之前讲解 Chrome 一大强势技术 override 时,给的案例貌似没有给大家留下多深的印象
浏览器本地替换(local overrides)快速定位前端样式问题的案例详解(也是hook js的手段)_浏览器的 overrides 替换功能-CSDN博客
其实这个超厉害的,任何一项小技术在 buffer 叠加的基础下才能发挥威力,若单单看到这一项技术,就局限了。
注意
实际测试时,最新版本的 Chrome 的 override 已经不好用了,原因未知,用的 360 极速浏览器搞得,不过神奇的时,Chrome 开启 override 公用极速浏览器的文件夹时,竟然也可以,后经排查,应该是谷歌浏览器的自动格式化问题导致,细节不深究。
结合 xhr 的监听
Chrome 浏览器是能监听到 XHR 请求的,一般我们逆向的突破点都在 XHR 这里,因为所谓的逆向就是为了捕捉传输过程中的数据,因为 Chrome 浏览器就帮我们解决了这个问题。
在 network 中监听 fetch/xhr 请求,发现每次点击页码时都是调用这个接口,于是我们以这个接口特征进行 xhr 断点
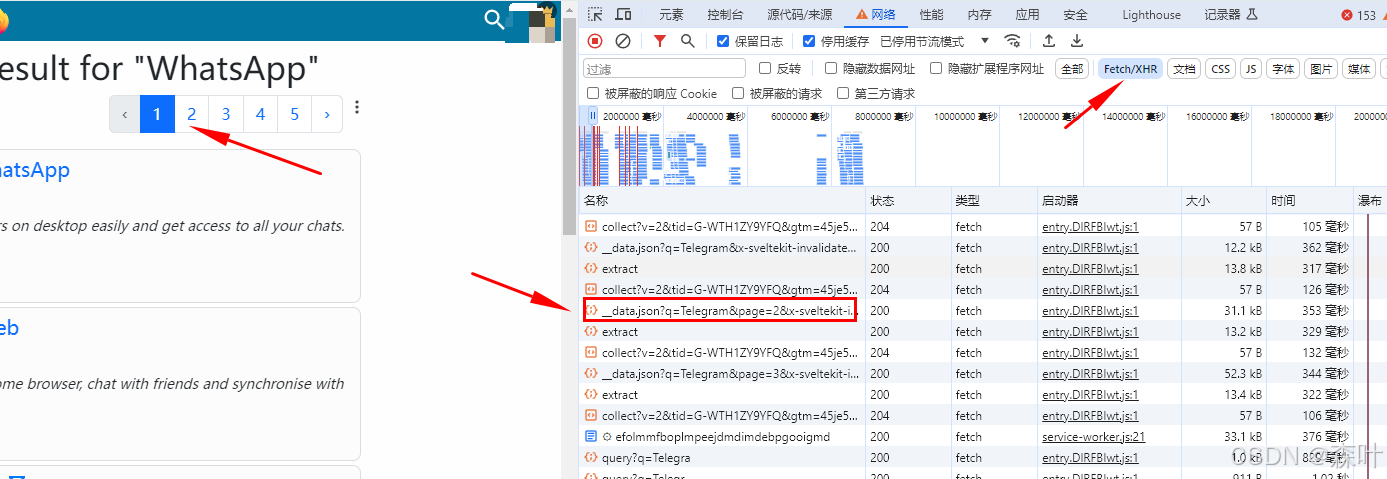
设置 xhr 断点
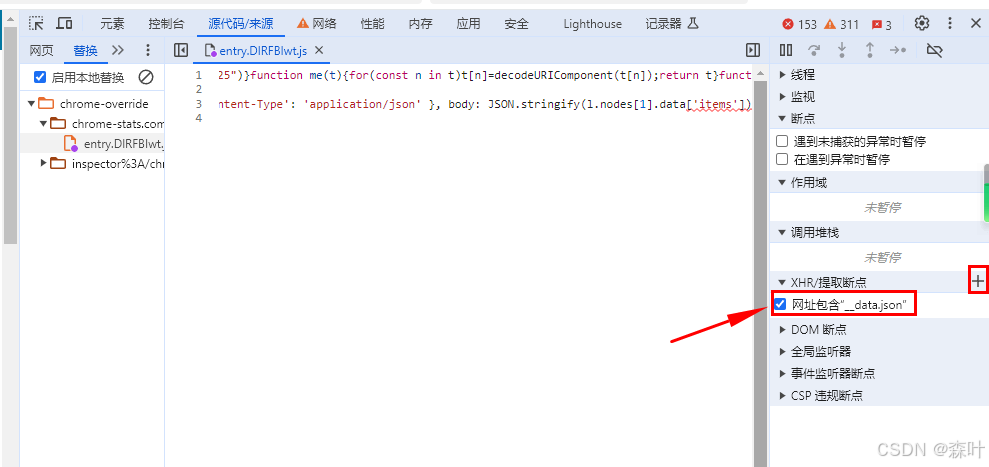
再次点击页码时,会停在一个位置
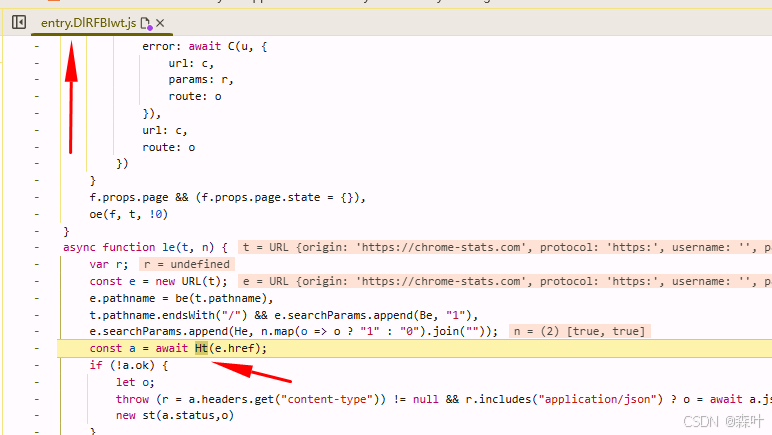
xhr 返回的数据是加密的
-
一般企业都会将信息进行加密,或者混淆,以避免这么简单就被你获取数据了,既然数据被加密,自然有解密函数,只要你耐心调试一下,往下游去找,定能找到被解密的数据结构,找到后,再对所有 js 进行回搜,就能快速定位解密函数,例如这里解密后,我们会发现数据结构中有个 nodes,且这个 nodes 是另外一个大对象里面的 key,那无非有两种赋值方式['nodes'] 或者 .nodes,我们搜搜后者,发现还在这个 js 文件中,那就没跑了

我们回到这个 js,再进行搜索,可以精确定位到这个数据的解析来源,把整个代码,让 grok 帮我们重新写一下,让我们理解得更彻底

grok 重写后的代码,完美重写的代码,一目了然,核心点就在 o(l),经过 grok 重写后,我们知道 o 就是 resolve,l 就是返回数据 parsedData
async function le(t, n) {
// 构造 URL
const e = new URL(t);
e.pathname = be(t.pathname);
if (t.pathname.endsWith("/")) {
e.searchParams.append(Be, "1");
}
e.searchParams.append(He, n.map(o => (o ? "1" : "0")).join(""));
// 发起 HTTP 请求
const a = await Ht(e.href);
if (!a.ok) {
const contentType = a.headers.get("content-type");
let errorMessage;
if (contentType?.includes("application/json")) {
errorMessage = await a.json();
} else if (a.status === 404) {
errorMessage = "Not Found";
} else if (a.status === 500) {
errorMessage = "Internal Error";
}
throw new st(a.status, errorMessage);
}
// 处理流式数据
return new Promise((resolve, reject) => {
const i = new Map();
const s = a.body.getReader();
const c = new TextDecoder();
// 自定义函数,用于处理数据转换
function f(g) {
return Me(g, {
Promise: d =>
new Promise((fulfil, reject) => {
i.set(d, { fulfil, reject });
}),
});
}
let buffer = "";
async function processStream() {
while (true) {
const { done, value } = await s.read();
if (done && !buffer) {
break;
}
buffer += value ? c.decode(value, { stream: true }) : "\n";
while (true) {
const lineEndIndex = buffer.indexOf("\n");
if (lineEndIndex === -1) {
break;
}
const line = buffer.slice(0, lineEndIndex);
buffer = buffer.slice(lineEndIndex + 1);
const parsedData = JSON.parse(line);
if (parsedData.type === "redirect") {
return resolve(parsedData); // 直接解析并返回
} else if (parsedData.type === "data") {
if (parsedData.nodes) {
parsedData.nodes.forEach(node => {
if (node?.type === "data") {
node.uses = fe(node.uses);
node.data = f(node.data);
}
});
}
resolve(parsedData); // 解析第一个 data 数据
return; // 避免多次 resolve
} else if (parsedData.type === "chunk") {
const { id, data, error } = parsedData;
const promiseHandler = i.get(id);
i.delete(id);
if (error) {
promiseHandler.reject(f(error));
} else {
promiseHandler.fulfil(f(data));
}
}
}
}
// 如果流结束且没有返回任何数据,可以选择 reject 或 resolve 一个默认值
reject(new Error("Stream ended without redirect or data"));
}
processStream().catch(reject);
});
}把这个 js 给 override 了,怎么 override,参考以前我写得链接吧,这里不赘述了

然后在 override 的文件里追加一个 fetch 代码,发到我们本地代码去
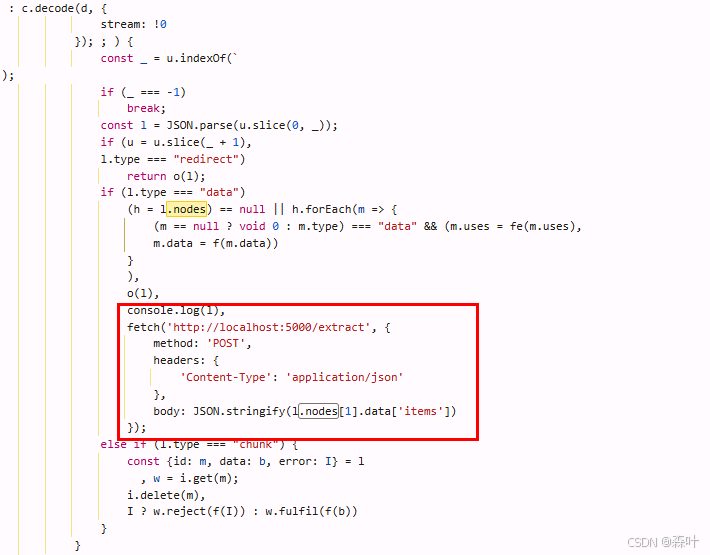
让 Grok 用 flask 写一个本地 http 协议的服务承接内容,并写到 excel 中去
-
注意 http 服务要允许跨域,因为发过来的 origin 是其他域名,不允许就会被拒绝
-
如果网页本身采用 CSP 的方式阻止浏览器发出跨域请求,不过 localhost 一般不会,若被拒绝,可以下载一个 CSP 扩展开启后就行了,这个可以重写 xhr 的 response headers
from flask import Flask, request, jsonify
from flask_cors import CORS
import openpyxl
from openpyxl import load_workbook
import os
app = Flask(__name__)
# 启用 CORS,允许所有来源访问
CORS(app)
# Excel 文件路径
EXCEL_FILE = 'WhatsApp.xlsx'
# 常驻缓存:存储已经写入的 id
ID_CACHE = set()
# 检查 Excel 文件是否存在,如果不存在则创建并添加表头
# 如果存在,则加载现有数据到缓存
if not os.path.exists(EXCEL_FILE):
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "Data"
headers = ["id", "name", "version", "description", "userCount", "lastUpdate", "email", "author", "ratingValue",
"ratingCount", "logo", "creationDate"]
ws.append(headers)
wb.save(EXCEL_FILE)
else:
# 加载 Excel 文件中的 id 到缓存
try:
wb = load_workbook(EXCEL_FILE)
ws = wb["Data"]
for row in ws.iter_rows(min_row=2, values_only=True): # 从第二行开始(跳过表头)
if row[0]: # 确保 id 不为空
ID_CACHE.add(row[0])
print(f"Loaded {len(ID_CACHE)} IDs into cache from {EXCEL_FILE}")
except Exception as e:
print(f"Error loading IDs from Excel: {e}")
# 定义一个 POST 路由来接收 JSON 数据
@app.route('/extract', methods=['POST'])
def extract_fields():
try:
# 获取请求中的 JSON 数据
data = request.get_json()
# 如果数据不是列表,直接转换为列表以统一处理
if not isinstance(data, list):
data = [data]
# 提取指定字段,并检查缓存
extracted_data = []
new_data_to_save = [] # 存储需要写入 Excel 的新数据
for item in data:
item_id = item.get("id")
if item_id in ID_CACHE:
# 如果 id 已存在,跳过写入,但仍返回该数据
extracted_item = {
"id": item_id,
"name": item.get("name"),
"version": item.get("version"),
"description": item.get("description"),
"userCount": item.get("userCount"),
"lastUpdate": item.get("lastUpdate"),
"email": item.get("email"),
"author": item.get("author"),
"ratingValue": item.get("ratingValue"),
"ratingCount": item.get("ratingCount"),
"logo": item.get("logo"),
"creationDate": item.get("creationDate")
}
extracted_data.append(extracted_item)
continue
# 如果 id 不存在,添加到缓存并准备写入 Excel
ID_CACHE.add(item_id)
extracted_item = {
"id": item_id,
"name": item.get("name"),
"version": item.get("version"),
"description": item.get("description"),
"userCount": item.get("userCount"),
"lastUpdate": item.get("lastUpdate"),
"email": item.get("email"),
"author": item.get("author"),
"ratingValue": item.get("ratingValue"),
"ratingCount": item.get("ratingCount"),
"logo": item.get("logo"),
"creationDate": item.get("creationDate")
}
extracted_data.append(extracted_item)
new_data_to_save.append(extracted_item)
# 将新数据保存到 Excel
if new_data_to_save: # 只有当有新数据时才写入 Excel
save_to_excel(new_data_to_save)
# 返回提取后的数据(包括已存在和新增的数据)
return jsonify(extracted_data), 200
except Exception as e:
return jsonify({"error": str(e)}), 400
# 函数:将数据保存到 Excel
def save_to_excel(data):
wb = load_workbook(EXCEL_FILE)
ws = wb["Data"]
for item in data:
row = [
item["id"],
item["name"],
item["version"],
item["description"],
item["userCount"],
item["lastUpdate"],
item["email"],
item["author"],
item["ratingValue"],
item["ratingCount"],
item["logo"],
item["creationDate"]
]
ws.append(row)
wb.save(EXCEL_FILE)
# 启动服务
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=False)
CSP 谷歌扩展
这玩意是啥?不懂就自行谷歌学习一下吧,给浏览器用的东西

跨域搞定后,数据就能发送过去了
network 记得勾选预留日志和关闭缓存,否则有些东西看不到,完美处理

后续
你想全自动化采集?那就自学个谷歌插件吧,或者用 python 的 puppeteer 来进行替换处理,所以的加解密,只要是网页端能被你眼睛看到的,基本都可以采用以上方式解决。