摘要:我们提出了OLMoTrace,这是第一个将语言模型的输出实时追溯到其完整的、数万亿标记的训练数据的系统。 OLMoTrace在语言模型输出段和训练文本语料库中的文档之间找到并显示逐字匹配。 我们的系统由扩展版本的infini-gram(Liu等人,2024)提供支持,可在几秒钟内返回追踪结果。 OLMoTrace可以帮助用户通过训练数据的视角来理解语言模型的行为。 我们展示了如何使用它来探索事实检查、幻觉和语言模型的创造力。 OLMoTrace是公开的,完全开源的。Huggingface链接:Paper page,论文链接:2504.07096
研究背景和目的
研究背景
随着语言模型(LMs)在各个领域的应用日益广泛,从文本生成到问答系统,再到对话机器人,LMs的性能和复杂性也在不断提升。这些模型通常是在大规模文本语料库上训练的,这些语料库可能包含数万亿个标记。然而,尽管这些模型在生成文本方面表现出色,但它们的行为,尤其是如何生成特定输出的决策过程,仍然是一个黑箱。理解LMs的行为对于评估它们的可靠性、公平性、以及在实际应用中的适用性至关重要。
现有的方法,如影响力函数(Koh and Liang, 2017; Han et al., 2020),尝试通过梯度信息来识别对给定测试示例有影响力的训练示例。然而,这些方法在计算上非常昂贵,难以扩展到数万亿标记的训练数据上。其他方法,如检索增强生成(RAG)系统,虽然从数据库中检索相关文档并基于这些文档进行LM生成,但它们并不直接显示LM输出与训练数据之间的逐字匹配。
因此,迫切需要一种能够高效地将LM输出实时追溯到其完整训练数据的方法,以便更好地理解LMs的行为和决策过程。
研究目的
本研究旨在开发一个系统,该系统能够实时地将语言模型的输出追溯到其完整的、数万亿标记的训练数据。具体来说,本研究的目标包括:
- 开发一个高效的系统:该系统能够在数秒内返回追踪结果,使得用户能够实时地探索语言模型的行为。
- 实现逐字匹配:系统需要在语言模型输出段和训练文本语料库中的文档之间找到并显示逐字匹配,以提供LM输出与训练数据之间的直接联系。
- 促进理解和应用:通过该系统,用户能够更好地理解语言模型的行为,探索其在事实检查、幻觉生成和创造力等方面的表现,并评估其在实际应用中的适用性。
- 公开和开放源码:系统应该是公开的,并且完全开放源码,以促进研究和社区的发展。
研究方法
系统概述
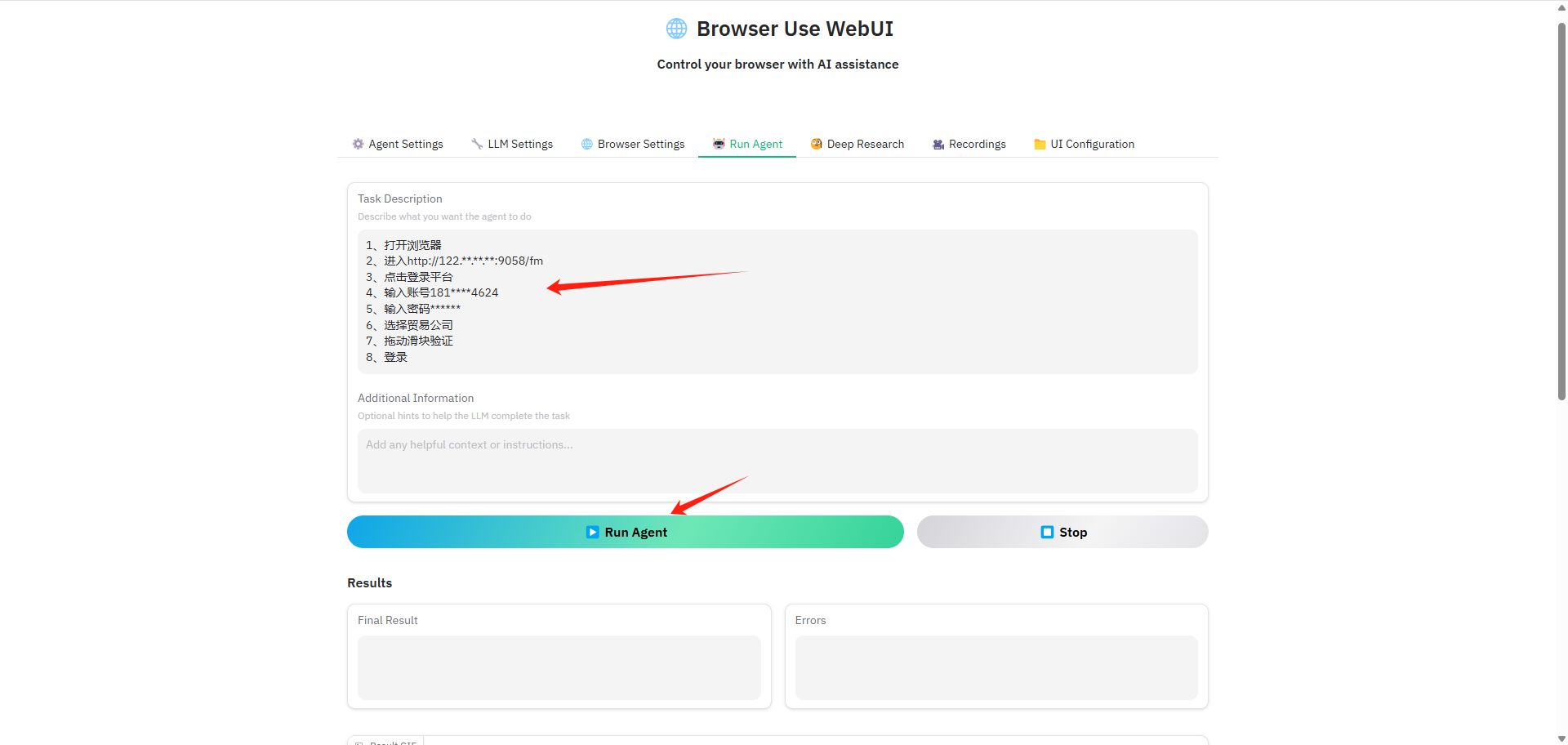
本研究提出了OLMoTrace系统,该系统利用扩展版本的infini-gram(Liu et al., 2024)来索引语言模型的训练数据,并开发了一种新颖的并行算法来加速匹配跨度的计算。OLMoTrace的推理管道包括五个步骤:
- 找到最大匹配跨度:在语言模型输出中找到所有在训练数据中出现逐字的最大跨度。这一步通过并行处理LM输出的每个后缀的最长匹配前缀来实现。
- 过滤以保留长且唯一的跨度:为了简化用户界面并仅显示更可能“有趣”的跨度,系统根据跨度一元概率(捕捉长度和唯一性的指标)对跨度进行过滤。
- 检索包含文档:对于每个保留的跨度,系统从训练数据中检索最多10个包含该跨度的文档片段。
- 合并跨度和文档:为了进一步简化用户界面,系统将重叠的跨度合并为一个要在LM输出中高亮的单个跨度,并将来自同一文档的片段合并为一个要在文档面板中显示的单个文档。
- 按相关性重新排序和着色文档:为了优先显示最相关的文档,系统根据BM25分数对文档进行降序排序,并根据相关性级别对文档和跨度高亮进行着色。
关键技术
- Infini-gram索引:使用infini-gram对语言模型的训练数据进行索引,以支持高效的文本查询和匹配文档检索。
- 并行算法:开发了一种新颖的并行算法来加速最大匹配跨度的计算,将时间复杂度降低到O(L log N),并在完全并行化时将延迟降低到O(log N)。
- 文档相关性评估:使用BM25分数对检索到的文档进行排序,并通过人类评估和LLM-as-a-Judge评价来优化超参数设置,以提高文档相关性。
研究结果
系统性能
OLMoTrace系统在实际应用中表现出色。在拥有64个vCPU和256GB RAM的Google Cloud Platform节点上,OLMoTrace的平均推理延迟为4.46秒,能够实时地向用户展示追踪结果。
文档相关性评估
通过人类评估和LLM-as-a-Judge评价,OLMoTrace检索到的文档显示出较高的相关性。第一篇显示文档的平均相关性得分为1.90(人类评估)和1.73(LLM-as-a-Judge评价),前五篇显示文档的平均相关性得分为1.43(人类评估)和1.28(LLM-as-a-Judge评价)。这些结果表明,OLMoTrace能够检索到与LM输出高度相关的训练文档。
案例研究
本研究展示了OLMoTrace在事实检查、追踪“创造性”表达和追踪数学能力方面的应用。例如,在事实检查案例中,OLMoTrace能够指示LM输出中的特定跨度在训练数据中出现逐字,并显示相应的文档,帮助用户验证声明的真实性。在追踪“创造性”表达案例中,OLMoTrace揭示了LM生成的看似新颖的表达可能并非真正新颖,而是从训练数据中学习而来的。在追踪数学能力案例中,OLMoTrace显示了LM执行的算术运算和解决的数学问题在训练数据中的逐字匹配。
研究局限
尽管OLMoTrace系统在多个方面表现出色,但它仍然存在一些局限性:
- 逐字匹配的局限性:OLMoTrace仅找到LM输出与训练数据之间的逐字匹配,这可能无法全面揭示LM生成输出的复杂决策过程。
- 训练数据的潜在问题:OLMoTrace可能会使训练数据中的潜在问题(如版权、个人信息和毒性内容)更容易暴露。
- 系统可扩展性:虽然OLMoTrace在处理当前规模的训练数据时表现出色,但随着语言模型规模的进一步扩大,系统的可扩展性仍需验证。
未来研究方向
为了克服现有局限并推动该领域的发展,未来研究可以从以下几个方面进行探索:
- 改进匹配算法:开发更先进的算法来识别LM输出与训练数据之间的非逐字匹配,以更全面地揭示LM的决策过程。
- 增强数据隐私保护:开发技术来保护训练数据中的隐私信息,同时仍然允许用户探索LM的行为。
- 优化系统性能:针对更大规模的语言模型和数据集,优化OLMoTrace系统的性能,以提高其可扩展性和实用性。
- 拓展应用场景:探索OLMoTrace在更多应用场景中的潜力,如自然语言理解、对话系统评估等,以进一步推动该领域的发展。






![[ctfshow web入门] web33](https://i-blog.csdnimg.cn/direct/7683d76833c34cc99d7ac1f3a1ea9499.png)