RDP 论文
- 通过 AR 提供实时触觉/力反馈;
- 慢速扩散策略,用于预测低频潜在空间中的高层动作分块;快速非对称分词器实现闭环反馈控制。
ACT、 π 0 \pi_0 π0 采取了动作分块,在动作分块执行期间处于开环状态,无法及时响应环境变化,缺乏触觉输入,无法适应高精度(力控制)任务和及时响应。现有的触觉输入是侧重于观察方面,利用触觉输入提供视觉遮挡或接触状态判断等信息。在数据上,MTDP(Mixed-Teleoperation Demonstration Policy)通过增强现实(AR)技术实现了两大突破性改进:1)异构机器人兼容性 - 克服了传统ALOHA双边控制系统必须使用同构机器人的限制;2)成本优化 - 相比基于专业力/扭矩传感器的触觉反馈方案,显著降低了硬件成本。并且现有的触觉输入的方案均排除了视觉输入。
- 力/扭矩传感器——直接测量末端或关节的力/扭矩数值,高速运动时噪声明显且成本高。
- 触觉传感器
- 电学式触觉传感器——通过电容、电阻等原理感知,空间分辨率较低,且少数型号能直接输出法向力与切向力,且需依赖力/扭矩传感器标定;
- 光学式触觉传感器——通过相机捕捉凝胶变形的高分率图像,追踪凝胶表面的法向/剪切变形场,力/扭矩信息需通过剪切长间接表征。
MTDP 采取 GelSight Mini 和 MCTrac 两种光学式触觉传感器和机器臂关节扭矩传感器。将法向力、剪切力、视觉 RGB 输入输入为统一的visual-tactile policy。
数据集为利用 GelSIght Mini 收集的 30min 的随机交互视频和使用 MCTrac 为剥皮任务收集的 60 次演示,为擦拭任务收集的 80 次演示,为双手抬举任务收集的 50 次演示。
TactAR

25 Hz 是因为限制于 GelSight 帧速率限制。
从二维光流推算力数据依赖传感器的标定,采用可视化三维变形场:
- 标记点提取:通过 OpenCV 从触觉图像 I t I_t It 中提取归一化标记点位置 D t D_t Dt;
- 光流计算:基于得分追踪算法(Gelsight SDK)计算初始帧 D 0 D_0 D0 与当前帧 D t D_t Dt 的二维光流 F t = [ d x , d y ] = F l o w ( D 0 , D t ) F_t=[d_x,d_y]=Flow(D_0,D_t) Ft=[dx,dy]=Flow(D0,Dt);
- 三维变形场:将光流扩展为含 z 轴偏移
o
z
o_z
oz 的三维变形场
V
t
=
[
f
x
,
f
y
,
f
z
]
V_t=[f_x,f_y,f_z]
Vt=[fx,fy,fz];
通过 OpenCV 和轻量级追踪算法,规避传统光学传感器的依赖,直接力矢量渲染。
构建流程:使用 Meta Quest3 的 color passthrough 在 Unity 中创建 AR 场景 -> SLAM 实时跟踪头显和控制器位姿 -> 力矢量渲染 -> 根据机器人末端执行器(TCP)实时位姿,通过 ROS2 同步触觉数据、机器人状态和相机流
跟踪算法延迟 10ms,Quest3 渲染延迟 10ms,网络延迟 1-6ms,光学触觉传感器 10-60ms,力传感器延迟 1ms
RDP

VISK 通过聚合同一时间步的多次迭代的预测结果实现实时反馈,但削弱了策略对多模态分布和非马儿可夫动作的建模能力,且对平滑系数相当敏感。
AT 由一个 1D-CNN(建模时序性) 和 GRU decoder 组成。通过触觉序列
F
r
e
d
u
c
e
d
F^{reduced}
Freduced (经过 PCA 降维后——光学触觉传感器的变形场可以被分解为几个高度可解释的独立成分)重建动作
A
^
=
D
(
c
o
n
c
a
t
(
[
Z
,
F
r
e
d
u
c
e
d
]
)
)
\hat{A}=\mathcal{D}\left(concat([\boldsymbol{Z},\boldsymbol{F}^{reduced}])\right)
A^=D(concat([Z,Freduced])) ,采用 L1 重建损失和 Kullback-Leibler(KL)惩罚损失:(1ms)(通过插值的方式调整)
L
A
T
=
E
A
,
F
r
e
d
u
c
e
d
∈
D
p
o
l
i
c
y
[
∣
∣
A
−
A
^
∣
∣
1
+
λ
K
L
L
K
L
]
L_{AT}=\mathbb{E}_{\boldsymbol{A},\boldsymbol{F}^{reduced}\in\mathcal{D}_{policy}}\left[||A-\hat{A}||_1+\lambda_{KL}L_{KL}\right]
LAT=EA,Freduced∈Dpolicy[∣∣A−A^∣∣1+λKLLKL]
LDP 利用学习到的梯度场
∇
E
(
A
)
\nabla E(A)
∇E(A),通过随机 Langevin 动力学,以较低的频率预测动作。 (100ms)(DP 120ms)
L
L
D
P
=
E
(
O
,
A
0
)
∈
D
p
o
l
i
c
y
,
k
,
ϵ
k
∥
ϵ
k
−
ϵ
θ
(
O
,
Z
0
+
ϵ
k
,
k
)
∥
2
L_{LDP}=\mathbb{E}_{(\mathbf{O},\mathbf{A}^0)\in\mathcal{D}_{policy},k,\epsilon^k}\|\epsilon^k-\epsilon_\theta(\mathbf{O},\mathbf{Z}^0+\epsilon^k,k)\|_2
LLDP=E(O,A0)∈Dpolicy,k,ϵk∥ϵk−ϵθ(O,Z0+ϵk,k)∥2

使用相对末端执行器轨迹进行动作表示,基准帧是动作块的最后一个观察帧,计算相对于基准帧的相对变换,将绝对轨迹转化为相对轨迹。
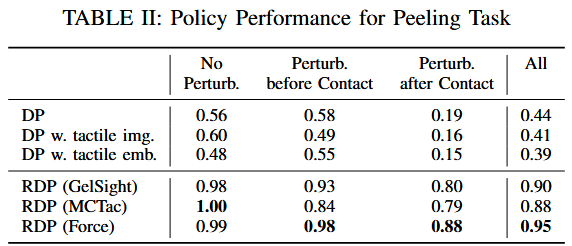
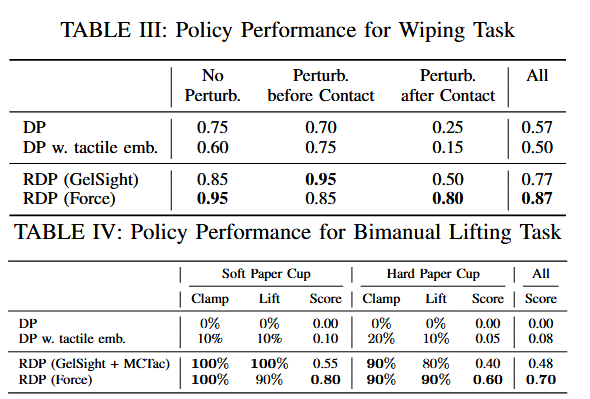
实验结果