反应式编程(Reactive Programming)是一套完整的编程体系,既有其指导思想,又有相应的框架和库的支持,并且在生产环境中有大量实际的应用。在支持度方面,既有大公司参与实践,也有强大的开源社区的支持。反应式编程出现的时间并不短,它所受到的关注度不断升高。这主要体现在主流编程平台和框架增强了对它的支持,使它得到了更多的受众,同时也反映了其在开发中的价值。就 Java 平台来说,几个突出的事件包括:Java 9中把反应式流规范以 java.util.concurrent.Flow 类的方式添加到了标准库中;Spring 5 对反应式编程模型提供了内置支持,并增加了新的 WebFlux 模块来支持反应式Web应用的开发。
反应式编程所涵盖的内容很多。与其他编程范式一样,反应式编程要求开发人员改变其固有的思维模式,以不同的角度来看问题。对于熟悉了传统面向对象编程范式的人来说,这样的思想转变可能并不那么容易。反应式编程在解决某些问题时有其先天的优势。在对应用性能要求很高的今天,反应式编程更大有用武之地。作为开发人员来说,根据项目的需求和特征,选择最适合的编程模型可以达到事半功倍的效果。
反应式编程相关的术语目前并没有非常统一的翻译方法,本文中尽量使用较为常见的译法或英文原文。
在讨论反应式编程之前,首先必须要提到的是《反应式宣言(The Reactive Manifesto)》。反应式宣言中对反应式系统(Reactive Systems)的特征进行了定义,有如下四个:
- 及时响应(Responsive):系统在尽可能的情况下及时响应请求。
- 有韧性(Resilient):系统在出现失败时仍然可以及时响应。
- 有弹性(Elastic):在不同的负载下,系统仍然保持及时响应。
- 消息驱动(Message Driven):系统使用异步消息传递来确定不同组件之间的边界,并确保松散耦合、隔离和位置透明性。
这四个特征互相关联和影响。及时响应是核心价值,是反应式系统所追求的目标。有韧性和有弹性是反应式系统的外在表现形式,通过它们才能实现及时响应这个核心价值。消息驱动则是实现手段。
反应式系统的特征
反应式编程的重要概念之一是负压(back-pressure),是系统在负载过大时的重要反馈手段。当一个组件的负载过大时,可能导致该组件崩溃。为了避免组件失败,它应该通过负压来通知其上游组件减少负载。负压可能会一直级联往上传递,最终到达用户处,进而对响应的及时性造成影响。这是在系统整体无法满足过量需求时的自我保护手段,可以保证系统的韧性,不会出现失败的情况。此时系统应该通过增加资源等方式来做出调整。
反应式流
反应式流(Reactive Streams)是一个反应式编程相关的规范。反应式流为带负压的异步非阻塞流处理提供了标准。反应式流规范的出发点是作为不同反应式框架互操作的基础,因此它所提供的接口很简单。
数据传递方式
随着反应式流的出现,我们可以对Java平台上常见的几种数据传递方式做一下总结和比较。
- 直接的方法调用。数据使用者直接调用提供者的方法来获取数据。这种方式是同步的,调用者在方法返回前会被阻塞。调用者和提供者之间的耦合最紧。每次方法调用只能返回一个数据。(虽然可以使用集合类来返回多个数据,但从概念上来说,集合类仍然只能视为一个数据。)
- 使用 Iterable 。 Iterable 表示一个可以被枚举的数据的集合,通常用不同的集合类型来表示,如 List 、 Set 和 Map 等。 Iterable 定义了可以对集合的数据所进行的操作。这些操作是同步的。 Iterable 所包含的数据数量是有限的。
- 使用 Future 。 Future 表示的是一个可以在未来获取的结果,由一个异步操作来负责给出这个结果。在获取到 Future 对象之后,可以使用 get 方法来获取到所需要的结果。虽然计算的过程是异步的, get 方法使用时仍然是阻塞的。 Future 只能表示一个结果。
- 反应式流。反应式流表示的是异步无阻塞的数据流,其中包含的元素数量可能是无限的。
上述四种数据传递方式,实际上代表了两个维度上的四个不同的值,如下表所示。
| 值的数量/ 获取方式 | 同步 | 异步 |
| 1个 | 方法调用 | Future |
| 多个 | Iterable | 反应式流 |
Java 8 的 java.util.stream.Stream 可以看成是对 Iterable 的一种扩展,可以包含无限元素。 Stream 同时又有一部分反应式流实现的特征,主要体现在其流式接口(Fluent interface)上,也可以做并行处理。不过 Stream 缺少了对负压的支持。
Future 和 CompletableFuture
Java 中的 Future 把异步操作进行了抽象,但是只解决了一半的问题。虽然 Future 所表示的计算是异步的,但是对计算结果的获取仍然是同步阻塞的。 Future 原本的设计思路是:当需要执行耗时的计算时,提交该计算任务到 ExecutorService ,并得到一个 Future 对象作为返回值。接着就可以执行其他任务,然后再使用之前得到的 Future 对象来获取到所需的计算的结果值,再继续下面的计算。这样的设计思路有一个突出的问题,那就是在实际的编程实践中,很难找到一个合适的时机来获取 Future 对象的计算结果。因为 get 方法是阻塞的,如果调用早了,主线程仍然会被阻塞;如果调用晚了,在某种程度上降低了并发的效率。除此之外,如果需要在代码的不同部分之间传递计算的结果,需要把 Future 对象在不同的对象之间进行传递,也增加了系统的耦合性。
Java 8 的 CompletableFuture 的出现解决了上面提到的 Future 的问题。而解决的办法是允许异步操作进行级联。比如有一个服务用来生成报表,另外一个服务用来发送电子邮件。生成报表的服务返回的是 CompletableFuture 对象,只需要通过 thenApply 或 thenRun 就可以调用发送电子邮件的服务,得到的结果是另外一个 CompletableFuture 对象。在使用 CompletableFuture 时,不需要考虑获取异步操作结果的时机,只需要以声明式的方式定义出对结果的操作即可。这也避免了不必要的 CompletableFuture 对象传递。
CompletableFuture 仍然只能表示一个结果。如果把 CompletableFuture 的思路进一步扩展,就是反应式流解决问题的思路。在实际中,异步服务通常都是处理数据流。比如上面提到的发送电子邮件的服务,会接受来自不同源的数据。反应式流的一个重要目标是确保流的消费者不会因为负载过重而崩溃。
在具体介绍反应式流之前,我们先看一下反应式流会带来的思维方式的转变。
流式思考(Thinking in Streams)
反应式流所带来的编程思维模式的改变是转为以流为中心。这是从以逻辑为中心到以数据为中心的转换,也是命令式到声明式的转换。传统的命令式编程范式以控制流为核心,通过顺序、分支和循环这 3 种控制结构来完成不同的行为。开发人员在程序中编写的是执行的步骤;以数据为中心侧重的是数据在不同组件的流动。开发人员在程序中编写的是对数据变化的声明式反应。
我们通过一个具体的示例来说明以流为中心的思维模式。在电子商务网站中都有购物车这个功能。用户在购物车界面可以看到所有已经添加的商品,还可以进一步修改商品的数量。当数量更新之后,购物车界面上要显示更新后的订单总价。按照一般的面向对象的思路,我们会有一个订单对象,里面包含了当前全部的商品,并有一个属性来表示订单的总价。当商品数量更新之后,订单对象中的商品被更新,同时需要重新调用计算总价的方法来更新总价属性值。
下面是按照命令式的思路的基本 Java 代码。 updateQty 用来更新订单商品数量, calculateTotal 用来计算总价。典型的运行流程是先调用 updateQty ,再调用 calculateTotal 。
class Order {
public void updateQty(LineItem item, int qty) {
item.qty = qty;
this.calculateTotal();
}
private void calculateTotal() {
this.total = ...
}
}如果采用事件驱动的方式,比如典型的Web界面中,情况并不会好太多。我们可以为不同的动作创建相应的事件。每个事件有自己的类型和相应的数据(payload)。比如,商品数量更新事件的数据中会包含商品的ID和新的数量。系统对不同的事件有不同的处理方式。商品数量更新事件其实是对之前的 updateQty 方法调用的封装。引入事件的好处是可以把调用者和处理者进行解耦。当直接调用 order.updateQty() 方法时,调用者和处理者紧密耦合在一起。在引入了事件之后,原来的一个步骤被划分成3个小步骤:
- 调用者创建事件并发布。
- 事件中间件负责传递事件,通常采用事件总线(Event Bus)来完成。
- 处理者接收到事件后进行处理。
事件驱动的方式增加了一定的灵活性,但对数据的处理方式仍然不是很自然。再回到最初的问题,问题的本质在于订单的总价是会随着商品的数量而改变的。当商品的数量变化时,订单对象本身并不会对该变化作出反应来更新自身的总价属性。如果以反应式的思维模式,那会是不一样的情况。
在以流为中心是思维模式中,值可能产生变化的变量都是一个流。流中的元素代表了变量在不同时刻的值。如果一个变量的值的变化会引起另外一个变量的变化,则把前一个变量所表示的流作为它所能引起变化另外一个变量对应的流的上游。我们可以把每个商品的数量看成一个流。当数量更新时,流中会产生一个新的元素。流中的元素可能是 1 -> 2 -> 3 -> 2 ,也可能是其他合法的序列。每个元素表示了用户的一次操作的结果。订单的总价也是一个流,它的元素表示了由于商品数量变化所对应的总价。总价对应的流中的元素是根据所有商品数量流的元素来产生的。每当任意一个商品数量中产生了新的元素,都会在总价流中产生一个对应的新元素。对总价的计算逻辑使用流的运算符来表示。
接着我们来具体看看怎么以反应式流的方式来实现购物车。为了更加直观的展示,这里我使用的是JavaScript上的反应式库RxJS。下面的代码是一个简单的购物车页面。页面上有3个固定的商品。每个商品有对应的 input 元素。 input 元素的 data-price 属性表明了商品的单价。函数 calculateItemPrice 的作用是根据一个 input 元素来计算其对应商品的价格,也就是单价乘以数量。
总价的计算逻辑在下面的6行代码中。对于每个 input 元素, Rx.Observable.fromEvent 从其 change 事件中创建出一个流。每当 change 事件产生时,流就会产生一个对应的事件对象。对于事件对象,可以通过 target 属性获取到对应的 input 元素,再使用 calculateItemPrice 进行计算。在经过 map 操作符之后,流的元素变成了每个商品的价格。流中的初始元素是数量为 1 时的价格。
Rx.Observable.combineLatest 方法的作用是把每个 input 所对应的流进行合并,从每个流中获取最新的元素,组合成一个数组,作为它所对应的流的元素。我们只需要把数组的值进行累加,就得到了总价。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>使用反应式编程的购物车示例</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/lodash.js/4.17.5/lodash.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/rxjs/5.5.6/Rx.js"></script>
<script>
let calculateItemPrice = node => $(node).val() * parseFloat($(node).data('price'));
$(function() {
Rx.Observable.combineLatest(
$('input').map((index, node) => Rx.Observable.fromEvent(node, 'change')
.map(e => calculateItemPrice(e.target))
.startWith(calculateItemPrice(node))).get())
.map(values => _.sum(values))
.subscribe(total => $('#total').html(total))
});
</script>
</head>
<body>
<div>
<span>商品1,单价10</span>
<input type="number" value="1" data-price="10">
</div>
<div>
<span>商品2,单价15</span>
<input type="number" value="1" data-price="15">
</div>
<div>
<span>商品3,单价20</span>
<input type="number" value="1" data-price="20">
</div>
<div>总价:<span id="total"></span></div>
</body>
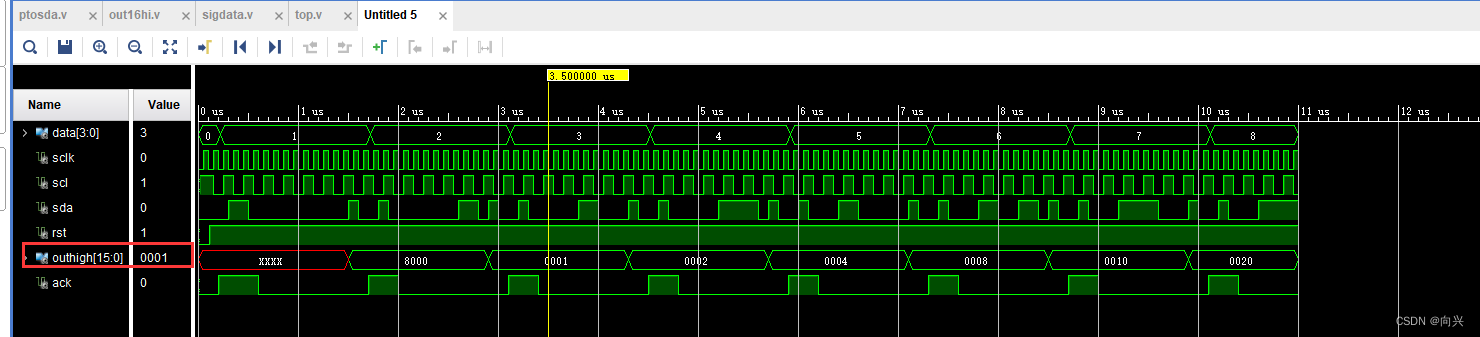
</html>该页面的运行效果如下所示。

购物车运行效果
从上述代码可以看到,反应式流采用了与传统编程不同的思路,更加注重的是数据层面上的抽象,淡化了状态。
Java 9 的 Flow
下面我们结合 Java 9 中的 java.util.concurrent.Flow 类来说明反应式流规范。Java 9中的 Flow 只是简单的把反应式流规范的4个接口整合到了一个类中。
Publisher
顾名思义, Publisher 是数据的发布者。 Publisher 接口只有一个方法 subscribe 来添加数据的订阅者,也就是下面的 Subscriber 。
Subscriber
Subscriber 是数据的订阅者。 Subscriber 接口有4个方法,都是作为不同事件的处理器。在订阅者成功订阅到发布者之后,其 onSubscribe(Subscription s) 方法会被调用。 Subscription 表示的是当前的订阅关系。当订阅成功后,可以使用 Subscription 的 request(long n) 方法来请求发布者发布 n 条数据。发布者可能产生3种不同的消息通知,分别对应 Subscriber 的另外3个回调方法。
- 数据通知:对应 onNext 方法,表示发布者产生的数据。
- 错误通知:对应 onError 方法,表示发布者产生了错误。
- 结束通知:对应 onComplete 方法,表示发布者已经完成了所有数据的发布。
在上述3种通知中,错误通知和结束通知都是终结通知,也就是在终结通知之后,不会再有其他通知产生。
Subscription
Subscription 表示的是一个订阅关系。除了之前提到的 request 方法之外,还有 cancel 方法用来取消订阅。需要注意的是,在 cancel 方法调用之后,发布者仍然有可能继续发布通知。但订阅最终会被取消。
Processor
Processor 表示的一种特殊的对象,既是生产者,又是订阅者。
Publisher 只有在收到请求之后,才会产生数据。这就保证了订阅者可以根据自己的处理能力,确定要 Publisher 产生的数据量,这就是负压的实现方式。
Reactor
反应式流规范所提供的API是很简单的,并不能满足日常开发的需求。反应式流的价值在于对流以声明式的方式进行的各种操作,以及不同流之间的整合。这些都需要通过第三方库来完成。目前Java平台上主流的反应式库有两个,分别是Netflix维护的 RxJava 和 Pivotal 维护的 Reactor。RxJava 是Java平台反应式编程的鼻祖。反应式流规范在很大程度上借鉴了 RxJava 的理念。由于 RxJava 的产生早于反应式流规范,与规范的兼容性并不是特别好。Reactor 是一个完全基于反应式流规范的全新实现,也是 Spring 5 默认的反应式框架。
Reactor 的两个最核心的类是 Flux 和 Mono 。Reactor采用了两个不同的类来表示流。 Flux 表示的包含0到无限个元素的流,而 Mono 则表示最多一个元素的流。虽然从逻辑上来说, Mono 表示的流都可以用 Flux 来表示,这样的区分使得很多操作的语义更容易理解。比如对一个 Flux 进行 reduce 操作的结果是一个 Mono 。而对一个 Mono 进行 repeat 操作得到的是一个 Flux 。
Flux 和 Mono 的强大之处来源于各种不同的操作符。完整的操作符列表可以参考官方文档。下面对这些操作符做一些基本的分类介绍。
第一类是创建 Flux 和 Mono 的静态方法。比如 Flux 的 fromArray 、 fromIterable 和 fromStream 方法分别从数组、 Iterable 和 Stream 中创建 Flux 。 interval 可以根据时间间隔生成从 0 开始的递增序列。 Mono 还可以从 Runnable 、 Callable 和 CompletableFuture 中创建。
Flux.fromArray(new String[] {"a", "b", "c"})
.subscribe(System.out::println);
Mono.fromFuture(CompletableFuture.completedFuture("Hello World"))
.subscribe(System.out::println);第二类是缓冲上游流中的元素的操作符,包括 buffer 、 bufferTimeout 、 bufferWhen 、 bufferUntil 、 bufferWhile 、 window 、 windowTimeout 、 windowWhen 、 windowUntil 和 windowWhile 等。 buffer 等方法按照元素数量和/或间隔时间来收集元素,把原始的 Flux<T> 转换成 Flux<List<T>> 。 window 等方法与 buffer 作用类似,只不过是把原始的 Flux<T> 转换成 Flux<Flux<T>> 。
使用 bufferTimeout 可以用简洁的方式解决一些复杂的问题。比如,有一个执行批量处理的服务,我们需要在请求数量达到某个阈值时马上执行批量处理,或者给定的时间间隔过去之后也要执行批量处理。这样既可以在负载高时降低批量处理的压力,又可以在负载低时保证及时性。
在下面的代码中, Flux.interval 用来生成递增的序列,其中第一个 Flux 的时间间隔是 100 毫秒,第二个 Flux 的时间间隔是 10 毫秒,并有一秒的延迟。两个 Flux 表示的流被 merge 合并。 bufferTimeout 的设置是最多 10 个元素和最长 500 毫秒。由于生成的流是无限的,我们使用 take(3) 来取前面3个元素。 toStream() 是把 Flux 转换成Java 8的 Stream ,这样可以阻止主线程退出直到流中全部元素被消费。在最初的 500 毫秒,只有第一个 Flux 产生数据,因此得到的 List 中只包含5个元素。在接着的 500 毫秒,由于时间精确度的原因,在 List 中仍然是可能有来自第二个 Flux 的元素。第三个 List 则包含 10 个元素。
Flux.merge(
Flux.interval(Duration.ofMillis(100)).map(v -> "a" + v),
Flux.interval(Duration.ofSeconds(1), Duration.ofMillis(10)).map(v -> "b" + v)
).bufferTimeout(10, Duration.ofMillis(500))
.take(3)
.toStream()
.forEach(System.out::println);第三类是收集操作符,包括 collect 、 collectList 、 collectMap 、 collectMultimap 和 collectSortedList 等,用来把流中的元素收集到不同的集合对象中。
第四类是流合并操作符,包括 concat 和 merge 等。 concat 和 merge 都可以合并多个流,不同之处在于 concat 会在完全消费前一个流之后,才开始消费下一个流;而 merge 则同时消费所有流,来自不同流的元素会交织在一起。
第五类是流转换合并操作符,包括 concatMap 和 flatMap 。这些操作符都把原始流的每个元素转换成一个新的流,再合并这些新生成的流。在合并流时, concatMap 的语义与 concat 相似,而 flatMap 的语义与 merge 相似。下面代码的输出结果是 0 、 0 、 1 、 0 、 1 、 2 。
Flux.just(1, 2, 3).concatMap(v -> Flux.interval(Duration.ofMillis(100)).take(v))
.toStream()
.forEach(System.out::println);第六类是对流元素进行处理的操作符。这一类操作符种类很多,也比较容易理解。比如对流中元素进行转换的 map ,对元素进行过滤的 filter ,去掉重复元素的 distinct ,从流中抽取给定数量元素的 take 和跳过流中给定数量元素的 skip 。
除了上述这些之外,还有其他不同的操作符,具体参见官方文档。
总结
反应式编程在解决某些问题时有其独到之处,可以作为传统编程范式的良好补充,也可以从头开发一个完整的反应式应用。要了解反应式编程,最重要的是思维模式的转变。这不可能一蹴而就,只能通过大量的实战开发来获取相关经验。大胆在你的下一个项目中使用反应式编程吧,肯定会有不一样的体验。