欢迎来到啾啾的博客🐱,一个致力于构建完善的Java程序员知识体系的博客📚,记录学习的点滴,分享工作的思考、实用的技巧,偶尔分享一些杂谈💬。
欢迎评论交流,感谢您的阅读😄。
在上一篇服务通信 中我们已经了解到服务同步通信的选择,本篇继续探索服务通信的设计思想。
目录
- 引言
- 负载均衡
- 为设计算法获取信息
- 数据采集方式
- 设计流量分发算法
- 轮询
- 最小连接数
- 动态权重算法(响应时间加权)
- 为设计算法获取信息
- 总结
引言
在微服务架构中,服务通常以集群形式部署以实现高可用性和水平扩展能力。当其他服务需要调用某个服务集群时,一个关键问题随之产生:如何设计请求分发策略才能实现服务集群的最大吞吐量和最优性能?
若直接将请求固定发送至单个服务实例或简单映射,会导致以下问题:
-
负载不均:部分实例过载,其他实例闲置,资源利用率低下
-
单点故障风险:目标实例压力过大可能引发性能瓶颈甚至服务雪崩
-
架构优势浪费:集群的高可用性和弹性扩展能力无法有效发挥
解决这一问题的核心机制是负载均衡(Load Balancing)。其核心设计目标是通过智能分发请求流量至集群中的多个实例,实现以下关键收益:
-
资源最优化:充分利用集群整体计算能力,最大化吞吐量
-
性能均衡化:避免局部热点,确保请求响应延迟最优
有的资料将熔断、降级等机制放入负载均衡,本篇暂不做论述。
本篇讨论的都是客户端的负载均衡,即“从服务集群中寻找到一个合适的服务来调用”。
负载均衡
已知,负载均衡的核心设计目的是通过智能分发将请求流量均匀地分布到服务集群中,以实现服务集群的最大吞吐量,均衡服务器性能。
为此,我们需要做什么设计呢?
两步走,获取服务实例信息——>设计算法
为设计算法获取信息
在服务注册一篇中,有讲过服务实例的基本信息为:服务名、实例IP、端口,为了服务注册,注册中心一般会设计一些其他属性如:服务状态、权重、最后心跳时间、唯一ID、服务标签的等。
为了设计负载均衡,也需要设计并获取服务的一些属性。
以Ribbon的ServerStats为例,需要请求耗时、错误率、当前活跃请求数等
![![[Pasted image 20250324161358.png]]](https://i-blog.csdnimg.cn/direct/2feeeb2030f44360a9df25de2035636d.png)
| 负载均衡算法 | 依赖的关键信息 | 决策逻辑 |
|---|---|---|
| 轮询 | 实例列表 | 简单轮转选择 |
| 加权轮询 | 静态权重 + 健康状态 | 按权重比例分配 |
| 最小连接数 | 实时活跃连接数 | 选择当前负载最轻实例 |
| 一致性哈希 | 实例标识 + 请求特征(如用户ID) | 哈希值固定映射 |
| 区域感知 | 实例区域标签 + 网络延迟 | 优先选择同区域低延迟实例 |
数据采集方式
数据采集有主动探测模式、被动上报模式,以及混合模式。
设计流量分发算法
为了避免单点过载,通过算法(如轮询、随机、权重等)将请求均匀分布到多个实例,这里均匀的可以是次数,也可以是响应时间,最终目的都是最大吞吐量。
一些典型的负载均衡算法与设计如下:
| 算法 | 设计原理 | 适用场景 |
|---|---|---|
| 轮询(Round Robin) | 按顺序依次分配请求,保证绝对均衡 | 实例性能相近的集群 |
| 加权轮询/随机 | 根据实例配置(CPU、内存)分配权重,高性能实例接收更多请求 | 异构硬件环境 |
| 最小连接数 | 动态选择当前连接数最少的实例,避免过载 | 长连接或处理时间差异大的服务 |
| 一致性哈希 | 对请求特征(如用户ID)哈希计算,固定映射到特定实例,减少缓存失效 | 分布式缓存、会话保持场景 |
| 区域感知(Zone-Aware) | 优先选择同一区域的实例,降低跨区域网络延迟 | 多数据中心部署 |
轮询
最常见的负载均衡算法,通过顺序分配请求实现绝对均衡。
核心机制是通用循环索引选择目标实例,确保每个实例获得均等的请求量。
以Ribbon框架为例,其轮询实现(RoundRobinRule)大致如下:
public class RoundRobinRule extends AbstractLoadBalancerRule {
private AtomicInteger nextServerCyclicCounter;
public RoundRobinRule() {
nextServerCyclicCounter = new AtomicInteger(0);
}
public Server choose(ILoadBalancer lb, Object key) {
// 获取可用服务列表
List<Server> allServers = lb.getAllServers();
int serverCount = allServers.size();
// 计算下一个索引(线程安全)
int nextIndex = incrementAndGetModulo(serverCount);
return allServers.get(nextIndex);
}
private int incrementAndGetModulo(int modulo) {
// 无线循环获取下一个值
for (;;) {
//获取当前索引
int current = nextServerCyclicCounter.get();
// +1取模
int next = (current + 1) % modulo;
// 更新AtomicInteger值
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
}
- 使用
AtomicInteger保证索引更新的原子性,避免并发问题。 - 通过取模运算实现循环逻辑,索引超出范围时重置为0。
详细源码则如下:
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
// 重试不超过10次
while (server == null && count++ < 10) {
// getReachableServers返回一个不可修改的List,List为从可达服务列表
List<Server> reachableServers = lb.getReachableServers();
// 获取所有服务器列表
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
// 服务器不可用
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
// 计算下一个服务器索引
int nextServerIndex = incrementAndGetModulo(serverCount);
// 从服务列表获取服务
server = allServers.get(nextServerIndex);
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
// Next.
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
对Ribbon怎么获取服务感兴趣的可以评论留言。
最小连接数
最小连接数的设计思想为动态选择当前连接数最少的实例,避免过载。需实时监控实例负载状态,适合处理时间差异大的长连接场景。
设计实现需要维护每个实例的活跃连接数计数器,选择计数器值最小的实例处理新请求。
感觉适合AI应用,AI给出结果的时间都比较长且长短不一。
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 服务实例对象(记录连接数)
* 这个代码demo存在当所有服务连接数都一样时都访问到同一实例的情况,可以通过锁与随机值来解决,这里没有实现
*/
class AIServer {
private final String endpoint; // 实例地址(如 "http://ai-node1:5000")
private final AtomicInteger activeConnections = new AtomicInteger(0); // 当前活跃连接数
public AIServer(String endpoint) {
this.endpoint = endpoint;
}
// 获取当前活跃连接数(线程安全)
public int getActiveConnections() {
return activeConnections.get();
}
// 增加连接数(请求开始时调用)
public void incrementConnections() {
activeConnections.incrementAndGet();
}
// 减少连接数(请求结束时调用)
public void decrementConnections() {
activeConnections.decrementAndGet();
}
public String getEndpoint() {
return endpoint;
}
}
/**
* 最小连接数负载均衡器
*/
public class LeastConnectionsLoadBalancer {
private final List<AIServer> servers;
public LeastConnectionsLoadBalancer(List<AIServer> servers) {
this.servers = servers;
}
/**
* 选择当前连接数最少的可用实例
*/
public AIServer selectServer() {
AIServer selected = null;
int minConnections = Integer.MAX_VALUE;
// 遍历所有实例,寻找最小连接数的节点
for (AIServer server : servers) {
int current = server.getActiveConnections();
if (current < minConnections) {
minConnections = current;
selected = server;
}
}
System.out.println("Thread:"+ Thread.currentThread().getName()+",Selected server: " + selected.getEndpoint() + " ,connections : "+ selected.getActiveConnections());
return selected;
}
/**
* 示例:执行AI任务(自动管理连接数)
*/
public void executeAITask(String input) {
AIServer targetServer = selectServer();
if (targetServer == null) {
throw new IllegalStateException("No available AI servers");
}
try {
targetServer.incrementConnections(); // 增加连接计数
// 模拟调用AI服务(实际替换为HTTP/gRPC调用)
System.out.println("Thread:"+ Thread.currentThread().getName()+",Processing input on " + targetServer.getEndpoint());
// 这里执行实际的AI推理逻辑...
Thread.sleep(1000); // 模拟长时任务
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
targetServer.decrementConnections(); // 确保连接计数释放
}
}
// 测试用例
public static void main(String[] args) {
List<AIServer> servers = Arrays.asList(
new AIServer("http://ai-node1:5000"),
new AIServer("http://ai-node2:5000"),
new AIServer("http://ai-node3:5000")
);
LeastConnectionsLoadBalancer lb = new LeastConnectionsLoadBalancer(servers);
// 模拟并发请求
for (int i = 0; i < 10; i++) {
new Thread(() -> lb.executeAITask("test input")).start();
}
}
}
### 动态权重算法(响应时间加权)
根据实时指标(如响应时间、CPU负载)动态调整权重,高性能实例自动获得更高优先级。Ribbon的 WeightedResponseTimeRule 是其典型实现。
public class WeightedResponseTimeRule extends RoundRobinRule {
private volatile List<Double> accumulatedWeights;
public Server choose(ILoadBalancer lb, Object key) {
// 根据响应时间计算权重
List<Double> weights = calculateWeights();
double maxWeight = weights.get(weights.size() - 1);
double randomWeight = random.nextDouble() * maxWeight;
// 选择匹配的权重区间
for (int i = 0; i < weights.size(); i++) {
if (randomWeight < weights.get(i)) {
return servers.get(i);
}
}
return null;
}
}
-
定期统计各实例的平均响应时间,响应越快权重越高。
-
通过权重区间随机选择实例,实现动态负载分配
总结
集合常用框架,负载均衡算法选型如下:
| 算法 | 依赖信息 | 适用场景 | 框架案例 |
|---|---|---|---|
| 轮询 | 实例列表 | 同构集群、简单请求分发 | Ribbon RoundRobinRule |
| 加权轮询 | 静态权重 + 健康状态 | 异构集群、静态权重分配 | Nginx、华为云SLB |
| 源地址哈希 | 客户端的源IP地址、后端服务器列表 | 会话保持、缓存亲和性 | Spring Cloud HashRule |
| 最小连接数 | 实时活跃连接数 | 长连接、处理时间差异大 | HAProxy、Envoy |
| 动态响应时间加权 | 服务器的响应时间、服务器的权重、健康状态 | 实时性能敏感型系统 | Ribbon WeightedResponseTimeRule |
| 一致性哈希 | 实例标识 + 请求特征(如用户ID) | 分布式缓存、避免雪崩 | gRPC、Redis Cluster |
需要流量分发的场景一般都需要负载均衡,其核心是算法,目的是使得集群吞吐量最大化、性能最佳。




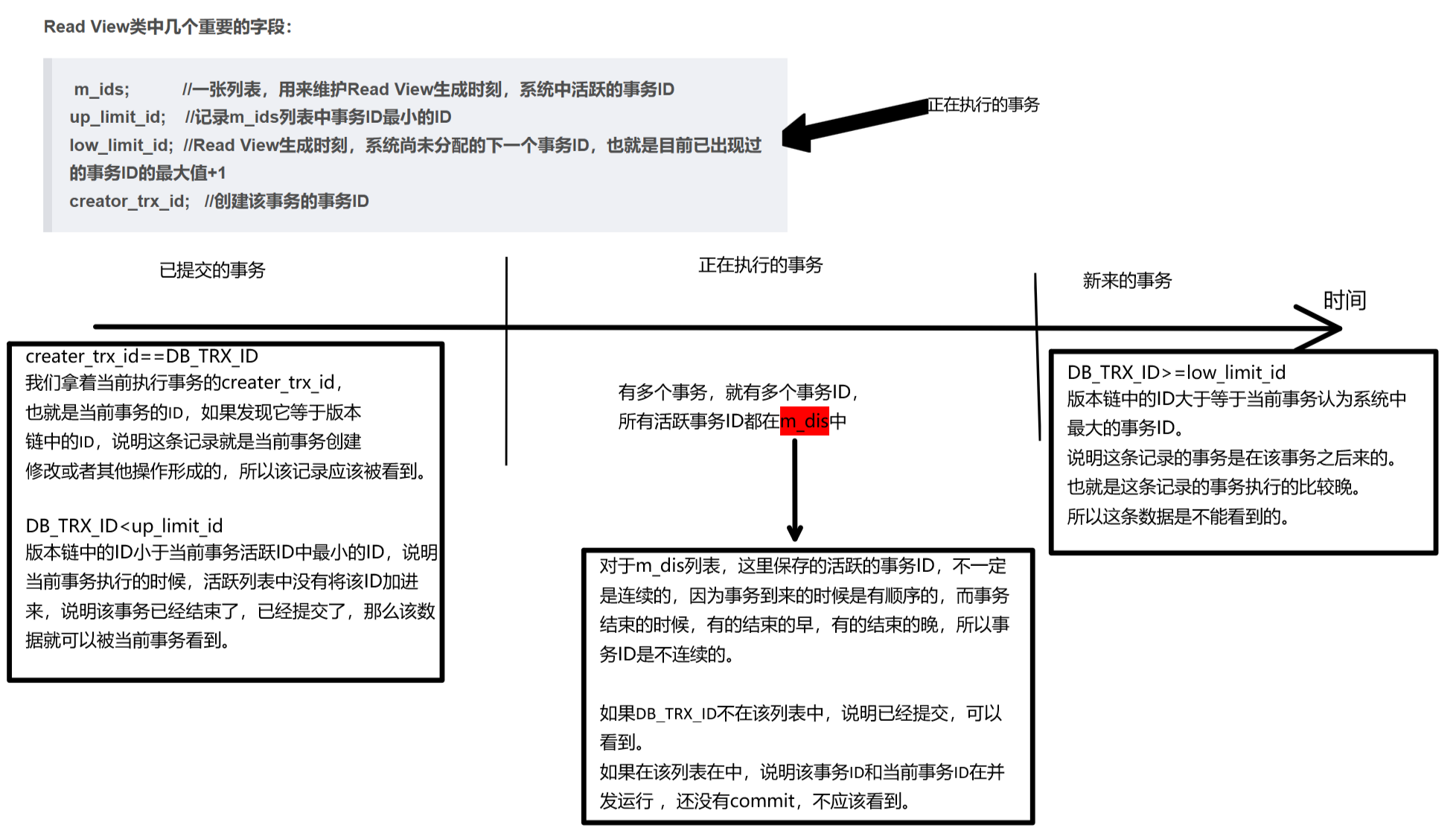







![[ C语言 ] | 从0到1?](https://i-blog.csdnimg.cn/direct/13d60a32caec4649aefe75c708efe0ca.png)
![[Mac]利用Hexo+Github Pages搭建个人博客](https://i-blog.csdnimg.cn/direct/4cd015aa99d0421f8087b872b9ea6170.png)





