一.模板初阶
1.泛型编程

以往我们要交换不同类型的两个数据就要写不同类型的交换函数,这是使用函数重载虽然可以实现,但是有以下几个不好的地方:
1.重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数。
2.代码的可维护性比较低,一个出错可能导致所有的重载均出错。
此时就引出了模板这个概念,就是告诉编译器一个模子,让编译器根据不同类型利用该模子来生成代码。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2.函数模板
2.1函数模板概念
函数模板代表了一个函数家族,该函数与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
2.2函数模板格式
template<typename T1,typename T2...typename Tn>
返回值类型 函数名(参数列表){}
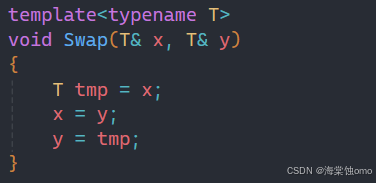

这样就完成了一个简单的交换函数模板,其中的typename可以换成class,不影响使用。
2.3函数模板的原理
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具,所以其实模板就是将本来我们做的重复的事情交给了编译器。
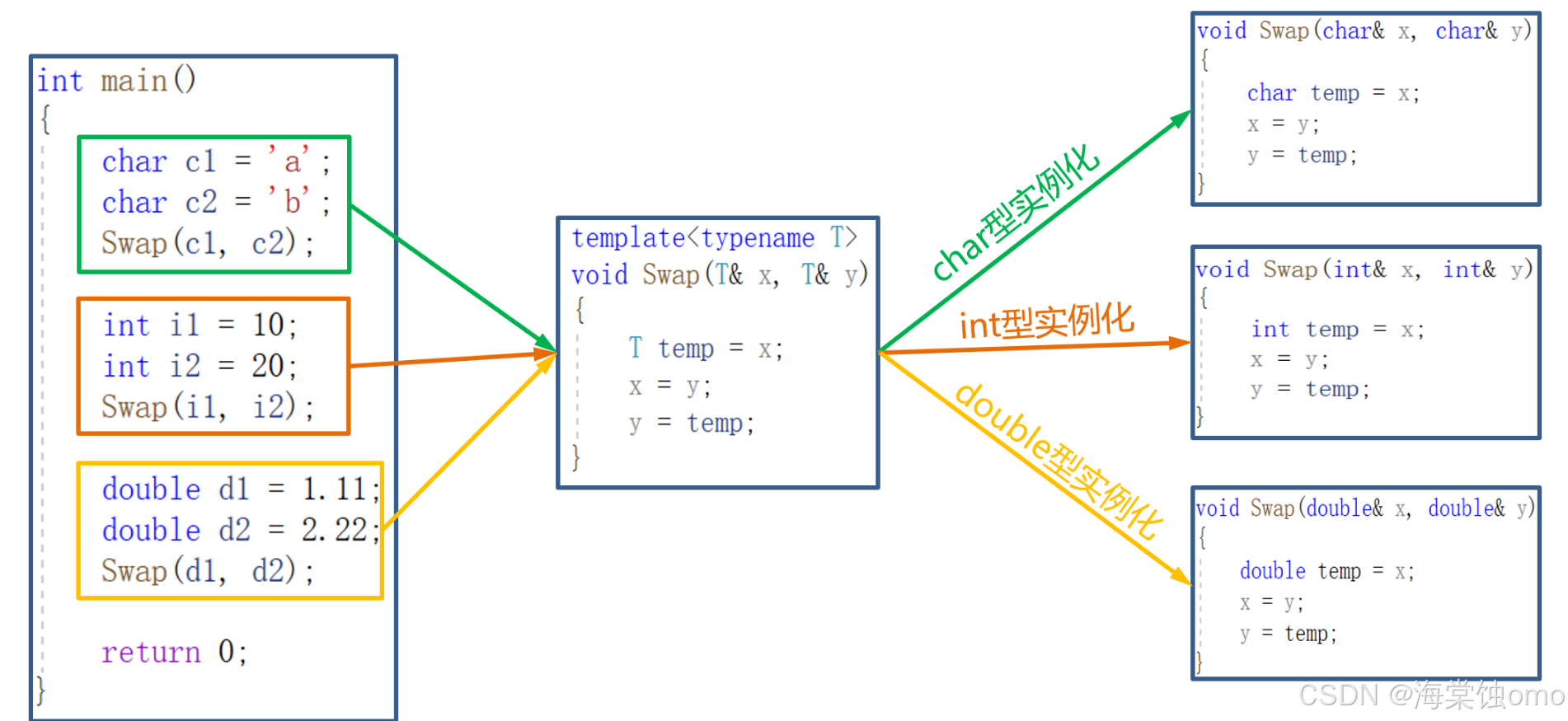
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
2.4函数模板的实例化
用不同类型的函数使用函数模板时,成为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
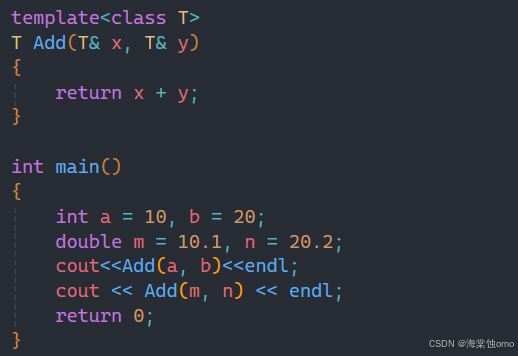
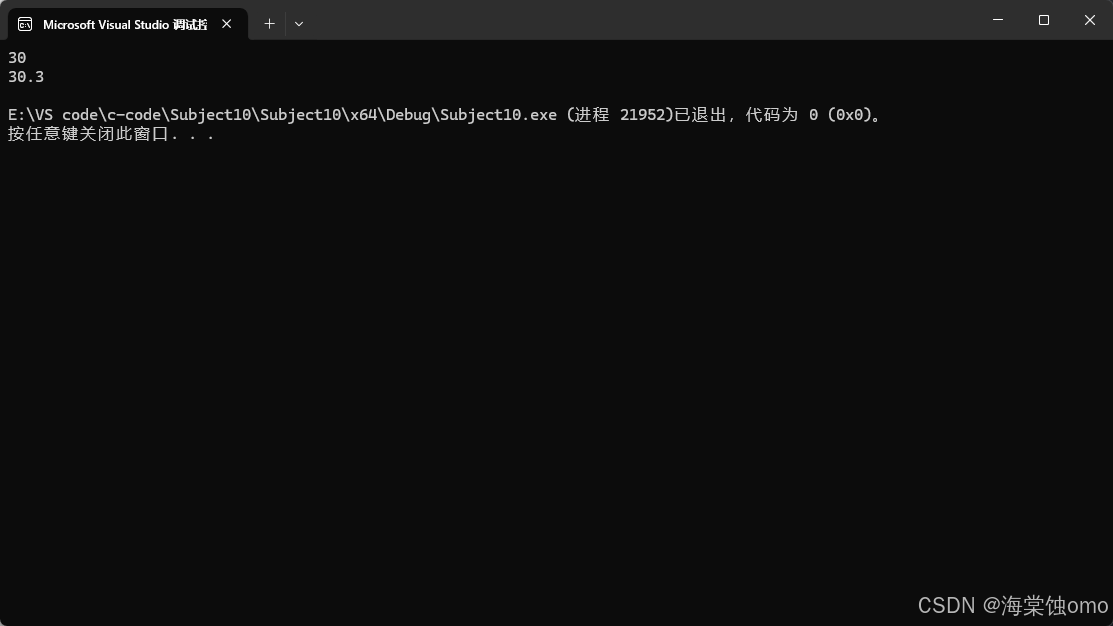
此时就可以使用隐式实例化,但是在实例化中会遇到其他特别的情况:
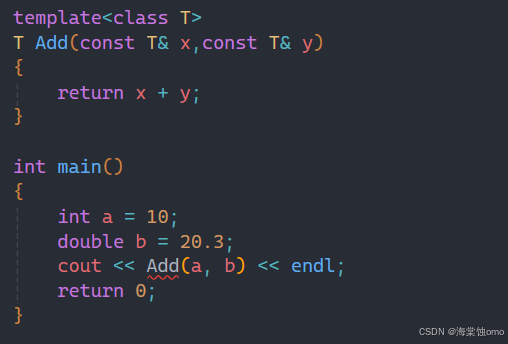
比如这样,传过去的参数类型不同,编译器就会不知道到底返回什么类型,就会报错。
这时就需要用到显式实例化。

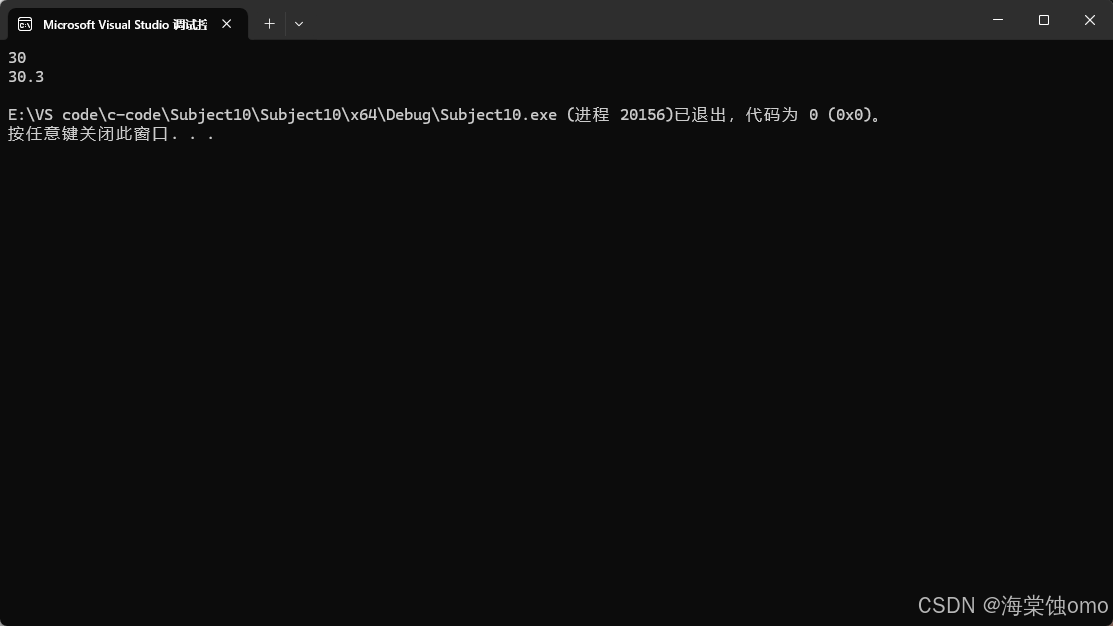
显式实例化就是在函数名后面用<指定类型>就是指定当前这个函数的返回值是什么类型。
再比如:

参数中T并没有作为参数,此时单独调用这个函数就会报错,就不知道T的类型是什么。
可能有人会说用一个变量来接收函数返回值不就行了,那我要就不接受呢?
此时也是必须用显式实例化的:
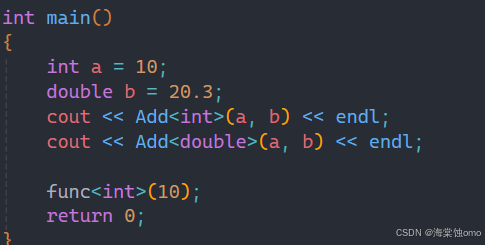
2.5模板参数的匹配原则
1.一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
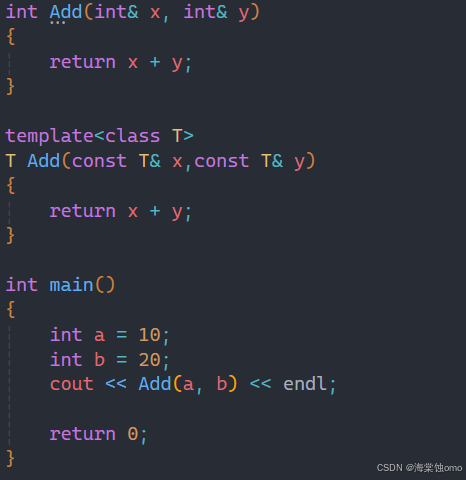
如上面这种情况,如果有一个专门处理int类型的加法函数和一个加法函数模板,此时调用加法函数会调用哪个呢?
此时就会遵从有现成的用现成的,也就是会调用专门处理int类型的加法函数。
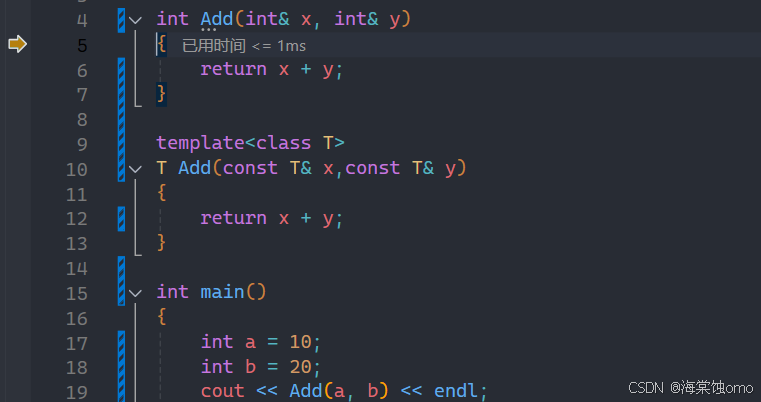
经过调试也可以发现调用的是现成的加法函数。
2.对于非模板函数和同名函数模板,如果其他条件都相同,在调用时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数,那么将选择模板。
后半句话用下面这个例子来解释:

如果我们传不同的参数,此时就会报错,其实就是因为编译器现在要调用模板,但是参数不同,所以才报错。

此时用显式实例化就可以解决问题。
3.函数模板不允许自动类型转换,但普通函数可以进行自动类型转换
3.类模板
3.1类模板的定义格式
template<class T1,class T2...class Tn>
class 类模板名
{
//类内成员定义
};
3.2类模板的实例化
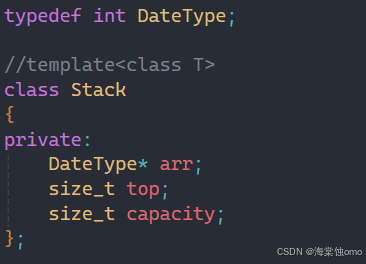
拿之前学过的Stack类举例,在这个例子中可能有人会觉得为什么非得用模板,直接用typedef不就行了吗?
如果只用一个Stack,那确实不需要用模板,但如果我的程序需要两个Stack呢,并且两个Stack的类型不一样,此时用typedef就解决不了这个问题,此时就需要用到模板。
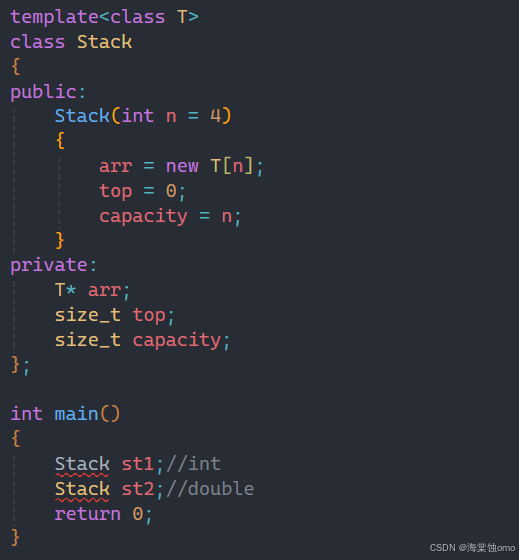
此时就用创建了一个类模板,但为什么下面实例化会出错呢?
答案是因为类模板不能根据构造函数来推导出T的类型。
所以类模板基本都是显式实例化:
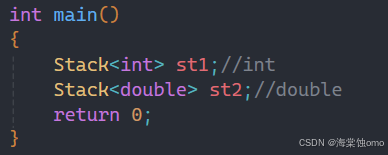
这样才能确定T的类型。

如果要做声明与定义分离,是需要重新写一个模板的,上面那个模板只是Stack类的,下面要再用的话需要重新写一个。
另外类模板不支持声明和定义在不同的文件中,会报链接错误。
二.string类
1.为什么要学string类?
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C++标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合0OP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
2.标准库中的sring类
在使用string类时,必须包含string头文件和using namespace std;
2.1string的构造函数
string底层其实就是一个char类型的顺序表,就是一个数组。
![]()
第一种构造的方式就是可以创建一个空字符串。
![]()
第二种就是在括号内直接接收一个字符串进行初始化。
![]()
当然也可以以这种方式进行初始化。
![]()
如果使用引用的话这样写是不行的,因为这种方式其实就相当于单参数隐式类型转换,而类型转换就会产生临时对象,临时对象具有常性,不能被修改,而引用会导致权限被放大,使其能够被修改,所以此时程序会报错。

此时加上const就可以解决问题,因为加上const后权限就相等了。
![]()
上面这种方式是最能体现string类底层是数组的,把10个*放入其中进行初始化,这种方式也是支持的。
还有几种不怎么常用的构造函数:

这种方法中有三个参数,第一个就是你要指定的字符串,第二个参数就是从哪个位置开始,而最后一个参数就是从上一个参数位置开始需要几个字符。
用上面的例子来实现结果就如第二幅图,把s2第六个位置后面的三个字符初始化给s6。
注意:
1.第三个参数不写的话是有默认值的,这个默认值如果去查的话显示是-1,但其实就是整数的最大值。如果不写第三个参数,就默认从第二个参数的位置开始,把后面所有的字符初始化给新字符串。
2.如果给了第三个参数,但是长度大于原字符串,那么效果和第一条是一样的。

还有一种是如上图这样初始化,这个方法有两个参数,第一个参数就是字符串,第二个参数是一个整型,意思是获取第一个参数的前n个字符。
实现效果就如第二幅图所示,获取了前5个字符,也就是hello。
2.2string的析构函数
string是一个类,那么就会有自己的析构函数,而析构函数不需要我们手动调用,编译器会自动调用,所以析构函数不需要怎么关注,编译器就会自动调用析构函数把类中的资源给释放掉。
2.3string的=运算符重载
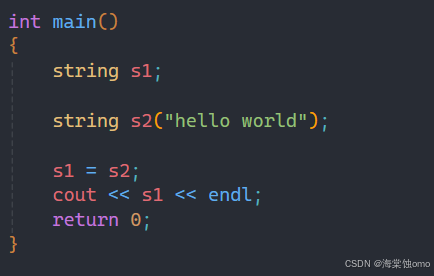
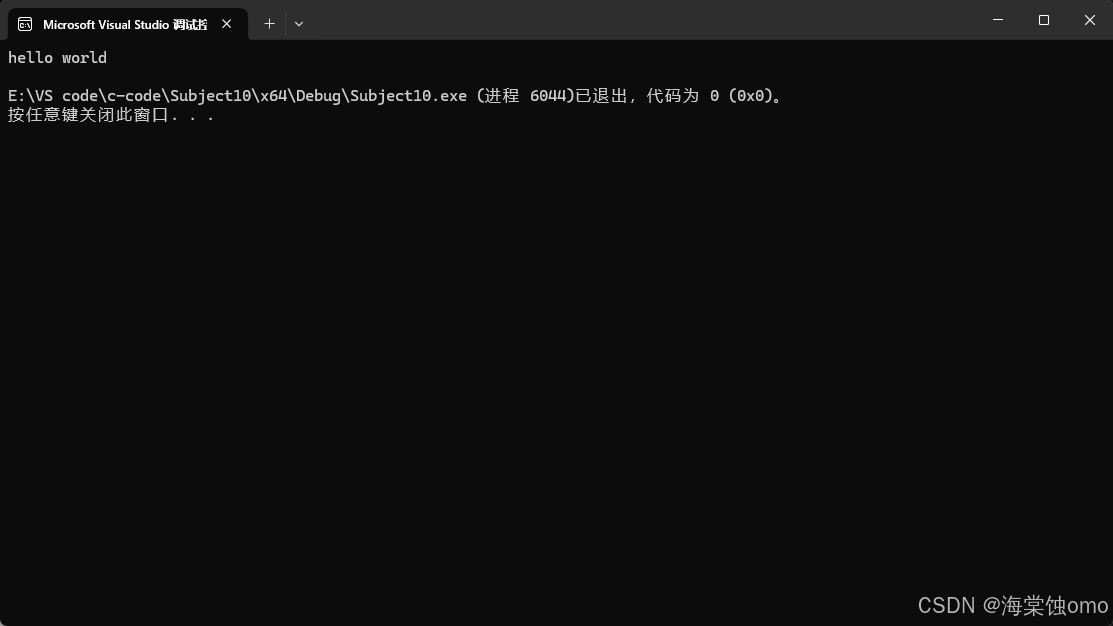
string类也是支持=运算符重载的,基本应用就是上面所示。
2.4string的遍历
string的遍历这里讲三种方式:
2.4.1operator[]遍历
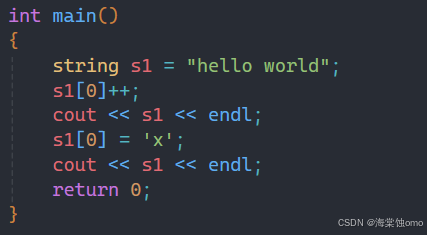
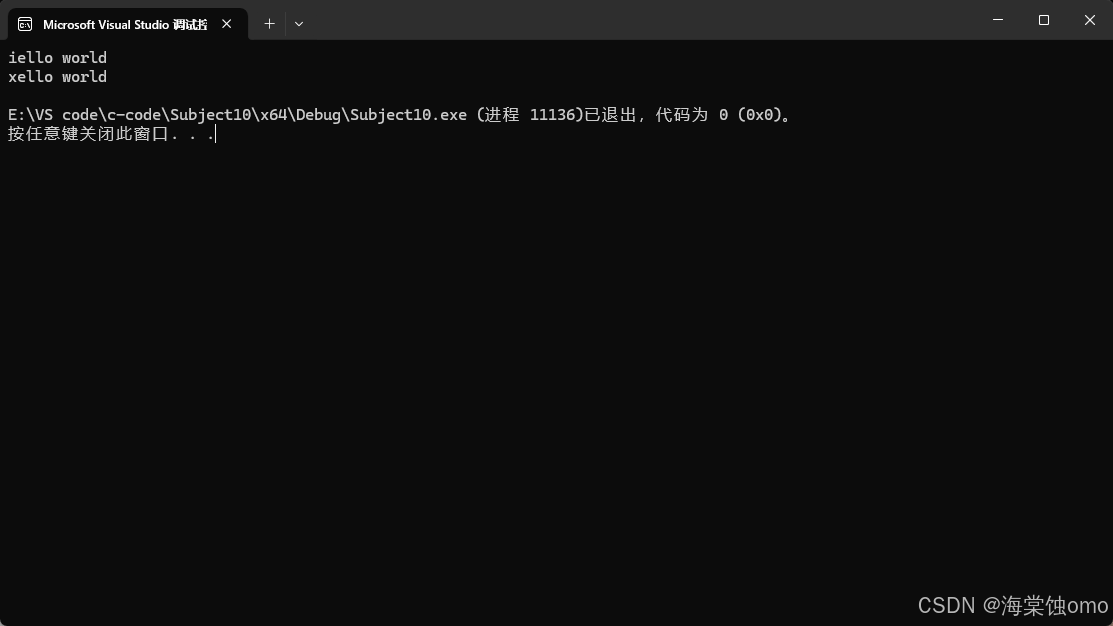
string类中是有[]符号重载的,这样我们就可以像数组一样来遍历字符串中的每个字符。
如上图所示,我们可以对第一个字符进行++或者将其更换为另一个字符,这些操作都是可以的。
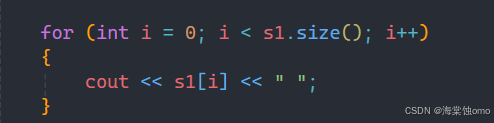
或者也可以像这样遍历字符串的每一个字符并将其打印出来,也是可以的。
注意:字符串的size()函数得到的是字符的数量,并不包含\0。
![]()
如上图,得到的字符数量是11,只是字符的数量。
另外,如果要访问的字符超出了字符串的长度,程序运行后会报错。
![]()
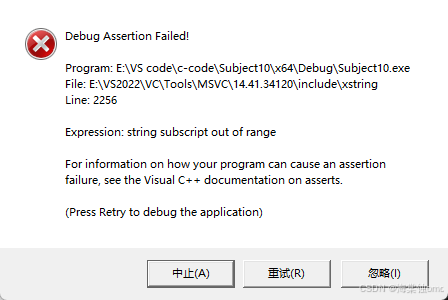
这其实就是在[]符号重载中加入了assert断言,如果访问的字符超出了字符串的长度,就会报上面的错误。
2.4.2迭代器遍历
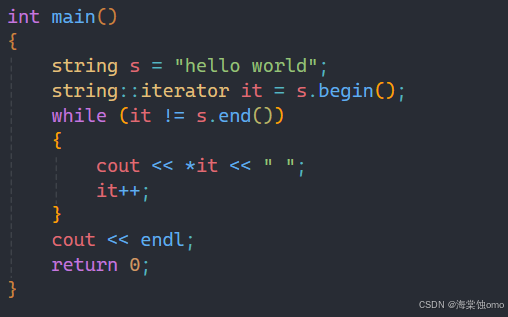
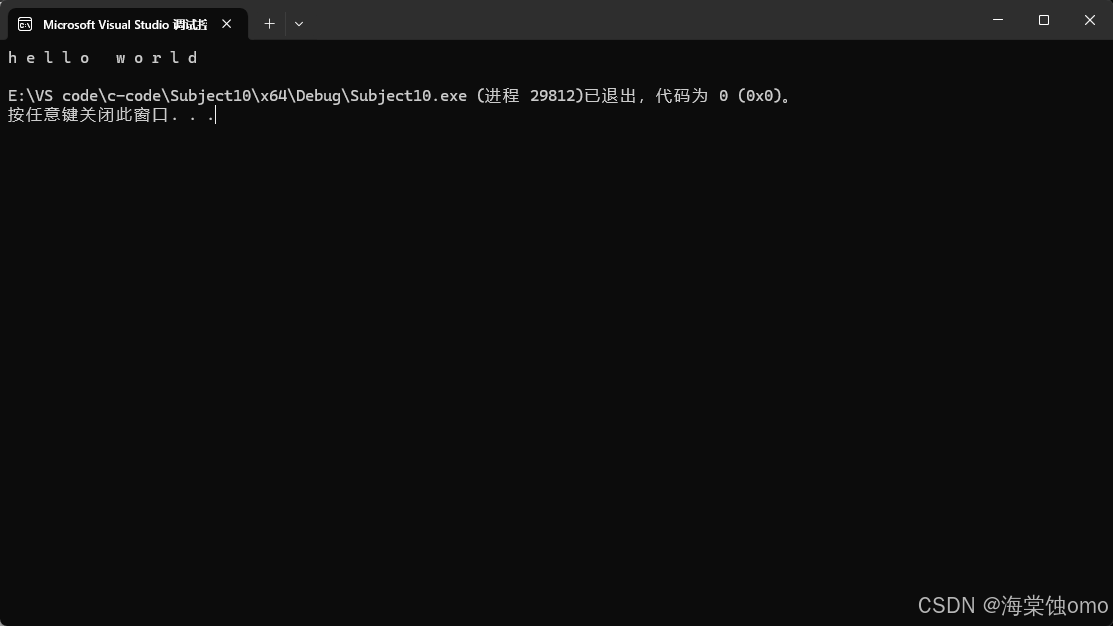
迭代器便的基本用法就如上图所示。
其中的iterator是string类中的一个类型,而begin获得的是字符串的第一个位置,end获得的是字符串最后一个位置的下一个位置,在这里it其实就相当于指针,通过解引用来获取每个字符。
注意:迭代器不一定是指针,只是在这里是指针而已,不要认为迭代器就是指针。
迭代器不只是能读字符串而已,也是能对字符串进行修改的:
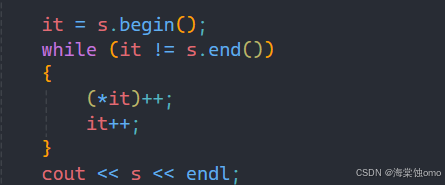
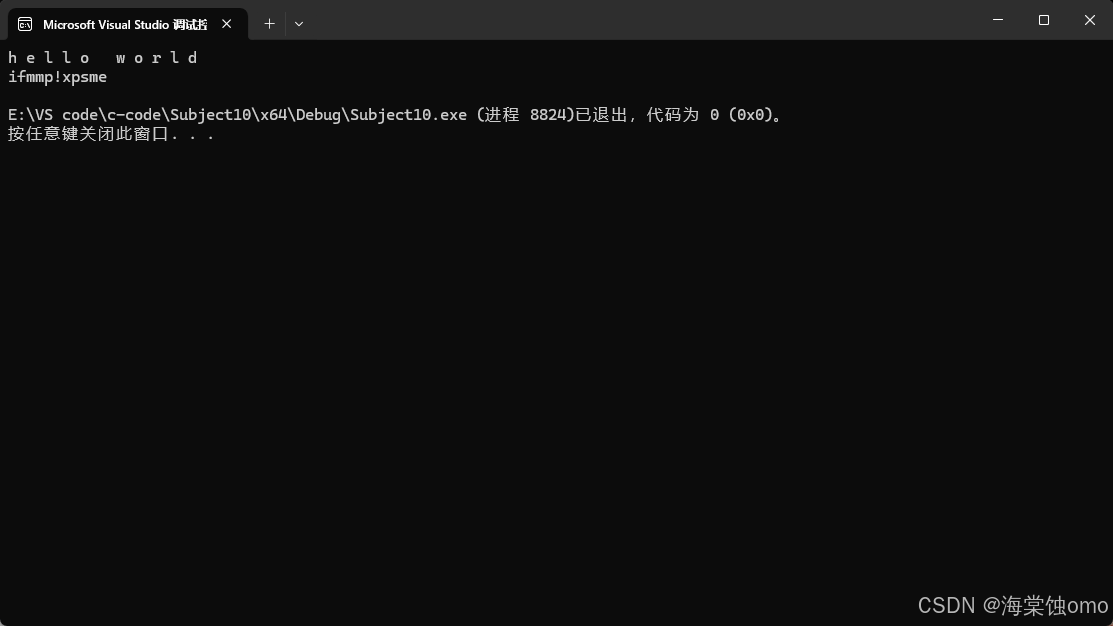
如上图所示,我们通过解引用也是能够对字符串进行修改的。
这里可能有人可能会有疑惑,为什么要学迭代器来遍历字符串呢?直接用[]符号重载来遍历不是更好理解吗?
在当前这个例子中呢确实是这样,但是迭代器是容器的通用访问方式,后面还有其他的容器,有的容器底层并不是数组,而是链表呢?
这时就不能用[]符号重载来进行访问,就只能用迭代器进行访问,所以说迭代器是必须要掌握的。
2.4.3范围for遍历
在讲范围for之前我们先了解一下auto这个东西。

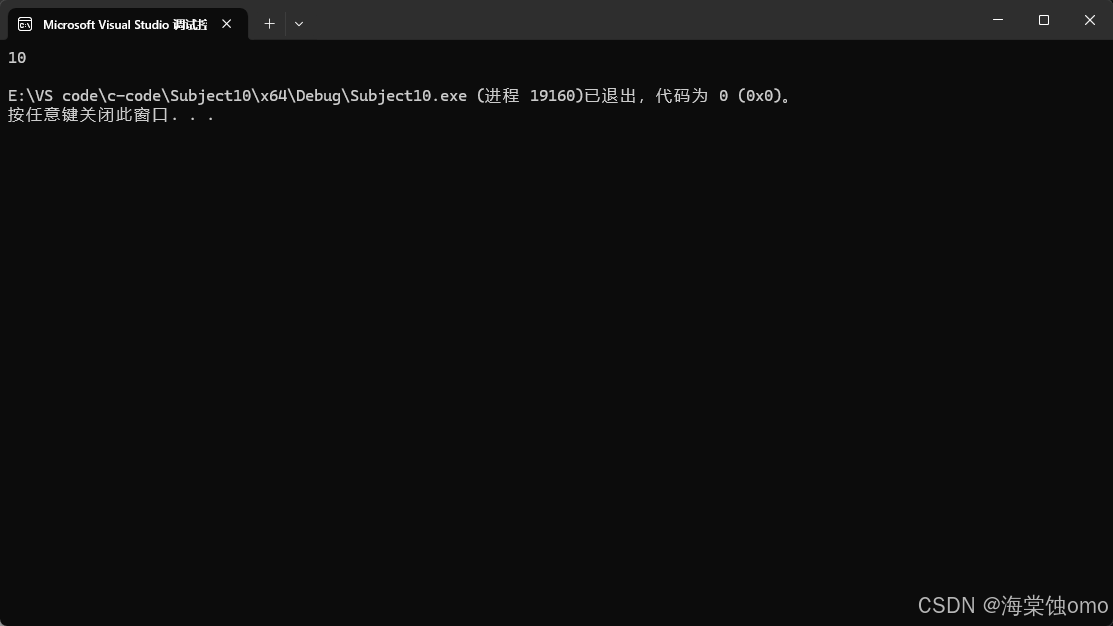
auto这个类型基本应用如上图所示,它的作用就是可以自动通过右边初始化值来推导k的类型。
有人可能会有疑惑,这样写有什么意义吗?我直接写具体类型不行吗?
在这里用auto确实没社么意义,但在我们上面的例子中我们再来看看:
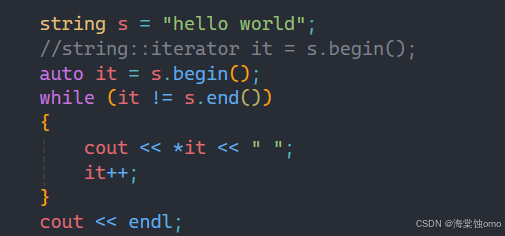
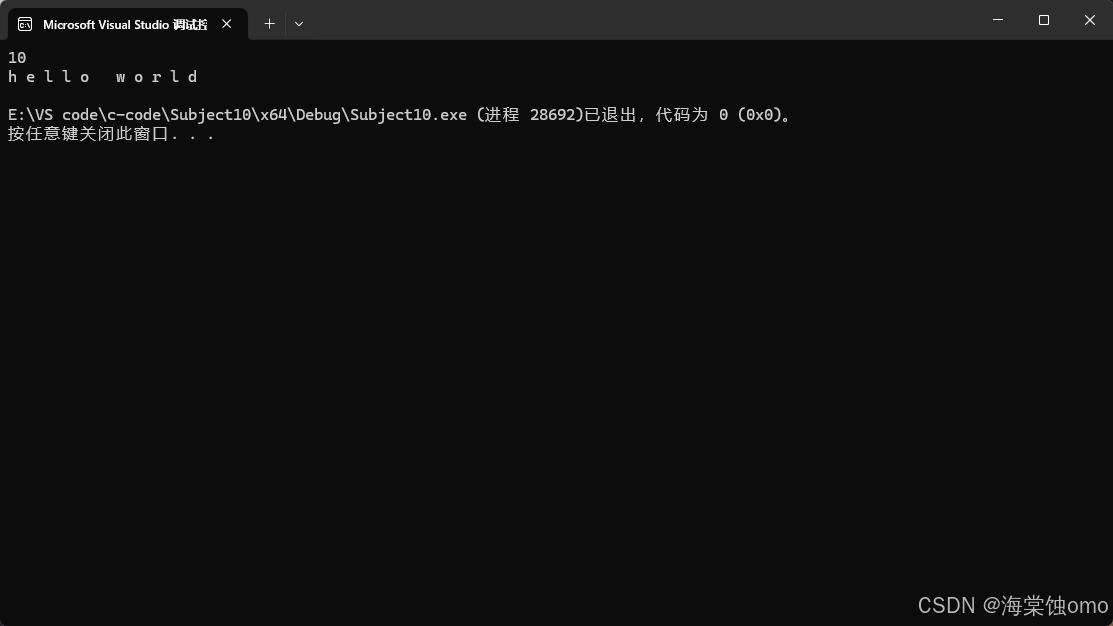
在上面的例子中,我们要写it的类型要写比较长的一串,此时我们就可以利用auto来代替,前面那么长的一串直接用auto来代替,这样代码量就减少并且代码看着也更简洁了,这其实才是auto常用的地方。
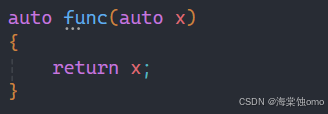

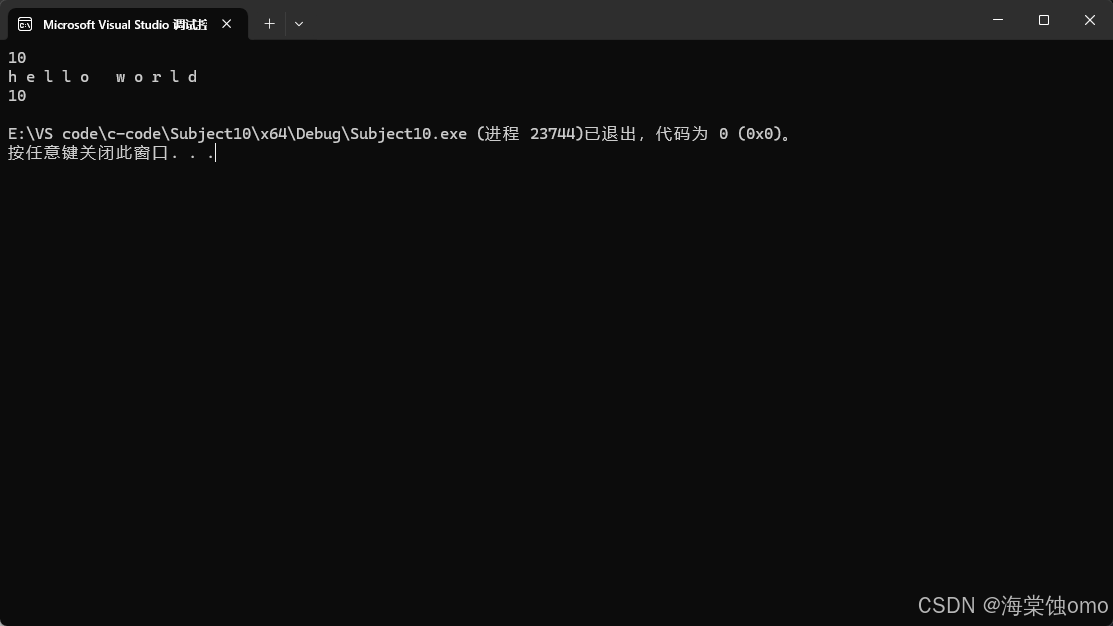
auto也是可以做返回值和参数类型的,不过用这两种方式时要谨慎使用,这里还体现的不明显,如果有很多函数相互调用,一旦出问题,你想找到参数什么类型就会很麻烦。
下面来讲范围for的用法:
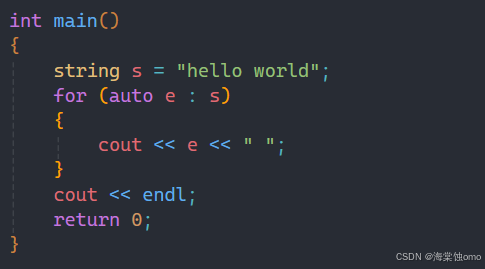
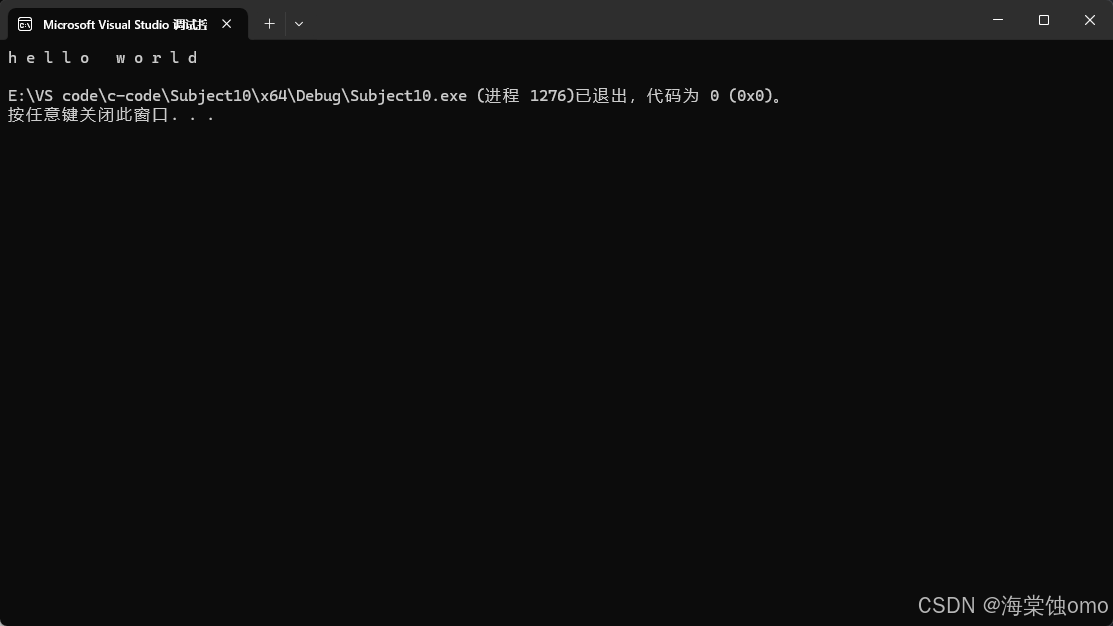
范围for的基本格式如上图所示,其中e是可以取其他名字的,这个不唯一,我用e来演示。
范围for其实就是自动取出容器中的数据给对象,并且自动结束。
范围for不仅可以读取数据,也是可以对容器内的数据进行修改的:
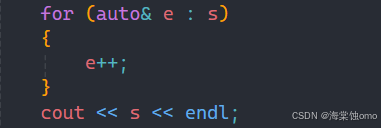
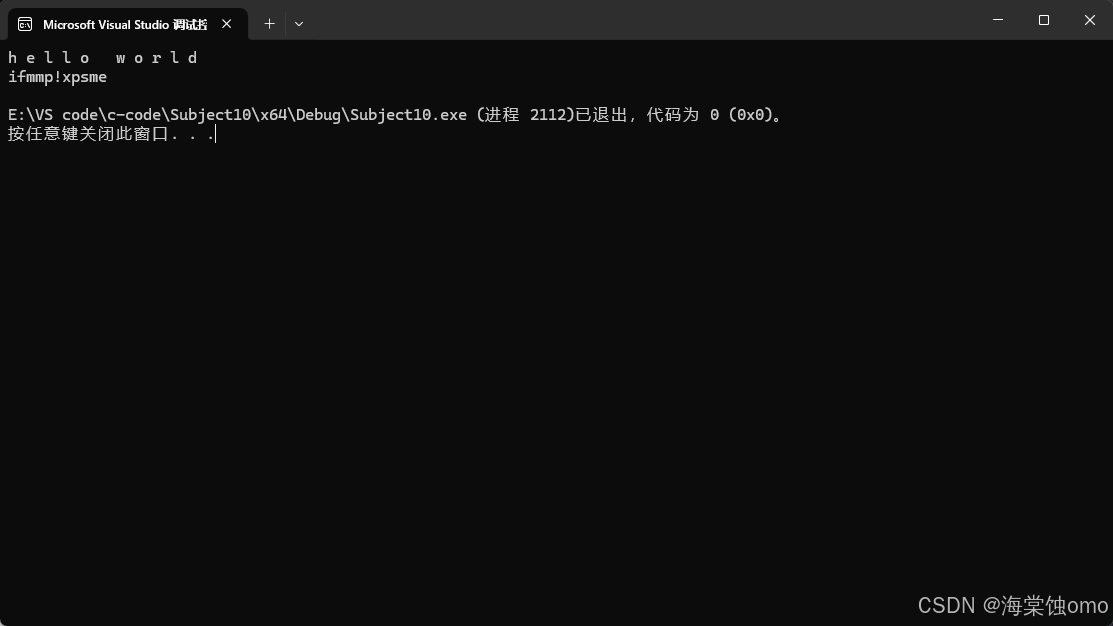
如果要修改容器中的数据,我们要使用引用,因为范围for只是把容器中的数据赋值给e,相当于形参,而形参修改时不会影响实参的,所以我们要修改的话用引用。
auto也可以换成具体的类型,不过一般在使用范围for时都用auto。
当然,容器也可以是一个整型数组:

这些操作都是可以实现的。
范围for原理:在编译时会传化成迭代器来使用
以上就是模板初姐和string(上)的内容。











![[linux] linux基本指令 + shell + 文件权限](https://i-blog.csdnimg.cn/img_convert/f632561f98d94a40bc09dcdc17c3165c.png)






