目标检测是计算机视觉领域的重要研究方向,而YOLO(You Only Look Once)系列算法因其高效性和准确性成为该领域的代表性方法。YOLOv8作为YOLO系列的最新版本,在目标检测任务中表现出色。然而,传统的目标检测结果通常以边界框和类别标签的形式呈现,缺乏对模型决策过程的直观解释。热力图作为一种可视化工具,能够直观地展示模型在图像中的关注区域,为模型的可解释性提供了重要支持。本文将探讨基于YOLOv8的热力图生成与可视化方法,并支持自定义模型与置信度阈值的多维度分析。
1. YOLOv8与热力图生成技术概述
1.1 YOLOv8的核心特性
YOLOv8在YOLO系列的基础上进行了多项优化,包括:
- 更高效的网络结构:采用CSP(Cross Stage Partial)架构,提升特征提取能力。
- 更精确的检测性能:通过改进的损失函数和训练策略,提高目标检测的准确性。
- 更灵活的部署支持:支持多种硬件平台和推理框架,便于实际应用。
1.2 热力图生成的基本原理
热力图是一种通过颜色梯度表示数据分布的可视化方法。在目标检测中,热力图通常用于展示模型对图像中不同区域的关注程度。生成热力图的核心步骤包括:
- 特征提取:从YOLOv8的中间层提取特征图。
- 权重计算:根据模型的输出计算每个像素的权重。
- 可视化映射:将权重映射为颜色梯度,生成热力图。
2. 项目源代码
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
import torch, yaml, cv2, os, shutil
import numpy as np
np.random.seed(0)
import matplotlib.pyplot as plt
from tqdm import trange
from PIL import Image
from ultralytics.nn.tasks import DetectionModel as Model
from ultralytics.utils.torch_utils import intersect_dicts
from ultralytics.utils.ops import xywh2xyxy
from pytorch_grad_cam import GradCAMPlusPlus, GradCAM, XGradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image
from pytorch_grad_cam.activations_and_gradients import ActivationsAndGradients
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
class yolov8_heatmap:
def __init__(self, weight, cfg, device, method, layer, backward_type, conf_threshold, ratio):
device = torch.device(device)
ckpt = torch.load(weight)
model_names = ckpt['model'].names
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
model = Model(cfg, ch=3, nc=len(model_names)).to(device)
csd = intersect_dicts(csd, model.state_dict(), exclude=['anchor']) # intersect
model.load_state_dict(csd, strict=False) # load
model.eval()
print(f'Transferred {len(csd)}/{len(model.state_dict())} items')
target_layers = [eval(layer)]
method = eval(method)
colors = np.random.uniform(0, 255, size=(len(model_names), 3)).astype(np.int32)
self.__dict__.update(locals())
def post_process(self, result):
logits_ = result[:, 4:]
boxes_ = result[:, :4]
sorted, indices = torch.sort(logits_.max(1)[0], descending=True)
return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[indices[0]], xywh2xyxy(torch.transpose(boxes_[0], dim0=0, dim1=1)[indices[0]]).cpu().detach().numpy()
def draw_detections(self, box, color, name, img):
xmin, ymin, xmax, ymax = list(map(int, list(box)))
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), tuple(int(x) for x in color), 2)
cv2.putText(img, str(name), (xmin, ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.8, tuple(int(x) for x in color), 2, lineType=cv2.LINE_AA)
return img
def __call__(self, img_path, save_path):
# remove dir if exist
if os.path.exists(save_path):
shutil.rmtree(save_path)
# make dir if not exist
os.makedirs(save_path, exist_ok=True)
# img process
img = cv2.imread(img_path)
img = letterbox(img)[0]
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.float32(img) / 255.0
tensor = torch.from_numpy(np.transpose(img, axes=[2, 0, 1])).unsqueeze(0).to(self.device)
# init ActivationsAndGradients
grads = ActivationsAndGradients(self.model, self.target_layers, reshape_transform=None)
# get ActivationsAndResult
result = grads(tensor)
activations = grads.activations[0].cpu().detach().numpy()
# postprocess to yolo output
post_result, pre_post_boxes, post_boxes = self.post_process(result[0])
for i in trange(int(post_result.size(0) * self.ratio)):
if float(post_result[i].max()) < self.conf_threshold:
break
self.model.zero_grad()
# get max probability for this prediction
if self.backward_type == 'class' or self.backward_type == 'all':
score = post_result[i].max()
score.backward(retain_graph=True)
if self.backward_type == 'box' or self.backward_type == 'all':
for j in range(4):
score = pre_post_boxes[i, j]
score.backward(retain_graph=True)
# process heatmap
if self.backward_type == 'class':
gradients = grads.gradients[0]
elif self.backward_type == 'box':
gradients = grads.gradients[0] + grads.gradients[1] + grads.gradients[2] + grads.gradients[3]
else:
gradients = grads.gradients[0] + grads.gradients[1] + grads.gradients[2] + grads.gradients[3] + grads.gradients[4]
b, k, u, v = gradients.size()
weights = self.method.get_cam_weights(self.method, None, None, None, activations, gradients.detach().numpy())
weights = weights.reshape((b, k, 1, 1))
saliency_map = np.sum(weights * activations, axis=1)
saliency_map = np.squeeze(np.maximum(saliency_map, 0))
saliency_map = cv2.resize(saliency_map, (tensor.size(3), tensor.size(2)))
saliency_map_min, saliency_map_max = saliency_map.min(), saliency_map.max()
if (saliency_map_max - saliency_map_min) == 0:
continue
saliency_map = (saliency_map - saliency_map_min) / (saliency_map_max - saliency_map_min)
# add heatmap and box to image
cam_image = show_cam_on_image(img.copy(), saliency_map, use_rgb=True)
"不想在图片中绘画出边界框和置信度,注释下面的一行代码即可"
cam_image = self.draw_detections(post_boxes[i], self.colors[int(post_result[i, :].argmax())], f'{self.model_names[int(post_result[i, :].argmax())]} {float(post_result[i].max()):.2f}', cam_image)
cam_image = Image.fromarray(cam_image)
cam_image.save(f'{save_path}/{i}.png')
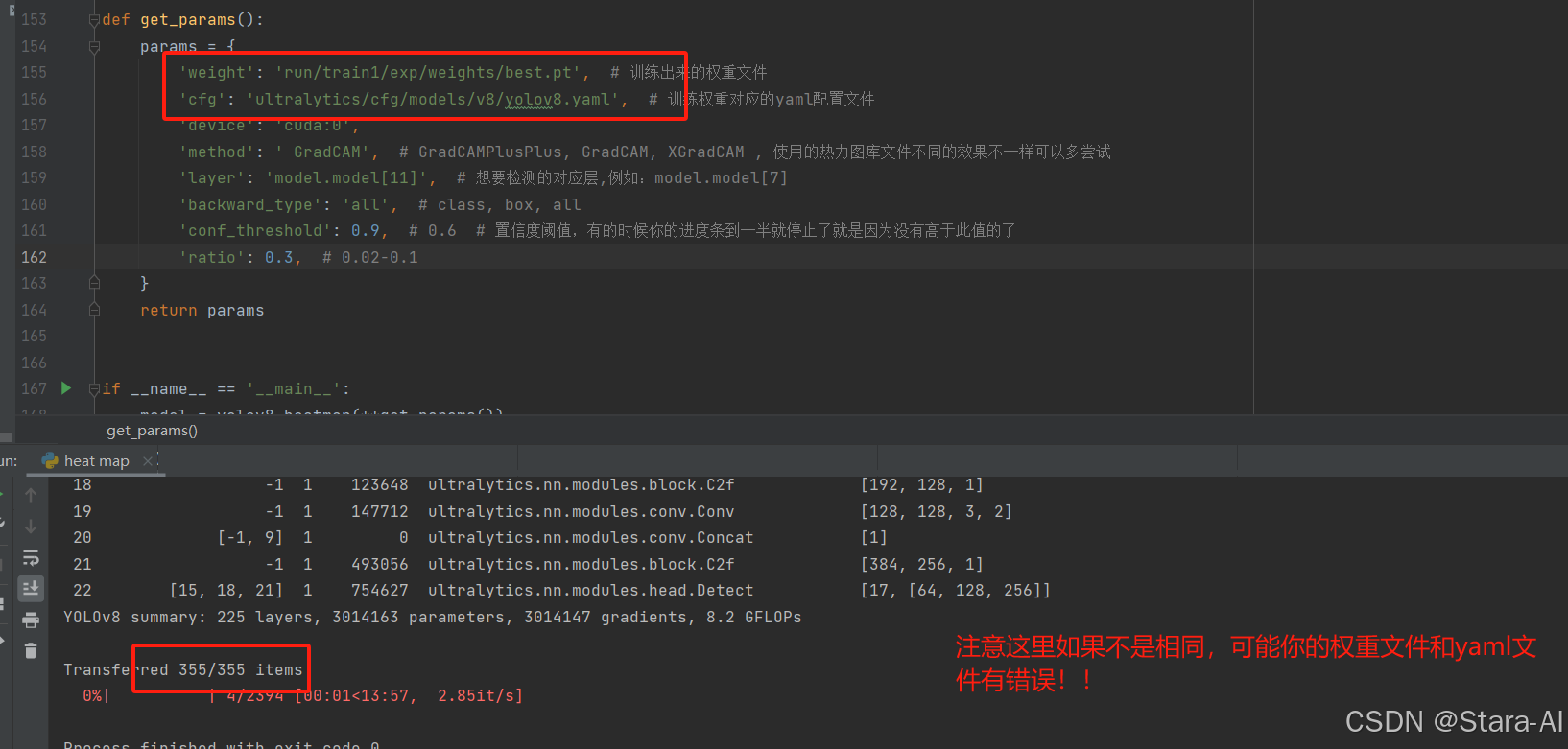
def get_params():
params = {
'weight': 'yolov8n.pt', # 训练出来的权重文件
'cfg': 'ultralytics/cfg/models/v8/yolov8n.yaml', # 训练权重对应的yaml配置文件
'device': 'cuda:0',
'method': 'GradCAM', # GradCAMPlusPlus, GradCAM, XGradCAM , 使用的热力图库文件不同的效果不一样可以多尝试
'layer': 'model.model[9]', # 想要检测的对应层
'backward_type': 'all', # class, box, all
'conf_threshold': 0.01, # 0.6 # 置信度阈值,有的时候你的进度条到一半就停止了就是因为没有高于此值的了
'ratio': 0.02 # 0.02-0.1
}
return params
if __name__ == '__main__':
model = yolov8_heatmap(**get_params())
model(r'ultralytics/assets/10.jpg', 'result') # 第一个是检测的文件, 第二个是保存的路径
| 参数名 | 参数类型 | 解释 |
|---|---|---|
| weight | str | 训练出来的权重文件路径,用于加载训练好的模型。 |
| cfg | str | 训练权重对应的YAML配置文件路径,定义了模型的结构和参数。 |
| device | str | 指定运行设备,例如 cuda:0 表示使用第一个GPU,cpu 表示使用CPU。 |
| method | str | 使用的热力图生成方法,例如 GradCAM、GradCAMPlusPlus、XGradCAM。 |
| layer | str | 想要检测的模型层,例如 model.model[11],表示检测第11层。 |
| backward_type | str | 反向传播类型,可选 class(类别)、box(边界框)、all(全部)。 |
| conf_threshold | float | 置信度阈值,过滤低于该值的检测结果,默认值为 0.9。 |
| ratio | float | 热力图与原图的叠加比例,取值范围为 0.02-0.1,默认值为 0.3。 |





![每日一题洛谷P8664 [蓝桥杯 2018 省 A] 付账问题c++](https://i-blog.csdnimg.cn/direct/a364218893964a4eb94fcf126534321f.jpeg)