什么是机器学习——多项式逼近
机器学习可以分成三大类别,监督学习、非监督学习、强化学习。三大类别背后的数学原理不同。监督学习使用了数学分析中的函数逼近方法和概率统计中的极大似然方法;非监督学习使用聚类和EM算法;强化学习使用马尔可夫决策过程的想法。
机器学习的本质就是寻找数据间的关联或者关系。
文章目录
- 什么是机器学习——多项式逼近
- 前言
- 一、什么是机器学习?
-
- 数学语言——叙述机器学习问题
- 二、多项式逼近函数
-
- 1.拉格朗日插值公式———Cramer法则
- 2.函数逼近——Cauchy矩阵
- 三、多项式Remez算法
-
- 1.最佳逼近函数
- 2. Remez 算法
- 参考文献
前言
数据间的关系直观上来说就两种:
一种是确定性的关系,如函数的对应关系;另一种是不确定的、带有一定概率意义上的或者统计上的关系,比如联合分布、条件分布等。
一、什么是机器学习?
虽然机器学习的深入研究需要用到高深的数学和计算机知识,但是机器学习的具体例子在我们平时的工作和学习中早已用到。
比如在下面这些二维数据中找出对应关系,并在问号处填上合适的数字。
上述都比较简单,但是有些问题就比较困难。例如,给定一个序列,根据前面几项,预测最后一个数字是多少。
数学语言——叙述机器学习问题
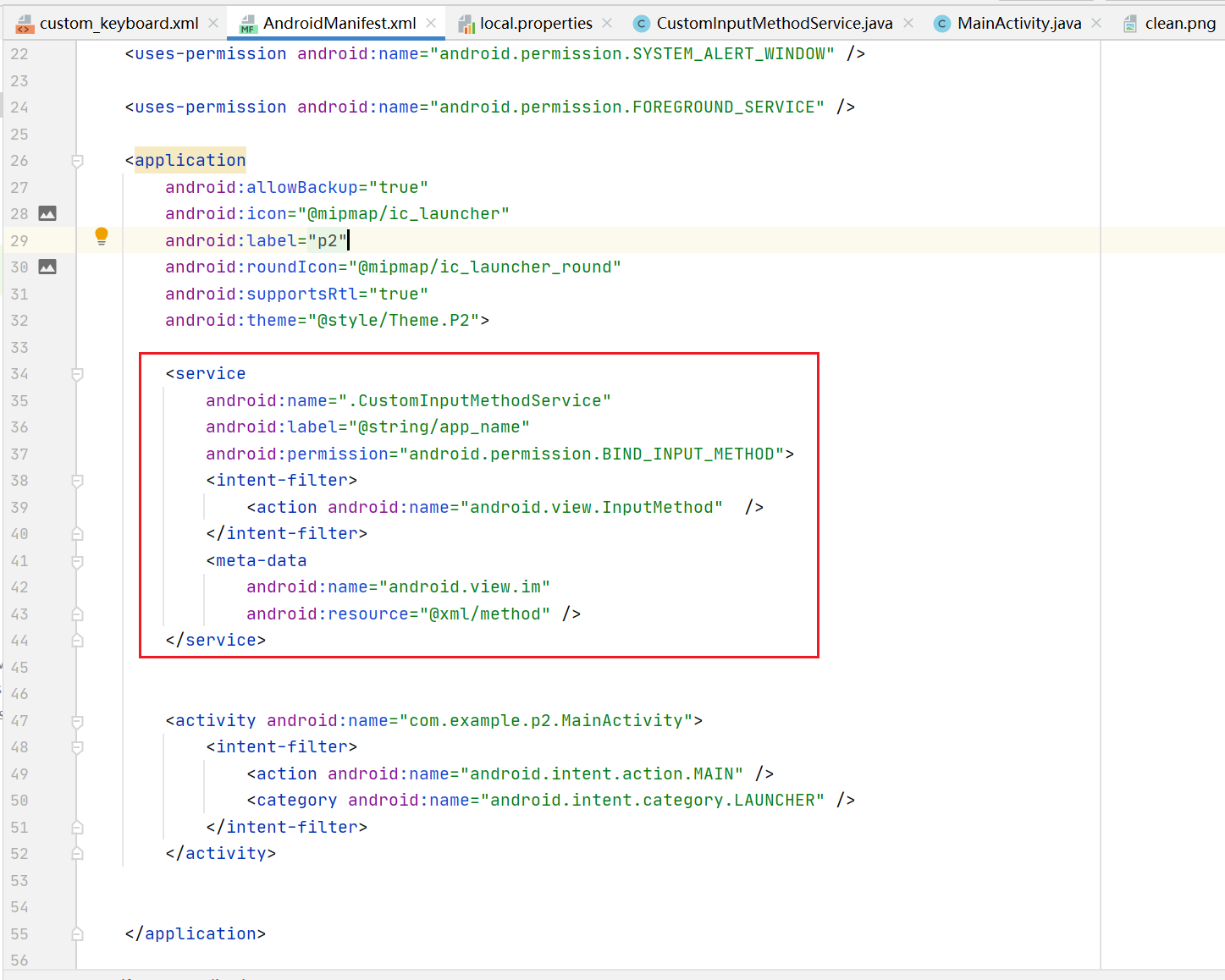
有两个集合 Ω \Omega Ω 和 A \mathrm{A} A,在它们之间有对应关系 f : Ω → A f: \Omega \rightarrow A f:Ω→A。这种对应关系我们称为函数,从而对于 x ∈ Ω x \in \Omega x∈Ω有唯一对应的 f ( x ) ∈ A f(x) \in A f(x)∈A,但是这个对应关系 f f f我们不知道。为此,我们能够接触到的是全集 Ω \Omega Ω上的一个子集 S ⊂ Ω S \subset \Omega S⊂Ω,同时每个 x ∈ S x \in S x∈S对应的 f ( x ) f(x) f(x)已知,即作为数据 { ( x , f ( x ) ) : x ∈ S } \begin{array}{l} \{(x, f(x)): x \in S\} \end{array} {(x,f(x)):x∈S} 是已知的,但是对应关系的算法描述我们是不知道的。我们需要通过这组数据(也称为样本数据)试图去寻找本源的对应关系,从而在全集 Ω \Omega Ω中任意给定一个新的 x ∈ Ω x \in \Omega x∈Ω,可以知道对应的 y = f ( x ) y=f(x) y=f(x)。上述使用函数的数学方法虽然结果令人满意,但是未必满足机器学习所有的问题形式。
下面考虑另外一个问题,一个袋子里有很多个球,一部分是红色的球,一部分是黑色的球。分别把球一个一个拿出来,看到颜色以后在放回去。例如,分别是红、红、黑、红、黑、黑、红、红。那么下一个拿出来的球应该是红色还是黑色呢?

这个问题就带着强烈的概率色彩。如果取球过程充分随机,绝对不可能因为取出来红色和黑色的球就断言所有球的颜色仅仅有红色和黑色,显然什么颜色的球都有可能出现,所以我们仅能在概率的意义上来问取到红色球和黑色球的概率分别是多少。
把这个概率问题用数学语言来叙述就是:两个随机变量 X , Y X,Y X,Y,它们的联合分布记为 p ( x , y ) p(x, y) p(x,y)。虽然联合分布没有给出具体形式,但是给出了有限个样本点集 ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x n , y n ) \begin{array}{l} ( x_1,y_1),( x_2,y_2 ),···,( x_n,y_n) \end{array} (x1,y1),(x2,y2),⋅⋅⋅,(xn,yn)我们需要从中学习到联合分布。一旦联合分布给出就很容易计算边缘分布 p ( x ) = ∫ R p ( x , y ) d y p ( y ) = ∫ R p ( x , y ) d x \begin{array}{l} p(x)=\int_{\mathbb{R}} p(x, y) \mathrm{d} y\\ p(y)=\int_{\mathbb{R}} p(x, y) \mathrm{d} x \end{array} p(x)=∫Rp(x,y)dyp(y)=∫Rp(x,y)dx以及对于任意一个 x x x,对应的是 y y y的条件分布 p ( y ∣ x ) = p ( x , y ) p ( x ) \begin{array}{l}p(y \mid x)=\frac{p(x, y)}{p(x)}\end{array} p(y∣x)=p(x)p(x,y)经过我们抽象出来的问题,无论是确定性问题还是统计性问题,都涉及学习和预测。学习过程可以看做从样本内找到一定关系;预测过程就是把学习到的关系使用在样本外。
二、多项式逼近函数
1.拉格朗日插值公式———Cramer法则
在基础的数学理论中,也可以找到非常明显的机器学习的影子,那就是函数逼近理论。本节将回顾这个理论并且从机器学习的角度来重新阐述一些重要的原则。已知有若干有限个一维实数空间的点和在这些点上的函数值,根据这些信息来预测这个函数在其他点的取值。这个传统的数学领域和机器学习的目标非常相似。下面我们用数学语言来精确描述问题。
给出直线上的一个区间 [ 0 , 1 ] [0,1] [0,1],有一个实值函数使得 f : [ 0 , 1 ] → R f:[0,1]→R f:[0,1]→R,但是我们不知道这个函数是什么形式。与此同时,给出 [ 0 , 1 ] [0,1] [0,1]区间上的一个离散点集
О < x 1 < x 2 < … < x n < 1 \begin{array}{l} О< x_1< x_2<…< x_n<1\end{array} О<x1<x2<…<xn<1
以及一组对应的函数值
y i = f ( x 1 ) , y 2 = f ( x 2 ) , … , y n = f ( x n ) \begin{array}{l} y_i=f(x_1),y_2=f(x_2),…,y_n=f(x_n)\end{array} yi=f(x1),y2=f(x2),…,yn=f(xn)我们试图通过这些有限数据推测出原来的函数关系。那么什么样的函数可以精确地给出这种对应关系呢?常见的可以选择多项式。根据多项式理论,任何一个 n − 1 n-1 n−1 次的多项式
g ( x ) = a n − 1 x n − 1 + a n − 2 x n − 2 + ⋯ + a 1 x + a 0 \begin{array}{l} g(x)=a_{n-1} x^{n-1}+a_{n-2} x^{n-2}+\cdots+a_{1} x+a_{0} \end{array} g(x)=an−1xn−1+an−2xn−2+⋯+a1x+a0使得能够满足对于任何 0 < i < n 0<i<n 0<i<n 有
g ( x i ) = y i \begin{array}{l} g(x_i)=y_i \end{array} g(xi)=yi这个问题就相当于求解一系列的关于多项式系数的线性方程
( 1 x 1 x 1 2 ⋯ x 1 n − 1 1 x 2 x 2 2 ⋯ x 2 n − 1 1 ⋯ ⋯ ⋯ ⋯ 1 x n x n 2 ⋯ x n n − 1 ) ( a 0 a 1 ⋯ a n − 1 ) = ( y 1 y 2 ⋯ y n ) \begin{array}{l} \left(\begin{array}{ccccc} 1 & x_{1} & x_{1}^{2} & \cdots & x_{1}^{n-1} \\ 1 & x_{2} & x_{2}^{2} & \cdots & x_{2}^{n-1} \\ 1 & \cdots & \cdots & \cdots & \cdots \\ 1 & x_{n} & x_{n}^{2} & \cdots & x_{n}^{n-1} \end{array}\right)\left(\begin{array}{c} a_{0} \\ a_{1} \\ \cdots \\ a_{n-1} \end{array}\right)=\left(\begin{array}{c} y_{1} \\ y_{2} \\ \cdots \\ y_{n} \end{array}\right) \end{array}
1111x1x2⋯xnx12x22⋯xn2⋯⋯⋯⋯x1n−1x2n−1⋯xnn−1
a0a1⋯an−1