✍ 个人博客:https://blog.csdn.net/Newin2020?type=blog
📝 专栏地址:https://blog.csdn.net/newin2020/category_12898955.html
📣 专栏定位:为 0 基础刚入门 Golang 的小伙伴提供详细的讲解,也欢迎大佬们一起交流~
📚 专栏简介:在这个专栏,我将带着大家从 0 开始入门 Golang 的学习。在这个 Golang 的新人系列专栏下,将会总结 Golang 入门基础的一些知识点,并由浅入深的学习这些知识点,方便大家快速入门学习~
❤️ 如果有收获的话,欢迎点赞 👍 收藏 📁 关注,您的支持就是我创作的最大动力 💪
1. 方法详解
1.1 快速了解
先来跟随一个案例,快速的先了解一下方法的使用,下面我们分别使用了值传递和引用传递的方法修改结构体变量中的值,可以发现两者修改后打印的结果并不相同。
值传递
package main
import (
"fmt"
)
type Person struct {
name string
age int
}
func (p Person) change() {
p.age = 19
}
func main(){
//调用方式
p := Person{
"bobby", 18,
}
p.change()
fmt.Printf("name:%s, age:%d\n", p.name, p.age) //name:bobby, age:18
}
引用传递
package main
import (
"fmt"
)
type Person struct {
name string
age int
}
func (p *Person) change() {
p.age = 19
}
func main(){
//调用方式
p := Person{
"bobby", 18,
}
p.change()
fmt.Printf("name:%s, age:%d\n", p.name, p.age) //name:bobby, age:19
}
注意:
原始定义的方法是值传递,通过方法无法改变结构体本身的值,如需改变,则要用指针进行传递。
1.2 值传递与引用传递
为了能够理解上面案例中为何改成指针类型后就能成功修改结构体的值,我们这里再详细的举一个例子看看,并观察一下其底层的函数栈帧是如何分布的。
值传递
现在定义了一个类型 A,并给他关联了一个方法 Name,这样我们就可以通过这个类型 A 的变量来调用这个方法即 a.Name(),这种调用方式其实是 “语法糖”。
package main
import (
"fmt"
)
type A struct {
name string
}
func (a A) Name() {
a.name = "Hi! " + a.name
}
func main(){
a := A{name: "john"}
a.Name()
A.Name(a)
fmt.Println(a) // john
}
这种方式和 A.Name(a)) 的调用方式其实是一样的,这里的变量 a 就是所谓的方法接受者,它会作为方法 Name 的第一个参数传入,这一点可以通过代码来验证一下。
因为 go 语言中函数类型只和参数与返回值相关,所以下面这两个类型值 t1 和 t2 相等就能够证明方法本质上就是普通的函数,而方法接受者就是隐含的第一个参数。
func NameOfA(a A) {
a.name = "Hi! " + a.name
}
func main(){
t1 := reflect.TypeOf(A.Name)
t2 := reflect.TypeOf(NameOfA)
fmt.Println(t1 == t2) // true
}
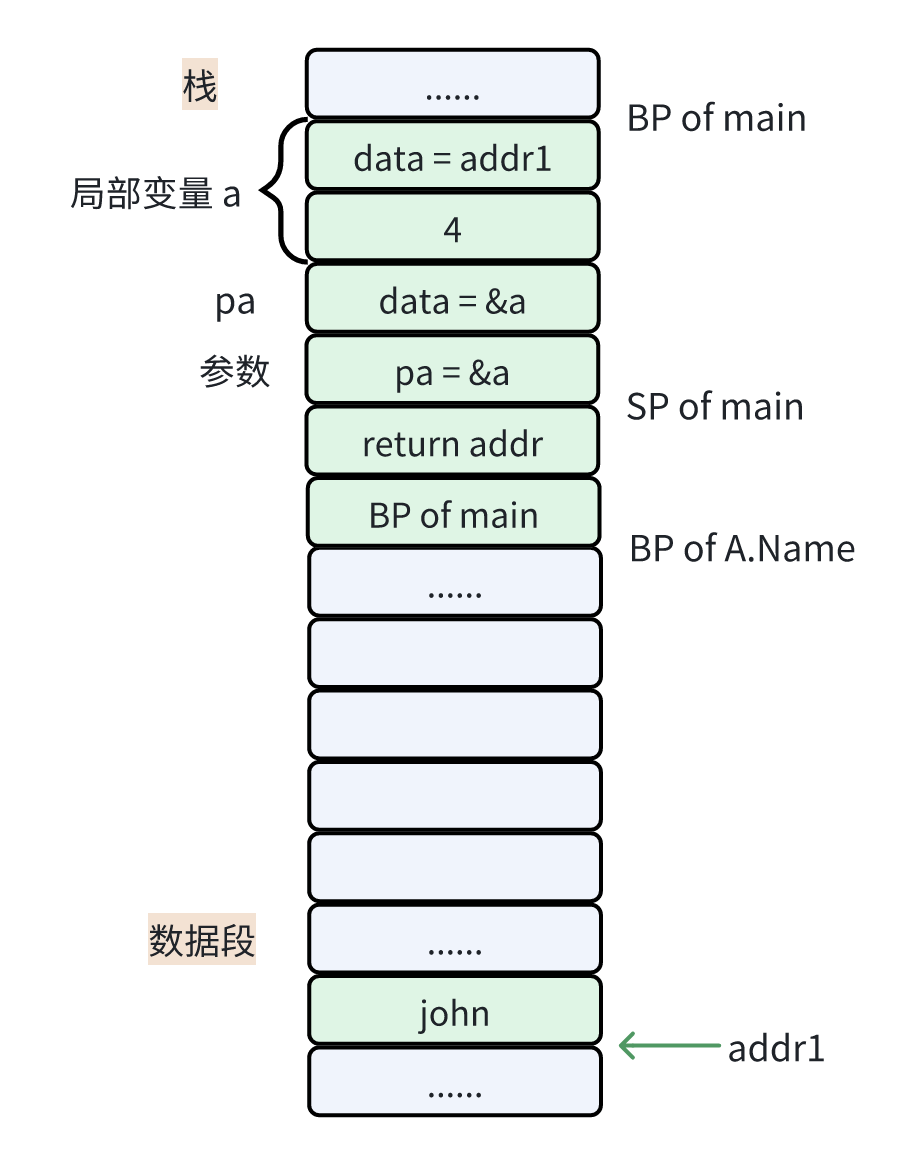
接下来我们来看看方法调用的情况,main 函数栈帧中,局部变量 a 只包含一个 string 类型的成员,字符串的内容在数据段,地址为 addr1 且字节数目为 4(这块不清楚的朋友可以去看我前面关于数据类型讲解中的字符串部分)。
由于调用的函数没有返回值,所以局部变量后面紧跟着的是参数空间,并且为 string 类型。而 go 语言中传参是值拷贝,所以局部变量 a 就会被拷贝到参数空间当中。
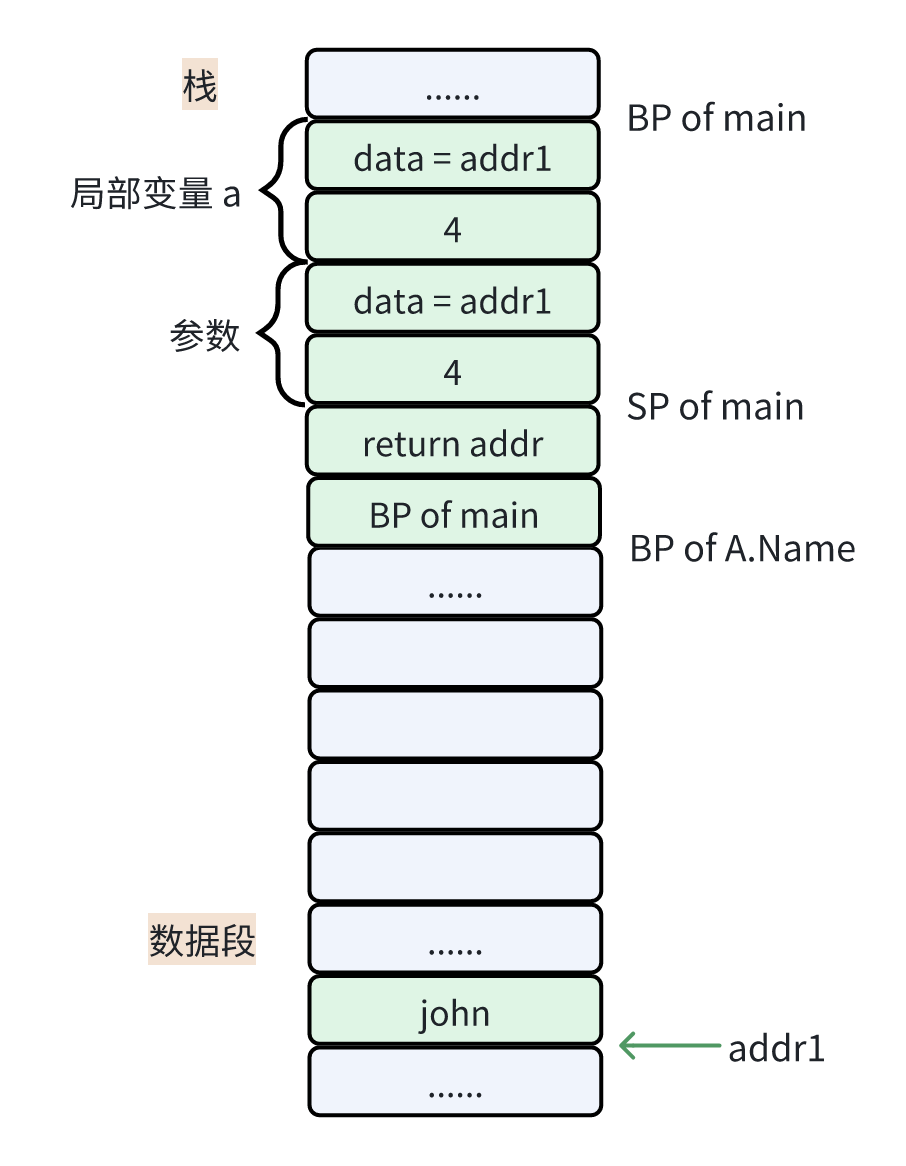
当函数执行到 Name 中的 a.name = "Hi! " + a.name 这行代码时,修改的是参数空间的值,它指向了新的字符串内容,而字节数也要修改为 8。
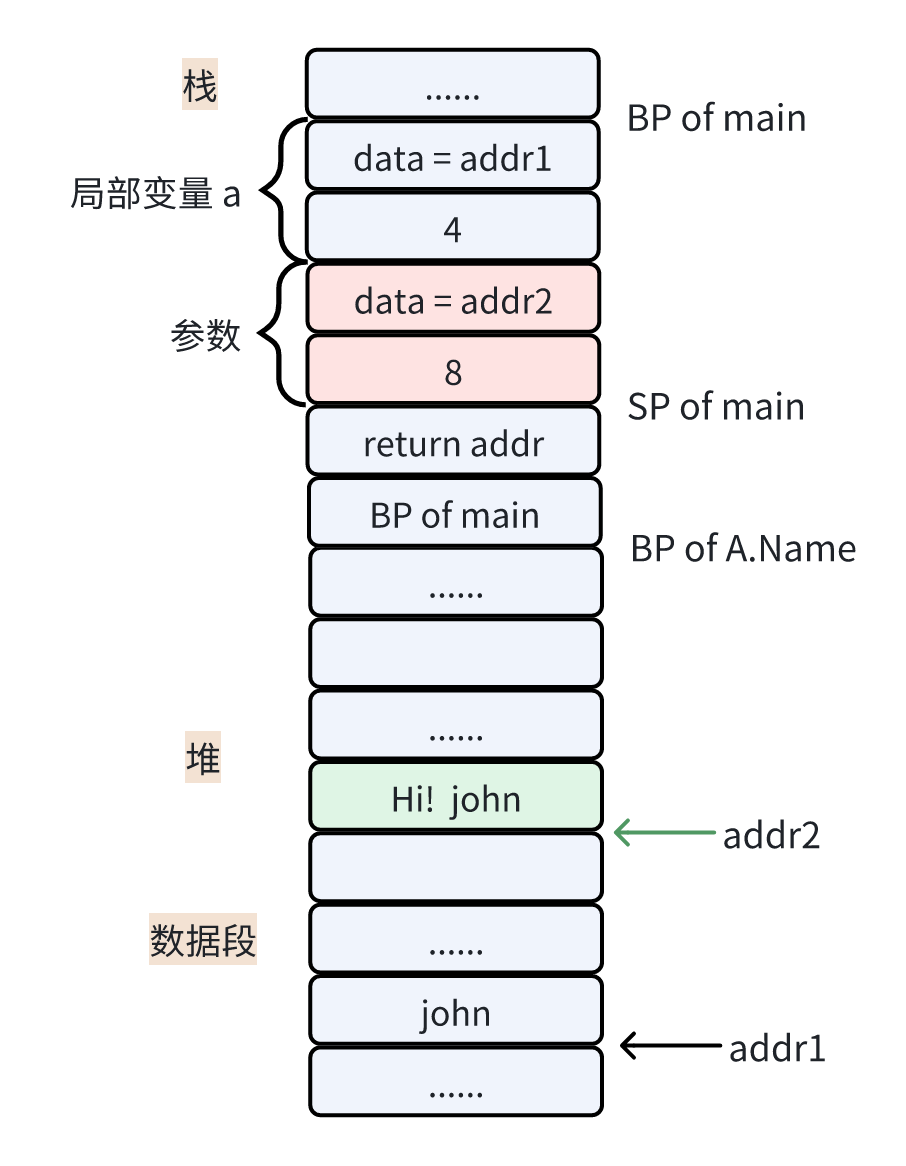
由于这里的局部变量 a 是值接收者,因此通过它调用方法时,修改的是拷贝过去的参数,而不是 main 函数中的局部变量 a。
引用传递
要想修改到局部变量 a,我们还是得使用指针接收者,我们这里将上面的方法 Name 的接收者修改成指针类型,然后用变量 pa 来调用方法 Name 再来看看函数的调用栈有何不同。
package main
import (
"fmt"
)
type A struct {
name string
}
func (pa *A) Name() {
pa.name = "Hi! " + pa.name
}
func main(){
a := A{name: "john"}
pa := &a
pa.Name()
fmt.Println(a) // Hi! john
}
这次 main 函数栈帧除了局部变量 a 外,还新增了一个 a 的指针 pa,pa.Name() 会被转换成 (*A).Name(pa)
这样的函数调用。
而下面参数变成了 A 的指针,并且因为传参值拷贝,所以这里拷贝的是局部变量 a 的地址。
当函数执行到 Name 函数中 pa.name = "Hi! " + pa.name 这行代码时,就需要修改 &a 这个地址处的变量即局部变量 a,它被修改为指向新的字符串内容且字节数目修改为 8。
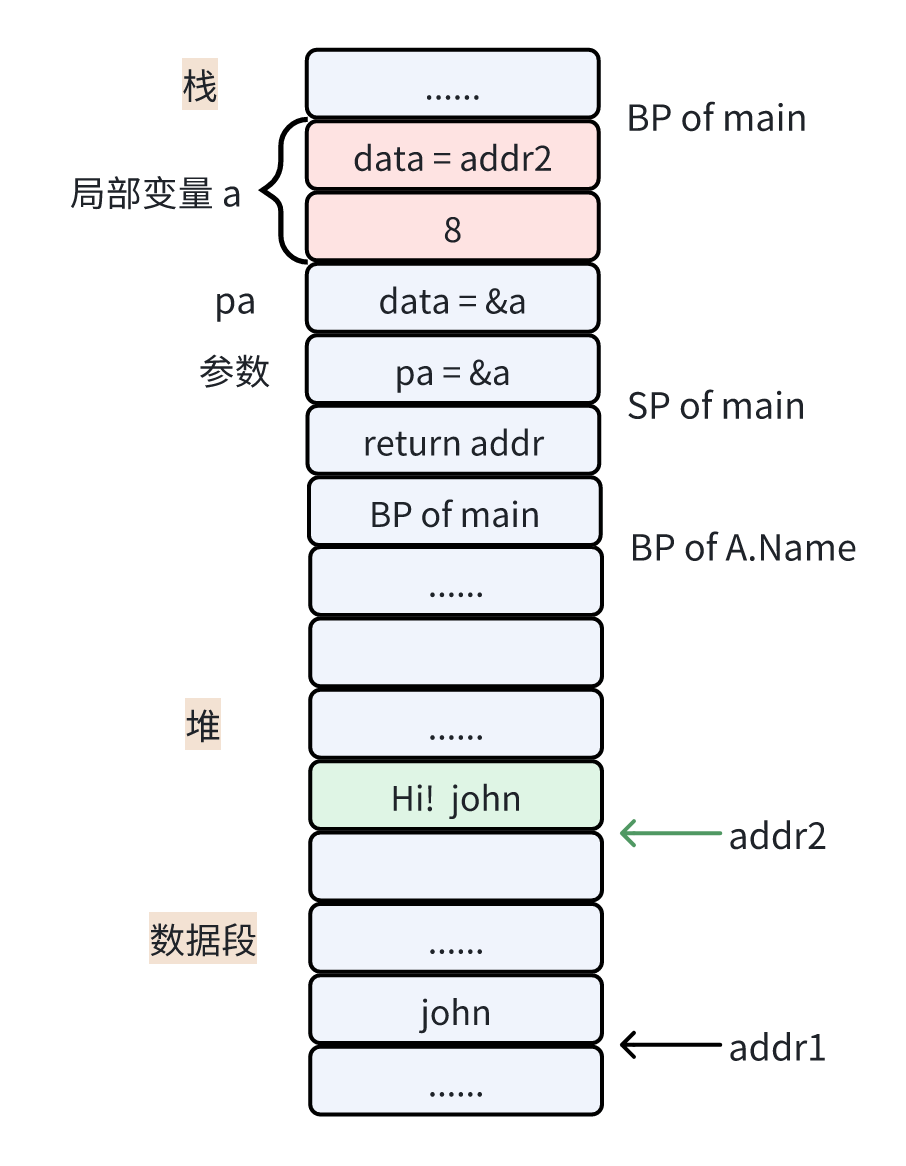
至此我们可以发现,此时打印时就会显示出我们预期的结果,因为指针帮我们成功修改到了局部变量 a 的值。
这就是指针接收者调用方法的过程,同样要把接收者作为第一个参数传入,同样是参数值拷贝,但是指针接收者拷贝的地址,因此实现了堆局部变量 a 的修改。
引用与值传递
接下来我们再看个例子,现在我将值接受者的方法和指针接收者的方法放在一起,但是这里我们通过值来调用指针接收者的方法,且用指针来调用值接受者的方法,却不会报错。
package main
import (
"fmt"
)
type A struct {
name string
}
func (a A) GetName() string {
return a.name
}
func (pa *A) SetName() {
pa.name = "Hi! " + pa.name
}
func main(){
a := A{name: "john"}
pa := &a
fmt.Println(pa.GetName())
a.SetName()
fmt.Println(a) // Hi! john
}
其实若没有涉及到接口的话,这些也是语法糖。在编译阶段:
- pa.GetName() 会转换成 (*pa).GetName() 这种形式
- a.SetName() 会转换成 (&a).SetName() 这种形式
不过这种语法糖既然是在编译期间发挥作用的,因此像 A{name: “john”}.SetName() 这种编译期间不能拿到地址的字面量是无法通过语法糖来转换的,所以不能通过编译。
1.3 方法赋值给变量
最后,我们再来看这个例子中,可以发现 f1 和 f2 变量都接收了方法,这其实是和变量接收函数是一个道理。
package main
import (
"fmt"
)
type A struct {
name string
}
func (a A) GetName() string {
return a.name
}
func main(){
a := A{name: "john"}
f1 := A.GetName
f1(a)
f2 := a.GetName
f2()
}
从前面的函数章节内容可以知道,go 语言中函数作为变量、参数和返回值时都是以 function value 的形式存在的,并且也知道了闭包只是有捕获列表的 function value 而已。
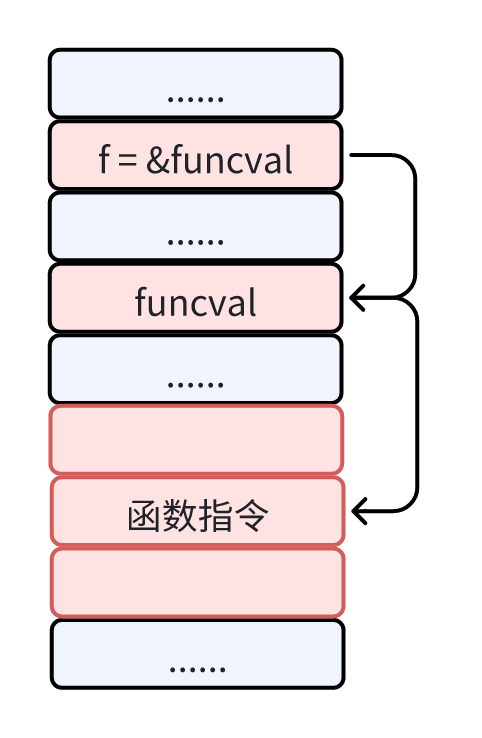
如果像上面这样把一个类型的方法赋值给变量 f1,那么 f1 就是一个方法表达式。可能这样看还是不太明显,我们转换一下代码,而下面这段代码其实等价于上面 f1 那段表达式的代码。
func GetName(a A) string {
return a.name
}
func main() {
a := A{name: "john"}
f1 := GetName
f1(a)
}
因此可以发现,f1 本质上也是一个 funcation value,也就是一个 funcval 结构体的指针,而结构体中的 fn 指向 A.GetName 的函数指令入口。
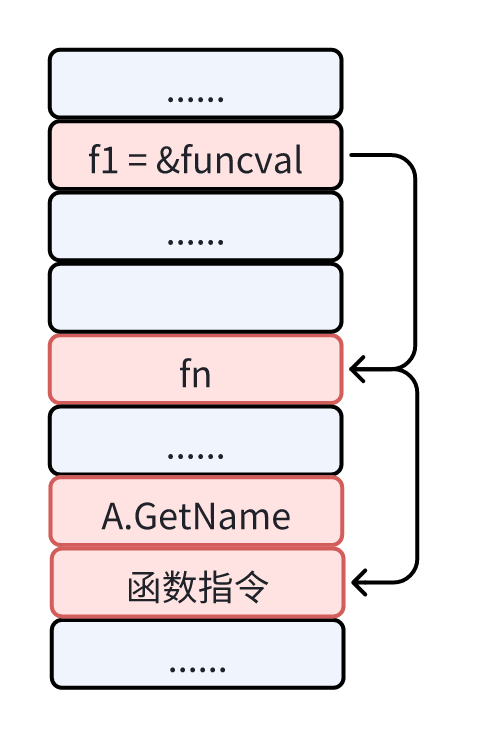
所以我们在调用 f1 的时候,需要传入 A 类型的变量 a 作为第一个参数。
而 f2 赋值方式又有不同,它这样的赋值被称为方法变量。理论上讲方法变量也是一个 function value,并且它会捕获方法接收者形成闭包。
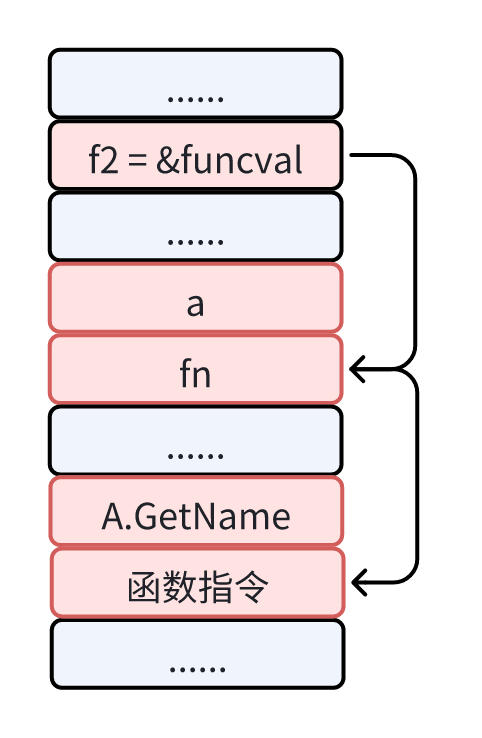
但是这里的 f2 仅作为局部变量,它与 a 的生命周期是一致的,所以编译器会做出优化,把它转换为类型 A 的方法调用并传入 a 作为参数即 A.GetName(a)。
我们可以再看一个方法变量作为返回值的例子对比一下,这里的 f2 与上一个例子相同,同样会被编译器优化成 A.GetName(a) 这样的函数调用,所以会输出 main 函数的局部变量 a。
package main
import (
"fmt"
)
type A struct {
name string
}
func (a A) GetName() string {
return a.name
}
func GetFunc() func() string {
a := A{name: "GetFunc"}
return a.GetName
}
func main(){
a := A{name: "main"}
f2 := a.GetName
fmt.Println(f2()) // main
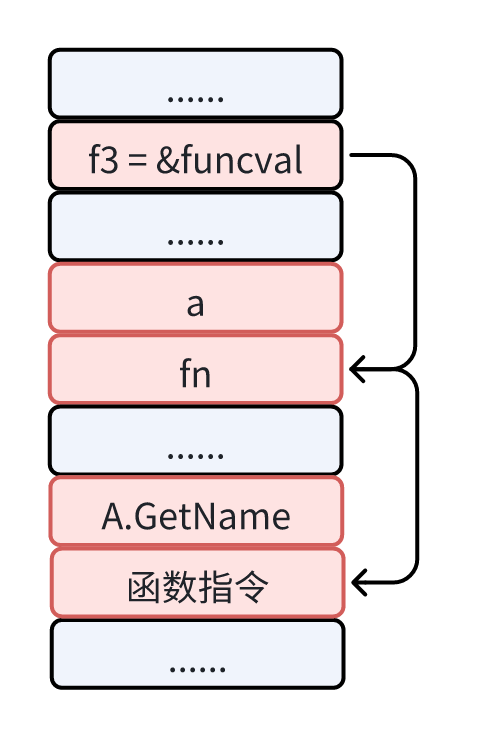
f3 := GetFunc()
fmt.Println(f3()) // GetFunc
}
而这里的 f3 被赋值为 GetFunc 函数的返回值,返回的是一个方法变量,这等价于下面这段代码。
func GetFunc() func() string {
a := A{name: "GetFunc"}
return func() string {
return A.GetName(a)
}
}
通过上面这段代码,我们可以清晰地看到闭包是如何形成的。所以 f3 就是一个闭包对象,捕获了 GetFunc 的局部变量 a。因此在 f3 执行后返回并打印的时候,会输出 GetFunc。
因此,从本质上来讲,方法表达式和方法变量都是 function value。
2. 类型系统
2.1 类型系统构成
- 基本类型:包括整数类型(如 int、int8、int16 等)、浮点数类型(如 float32、float64)、布尔类型(bool)、字符串类型(string)等。
- 复合类型:
- 数组:具有固定长度的相同类型元素的序列。
- 切片:可以动态增长或收缩的元素序列。
- 结构体:将不同类型的数据组合在一起形成一个新的类型。
- 指针:用于指向其他变量的地址。
- 映射(字典):存储键值对的数据结构。
- 接口类型:定义了一组方法签名,具体的类型可以实现这些接口。
- 类型别名:可以为已有的类型定义一个新的名称。
Go 语言的类型系统简洁而高效,在保证强类型安全的同时,也提供了足够的灵活性来构建各种复杂的程序结构。
2.2 自定义类型
如果我们自定义一个类型 T,并且给它关联一个方法 F1。这里的方法调用再前面的函数篇也介绍过,方法本质上就是函数,只不过在调用时接收者会作为第一个参数传入。
type T struct {
name string
}
func (t T) F1() {
fmt.Println(t.name)
}
func main() {
t := T{name: "eggo")
t.F1() // T.F1(t)
}
这在编译阶段自然行得通,但到了执行阶段,反射、接口动态派发、类型断言等语言特性或机制又该如何动态的获取数据类型信息呢?
接下来我们就来弄清楚这些问题,首先要理清楚在 Go 语言中,下面这些都属于内置类型。
int8 int16 int32 int64 int
byte string slice func map
......
而从前面 type 关键字那小节可知,下面这些都属于自定义的类型。
// 定义了一个新的类型T,其底层类型是int
type T int
// 定义了一个名为T的结构体类型
type T struct {
name string
}
// 定义了一个名为I的接口类型,要求实现该接口的类型必须具有Name() string这个方法
type I interface {
Name() string
}
这里需要注意的是,给内置类型定义方法是不被允许的,而接口类型是无效的方法接收者。所以我们不能像下面的类型 T 这样,给内置类型和接口定义方法。
func (t T) Test() {
// ......
}
2.3 类型元数据
数据类型虽然然多,但是不管是内置类型还是自定义类型都有对应的类型描述信息,称为它的 “类型元数据”。而且每种类型的元数据都是全局唯一的,这些类型元数据构成了 Go 语言的 “类型系统”。
而类型元数据这里,像类型名称、大小、对齐边界、是否为自定义类型等,是每个类型元数据都要记录的信息,所以被放到了 runtime._type 结构体中,作为每个类型元数据的 Header。
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
// ......
}
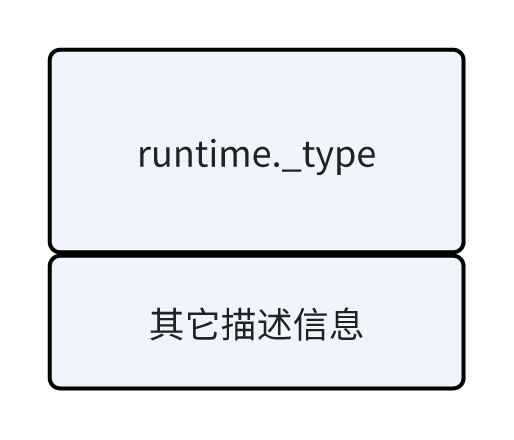
在 _type 之后存储的是各种类型额外需要描述的信息,例如 slice 的类型元数据在 _type 结构体后面记录着一个 *_type,指向其存储的元素的类型元数据。如果是 string 类型的 slice,下面这个 *_type 类型的指针就指向 string 类型的元数据。
// 假设为[]string类型元数据
type slicetype struct {
typ _type
elem *_type // 会指向string类型元数据
}
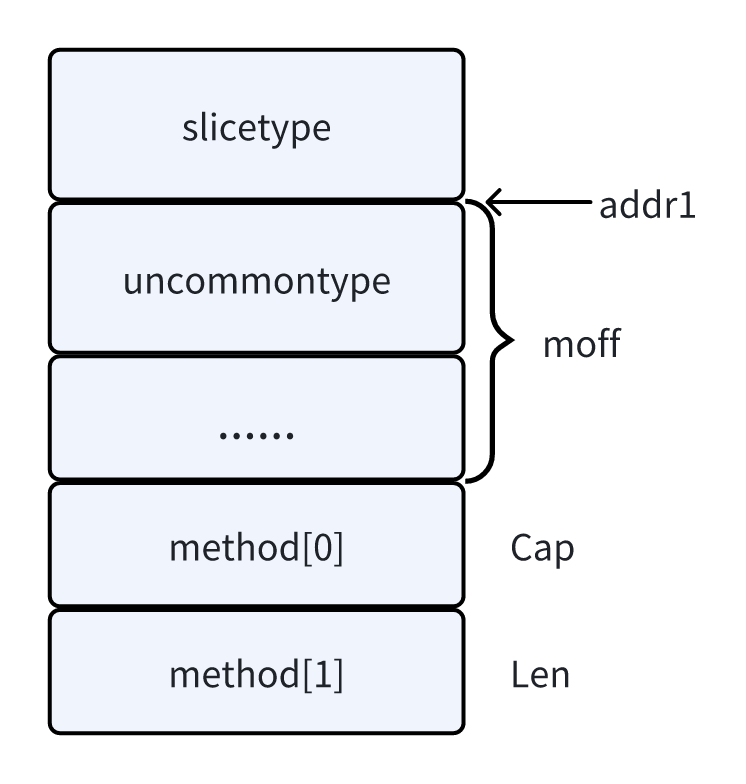
如果是自定义类型,在其它描述信息的后面还会有一个 uncommontype 结构体。
type uncommontype struct {
pkgpath nameOff // 记录类型所在的包路径
mcount uint16 // 记录了该类型关联到多少个方法
_ uint16
moff uint32 // 记录的是这些方法元数据组成的数组相对于这个uncommontype结构体偏移了多少字节
_ uint32
}
// 方法描述信息
type method struct {
name nameOff
mtyp typeOff
ifn textOff
tfn textOff
}
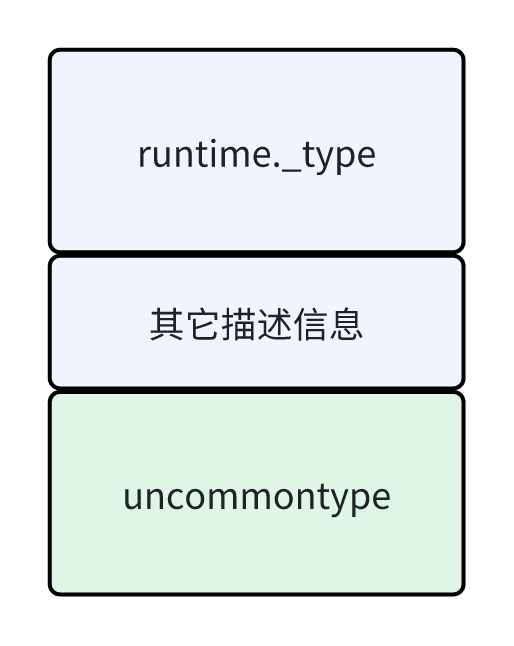
例如,我们基于 [ ]string 定义一个新类型 myslice,它就是一个自定义类型,可以给它定义两个方法 Len 和 Cap。
type myslice []string
func (ms myslice) Len() {
fmt.Println(len(ms))
}
func (ms myslice) Cap() {
fmt.Println(cap(ms))
}
myslice 的类型元数据首先是 []string 的类型描述信息,然后在后面加上 uncommontype 结构体,注意通过 uncommontype 这里记录的信息,我们就可以找到给 myslice 定义的方法元数据在哪了。
如果 uncommontype 的地址为 addrA,加上 moff 字节的偏移,就是 myslice 关联的方法元数据数组了。
2.4 类型误区
接下来我们可以利用类型元数据来解释下面这两种写法:
- MyType1 这种写法,叫做给类型 int32 取别名。实际上 MyType1 和 int32 会关联到同一个类型元数据,属于同一种类型,例如 rune 和 int32 就是这样的关系。
- MyType2 这种写法,属于基于已有类型创建新类型,MyType2 会自立门户,从而拥有自己的类型元数据。即使 MyType2 相对于 int32 来说没有做任何改变,但它两对应的类型元数据也已经不同了。
// 写法一
type MyTypr1 = int32
// 写法二
type MyType2 int32
从上面的这些例子可以知道,每种类型都有唯一对应的类型元数据,而类型定义的方法能通过类型元数据找到,那么很多问题就变得好解释了,例如接下来要介绍的接口。








![[数据结构]排序 --2](https://i-blog.csdnimg.cn/direct/4fb02329afd54ebcade86b194165ffd5.png)