一 Spark 运行架构
1 运行架构
定义
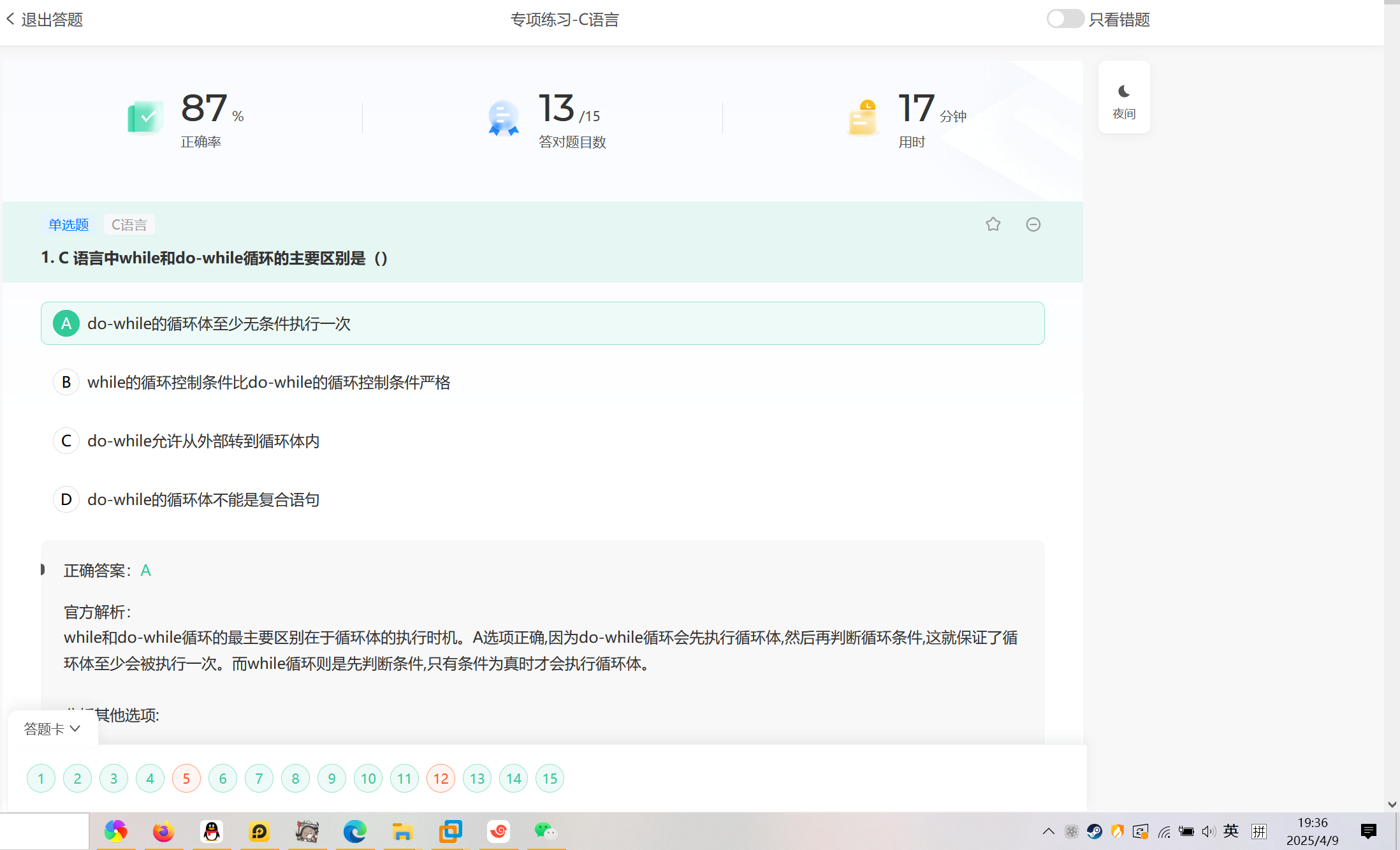
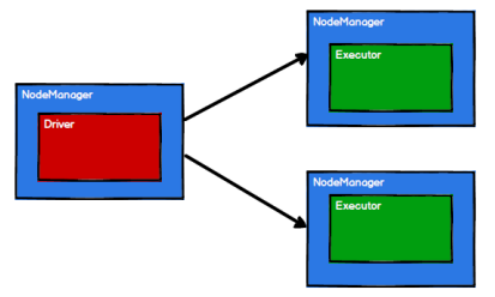
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构 如图所示
2 核心组件
Spark 框架有两个核心组件:
1)Driver
2)Spark 驱动器节点(用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
1) 将用户程序转化为作业(job)
2)在 Executor 之间调度任务(task)
3)跟踪 Executor 的执行情况
4) 通过 UI 展示查询运行情况
Executo
定义
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
核心功能
1) 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
2) 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Master & Worker
还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
ApplicationMaste
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
3 核心概念
3.1 Executor 与 Core
Executor:是 Spark 集群中运行在工作节点(Worker)里的 JVM 进程,属于集群中专门用于计算的节点。提交应用时可指定计算节点个数以及对应资源,像 Executor 的内存大小、虚拟 CPU 核(Core)数量等都是可配置的资源参数。
Core:指的是 Executor 所使用的虚拟 CPU 核数量,是衡量 Executor 计算资源的一个重要方面。
并行度(Parallelism)
在分布式计算框架中,多个任务能同时在不同计算节点进行计算,实现真正的并行执行(区别于并发)。整个集群并行执行任务的数量被称为并行度,其大小取决于框架默认配置,应用程序也可在运行期间动态修改。
有向无环图(DAG)
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
4 提交流程
定义
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。
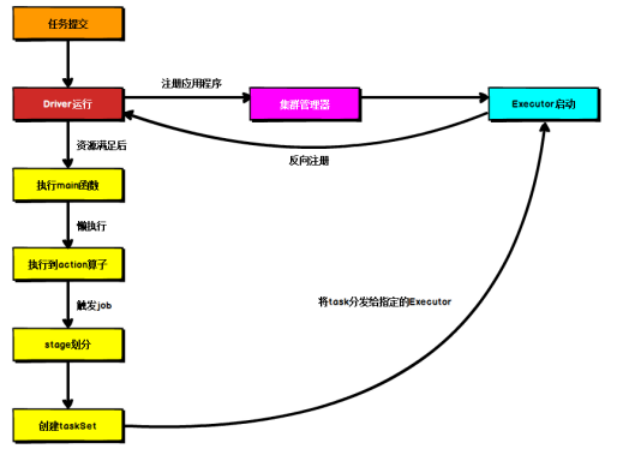
一般会有两种部署执行的方式:Client和 Cluster
两种模式主要区别在于:Driver 程序的运行节点位置。
Yarn Client 模式
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境
二 RDD的概念
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
1)RDD
2)累加器
3)广播变量
1 RDD的定义
RDD叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性特点
1) 存储的弹性:内存与磁盘的自动切换;
2) 容错的弹性:数据丢失可以自动恢复;
3) 计算的弹性:计算出错重试机制;
4) 分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
可分区、并行计算
2 核心属性
1)分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
2)分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。
3)RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
4)分区器
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区
5)首选位置
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
3 执行原理
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
1)启动 Yarn 集群环境

2)Spark 通过申请资源创建调度节点和计算节点
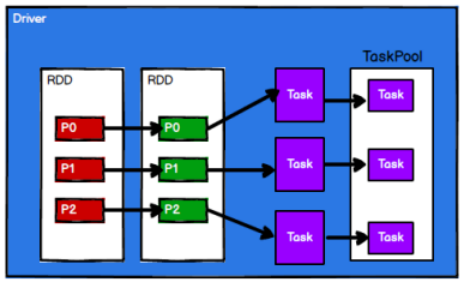
3)Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
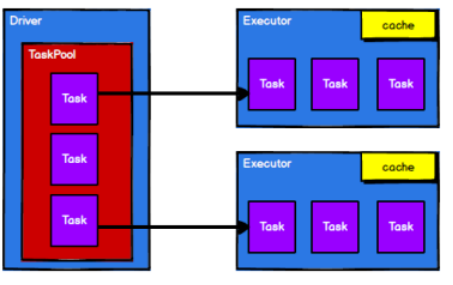
4)调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
4 RDD序列化
1) 闭包检查
2) 序列化方法和属性
3) Kryo 序列化框架
RDD 依赖关系
1) RDD 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2) RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。包括打印依赖、shuffle依赖等。
3) RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
4) RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
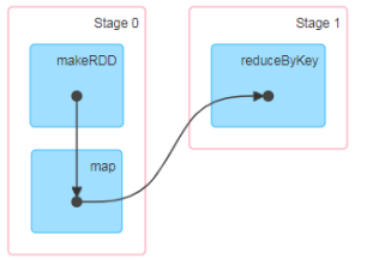
5) RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
6) RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task
Application:初始化一个 SparkContext 即生成一个 Application;
Job:一个 Action 算子就会生成一个 Job;
Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
RDD 持久化
1) RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
2) RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
3) 缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
RDD 分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
➢ 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
➢ 每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
- Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余。
- Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
RDD 文件读取与保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。可以通过 objectFile[T: ClassTag](path)函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
三 spark core 编程
1 spark实现单词统计
1.1 创建maven 在pom.xml中添加依赖
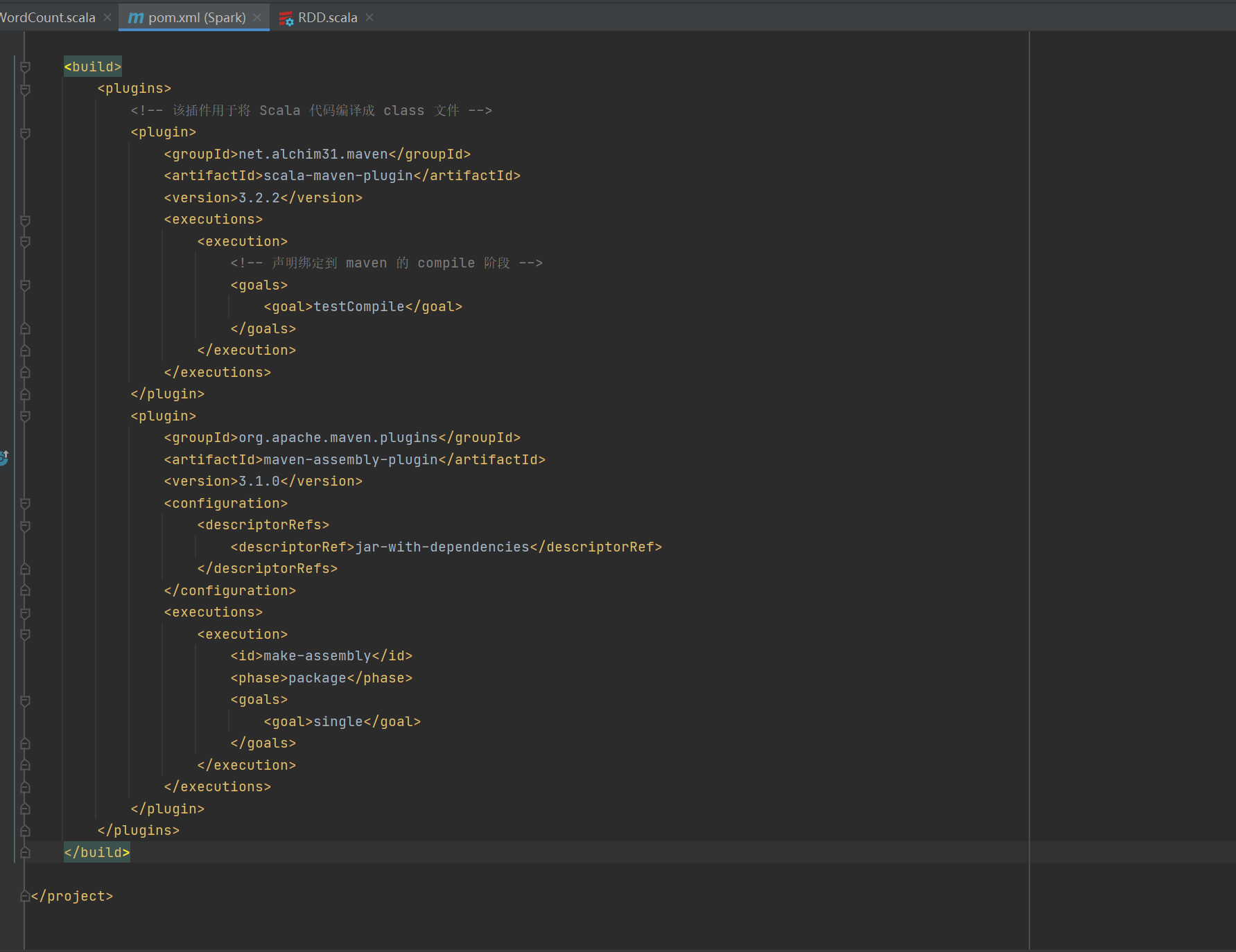
如图所示 就是成功添加依赖
1.2 创建文本文件
1.3 编写WordCount程序
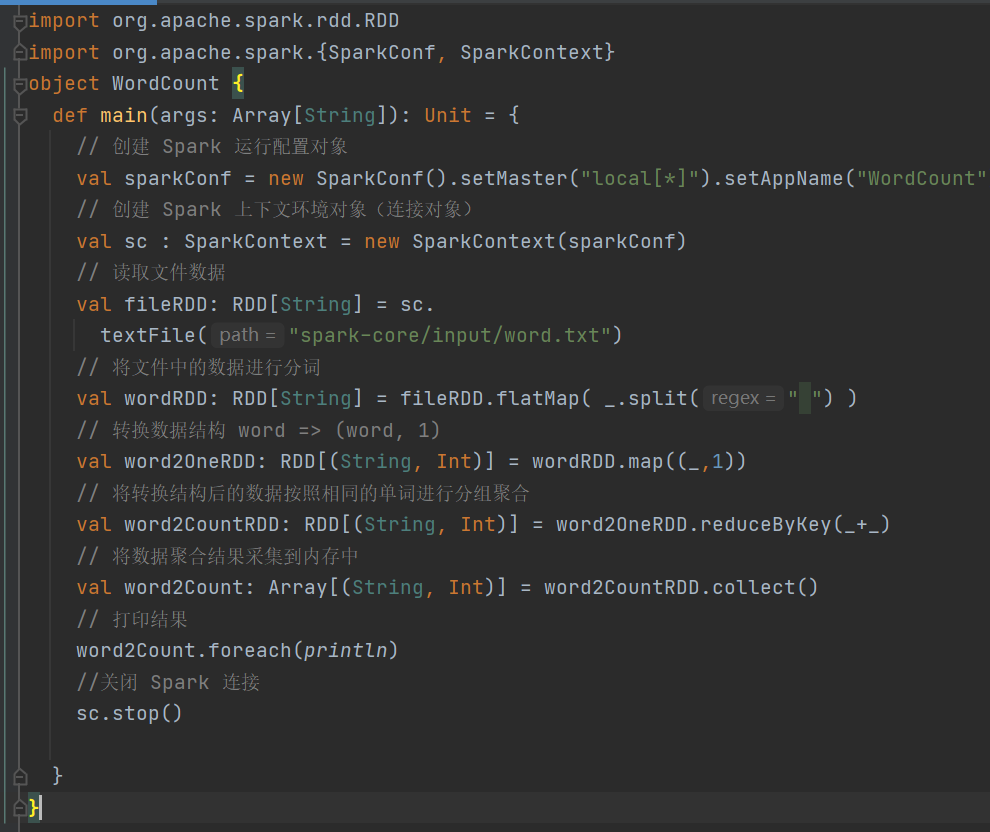
运行结果

2 RDD 的创建
2.1从集合(内存)中创建 RDD
任务要求:从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD
案例演示
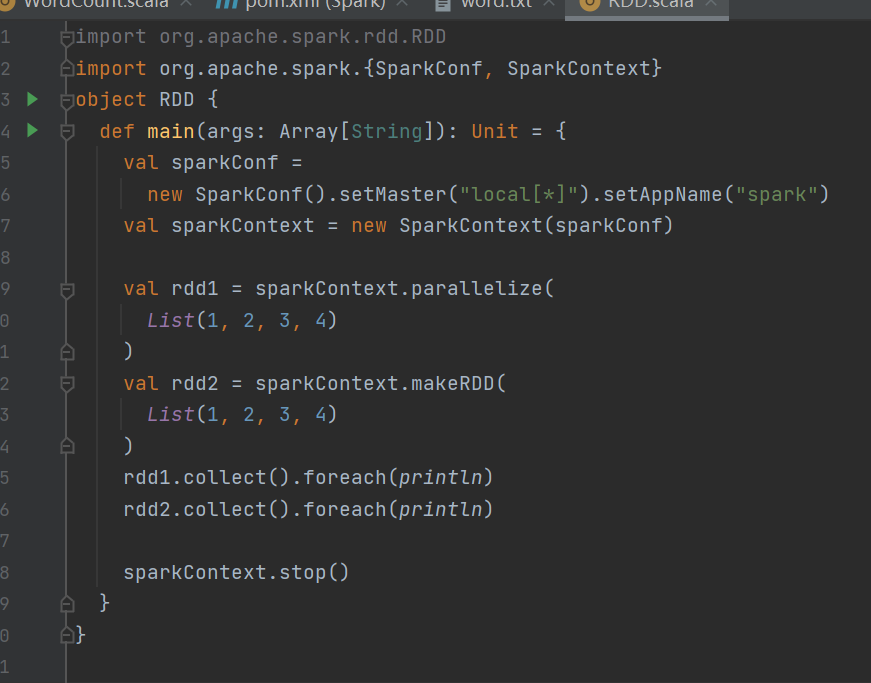
运行结果



![[ctfshow web入门] web7](https://i-blog.csdnimg.cn/direct/ad4910345cb34925ae416c4c9599404f.png)