目录
前言:
分布式系统
开源节流
认识Redis
负载均衡
缓存
微服务
前言:
本文只是作为Redis的一篇杂谈,简单理解一下Redis为什么要存在,以及它能做到和它不能做到的事儿,简单提及一下它对应的优势有什么,不足有什么之类的。
总之,本文只是Redis入门的杂谈,咱们看看即可~
分布式系统
首先提到Redis,咱们除了能想到它快之外,还应该能想到分布式系统,即便没有系统学习过Redis的同学,对于Redis的第一印象大概率就是它能应用在分布式系统上。
那么什么是分布式系统呢?
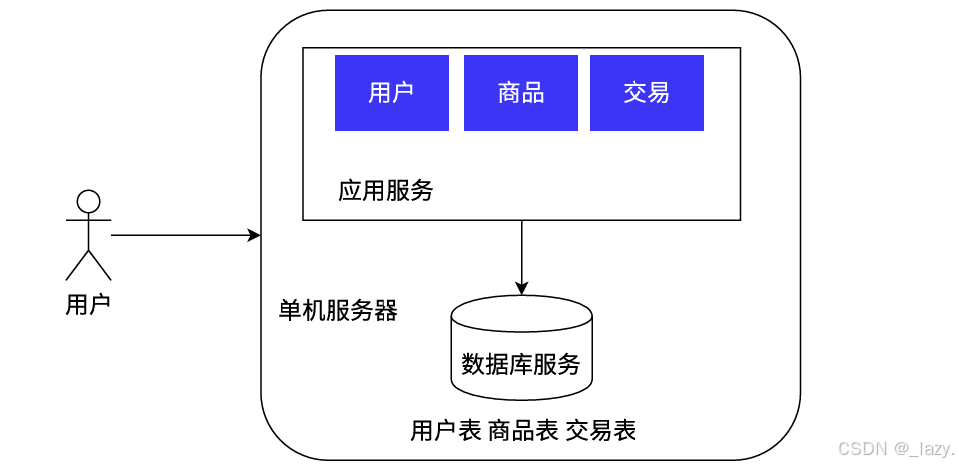
我们从最简单的单机架构开始谈。
其实到目前为止,挺多公司用的还是单机架构的服务器,什么是单机架构呢?就是上层的应用服务和数据库服务都是由一个服务器来完成的。那么这个服务器就会面临一个老生常谈的问题,它这个单机服务器面临大的吞吐量的时候怎么办?
所以当数据量大起来的时候,一台单机服务器就没有办法处理这么多的数据量,我们就可以引入其他服务器来帮助原来的单机服务器处理多余的数据量。
那么问题来了,我们是将服务器直接通上电,然后就可以直接运行,甚至可以直接处理数据了吗?显然并不是。
在引入了多台主机的情况下,我们势必面临的问题是不仅有服务器和服务器之间的连接问题,甚至有了人与人之间的资源调度问题。因为多台主机,代码量几乎是按照指数级增加的,所以前期的代码开发,到后期的代码维护,开发人员运维人员的调度明显是一个问题。
我们从最简单的分布式开始入手,最开始一台服务器处理应用服务和数据库存储服务,那么我们思考,是否可以将数据库存储服务和应用服务分开:
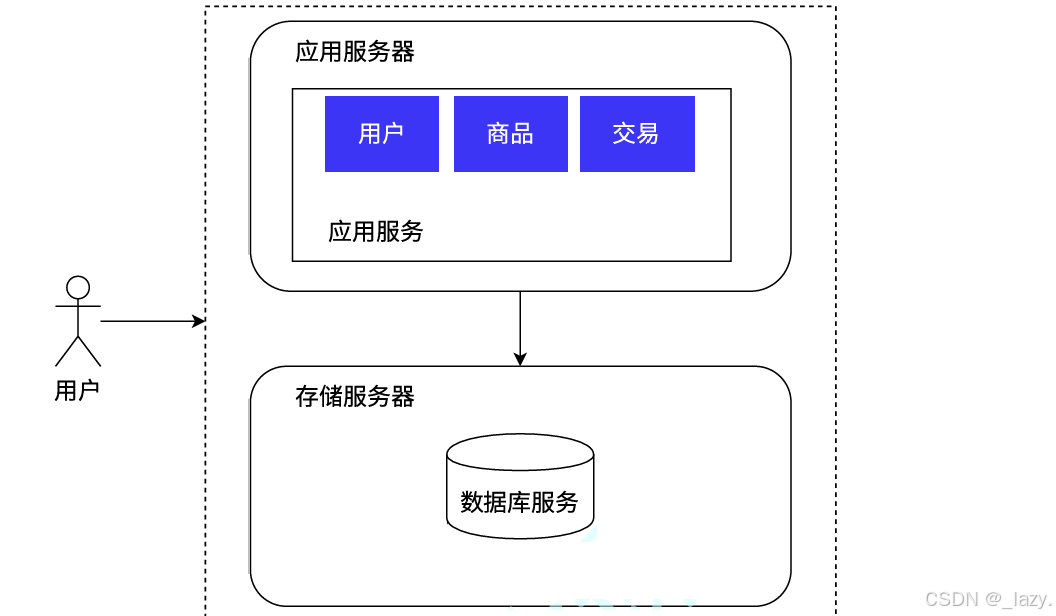
就像这样,我们就拥有了两台主机,一台是应用服务器的主机,一台是存储服务器的主机,一个专门用来处理应用的上层请求,一个专门用来处理数据库的服务。
到现在,最最基本的分布式架构已经出来了,那么我们把数据量往上增加的过程,势必会有一种烦恼:硬件资源和软件资源如何增加?
开源节流
到了这个时候,面对非常庞大的数据量的时候,硬件资源反而是最好提升的,因为服务器处理请求的时候,吃的资源无非就是CPU,内存,硬盘,网络等资源,所以面对硬件资源,我们可以这样提升:主板上面多插几块CPU,多插几块内存,硬盘等同理,对于网络来说我们可以提升网络带宽,可以更换网卡,从万兆网卡更换成千兆网卡。
到这里,我们就简单理解了开源节流中的开源,即非常简单粗暴的增加硬件资源,无脑堆就行,但是我们仍然面临的问题是,主板中的位置是有限的,也就是说硬件资源是没有办法无线堆积的,那么有人就说了,堆积主板呗,只能说想法是美好的,毕竟硬件资源最耗费的就是钱财了~~
那么开源的时候预算到了一定程度,没有办法了,我们是否应该考虑一下涉及到人工成本的节流?
比如Redis存储热点数据的时候,我们使用的是什么数据结构?这样操作下来时间复杂度是多少?空间复杂度是多少?是否还有更多的空间进行优化?
此时就涉及到了人工的优化了,可是随着服务器规模的增大,代码量增大的可不是一点半点,那么人工成本就非常大了,并且改错了一个bug可能就伴随着n个Bug。
所以其实从这里就可以看到,分布式并不是一件太完美的事,虽然增加了数据量的处理,但是处理的成本是真的大~~
认识Redis
当我们访问Redis的官方网站的时候,我们大概率能搜索到以下的关键字:in-memory data store, cache, streaming engine, message broker。

翻译过来就就是存储在内存的数据,缓存,流式引擎,消息队列。
即我们可以理解为Redis可以做的事儿有以上这么多,当然实际上比这些多多了,不过你说Redis能做这么多,是因为它一发明出来就能做这么多事儿吗?
显然不是,最开始Redis的初心只是为了作为消息中间件,即用在消息队列上面,那么这里就涉及了生产消费模型,最开始人们用了一段时间后,发现Redis好像不止可以用在消息队列上,比如应用在流式引擎上好像更香。
所以到这里咱们简单理解呢就是Redis最开始发明出来之后发现应用在其他领域好像也是个香饽饽,也就拿去开发了,不过目前的消息队列呢很少有直接使用Redis作为中间件的,有很多其他著名的中间件,咱们可以上网搜搜~
咱们拿MySQL和Redis来讲,MySQL最大的缺点就是访问慢,数据量一起来,访问速度是会有显著的下降的,而巧了,Redis也可以当作数据库使用,那么我们是不是就可以把MySQL踢出去,直接使用Redis呢?
显然不能,MySQL慢是慢了点,但是人家的存储量比Redis大到哪里去了,那么为什么Redis快呢?因为它是将数据存储到了内存里面。
既然是存储到了内存里面,那么按照访问速度金字塔,CPU是最快的,然后是一级缓存二级缓存三级缓存等,最慢的是硬盘,而MySQL读写都是在硬盘,Redis读写都是在内存,你说这速度差的多不多吧!!
而对于Redis来说,还有一个独特的点是它可以进行网络通信,即将自己的内存数据通过网络发送到其他主机上,这就很强了,不过有的时候也会受限于网络等问题。咱们学习进程的时候都知道有一个东西叫做进程的隔离性,而对于Redis来说,它能进行进程间通信,即网络通信,你说它强不强?
好了,我们简单比较了以下MySQL和Redis的区别之后,我们是否会思考,有没有存储量大且速度快的方案?
显然是有的,我们明显可以结合MySQL和Redis使用,比如利用二八原则,即百分之20的数据可以满足百分之80的访问需求。我们就可以把这百分之20的数据放在Redis里面,到时候直接访问redis就可以了,要是访问的不是这20的数据,再访问MySQL就行。
所以根据上文介绍的分布式系统来说,数据量虽然大,但是总有部分数据是经常访问的,我们就把这种数据成为热点数据,其他数据成为冷数据,冷数据咱们就通过MySQL访问,热数据我们大多都是通过Redis访问。
负载均衡
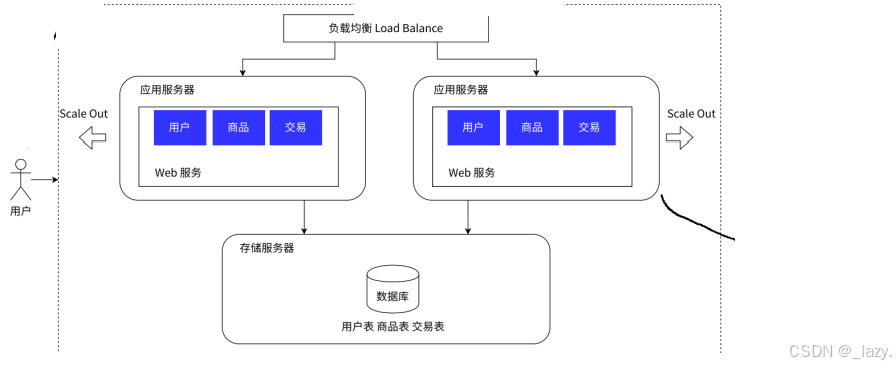
好了,我们现在引入负载均衡的概念了,既然数据量起来了,我们还有多个服务器,那么哪个服务器处理哪个请求呢?最简单的方式是轮询,即A服务器处理了第一个那么就B服务器处理第二个,好了,问题来了,谁来完成这个分配的任务呢?
此时,负载均衡就出现了,负载均衡就像是领导,它不处理请求,它要求的是分发每个请求,即把每个请求根据实际情况分发给不同的服务器,这样就能完成一个削峰填谷的作用。大概率就不能出现某个主机处理的请求太多了导致服务器挂了的情况。
即,负载均衡=领导。
不过既然是领导,既然是要接受所有的请求,虽然不处理,但是仍然是要求负载均衡的接受请求的能力是要大于处理应用服务器的,那么你说会不会数据量大到负载均衡都接受不完的情况?
是非常有可能的,比如双十一,618的时候,就是数据量大爆发的时候,这个时候就可能要引入更多的负载均衡器了。
缓存
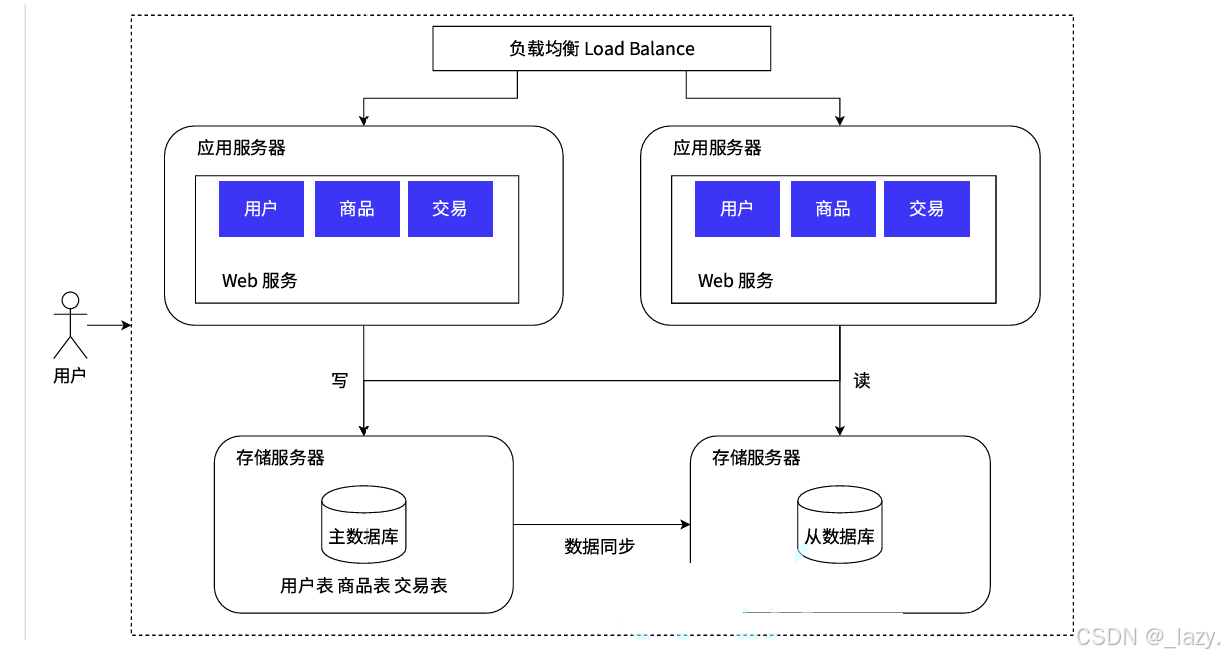
可是你别看数据量这么大的时候只有应用服务器在工作,数据多的时候,数据库可是真的烦恼,因为几乎所有的数据都是要从数据库的这里走的,也就是说数据库服务器是一个人默默承担了所有。
那么为了解决问题,根据实际情况出发,我们发现数据库的读频率是远远大于写频率的,所以我们不妨把数据库服务器分为主数据库和从数据库,一个负责读取一个负责写,这样我们引入了两台服务器分别完成读写的操作,自然面临的一个问题就是同步问题。
而大多数情况,光把数据库分为了读写数据库还不够,因为有的数据非常频繁的访问,这就导致了有的时候同步不及时,所以引入了缓存:
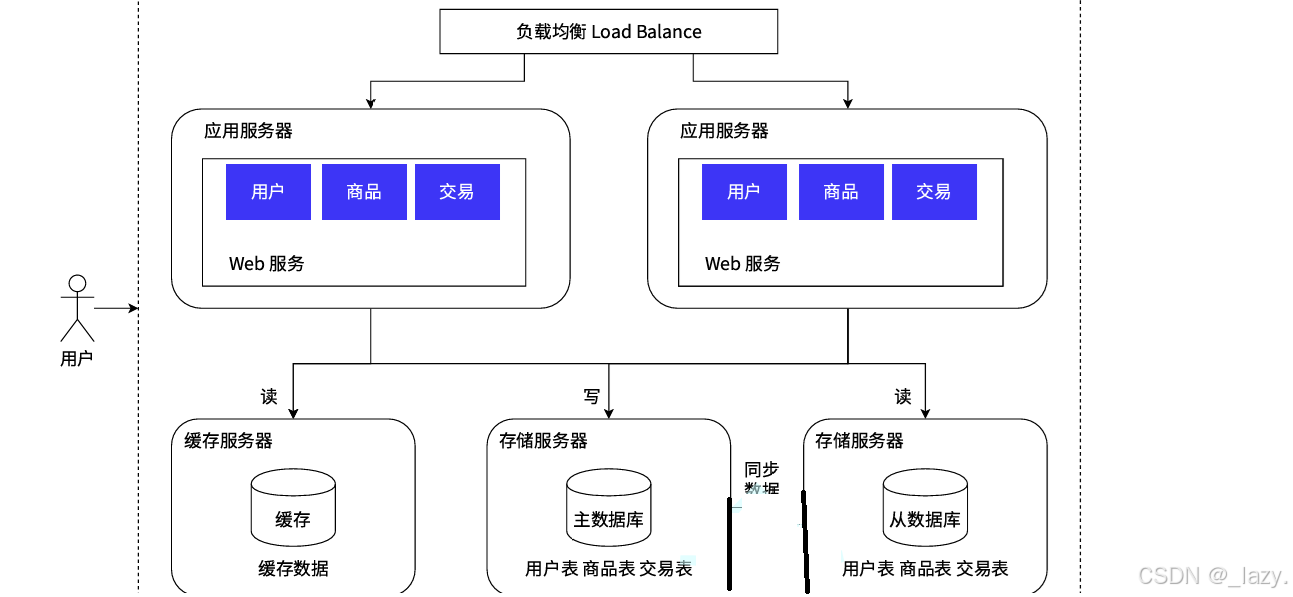
即我们将数据库分为了三个,其中两个用来读取,一个是普通的从数据库,一个是缓存,用来缓存热点数据,这样数据库的压力一下就下来了。
不过还是那句话,这样后面的维护成本是比较大的,并且同步问题的难度也是越来越大了。此时咱门的Redis就应用到了缓存服务器里面了。不过这里的从数据库存放的可都是全量数据。
微服务
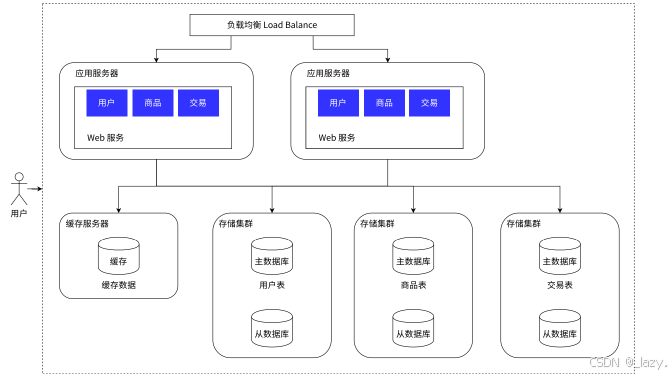
不过如果数据量在极端情况下,非常非常多,多到什么程度呢,多到一张表都需要拆分,此时就需要引入微服务了,即我们将数据量拆分了之后,哪个服务器处理哪个库的哪个表的数据等。
即分库分表。
这个时候的代码量,以及维护难度是大大的提高了,不过能处理数据的程度也确实提升了不少了。
我们在这里就简单的理解了微服务是什么,即将引入了多台服务器,不过处理的内容比较单一,比如就一个数据库的哪个哪个表。不过具体怎么分,那得看实际情况了。
引入微服务,解决了人的问题,付出的代价?
1.系统的性能下降~~(要想保证性能不下降太多,只能引入更多的机器,更多的硬件资源 =>充钱~~)
拆出来更多的服务,多个功能之间要更依赖网络通信,网络通信的速度很可能是比硬盘还慢的!!!幸运的是,硬件技术的发展,网卡现在有 万兆 网卡,读写速度已经能过超过硬盘读写了~~
2.系统复杂程度提高, 可用性收到影响~~
服务器更多了,出现问题的概率就更大了~~
这就需要一系列的手段,来保证系统的可用性~~
(更丰富的监控报警,以及配套的运维人员)
微服务的优势:
1.解决了人的资源分配问题.
2.使用微服务, 可以更方便于功能的复用
3.可以给不同的服务进行不同的部署
小结:
在分布式系统中,我们接触到的名词有:
应用/系统:即一个服务器程序。
模块/组件:即一个应用中独立的功能
分布式:引入多个服务器,每个服务器协同工作
集群:其实就是分布式上的多个主机,不过集群偏逻辑上
主从结构:比如数据库可以分为主从数据库,服务器节点也是
中间件:和业务无关的功能,比如消息队列,数据库,更多的是为了协助整个服务器工作。
可用性:系统整体可用的时间/总时间
响应时间:肯定是越短越好
吞吐量和并发:一条高速公路,两个车道,并发量为2,一分钟过了100辆车,吞吐量为100.
感谢阅读!
本文主要还是通过分布式系统简单引入Redis~~所以较为粗糙~~后面会越来越详细的!!