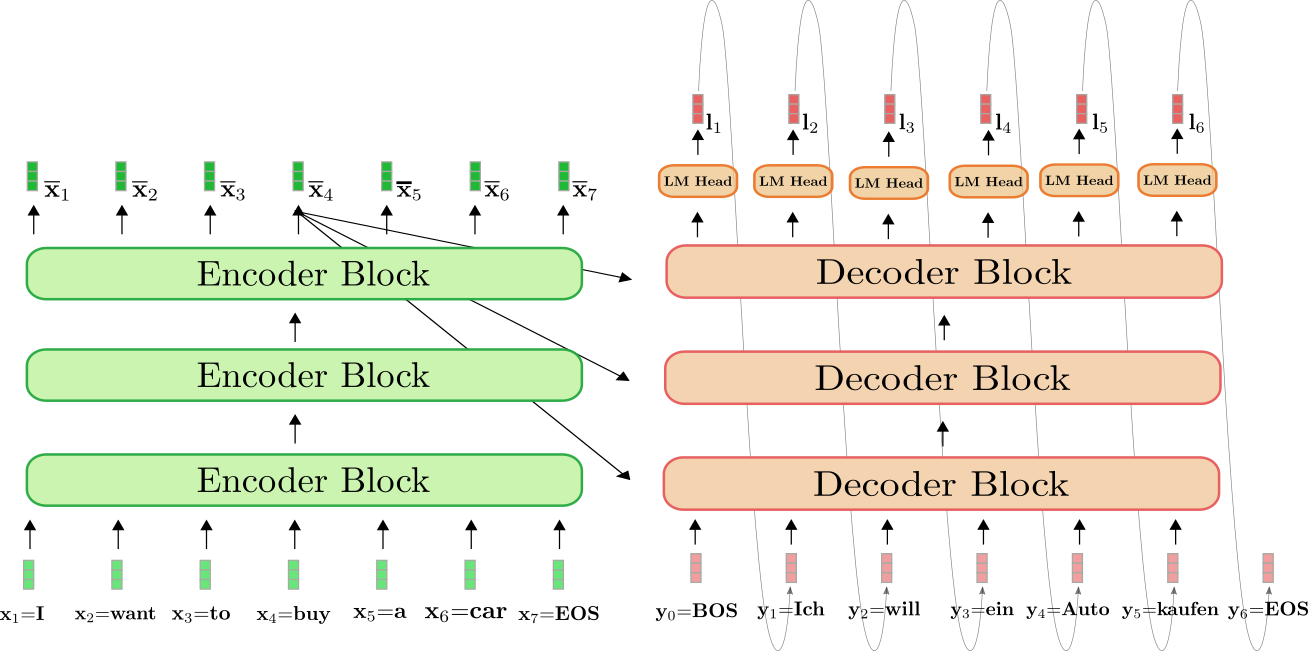
第二天清晨,李明早早来到了图书馆。今天他的研究目标是bisect模块,特别是其中的bisect_left和bisect_right函数。这些函数实现了二分查找算法,用于在已排序的序列中高效地查找元素或确定插入位置。
二分查找的核心思想是每次将搜索区间缩小一半,这使得算法的时间复杂度为O(log n),相比于线性搜索的O(n),在大规模数据集上表现出显著的性能优势。
李明首先记录了这两个函数的基本用途:
bisect_left(a, x):在已排序的序列a中查找元素x应该插入的位置,若x已存在,则返回最左侧的插入点bisect_right(a, x)或bisect(a, x):在已排序的序列a中查找元素x应该插入的位置,若x已存在,则返回最右侧的插入点
应用示例:数据分析中的区间分组
李明正在处理一个城市温度监测项目,需要将全年温度数据按照不同的温度区间进行分类统计。他发现bisect模块非常适合这种场景:
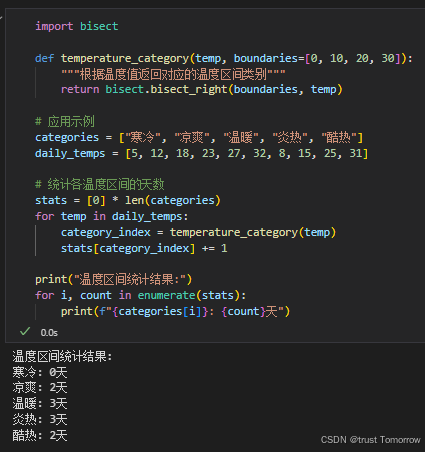
import bisect
def temperature_category(temp, boundaries=[0, 10, 20, 30]):
"""根据温度值返回对应的温度区间类别"""
return bisect.bisect_right(boundaries, temp)
# 应用示例
categories = ["寒冷", "凉爽", "温暖", "炎热", "酷热"]
daily_temps = [5, 12, 18, 23, 27, 32, 8, 15, 25, 31]
# 统计各温度区间的天数
stats = [0] * len(categories)
for temp in daily_temps:
category_index = temperature_category(temp)
stats[category_index] += 1
print("温度区间统计结果:")
for i, count in enumerate(stats):
print(f"{categories[i]}: {count}天")
应用示例:时间序列数据查询
午后,李明转向了另一个项目——金融数据分析系统,需要在时间戳排序的大型数据集中快速查找特定时间点的数据或最接近的记录。
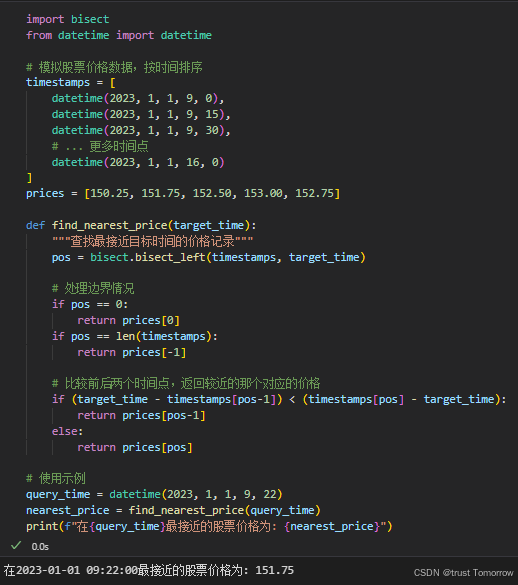
import bisect
from datetime import datetime
# 模拟股票价格数据,按时间排序
timestamps = [
datetime(2023, 1, 1, 9, 0),
datetime(2023, 1, 1, 9, 15),
datetime(2023, 1, 1, 9, 30),
# ... 更多时间点
datetime(2023, 1, 1, 16, 0)
]
prices = [150.25, 151.75, 152.50, 153.00, 152.75]
def find_nearest_price(target_time):
"""查找最接近目标时间的价格记录"""
pos = bisect.bisect_left(timestamps, target_time)
# 处理边界情况
if pos == 0:
return prices[0]
if pos == len(timestamps):
return prices[-1]
# 比较前后两个时间点,返回较近的那个对应的价格
if (target_time - timestamps[pos-1]) < (timestamps[pos] - target_time):
return prices[pos-1]
else:
return prices[pos]
# 使用示例
query_time = datetime(2023, 1, 1, 9, 22)
nearest_price = find_nearest_price(query_time)
print(f"在{query_time}最接近的股票价格为: {nearest_price}")
应用示例:数值区间的高效映射
晚上,李明思考了bisect在机器学习特征工程中的应用。他正在开发一个信用评分模型,需要将连续的数值特征(如年龄、收入、账户余额等)映射到离散的评分区间。
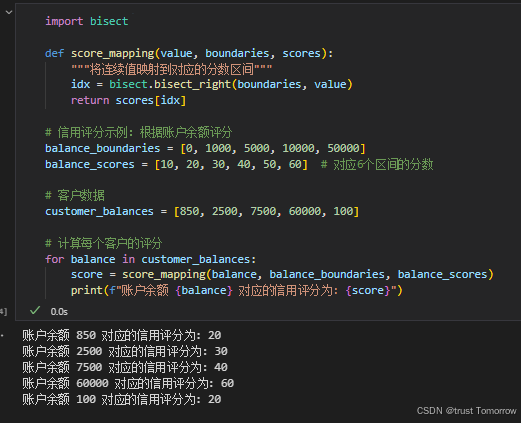
import bisect
def score_mapping(value, boundaries, scores):
"""将连续值映射到对应的分数区间"""
idx = bisect.bisect_right(boundaries, value)
return scores[idx]
# 信用评分示例:根据账户余额评分
balance_boundaries = [0, 1000, 5000, 10000, 50000]
balance_scores = [10, 20, 30, 40, 50, 60] # 对应6个区间的分数
# 客户数据
customer_balances = [850, 2500, 7500, 60000, 100]
# 计算每个客户的评分
for balance in customer_balances:
score = score_mapping(balance, balance_boundaries, balance_scores)
print(f"账户余额 {balance} 对应的信用评分为: {score}")
思考与总结
深夜,李明合上笔记本,对这两天的学习成果感到满足。这些看似基础的数学函数构成了复杂算法和应用程序的基石。通过深入理解它们的原理和应用场景,他不仅丰富了自己的知识库,也为未来的项目开发奠定了坚实的基础。
二分查找算法的优雅与高效给李明留下了深刻印象。在有序数据集上,它能将搜索时间从线性降至对数级别,这在处理大规模数据时意味着巨大的性能提升。同时,bisect_left和bisect_right的细微差别也提醒他在实际应用中要注意边界条件的处理,这往往是编程中最容易被忽视却最关键的部分。
明天,他计划探索更多高级的数学函数,如线性代数运算和微积分函数,以进一步拓展他的数学工具箱。在计算机科学与数学交叉的广阔天地中,每一个函数都是通向新发现的钥匙。
正如李明在笔记末尾写道的:“数学不仅是科学的语言,更是解决实际问题的强大工具。理解其本质,方能驾驭其力量。算法的美妙之处在于,它将抽象的数学原理转化为解决现实问题的具体方法,而高效的实现则让这种美妙得以在有限的计算资源下展现。”