1. 背景
arXiv简介(参考DeepSeek大模型生成内容):
- arXiv(发音同“archive”,/ˈɑːrkaɪv/)是一个开放的学术预印本平台,主要用于研究人员分享和获取尚未正式发表或已完成投稿的学术论文。
- 创建于1991年,最初服务于高能物理领域,后扩展至数学、计算机科学、定量生物学、统计学等多学科。
- 截至2023年,收录论文超200万篇,月均访问量超3000万次
- 已成为许多领域(如理论物理、机器学习)的首发平台,例如AlphaGo、GPT等突破性研究均先发布于arXiv。
- 支持按学科、关键词、作者等检索,并提供每日更新订阅服务。
- arXiv通过即时共享研究成果,显著推动了开放科学运动,尤其在高动态领域(如人工智能)中成为不可或缺的工具。
由于arXiv的这些特点,对于做科技动态跟踪来说,arXiv就是一个重要的论文来源。通过对arXiv论文进行采集、处理和分析,可以帮助我们了解前沿热门技术、分析技术研究的演化脉络、构建学术合作网络、辅助开展科研等。
2. 需求简介
计划通过大模型技术(RAG、DeepSearch等)帮助对论文进行阅读理解、提取关键信息,能够回答我们提出的问题,例如论文的主要创新点是什么,或者论文的实验结果相比之前的SOTA提升了多少百分点。
整理一下技术需求,包括以下关键内容:
- arXiv论文数据采集:通过某种方式,实现最新论文的持续采集,从而获取最新的论文数据。
- 论文信息抽取:通过直接采集或对采集原始数据进行抽取的方式,获取论文题目、作者、摘要、正文、表格、图表、参考文献、附录等信息。
- 数据存储:基于某种数据库或文件系统,对下载及抽取的论文数据进行保存,从而方便查询、展示。需要设计合适的ID机制精确定位每一篇论文。
- 建立索引:为了支持从大量论文中快速查找最相关的论文,需要建立索引。以往主要是建立全文索引(比如基于
ElasticSearch),当前大模型技术背景下,则还需要建立向量索引(基于某种向量数据库如Qdrant)。 - 跨模态检索:由于论文中的表格和图表信息也很重要,不仅需要对元信息和正文建立全文索引、文本向量化索引,还需要对表格、图表建立某种索引。目前先考虑对图表建立向量化索引,从而支持进行论文图片的语义匹配。
- 论文内容细粒度抽取识别:针对一些更复杂需求(如进行技术分析、构建技术发展脉络等),可能还需要对论文正文文本、表格、图表等进一步抽取识别;若需要建立学者合作网络,则需要对作者信息进行准备识别,并进行学者链接;若需要建立论文引用关系网络,则需要对参考文献部分进行解析,并与已有的论文库进行链接;等等。这类需求非常复杂本文暂不考虑。(在知识图谱时代,为了实现很多复杂需求,就必须做这些工作。但现在很多技术都可以被大模型技术代替。)
3. 准备工作
由于任务背景与需求较为复杂,需要开展数据调研,搞清楚到底可以从哪些渠道获取数据,根据数据源的情况确定采用什么样的技术实施方案。这是非常重要的,如果可以获取相对结构化的数据,可能就不需要做诸如PDF解析抽取等复杂工作。
3.1.数据源
3.1.1.arXiv官网网页
首先想到的是arXiv官网,提供了搜索和详情阅读功能。
搜索功能按照领域提供单独的URL,如计算机科学主页是https://arxiv.org/search/cs,其中cs是Computer Science的缩写。支持输入关键词,支持选择搜索的字段。
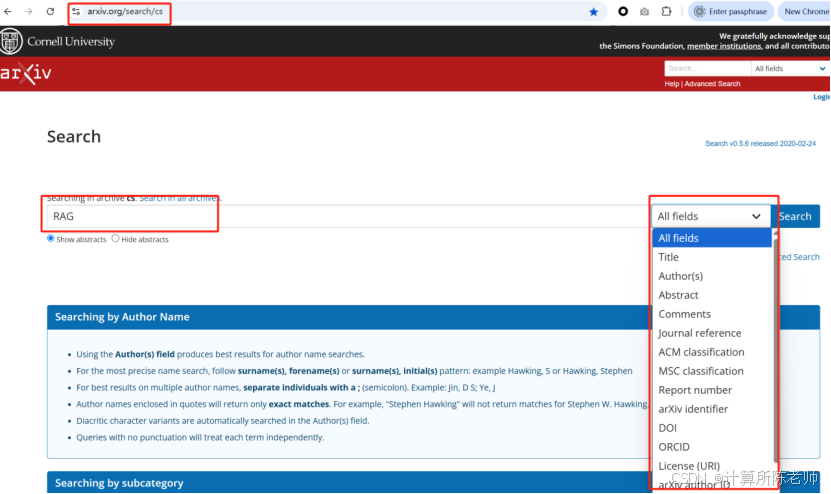
当我们输入关键词进行搜索,系统默认返回50篇。URL中显示了搜索关键词(query=RAG)、搜索字段(searchtype=all)、排序顺序(order=-announced_date_first,应该是指最初发布时间的倒序)、每页数量(size=50)。搜索结果中包含了论文编号(如2504.02458)、PDF格式链接、其他格式链接、子领域(cs.IR,即计算机科学领域的信息检索子领域)、主题(如Retrieval-Augmented Purifier for Robust LLM-Empowered Recommendation)、作者(如Liangbo Ning)、论文摘要、提交日期、最初发布时间(只到月份),以及备注(可能没有)。基于爬虫技术,可以快速实现论文搜索,获取指定关键词匹配的论文的基本信息。
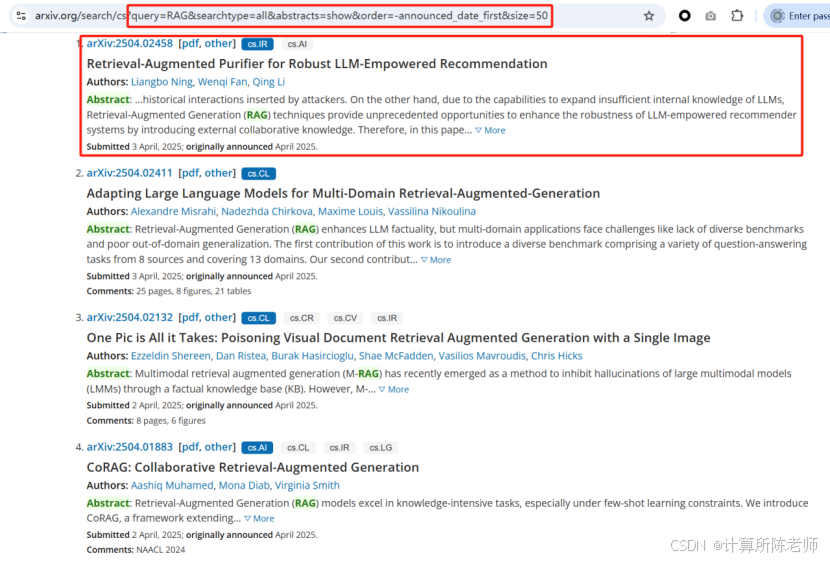
打开PDF链接,可以看到浏览器直接显示了论文的PDF文件内容。可以注意到网页链接(以arxiv.org/pdf/为前缀,加上论文编号)非常简洁、有规律。
至此,我们可以通过搜索页面,获取指定关键词的论文的基本信息,然后根据ID下载PDF文件。
考虑到论文编号(ID)存在明显的规律,YYMM.nnnnn,年月+5位数字编号,因此如果需要大规模的采集,也许可以通过直接构造ID下载PDF格式论文。
3.1.2.arXiv官网API
实际上arXiv官网提供了搜索API,完全不需要我们去用传统爬虫的方式去获取论文信息。查看详情以及详情。
对于Python开发者,既可以直接通过requests库访问arXiv API(请求示例),还可以通过基于该API封装的python包进行,安装arxiv库即可使用,查看详情。arxiv库除了获取论文基本信息外,还提供了论文下载方法,可获取论文源文件和PDF文件,并且支持对搜索结果进行批量下载。样例数据 为API返回结果的样例(XML格式),对应的JSON格式样例。
3.1.3.arXiv官网RSS订阅
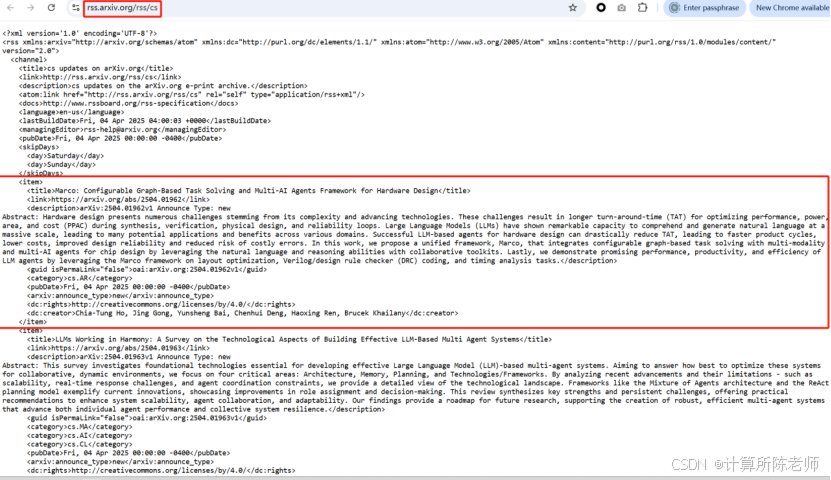
基于arXiv官网API可以根据指定关键词或ID进行论文搜索、下载,获取论文基本信息、源文件、PDF文件等。但是如何进行持续采集呢?如何自动获取最新的论文数据?针对这个需求,arXiv提供了RSS订阅,支持按照领域和子领域获取,查看RSS说明。RSS订阅数据每天更新一次,在美国东部时间的午夜,也就是北京时间12点-13点左右,理论上,可以让用户在下午看到当天中午以前发布的论文,时效性已经挺好的了。
RSS为XML格式,可引入XML解析库进行解析。不过注意,RSS只包含论文基本信息,源文件和PDF文件需要单独下载(可以配合arxiv库进行)。
3.1.4.kaggle数据集
上述方法可以获取特定主题的论文以及最新的论文。如果需要获取更多历史数据呢?或者如果需要构建一个足够大的论文库以支持长时间跨度分析,有比搜索更好的方法吗?
首先想到的是暴力采集方法,通过构造论文编号,利用arxiv库进行基本信息获取和论文下载。不过这个需要进行大量的请求,考虑到arxiv网站的访问限制策略,可能需要花费很漫长的时间。
幸运的是,在kaggle平台上,官方机构提供了每周更新的数据集,可以直接从kaggle下载,或者通过谷歌云平台下载。目前JSON格式文件约4.6G(zip格式1.5G左右),每周下载一次,对带宽和处理要求都不高。注意,源文件或PDF文件仍需要单独下载。这里查看样例数据,其中包含了1000条数据供测试。
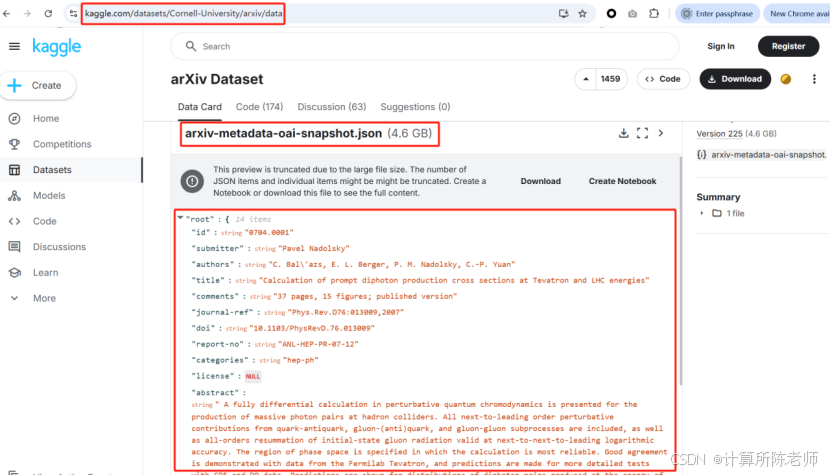
3.1.5 小结
综合来说,可以采取一次性下载kaggle数据集+RSS订阅跟踪的方式,实现最新论文元数据的持续获取。对于源文件和PDF文件,则需要综合考虑业务需求和资源情况。按照每月3万篇、每个PDF文件3MB估算,则每天需要下载3GB;在不考虑IP资源池的情况下,每次请求需要间隔3秒左右,约需要1个小时左右,总体压力不大。对于超过200万历史数据,需要下载6TB左右,按1MB/s下载速度估算需要140天左右。
3.2.信息抽取
上述方法提供了论文的基本信息,但没有正文、表格、图表、参考文献、附录等信息,需要基于原始数据进行信息抽取。
3.2.1.基于MinerU的PDF内容抽取
一开始以为arXiv仅提供PDF格式文件,以及考虑到大部分论文平台都是提供PDF格式文件,因此考虑基于PDF进行抽取。由于PDF格式特殊性,虽然有不少PDF解析库(如pdfminer、pdfplumber、Camelot、Apache PDFBox等),但是效果不佳。甚至有针对PDF解析的大模型技术研究。
MinerU是一款基于大模型的文档内容提取工具,代码开源,效果较好。MinerU可以直接解析生成Markdown格式内容,可以用于大模型的输入(RAG的上下文),这也是我们考虑使用MinerU的一个重要原因。在此之前,已经在SmartETL中实现了markdown格式解析为层级化JSON结构,可以方便构建层级化索引。
考虑到文档解析的广泛需求,将MinerU部署为docker镜像,并进行API封装,方便调用。
实验测试发现,MinerU(没有GPU加速)抽取一页需要大约20秒,对于20页的论文,则需要7分钟左右。
3.2.2.arXiv官网HTML网页内容抽取
其实,arXiv除了提供PDF格式,还提供源文件以及HTML文件。相比PDF抽取,HTML解析会简单、高效和准确得多。需要注意:(1)HTML页面的URL不仅有ID编号,还有一个版本号(如v1);(2)少量论文可能没有对应的HTML。
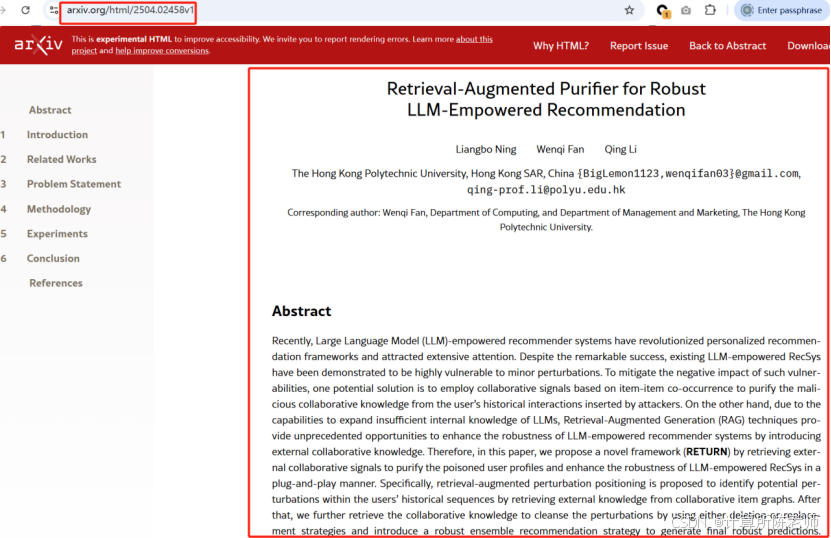
通过浏览器审查,发现HTML页面结构设计规范,便于进行抽取:
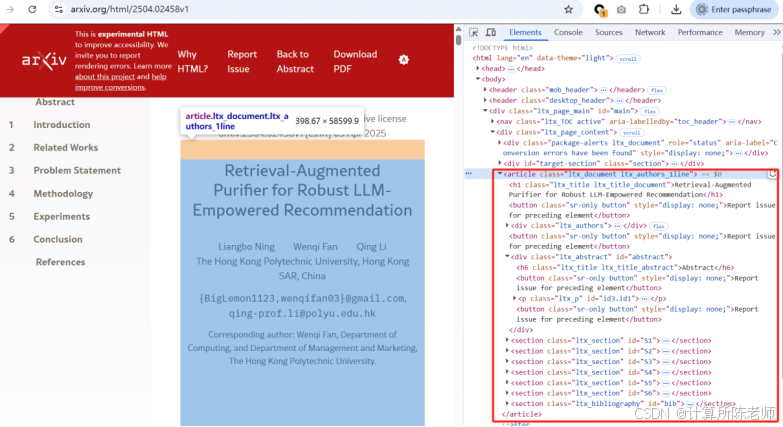
另外对于论文中图片,HTML页面是通过图片链接的方式包含,因此需要通过解析HTML构造图片绝对URL,进而下载图片。