25年2月来自北大、北京智源、中科院自动化所等的论文“RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete”。
目前的多模态大语言模型(MLLM) 缺少三项必备的机器人大脑能力:规划能力,将复杂的操作指令分解为可管理的子任务;affordance感知,识别和解释交互目标affordance的能力;轨迹预测,预测成功执行所需的完整操作轨迹。为了增强机器人大脑从抽象到具体的核能力,引入 ShareRobot,这是一个高质量的异构数据集,可标记任务规划、目标affordance和末端执行器轨迹等多维信息。ShareRobot 的多样性和准确性,经过三位人类注释员的改进。基于该数据集,开发 RoboBrain一个基于 MLLM 的模型,它结合机器人和通用多模态数据,采用多阶段训练策略,并结合长视频和高分辨率图像来提高其机器人操控能力。
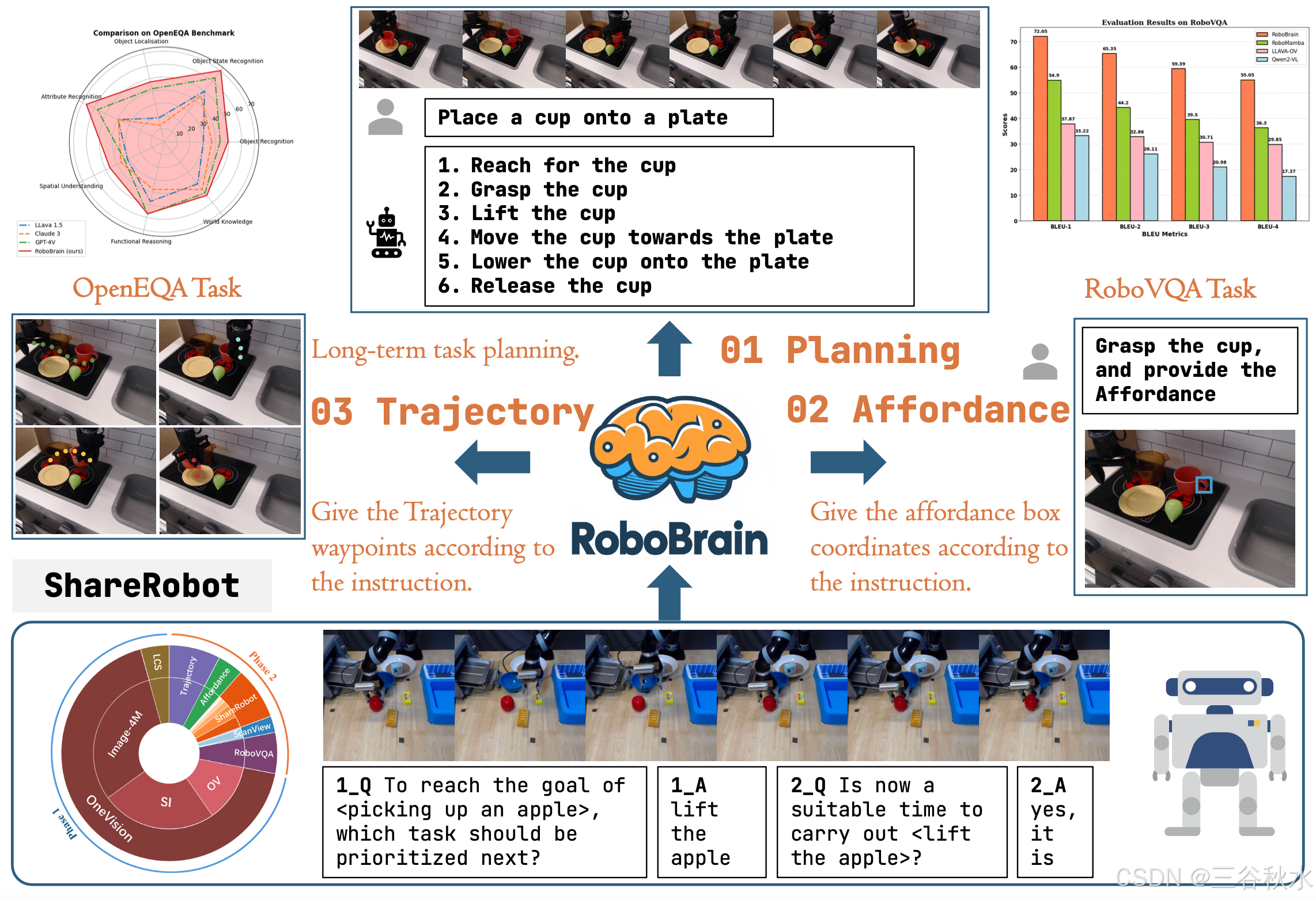
RoboBrain 如下所示:
为了增强RoboBrain的规划、感知和轨迹预测能力,开发一个ShareRobot的数据集,这是一个专为机器人操作任务设计的大规模、细粒度的数据集。数据集的生成过程如图所示:
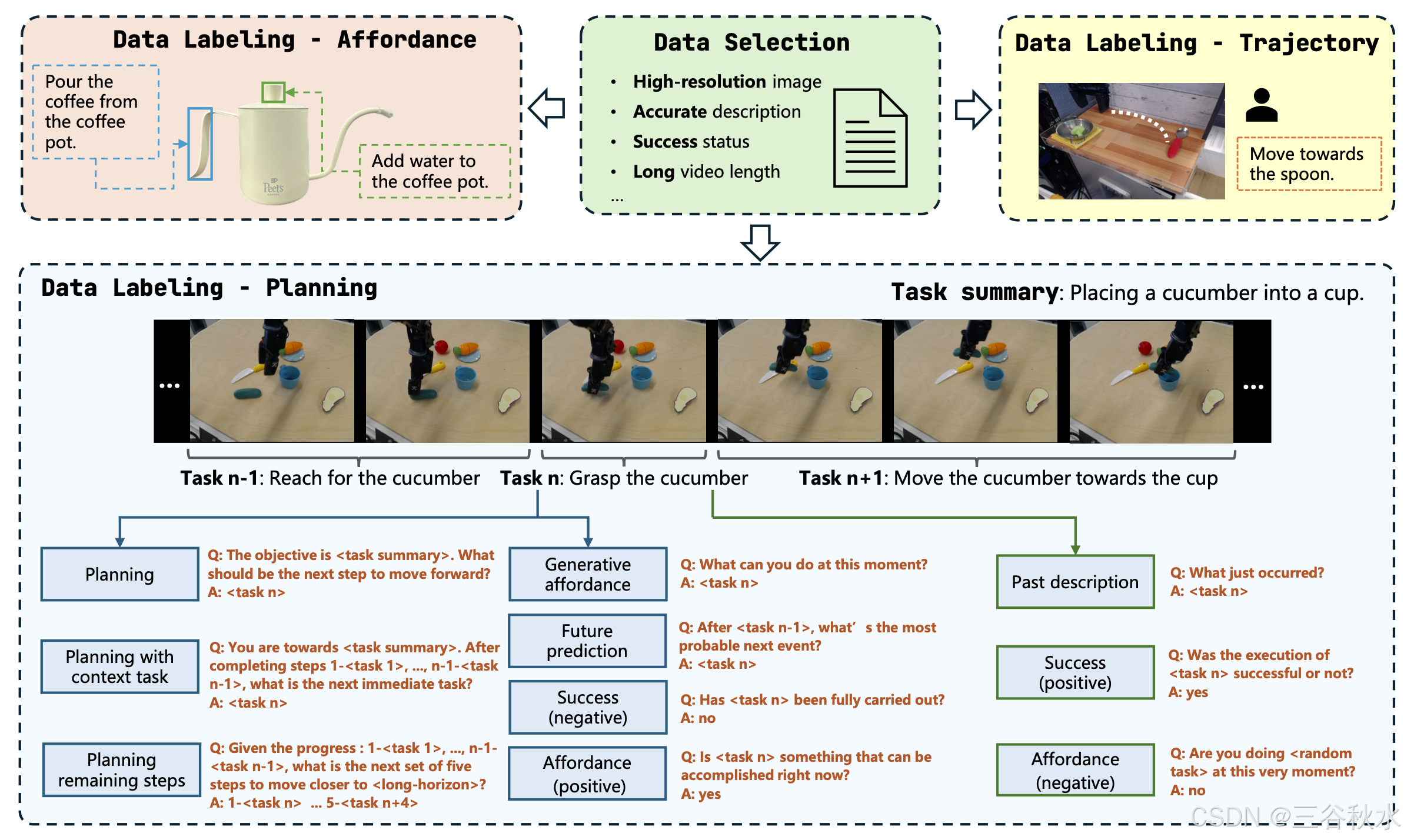
ShareRobot 是一个综合性数据集,将抽象概念转化为具体动作,促进更高效的任务执行。ShareRobot 数据集的主要特点包括:
• 细粒度。与仅提供通用高级任务描述的 Open X-Embodiment 数据集[53]不同,ShareRobot 中的每个数据点都包含与各个帧相关的详细低级规划指令。这种特殊性增强模型在正确的时刻准确执行任务的能力。
• 多维。为了增强 RoboBrain 从抽象到具体的能力,标记任务规划、目标affordance和末端执行器轨迹,从而提高任务处理的灵活性和精确度。
• 高质量。为从 Open-X-Embodiment 数据集[53]中选择数据建立严格的标准,重点关注高分辨率、准确描述、成功执行任务、可见affordance和清晰的运动轨迹。基于这些标准,验证 51,403 个实例以确保高质量,从而为 RoboBrain 的核心功能奠定基础。
• 大规模。ShareRobot 拥有 1,028,060 个问答对,是最大的开源任务规划、可供性预测和轨迹预测数据集,可以更深入地理解从抽象到具体的复杂关系。
• 丰富的多样性。与 RoboVQA[60] 数据集的有限场景相比,ShareRobot 具有 102 个场景,涵盖 12 个实施例和 107 种原子任务。这种多样性使 MLLM 能够从不同的现实世界环境中学习,从而增强复杂、多步骤规划的稳健性。
• 易于扩展。数据生成管道具有高可扩展性,随着新的机器人实具身、任务类型和环境的发展,可轻松扩展。这种适应性确保 ShareRobot 数据集可以支持日益复杂的操作任务。
标注
从每个机器人操作演示中提取 30 帧。用这些帧及其高级描述,使用 Gemini [63] 将它们分解为低级规划指令。然后,三位注释者审查并完善这些指令,以确保标记的准确性。低级规划数据的格式与 RoboVQA [60] 结构一致,用于模型训练,使用 RoboVQA 中 10 种问题类型的问题模板。此过程将 51,403 个低级规划条目转换为 1,028,060 个问答对,注释者监控数据生成以维护数据集的完整性。
从数据集中筛选出 8,511 张图像,并为每张图像标注affordance区域。对于每个 30 帧的演示,在第一帧中标记可affordance,对应于末端执行器和目标之间的接触区域。确定接触帧,即末端执行器首次接触目标的位置,并将第一帧中的真值边框标记为 {l(x), l(y), r(x), r(y)},其中 {l(x), l(y)} 是左上角坐标,{r(x), r^(y)} 是右下角坐标。
用边框注释 8,511 张夹持器图像,与affordance边框格式保持一致。每个末端执行器都标有三部分:整个夹持器、左手指和右手指。这些数据用于计算轨迹位置和训练夹持器检测器。轨迹位置通过平均左右手指的边框来确定,从而可以有效地标记其他数据。
目标是使多模态大语言模型 (MLLM) 能够理解抽象指令并明确输出目标affordance区域和潜操作轨迹,从而促进从抽象到具体的过渡。采用多阶段训练策略:第一阶段专注于通用 OneVision (OV) 训练,以开发具有强大理解和指令遵循能力的基础 MLLM。第二阶段,即机器人训练阶段,旨在增强 RoboBrain 的核心能力,使其从抽象到具体。
RoboBrain 包含三个模块:规划基础模型、affordance 感知 A-LoRA 模型和轨迹预测 T-LoRA 模型。在实际应用中,模型首先生成详细规划,然后将其拆分为子任务描述以执行affordance感知和轨迹预测。RoboBrain 流程如图 所示:
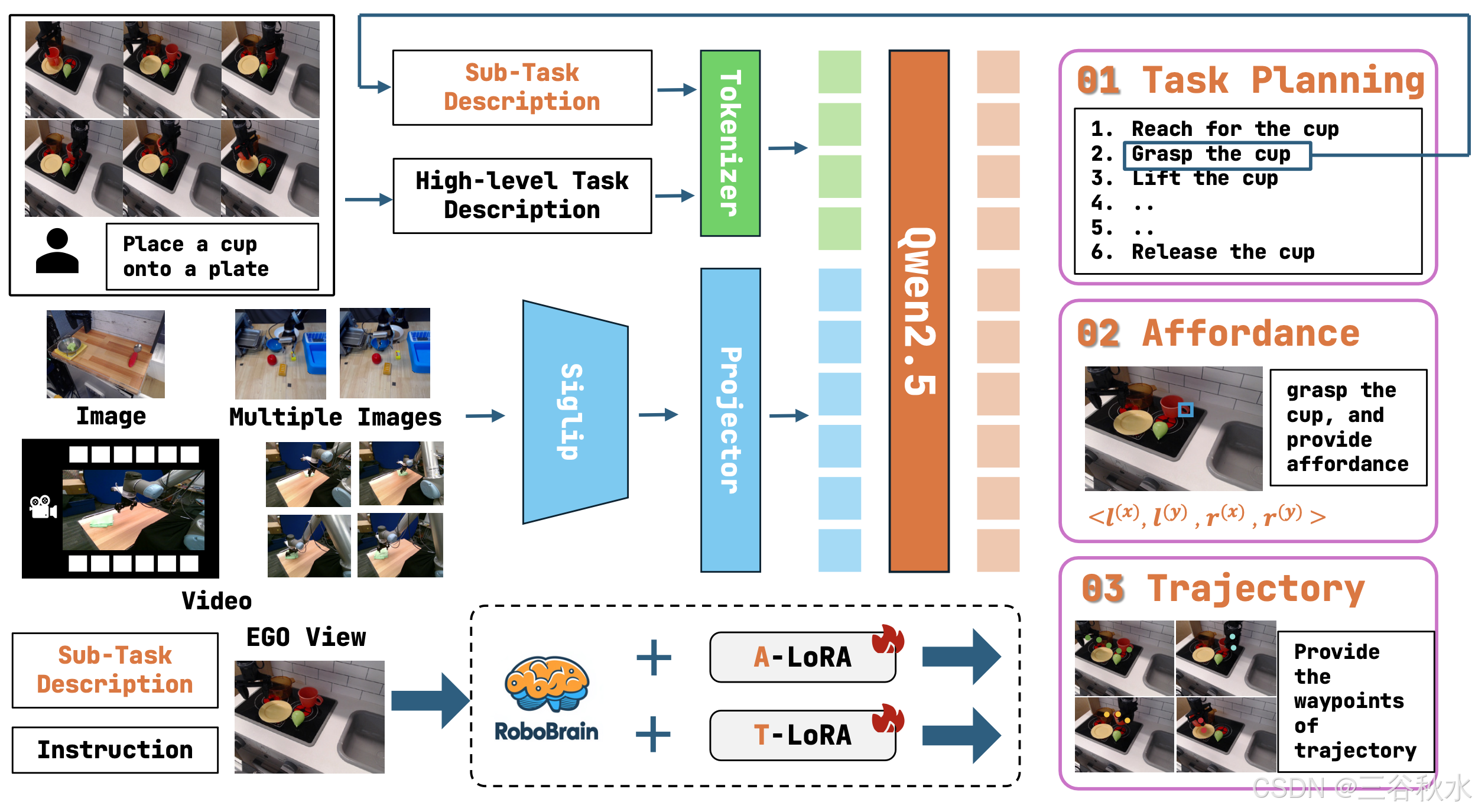
用 LLaVA 作为 RoboBrain 的基础模型,它由三个主要模块组成:视觉编码器(ViT)g(·)、投影器 h(·)和大语言模型(LLM)f(·)。具体来说,用 SigLIP [74]、2 层 MLP [39] 和 Qwen2.5-7B-Instruct [64]。给定图像或视频 X_v 作为视觉输入,ViT 将其编码为视觉特征 Z_v = g(X_v),然后通过投影器将其映射到 LLM 的语义空间,得到一系列视觉tokens H_v = h(Z_v)。最后,LLM 根据人类语言指令 X_t 和 H_v 以自回归方式生成文本响应。
Affordance是指人手与目标接触的区域。在交互过程中,人类会本能地与特定区域内的各种目标互动。利用边框来表示affordance。正式地,考虑一个由多个目标及其affordance组成的图像 I:O_i = {A0_i , A1_i , …, AN_i },其中第 i 个目标拥有 N 个affordance。Affordance的格式定义为 {l(x), l(y), r(x), r(y)},其中 {l(x), l(y)} 表示左上角坐标,而 {r(x), r^(y)} 是右下角坐标。
“轨迹”一词是指 [21] 中提出的 2D 视觉轨迹概念。将轨迹航点定义为一系列 2D 坐标,表示整个过程中末端执行器或手的运动。形式上,在时间步 t,轨迹航点可以表示为 P_t:N = {(x_i, y_i) | i = t, t + 1,…,N},其中 (x_i,y _i) 表示视觉轨迹中的第 i 个坐标,N 表示episode中的总时间步数。
训练
第 1 阶段:通用 OV 训练在第 1 阶段,用 LLaVA-OneVision [34] 的训练数据和策略,构建了具有通用多模态理解和视觉指令跟踪能力的基础模型。这为第 2 阶段增强模型的机器人操作规划能力奠定基础。
在第 1 阶段,用 LCS-558K 数据集 [10, 59] 中的图文数据来训练 Projector,促进视觉特征 Zv 与 LLM 语义特征 Hv 的对齐。在第 1.5 阶段,用 4M 高质量图文数据训练整个模型,以增强模型的多模态常识理解能力。在第 2 阶段,用来自 LLaVA-OneVision-Data [34] 的 3.2M 单图像数据和 1.6M 图像和视频数据进一步训练整个模型,旨在增强 RoboBrain 的指令遵循能力并提高对高分辨率图像和视频的理解。
第 2 阶段:机器人训练在第 2 阶段,以第 1 阶段开发的稳健多模态基础模型为基础,为机器人操作规划创建更强大的模型。具体而言,目标是让 RoboBrain 理解复杂、抽象的指令,支持对历史帧信息和高分辨率图像的感知,并在预测潜操作轨迹的同时输出目标affordance区域。这将有助于操作规划任务从抽象到具体的转变。
在第 3 阶段,收集 1.3M 机器人数据的数据集,以提高模型的机器人操作规划能力。具体来说,这些数据来源于 RoboVQA-800K [60]、ScanView-318K 包括 MMScan-224K [24, 47]、3RScan-43K[24, 67]、ScanQA-25K [4, 24]、SQA3d-26K [24, 48] 以及本文介绍的 ShareRobot-200K 子集。这些数据集包含大量的场景扫描图像数据、长视频数据和高分辨率数据,以支持模型感知不同环境的能力。此外,ShareRobot 数据集中细粒度、高质量的规划数据进一步增强 RoboBrain 的机器人操控规划能力。为了缓解灾难性遗忘问题 [75],从第 1 阶段选取约 1.7M 的高质量图文数据子集,与第 3 阶段收集的机器人数据混合进行训练,并相应地调整整个模型。
在第 4 阶段,利用 ShareRobot 数据集中标注的 affordance 和轨迹数据,进一步增强模型根据指令感知目标affordance和预测操作轨迹的能力。这是通过引入 LoRA [23] 模块进行训练来实现细粒度规划能力的。
如表所示:各阶段的训练参数细节

在整个训练阶段,采用 Zero3 [58] 分布式训练策略,所有实验都在一个服务器集群上进行,每个服务器配备 8×A800 GPU。

















![[QT]开发全解析:从概念到实战](https://i-blog.csdnimg.cn/direct/f14d41e6ca834314b399c50991196aa7.png)
