在数据驱动的时代,如何高效管理复杂的数据管道、确保数据质量并实现团队协作?本文深入探讨数据编排的核心概念,解析其与传统编排器的差异,并聚焦开源工具Dagster如何以“资产为中心”的理念革新数据开发流程,助力企业构建可观测、可扩展且易于维护的数据基础设施。
一、什么是数据编排器?
数据编排器(Orchestrator)是一种自动化工具,用于协调和管理复杂的工作流。它通过定义任务的执行顺序、依赖关系和资源分配,确保流程按计划运行。与传统IT编排器(如Airflow)不同,数据编排器专注于数据领域的特定需求:
- 跟踪数据血缘:记录数据从源头到最终产出的完整链路。
- 动态响应异常:自动识别失败节点并提供上下文诊断信息。
- 优化资源利用:根据数据规模和计算需求智能调度任务。
例如,一个典型的数据编排任务可能涉及从数据库提取数据、清洗后存入仓库、触发机器学习模型训练,并最终生成可视化报告。编排器在此过程中充当“指挥家”,确保每个环节无缝衔接。
二、数据编排器的核心价值
传统ETL(Extract, Transform, Load)工具往往关注单一任务执行,而数据编排器解决了三大关键挑战:
- 复杂性管理:当数据管道包含数十甚至上百个步骤时,人工维护极易出错。编排器通过可视化界面和代码声明机制简化流程设计。
- 数据一致性:自动检测数据更新状态,避免因上游延迟或代码变更导致的下游数据失效。
- 跨团队协作:非技术人员(如分析师)可通过血缘图理解数据来源,减少沟通成本。
举个实例:若某销售报表因数据源延迟未能按时生成,数据编排器不仅能发出警报,还可直接定位到延迟节点,并触发重试或告警通知。
三、为何选择Dagster?
Dagster是新一代数据编排工具,其独特的设计哲学彻底改变了数据管道的构建方式:

1. 以资产为中心的架构
Dagster摒弃传统的“任务导向”思维,转而围绕数据资产(如数据库表、API响应、模型文件)构建管道。每个资产均明确绑定以下信息:
- 生成逻辑:Python函数定义如何从输入生成输出。
- 依赖关系:资产间的上下游映射。
- 元数据:更新时间、负责人、质量指标等。
这种设计使得团队能够直观理解数据资产的生命周期,如图所示的DAG(有向无环图)可清晰展示资产间的依赖网络。
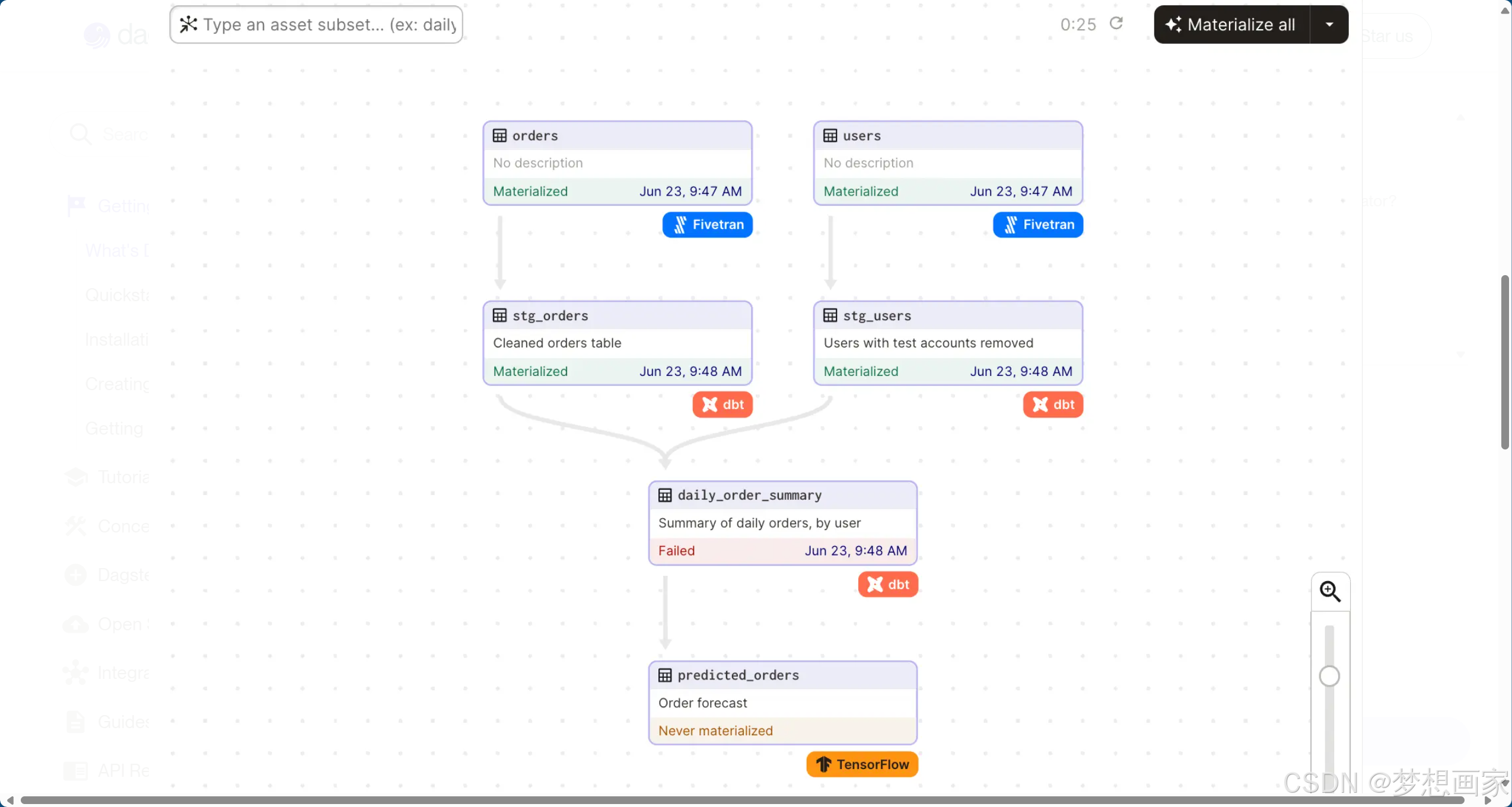
2. 内置可观测性
Dagster将关键能力直接融入开发流程:
- 自动质量检查:在管道中嵌入数据验证逻辑(如字段完整性校验),异常时即时阻断流程。
- 版本化调试:每次运行与生成资产关联,支持按资产回溯日志和输入数据。
- 环境一致性:从本地开发到生产部署,通过容器化确保代码行为一致。
3. 标准化协作实践
- 软件定义资产(SDA):统一抽象层让数据工程师与科学家使用相同接口,加速跨职能协作。
- 持续集成(CI)支持:通过预置测试框架,实现代码变更的自动化验证。
- 可视化监控:内置仪表盘提供实时运行状态、资产依赖图和性能指标,满足开发者与业务方的不同需求。
四、Dagster的应用场景
- 数据工程:管理ETL/ELT流程,确保数据仓库的时效性和准确性。
- 机器学习:跟踪模型训练数据版本,自动化特征工程管道。
- 实时分析:协调流处理任务,监控数据延迟和异常。
总结
在数据规模爆炸式增长的今天,Dagster通过“资产为中心”的创新架构,解决了传统编排工具的碎片化问题。其核心优势在于:
- 降低复杂性:以数据资产为单元,简化管道设计与维护。
- 增强可靠性:内置质量管控和调试工具,减少人为错误。
- 促进协作:统一视图打破团队壁垒,加速数据驱动决策。
无论是初创公司还是大型企业,Dagster都能为数据基础设施提供坚实底座,让团队专注于业务价值而非底层运维。随着数据成为核心资产,掌握Dagster等现代工具将成为数据从业者的必备技能。