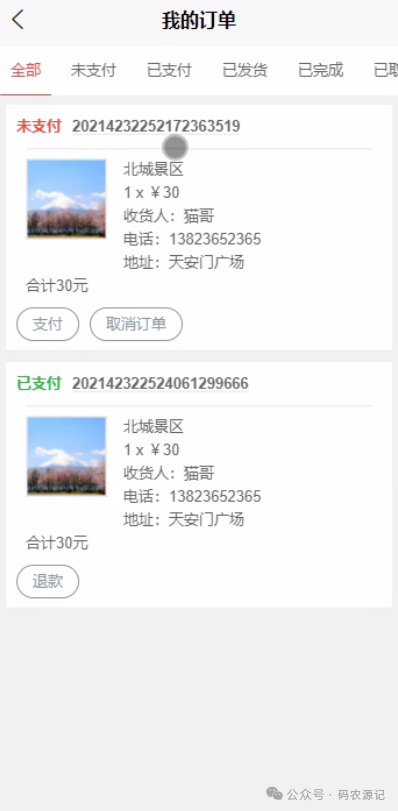
LangChain 是一个用于构建大语言模型(LLM)应用的框架,而向量数据库在 LangChain 中主要用于实现检索增强生成(RAG, Retrieval-Augmented Generation),即通过向量搜索从外部知识库中快速检索相关信息,辅助大模型生成更准确的回答。以下是具体的使用方法:
1. 核心流程
LangChain 使用向量数据库的典型流程分为四步:
- 加载文档 → 2. 文本分块 → 3. 向量化存储 → 4. 检索与生成
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS # 以FAISS为例
# 1. 加载文档
loader = TextLoader("data.txt")
documents = loader.load()
# 2. 文本分块(避免超出模型上下文长度)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# 3. 向量化并存储到数据库
embeddings = OpenAIEmbeddings() # 使用OpenAI的嵌入模型
vector_db = FAISS.from_documents