背景
maskrcnn用作实例分割时,可以较为精准的定位目标物体,相较于yolo只能定位物体的矩形框而言,优势更大。虽然yolo的计算速度更快。
直接开始从0到1使用maskrCNN训练自己的模型并并导出给C++部署(亲测可用)
数据标注
使用labelme标注

标注完生成后,包含标注的jeson文件,以及.jpg图片文件
模型训练
我这里的环境
PyTorch版本: 2.6.0+cu126
torchvision版本: 0.21.0+cu126
import os
import json
import numpy as np
import torchvision
from PIL import Image, ImageDraw
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.models.detection import maskrcnn_resnet50_fpn
import torchvision.transforms.functional as F
from tqdm import tqdm
# ===================== 数据集类 =====================
from torchvision import transforms
class LabelMeDataset(Dataset):
def __init__(self, image_dir, annotation_dir, transforms=None):
self.image_dir = image_dir
self.annotation_dir = annotation_dir
self.transforms = transforms or self.default_transforms()
# 获取所有 JSON 文件路径
self.json_files = [os.path.join(annotation_dir, f) for f in os.listdir(annotation_dir) if f.endswith(".json")]
@staticmethod
def default_transforms():
"""默认的图像转换"""
return transforms.Compose([
transforms.ToTensor() # 将 PIL.Image 转换为张量 (C, H, W),并归一化到 [0, 1]
])
def __len__(self):
"""返回数据集的长度"""
return len(self.json_files)
def _get_image_path(self, image_path):
"""
根据 JSON 文件中的 imagePath 构造图像的完整路径。
:param image_path: JSON 文件中的 imagePath 字段
:return: 规范化的完整图像路径
"""
# 拼接路径
full_path = os.path.join(self.image_dir, image_path)
# 规范化路径
return os.path.normpath(full_path)
def __getitem__(self, idx):
# 加载 JSON 文件
with open(self.json_files[idx], "r") as f:
data = json.load(f)
# 获取图像路径
img_path = self._get_image_path(data["imagePath"])
if not os.path.exists(img_path):
raise FileNotFoundError(f"Image file not found: {img_path}")
img = Image.open(img_path).convert("RGB")
# 解析标注信息(省略部分代码)
boxes = []
labels = []
masks = []
for shape in data["shapes"]:
label = shape["label"]
points = shape["points"]
# 验证 points 格式
if not isinstance(points, list) or len(points) < 3:
print(f"Invalid points for label '{label}': {points}")
continue
# 确保每个点是二维坐标
try:
points = [(float(p[0]), float(p[1])) for p in points]
except (TypeError, IndexError, ValueError) as e:
print(f"Error parsing points for label '{label}': {e}")
continue
# 转换多边形为掩码
mask_img = Image.new("L", (data["imageWidth"], data["imageHeight"]), 0)
ImageDraw.Draw(mask_img).polygon(points, outline=1, fill=1)
mask = np.array(mask_img)
# 计算边界框
pos = np.where(mask)
if len(pos[0]) == 0 or len(pos[1]) == 0:
print(f"No valid mask for label '{label}'")
continue
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
masks.append(mask)
# 将标签转换为整数
label_map = {"background": 0, "cat": 1, "dog": 2} # 自定义类别映射
labels = [label_map.get(label, 0) for label in labels] # 如果标签不存在,默认为背景
# 转换为张量
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
target = {
"boxes": boxes,
"labels": labels,
"masks": masks,
"image_id": torch.tensor([idx]),
"area": (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]),
"iscrowd": torch.zeros((len(boxes),), dtype=torch.int64)
}
# 应用图像转换
if self.transforms is not None:
img = self.transforms(img)
return img, target
# ===================== 训练函数 =====================
def train_model(model, train_loader, optimizer, device, num_epochs=10):
model.to(device)
model.train()
for epoch in range(num_epochs):
total_loss = 0
for images, targets in tqdm(train_loader):
# 将图像移动到 GPU
images = [img.to(device) for img in images]
# 将目标中的张量移动到 GPU
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# 前向传播
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
# 反向传播和优化
optimizer.zero_grad()
losses.backward()
optimizer.step()
total_loss += losses.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader)}")
# ===================== 主程序 =====================
if __name__ == "__main__":
# 定义路径
image_dir = "C:/workspace/dog_cat_dataset/label"
annotation_dir = "C:/workspace/dog_cat_dataset/label"
# 创建数据集和 DataLoader
dataset = LabelMeDataset(image_dir=image_dir, annotation_dir=annotation_dir)
train_loader = DataLoader(
dataset,
batch_size=2,
shuffle=True,
collate_fn=lambda batch: tuple(zip(*batch))
)
# 定义模型
num_classes = 3 # 背景 + 猫 + 狗
model = maskrcnn_resnet50_fpn(pretrained=True)
# 修改分类头以适应你的类别数
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 修改掩码头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(
in_features_mask, hidden_layer, num_classes
)
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)
# 设备配置
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 开始训练
train_model(model, train_loader, optimizer, device, num_epochs=10)
# 保存模型
torch.save(model.state_dict(), "maskrcnn_model.pth")
模型推理
import torch
import torchvision
from PIL import Image, ImageDraw
import torchvision.transforms as T
import matplotlib.pyplot as plt
from torchvision.models.detection import maskrcnn_resnet50_fpn
# ===================== 加载模型 =====================
def load_model(model_path, num_classes=3):
# 定义模型
model = maskrcnn_resnet50_fpn(pretrained=False)
# 修改分类头以适应你的类别数
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 修改掩码头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(
in_features_mask, hidden_layer, num_classes
)
# 加载权重
model.load_state_dict(torch.load(model_path))
model.eval() # 设置为评估模式
return model
# ===================== 预处理输入数据 =====================
def preprocess_image(image_path):
# 定义与训练时一致的预处理步骤
transform = T.Compose([
T.ToTensor() # 转换为 Tensor 并归一化到 [0, 1]
])
# 加载并预处理输入图像
image = Image.open(image_path).convert("RGB")
input_tensor = transform(image).unsqueeze(0) # 添加 batch 维度
return image, input_tensor
# ===================== 后处理输出结果 =====================
def visualize_predictions(image, predictions, threshold=0.5):
"""
可视化 Mask R-CNN 的预测结果。
:param image: PIL.Image 对象
:param predictions: 模型的输出
:param threshold: 置信度阈值
"""
# 获取预测结果
masks = predictions[0]['masks'].cpu().detach().numpy()
boxes = predictions[0]['boxes'].cpu().detach().numpy()
labels = predictions[0]['labels'].cpu().detach().numpy()
scores = predictions[0]['scores'].cpu().detach().numpy()
# 创建绘图对象
draw = ImageDraw.Draw(image)
for i in range(len(scores)):
if scores[i] > threshold:
# 绘制边界框
box = boxes[i]
draw.rectangle(box, outline="red", width=2)
# 绘制标签
label = "cat" if labels[i] == 1 else "dog"
draw.text((box[0], box[1]), f"{label} ({scores[i]:.2f})", fill="red")
# 绘制掩码
mask = (masks[i][0] > 0.5).astype(float) * 255
mask = Image.fromarray(mask).convert("L")
image.paste(Image.new("RGB", image.size, (255, 0, 0)), mask=mask)
# 显示图像
plt.imshow(image)
plt.axis("off")
plt.show()
# ===================== 主程序 =====================
if __name__ == "__main__":
# 加载模型
model_path = "maskrcnn_model.pth"
model = load_model(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 输入图像路径
image_path = "C:/workspace/dog_cat_dataset/test/cattest1.jpg"
# 预处理输入数据
image, input_tensor = preprocess_image(image_path)
input_tensor = input_tensor.to(device)
# 进行推理
with torch.no_grad():
predictions = model(input_tensor)
# 后处理输出结果
visualize_predictions(image, predictions)
模型导出
ONXX版本:
Name: onnx
Version: 1.17.0
import torch
import torchvision
import onnxruntime as ort
import numpy as np
# 定义模型
num_classes = 3 # 背景 + 猫 + 狗
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False)
# 修改分类头以适应你的类别数
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 修改掩码头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(
in_features_mask, hidden_layer, num_classes
)
# 加载模型权重
model.load_state_dict(torch.load("C:/workspace/maskrcnn_model.pth"))
# 设置为评估模式
model.eval()
# 假设输入图像大小为 (800, 800),通道数为 3
dummy_input = torch.randn(1, 3, 800, 800) # Batch size = 1, Channels = 3, Height = 800, Width = 800
# 导出为 ONNX 格式
torch.onnx.export(
model,
dummy_input,
"maskrcnn_model.onnx", # 输出文件名
opset_version=12, # ONNX 版本号,建议使用最新稳定版
input_names=["input"], # 输入名称
output_names=["boxes", "labels", "scores", "masks"], # 输出名称
dynamic_axes={
"input": {0: "batch_size"}, # 动态 batch size
"boxes": {0: "batch_size"},
"labels": {0: "batch_size"},
"scores": {0: "batch_size"},
"masks": {0: "batch_size"},
}
)
print("Model has been exported to ONNX format.")
# 加载 ONNX 模型
session = ort.InferenceSession("maskrcnn_model.onnx")
# 准备输入数据
dummy_input = np.random.randn(1, 3, 800, 800).astype(np.float32) # 匹配导出时的输入形状
# 获取输入输出名称
input_name = session.get_inputs()[0].name
output_names = [output.name for output in session.get_outputs()]
# 推理
outputs = session.run(output_names, {input_name: dummy_input})
# 打印输出
for name, output in zip(output_names, outputs):
print(f"{name}: {output.shape}")
C++推理
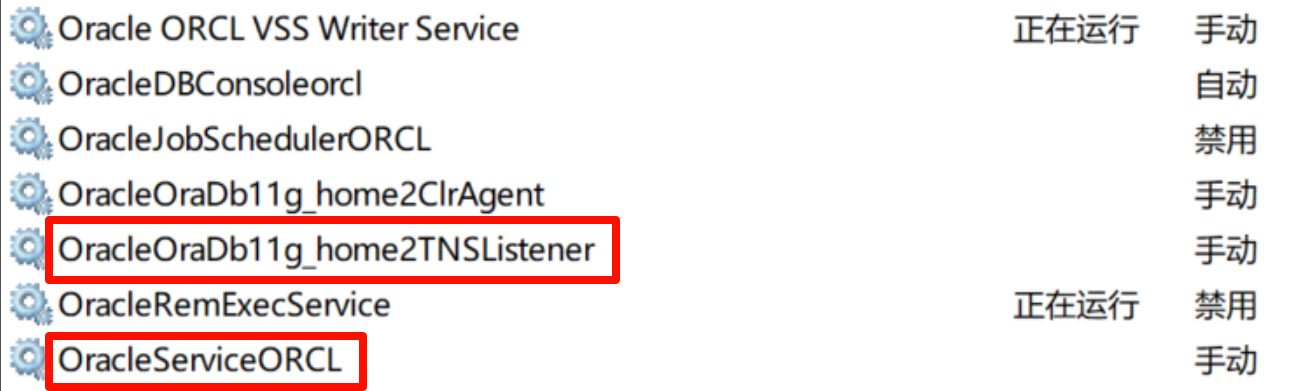
onnxruntime版本
onnxruntime-win-x64-gpu-1.20.0
//onxx推理
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
#include <string>
#include <Windows.h> // 使用 WinAPI 进行字符转换
using namespace std;
using namespace cv;
// 图像预处理函数
std::vector<float> preprocess_image(const cv::Mat& image, int target_height, int target_width) {
cv::Mat resized_image;
cv::resize(image, resized_image, cv::Size(target_width, target_height));
// 归一化到 [0, 1] 并转换为浮点数
resized_image.convertTo(resized_image, CV_32F, 1.0 / 255.0);
// 转换为 CHW 格式 (C=3, H=height, W=width)
std::vector<float> input_data(3 * target_height * target_width);
for (int c = 0; c < 3; ++c) {
for (int h = 0; h < target_height; ++h) {
for (int w = 0; w < target_width; ++w) {
input_data[c * target_height * target_width + h * target_width + w] =
resized_image.at<cv::Vec3f>(h, w)[c];
}
}
}
return input_data;
}
// 将 std::string 转换为 std::wstring
std::wstring string_to_wstring(const std::string& str) {
if (str.empty()) return L"";
int size_needed = MultiByteToWideChar(CP_UTF8, 0, &str[0], (int)str.size(), NULL, 0);
std::wstring wstr(size_needed, 0);
MultiByteToWideChar(CP_UTF8, 0, &str[0], (int)str.size(), &wstr[0], size_needed);
return wstr;
}
// 将 std::wstring 转换为 std::string
std::string wstring_to_string(const std::wstring& wstr) {
if (wstr.empty()) return "";
int size_needed = WideCharToMultiByte(CP_UTF8, 0, &wstr[0], (int)wstr.size(), NULL, 0, NULL, NULL);
std::string str(size_needed, 0);
WideCharToMultiByte(CP_UTF8, 0, &wstr[0], (int)wstr.size(), &str[0], size_needed, NULL, NULL);
return str;
}
int main() {
// 初始化 ONNX Runtime 环境
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "MaskRCNNExample");
Ort::SessionOptions session_options;
// 加载 ONNX 模型
//const char* model_path = "C:/workspace/yolov5/yolov5-master/yolov5-master/maskrcnn_model.onnx";
//Ort::Session session(env, model_path, session_options);
// 加载 ONNX 模型
std::string model_path = "C:/workspace/yolov5/yolov5-master/yolov5-master/maskrcnn_model.onnx";
std::wstring w_model_path = string_to_wstring(model_path); // Windows 平台需要宽字符
Ort::Session session(env, w_model_path.c_str(), session_options);
// 获取模型输入信息
Ort::AllocatorWithDefaultOptions allocator;
size_t num_input_nodes = session.GetInputCount();
Ort::AllocatedStringPtr input_name = session.GetInputNameAllocated(0, allocator);
const char* input_names[] = { input_name.get() };
std::vector<int64_t> input_dims = { 1, 3, 800, 800 }; // 假设输入尺寸为 (1, 3, 800, 800)
// 加载并预处理输入图像
cv::Mat image = cv::imread("C:/workspace/dog_cat_dataset/test/cattest1.jpg");
if (image.empty()) {
std::cerr << "Error: Could not load image!" << std::endl;
return -1;
}
std::vector<float> input_data = preprocess_image(image, 800, 800);
// 创建输入张量
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, input_data.data(), input_data.size(), input_dims.data(), input_dims.size());
// 推理
std::vector<const char*> output_names = { "boxes", "labels", "scores", "masks" };
auto output_tensors = session.Run(
Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names.data(), output_names.size());
// 处理输出
// 处理输出
float* boxes = output_tensors[0].GetTensorMutableData<float>();
int64_t* labels = output_tensors[1].GetTensorMutableData<int64_t>();
float* scores = output_tensors[2].GetTensorMutableData<float>();
float* masks = output_tensors[3].GetTensorMutableData<float>();
auto mask_shape = output_tensors[3].GetTensorTypeAndShapeInfo().GetShape();
int num_masks = mask_shape[0]; // 掩码数量
int mask_height = mask_shape[2]; // 掩码高度
int mask_width = mask_shape[3]; // 掩码宽度
// 缩放比例
float scale_x = static_cast<float>(image.cols) / 800.0f;
float scale_y = static_cast<float>(image.rows) / 800.0f;
cout << "image.cols , image.rows" << image.cols << image.rows<<endl;
// 绘制检测框和掩码
for (size_t i = 0; i < num_masks && scores[i] > 0.5; ++i) {
// 获取当前实例的边界框
cout << boxes[i * 4 + 0] << " " << boxes[i * 4 + 1] << " " << boxes[i * 4 + 2] << " " << boxes[i * 4 + 3];
float x1 = boxes[i * 4 + 0] * scale_x;
float y1 = boxes[i * 4 + 1] * scale_y;
float x2 = boxes[i * 4 + 2] * scale_x;
float y2 = boxes[i * 4 + 3] * scale_y;
cv::Rect box_rect(x1, y1, x2 - x1, y2 - y1);
cv::rectangle(image, box_rect, cv::Scalar(0, 255, 0), 2);
std::string label = "Class " + std::to_string(labels[i]) + " (" + std::to_string(scores[i]).substr(0, 4) + ")";
cv::putText(image, label, cv::Point(x1, y1 - 10), cv::FONT_HERSHEY_SIMPLEX, 0.9, cv::Scalar(0, 255, 0), 2);
// 获取当前掩码
cv::Mat mask(mask_height, mask_width, CV_32F, masks + i * mask_height * mask_width);
// 调整掩码尺寸以匹配原始图像
cv::Mat resized_mask;
cv::resize(mask, resized_mask, cv::Size(image.cols, image.rows));
cv::imshow("mask", resized_mask);
将掩码转换为二值图像
//cv::Mat binary_mask;
//cv::threshold(resized_mask, binary_mask, 0.5, 1, cv::THRESH_BINARY);
创建一个彩色掩码用于叠加
//cv::Mat color_mask = cv::Mat::zeros(image.size(), CV_8UC3);
//cv::randu(color_mask, cv::Scalar(0, 0, 0), cv::Scalar(255, 255, 255)); // 随机颜色
//cv::cvtColor(color_mask, color_mask, cv::COLOR_BGR2RGB);
将掩码应用到图像上
//cv::Mat masked_image;
//image.copyTo(masked_image, binary_mask);
//cv::addWeighted(masked_image, 0.5, image, 0.5, 0, image);
}
// 显示结果
cv::imshow("Image with Masks", image);
cv::waitKey(0);
return 0;
}

![Java单列集合[Collection]](https://i-blog.csdnimg.cn/direct/67a170692dd241ca9f3e1056a2d8c6ca.png)