Hadoop是什么
Hadoop为分布式系统基础框架。主要解决海量数据的存储和海量数据的分析计算问题。
大数据解决的是海量数据的采集、存储和计算。
Hadoop三大发行版本
Apache 最原始最基础的版本,2006年诞生,开源;
Cloudera 内部封装Apache,对应产品CDH,2008年,部分免费,已结束免费;
Hortonworks 内部封装Apache,对应产品HDP,2011年,部分免费,已结束免费。
Cloudera现今已经收购Hortonworks,产品CDP,现今收费,10000美元起步。
Hadoop优势
高可靠性
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性
在集群之间可以动态添加删除服务器,而不需要停止然后重新启动。
高效性
在MapReduce影响下,Hadoop是并行工作的,如此可以加快任务的处理速度。
高容错性
可以自动地将失败的任务重新地分配。
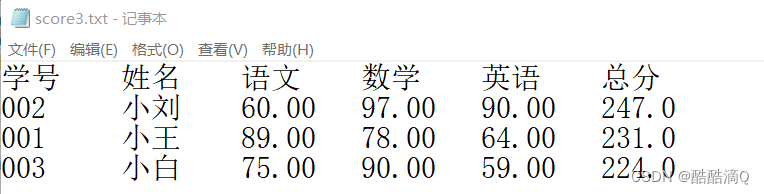
Hadoop的组成
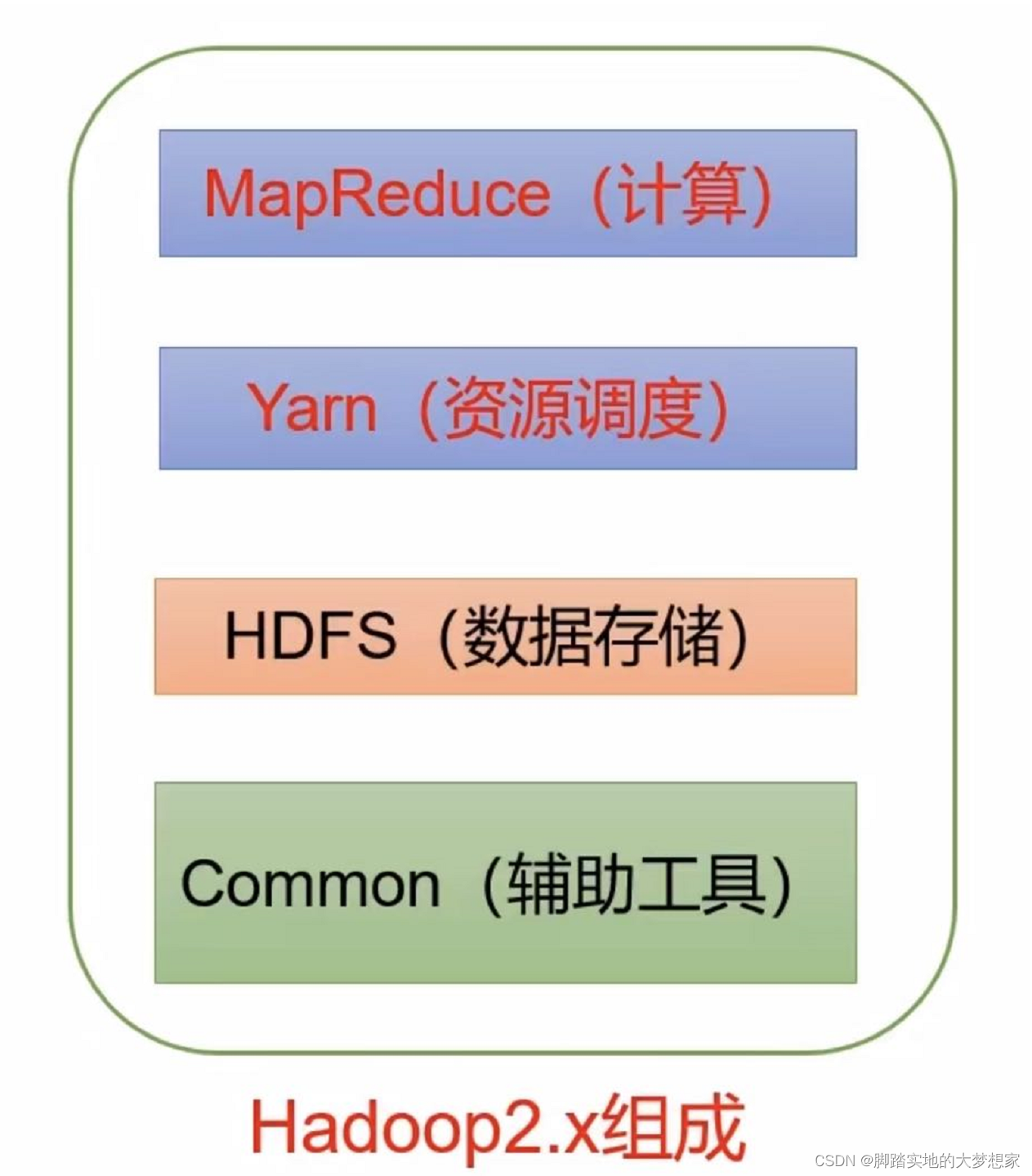
Hadoop1.x中,MapReduce同时负责计算与资源调度,在2.x与3.x中,采用MapReduce进行计算以及Yarn进行资源调度。3.x在2.x的基础上,组成结构上并未进行大的变动,只是在某些方面,比如NameNode等有变化。
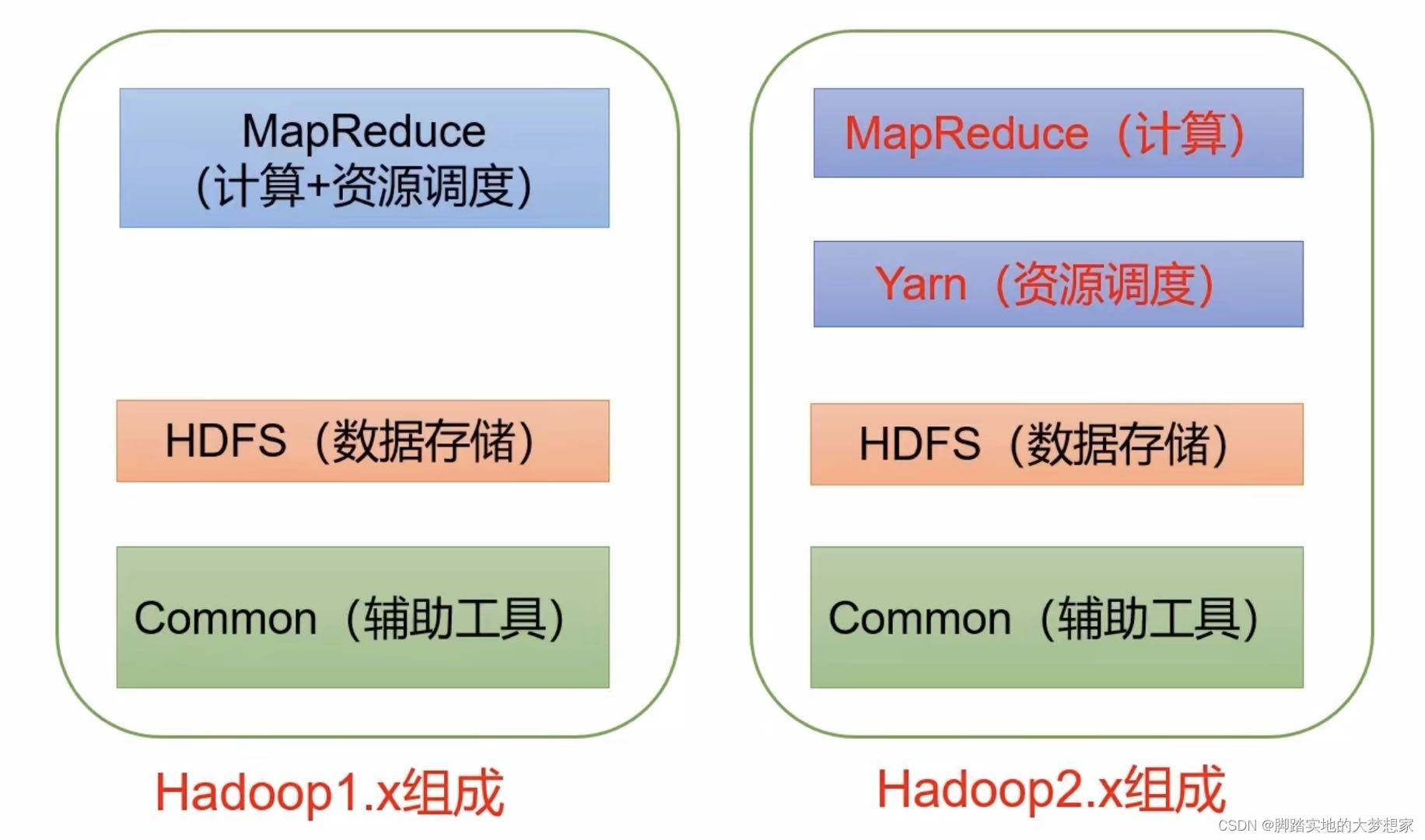
HDFS
HDFS: Hadoop Distribute File System,简称HDFS,是一个分布式文件系统。主要负责资源调度。
HDFS第一个组件,NameNode,用于记录每一个文件块的存储位置;DataNode,具体存储数据的位置。为了防止NameNode“挂了”,所以冗余备份一份,为2NN。
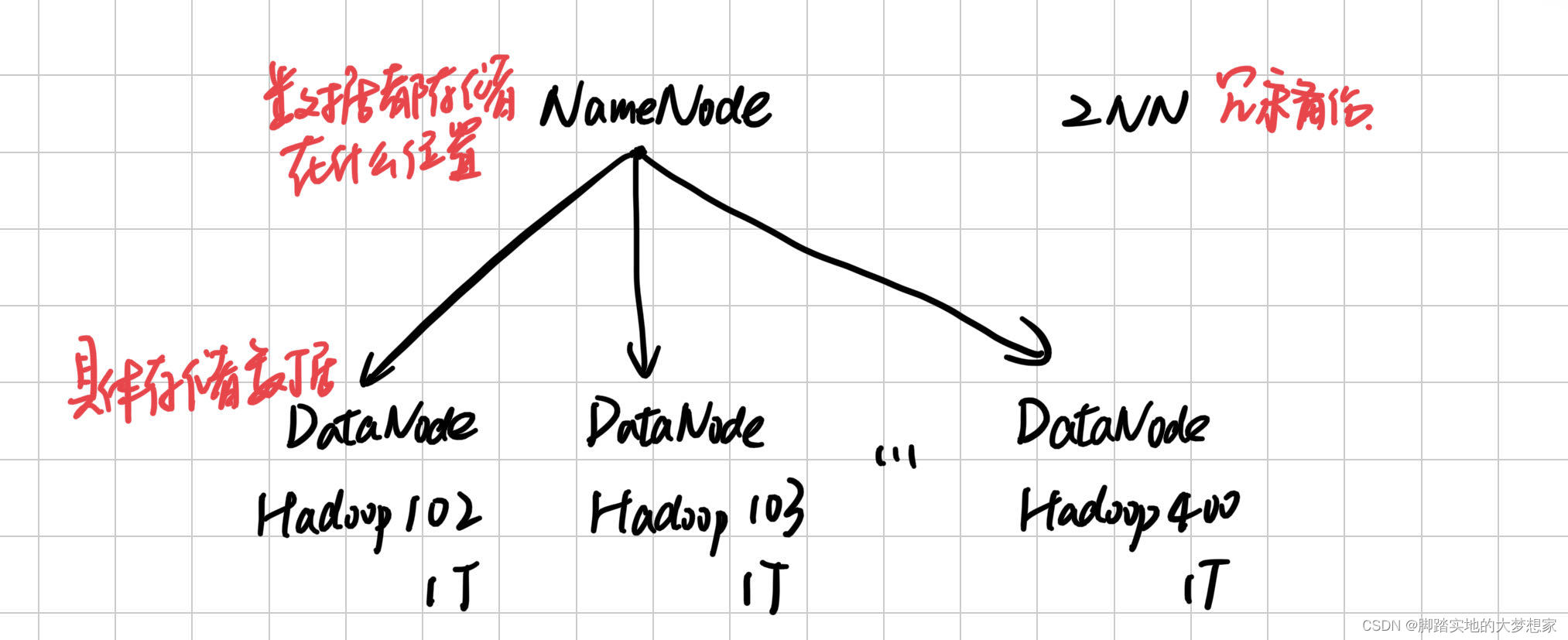
NameNode: 存储文件的元数据,如文件名,文件目录结构,文件属性以及文件的块列表与块所在的DataNode等。
DataNode: 在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode (2NN): 每隔一段时间对NameNode元数据备份。
Yarn架构概述
Yarn:Yet Another Resource Negotiator,资源协调者,是Hadoop的资源管理器,主要管理CPU和内存。
ResourceManager (RM),整个集群资源的管理者,为所有单结点资源的集合。
NodeManager (NM),单个结点资源的管理者。
ApplicationMaster (AM),单个任务运行的管理者。
Container:容器,每个任务在每个单独的容器中运行,其相当于一台独立的服务器,里面封装了任务运行时所需要的资源。比如为什么100台服务器的数据中心可以提供上万个用户单独使用,就是通过容器。
通过容器,可以跨服务器运行一个任务;比如当容器发现当前开辟的CPU与内存不够用的时,“充值”,通过联系RM,将分配另一块CPU+内存给容器,且另一块的CPU+内存不是必须在一个服务器、NM中。
MapReduce架构概述
MapReduce: 将计算过程分为两个阶段,Map和Reduce。
Map阶段并行处理输入数据;
Reduce阶段对Map结果进行汇总。

HDFS、YARN与MapReduce配合
回忆,DataNode,实实在在存储数据;NameNode,存储在哪个结点上,存储的是什么信息;SecondaryNN,冗余备份,防止NN完蛋。
Yarn负责整个集群资源的管理,RM与NM;
e . g . e.g. e.g. 用户向集群提交一个任务,集群开始工作,RM找到一个结点,开启一个容器,任务放到其中,为App Master,由App来向RM申请CPU与内存大小,RM提供给容器一块又一块CPU与内存。容器到每一个“块”(CPU+内存)的容器称为MapTask,每一个MapTask进行任务,称为MAP;然后进行任务反馈,为Reduce;
以上仅为概述部分,在后面将详细的将每个部分拆解进行详细的阐述。
2022年10月31日
于 香港理工大学


![[vue3] Tree/TreeSelect树形控件使用](https://img-blog.csdnimg.cn/a13ac3b8954b4f96ab0e405e953f91d3.png)

![[操作系统笔记]处理机调度](https://img-blog.csdnimg.cn/e62e76cdaeda48be8d20ba58ae6a061e.png)