本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:了解 响应内容的分类 Selenium概要 selenium的介绍 知识点: 1. selenium运行效果展示 1.1 chrome浏览器的运行效果 Selenium概要 selenium的其它使用方法 知识点: 1. selenium标签页的切换 知识点:掌握 selenium控制标签页的切换 反爬与反反爬 常见的反爬手段和解决思路 学习目标 1 服务器反爬的原因 2 服务器常反什么样的爬虫 反爬与反反爬 验证码处理 学习目标 1.图片验证码 2.图片识别引擎 反爬与反反爬 JS的解析 学习目标: 1 确定js的位置 1.1 观察按钮的绑定js事件 Mongodb数据库 介绍 内容 mongodb文档 mongodb的简单使用 Mongodb数据库 介绍 内容 mongodb文档 mongodb的聚合操作 Mongodb数据库 介绍 内容 mongodb文档 mongodb和python交互 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的入门使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy管道的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy中间件的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy_redis原理分析并实现断点续爬以及分布式爬虫 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的日志信息与配置 利用appium抓取app中的信息 介绍 内容 appium环境安装 学习目标
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/爬虫/爬虫开发从0到1全知识教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:
scrapy爬虫框架
介绍
我们知道常用的流程web框架有django、flask,那么接下来,我们会来学习一个全世界范围最流行的爬虫框架scrapy
内容
- scrapy的概念作用和工作流程
- scrapy的入门使用
- scrapy构造并发送请求
- scrapy模拟登陆
- scrapy管道的使用
- scrapy中间件的使用
- scrapy_redis概念作用和流程
- scrapy_redis原理分析并实现断点续爬以及分布式爬虫
- scrapy_splash组件的使用
- scrapy的日志信息与配置
- scrapyd部署scrapy项目
scrapy官方文档
[
scrapy中间件的使用
学习目标:
- 应用 scrapy中使用间件使用随机UA的方法
- 应用 scrapy中使用ip的的方法
- 应用 scrapy与selenium配合使用
1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用ip等
- 对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2. 下载中间件的使用方法:
接下来我们对腾讯招聘爬虫进行修改完善,通过下载中间件来学习如何使用中间件 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
-
process_request(self, request, spider):
-
当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
-
返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
process_response(self, request, response, spider):
-
当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
-
返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
在settings.py中配置开启中间件,权重值越小越优先执行
3. 定义实现随机User-Agent的下载中间件
3.1 在middlewares.py中完善代码
import random
from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示
class UserAgentMiddleware(object):
def process_request(self, request, spider):
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
# 不写return
class CheckUA:
def process_response(self,request,response,spider):
print(request.headers['User-Agent'])
return response # 不能少!
3.2 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {
'Tencent.middlewares.UserAgentMiddleware': 543, # 543是权重值
'Tencent.middlewares.CheckUA': 600, # 先执行543权重的中间件,再执行600的中间件
}
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
运行爬虫观察现象
4. ip的使用
4.1 思路分析
- 添加的位置:request.meta中增加
proxy字段 - 获取一个ip,赋值给
request.meta['proxy'] - 池中随机选择ip
- ip的webapi发送请求获取一个ip
4.2 具体实现
免费ip:
class ProxyMiddleware(object):
def process_request(self,request,spider):
# proxies可以在settings.py中,也可以来源于ip的webapi
# proxy = random.choice(proxies)
# 免费的会失效,报 111 connection refused 信息!重找一个ip再试
proxy = '
request.meta['proxy'] = proxy
return None # 可以不写return
收费ip:
# 人民币玩家的代码(使用abuyun提供的ip)
import base64
# 隧道验证信息 这个是在那个网站上申请的
proxyServer = ' # 收费的ip服务器地址,这里是abuyun
proxyUser = 用户名
proxyPass = 密码
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 设置
request.meta["proxy"] = proxyServer
# 设置认证
request.headers["Proxy-Authorization"] = proxyAuth
4.3 检测ip是否可用
在使用了ip的情况下可以在下载中间件的process_response()方法中处理ip的使用情况,如果该ip不能使用可以替换其他ip
class ProxyMiddleware(object):
......
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True # 重新发送的请求对象能够再次进入队列
return requst
在settings.py中开启该中间件
5. 在中间件中使用selenium
以github登陆为例
5.1 完成爬虫代码
import scrapy
class Login4Spider(scrapy.Spider):
name = 'login4'
allowed_domains = ['github.com']
start_urls = [' # 直接对验证的url发送请求
def parse(self, response):
with open('check.html', 'w') as f:
f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time
from selenium import webdriver
def getCookies():
# 使用selenium模拟登陆,获取并返回cookie
username = input('输入github账号:')
password = input('输入github密码:')
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver',
chrome_options=options)
driver.get('
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_field"]').send_keys(username)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login"]/form/div[3]/input[3]').click()
time.sleep(2)
cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}
driver.quit()
return cookies_dict
class LoginDownloaderMiddleware(object):
def process_request(self, request, spider):
cookies_dict = getCookies()
print(cookies_dict)
request.cookies = cookies_dict # 对请求对象的cookies属性进行替换
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
小结
中间件的使用:
-
完善中间件代码:
-
process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
需要在settings.py中开启中间件 DOWNLOADER_MIDDLEWARES = { 'myspider.middlewares.UserAgentMiddleware': 543, }
scrapy_redis概念作用和流程
学习目标
- 了解 分布式的概念及特点
- 了解 scarpy_redis的概念
- 了解 scrapy_redis的作用
- 了解 scrapy_redis的工作流程
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
1. 分布式是什么
简单的说 分布式就是不同的节点(服务器,ip不同)共同完成一个任务
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬
- 分布式快速抓取
4. scrapy_redis的工作流程
4.1 回顾scrapy的流程
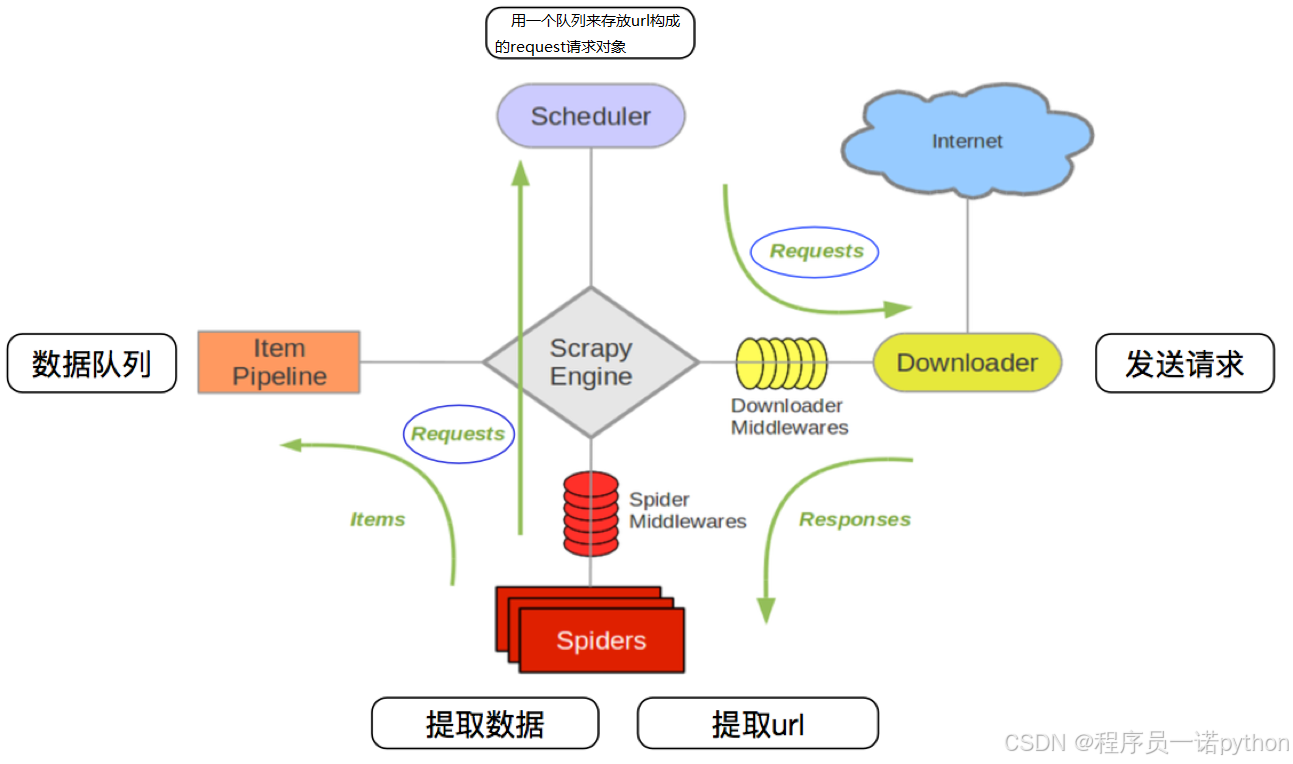
思考:那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
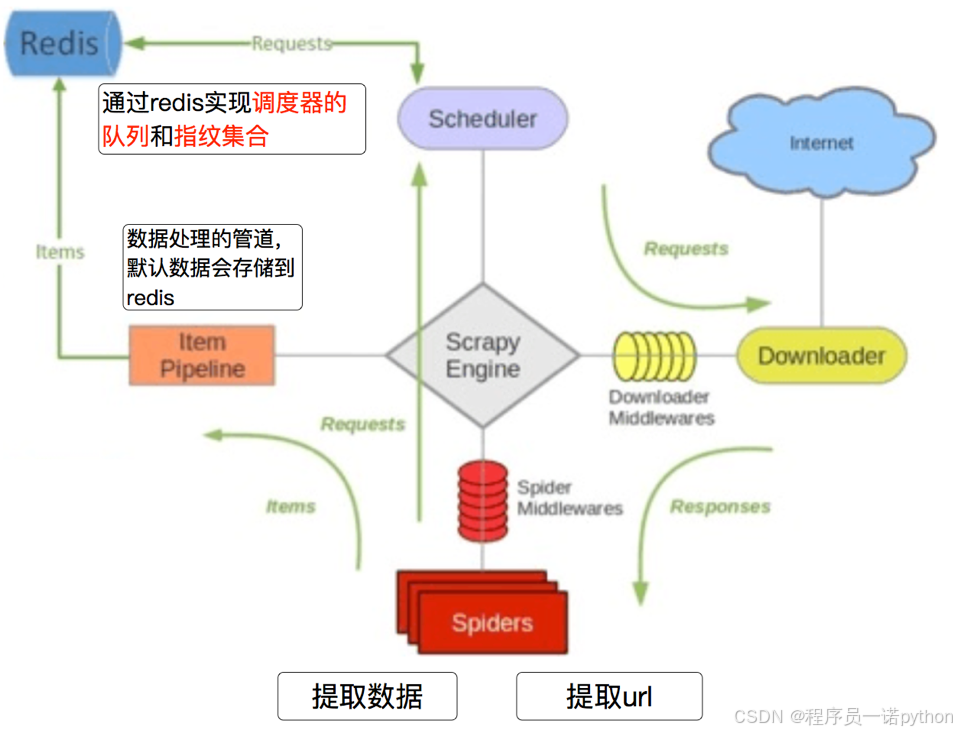
4.2 scrapy_redis的流程
-
在scrapy_redis中,所有的待抓取的request对象和去重的request对象指纹都存在所有的服务器公用的redis中
-
所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
-
所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
-
在默认情况下所有的数据会保存在redis中
具体流程如下:
小结
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的待抓取的对象和去重的指纹都存在公用的redis中
- 所有的服务器公用同一redis中的请求对象的队列
- 所有的request对象存入redis前,都会通过请求对象的指纹进行判断,之前是否已经存入过