
-

作者:Shaoting Zhu, Derun Li, Linzhan Mou, Yong Liu, Ningyi Xu, Hang Zhao
-
单位:清华大学交叉信息研究院,上海交通大学电子信息与电气工程学院,浙江大学计算机科学与技术学院,宾夕法尼亚大学GRASP实验室,上海期智研究院
-
标题:SARO: Space-Aware Robot System for Terrain Crossing via Vision-Language Model
-
原文链接:https://saro-vlm.github.io/resources/saro_paper.pdf
-
项目主页:https://saro-vlm.github.io/
主要贡献

-
高阶推理模块与闭环子任务执行:SARO系统引入了一个由高层次推理模块和闭环子任务执行模块,利用视觉语言模型(VLM)的推理能力,通过任务分解和闭环子任务执行机制来增强机器人的三维场景理解和运动规划能力。
-
基于强化学习的低阶控制策略:提出了基于强化学习的低阶控制策略,称为概率退火选择(PAS),通过强化学习有效地训练控制策略,以应对各种三维地形挑战,解决了传统模仿学习在真实世界部署中的性能下降问题。
-
零样本推理与通用性:SARO系统利用VLM的零样本推理能力进行常识推理,使得系统能够在没有特定训练数据的情况下,通过视觉常识进行导航和决策,增强了系统的通用性和适应性。
-
实验验证与鲁棒性:通过在多种室内和室外环境中的实验验证,展示了SARO系统在完成特定目标跟踪任务时的准确性和鲁棒性。实验结果表明,系统能够在不同的三维地形上实现导航,并且具有较好的泛化能力,适用于多样化的环境和场景。
研究背景
研究问题
论文主要解决的问题是如何设计一个系统来充分利用视觉语言模型(VLM)在机器人导航中的潜力,使机器人能够在3D环境中观察、理解和行动。
研究难点
该问题的研究难点包括:
-
VLM在训练数据视角和缺乏记忆信息库方面的局限性,
-
传统导航方法在复杂真实世界情况下的鲁棒性不足,
-
以及从模拟到真实世界的迁移问题。
相关工作
-
基础模型在机器人中的应用
-
基础模型的应用:一些研究者将基础模型应用于机器人任务中,使用开放词汇预训练模型进行机器人任务。例如,一些工作利用GPT-4V等强大的VLMs进行机器人任务。
-
四足机器人应用:一些研究尝试将基础模型应用于四足机器人。例如,Saytap使用大型语言模型将自然语言命令转换为四足机器人的足部接触模式。ViNT从大规模视觉导航数据集中训练一个通用策略。CognitiveDog将大型多模态模型与四足机器人集成。GeRM训练了一个用于四足机器人的通用模型。QuadrupedGPT和Commonsense利用大型模型进行简单场景中的移动。
-
然而,这些方法大多仅适用于平面表面上的任务,未能充分利用四足机器人在三维地形上的能力。
-
四足机器人行走控制
-
传统控制方法:传统的行走控制方法(如SLIP、VMC、MPC)在处理特定地形任务时表现不佳,通常在真实世界部署中存在不稳定性问题。
-
强化学习的应用:强化学习在近年来显示出显著的能力,能够利用特权训练范式训练四足机器人,而不需要额外的传感器。一些工作结合本体感知和外感知状态来实现敏捷行走。
-
模仿学习和迁移学习:模仿学习在之前的工作中被频繁使用。适应学习和教师-学生框架学习被用来解决模拟到现实的迁移问题,但这些方法在真实部署中容易出现性能下降。
-
创新方法:一些工作提出了创新的方法来提高行走效率。例如,DayDreamer学习一个“世界模型”来合成无限交互,而DreamWaQ通过学习VAE模型隐式推断地形属性并相应地调整步态。
-
结合传统控制与深度强化学习:一些工作将传统控制方法与深度强化学习结合,以加速训练速度,但未能充分利用模拟中的特权信息。
-
论文方法
任务定义
-
前提描述:
-
四足机器人在三维环境中自主导航的目标跟踪任务。
-
任务要求机器人在包含不同地形的3D环境中导航,从一个平台到达另一个平台。
-
地形由两个平台和连接这两个平台的中间区域组成。中间区域包括“楼梯”、“坡道”、“间隙”和“门”。
-
机器人的初始位置在一个平台上,目标是到达另一个平台上指定的目标位置。
-
任务还包括一个语言描述,指导机器人如何穿越地形。
-
机器人只能访问机载传感器,包括本体感知、自视角RGB图像和深度图像。
-
-
形式化描述:
-
地形 包含两个平台 和 ,以及连接这两个平台的中间区域 I。
-
机器人的起始位置在 上,目标是到达 上的指定目标 G,目标位置由相对机器人的起始位置的坐标 (x, y, z, yaw) 定义,并结合语言描述 L。
-

高层次推理与任务执行
-
任务分解:
-
系统作为一个状态机工作,将多步导航分解为一个由移动动作和结束点组成的子任务序列。
-
通过提示VLM,系统能够识别与任务指令相关的中间区域,并生成分解后的子任务序列。
-
每个子任务定义为 (Action, Ending) 对,其中 Action 是 ["move", "climb"] 中的一个,Ending 是 ["facing intermediation", "across intermediation", "to the goal"] 中的一个。
-
-
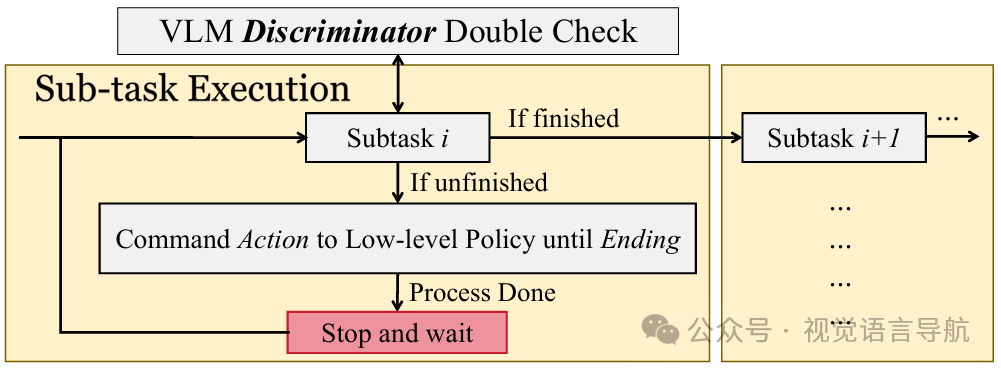
子任务执行:
-
系统利用VLM的感知能力来辅助精细的轨迹引导和子任务状态的判断。
-
对于每个子任务,VLM鉴别器首先根据 Ending 判断子任务是否完成。
-
如果未完成,则根据 Action 和 VLM的语言指令发送速度命令到低层次策略。
-
预定义的执行工作流决定了如何完成这个 Action 直到到达 Ending 点。
-
系统采用闭环模块和双重检查机制,确保子任务的准确执行。
-
低层次行走控制策略
-
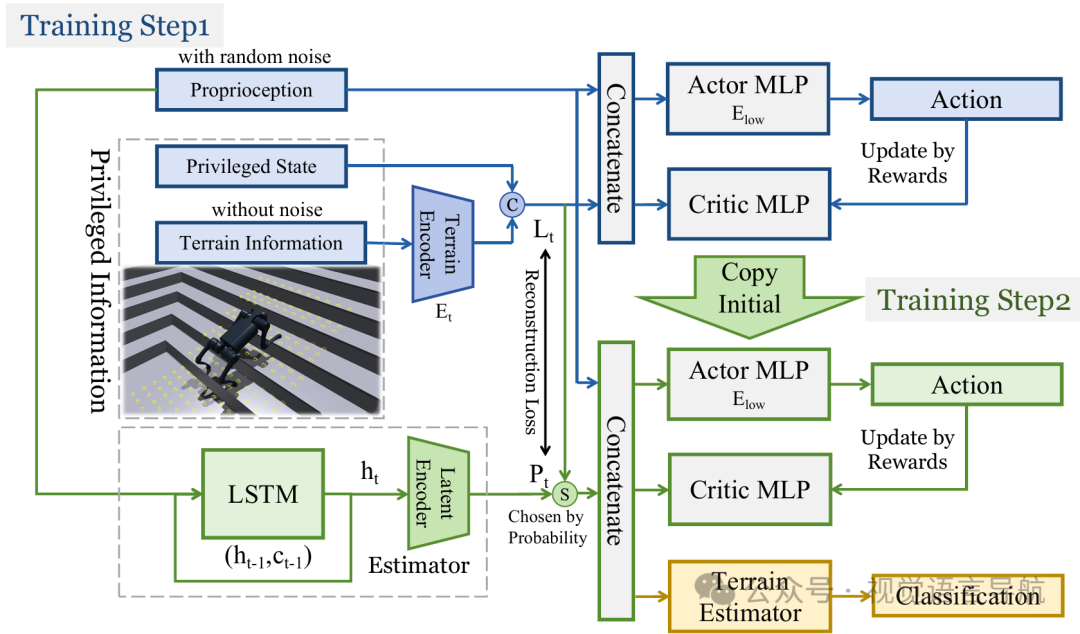
Oracle策略训练:在第一阶段,系统训练一个Oracle策略,使用本体感知、特权状态和地形信息作为输入。通过强化学习,机器人可以在各种地形上快速有效地学习行走技能。
-
部分观察策略训练:在第二阶段,系统使用概率退火选择(PAS)方法训练最终的动作网络,该方法仅使用本体感知作为输入。PAS方法通过逐渐增加预测值的使用比例,确保训练过程的稳定性和最终策略的性能。
实验
实验设置
-
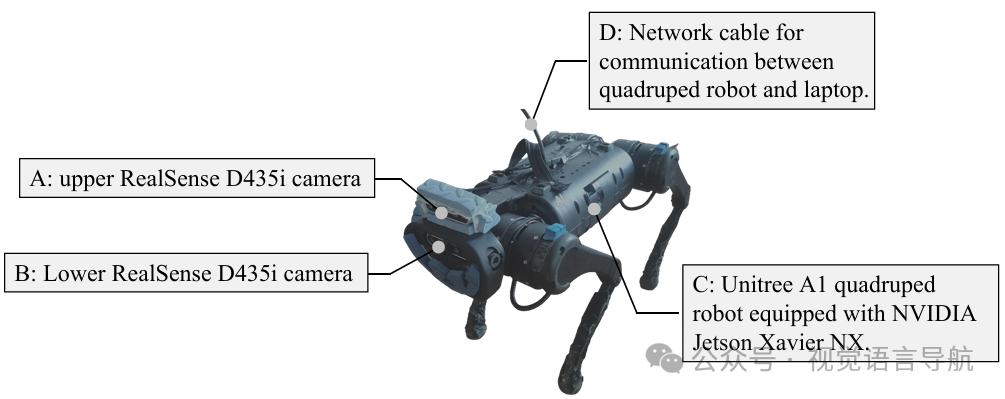
硬件配置:
-
机器人平台:实验在Unitree A1四足机器人上进行,搭载NVIDIA Jetson Xavier NX作为车载计算机。
-
传感器:机器人在前部安装了两台RealSense D435i相机,一台用于视觉惯性测距(VIO)获取机器人位姿,另一台用于高层次推理。
-
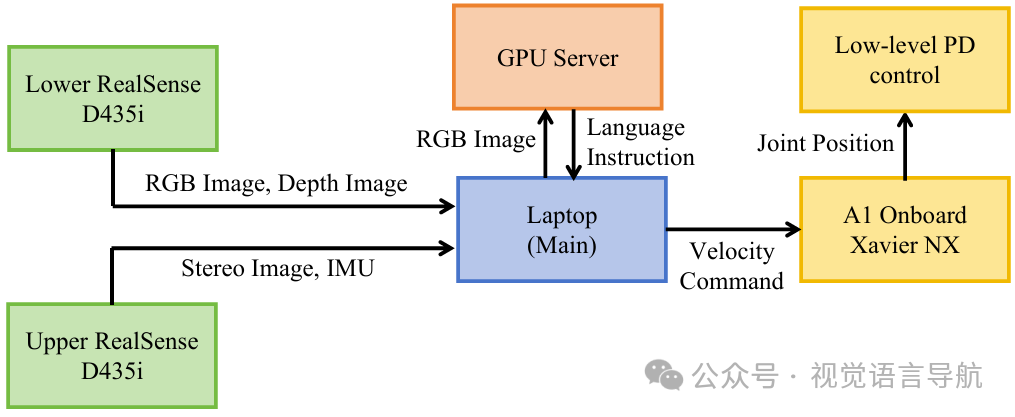
计算平台:使用一台笔记本电脑和一台GPU服务器进行计算,笔记本电脑运行SLAM程序和系统主程序,GPU服务器运行LLaVA程序并与笔记本电脑通信。
-
-
软件配置:
-
操作系统:基于ROS(机器人操作系统)进行通信。
-
VLM模型:使用LLaVA-34B作为视觉语言模型和VLM鉴别器。
-
VIO算法:使用VINS-Fusion进行视觉惯性测距。
-
高层次推理结果

-
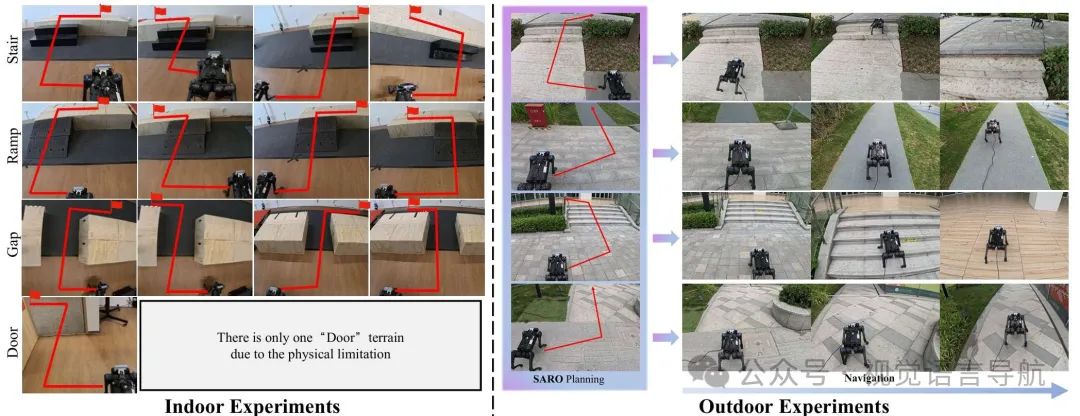
室内实验:
-
实验目标:评估SARO系统在多样化路线上的鲁棒性,测试其在不同地形(如楼梯、坡道、间隙和门)上的表现。
-
实验设计:每种地形进行20次试验,记录整个过程的成功率、仅穿越地形的成功率和稳定的定位成功率。
-
对比基线:与三种基线方法(朴素LSTM网络、ViNT和NoMaD)进行比较。
-
结果分析:SARO系统在楼梯等复杂地形上表现出色,显示出其有效性和鲁棒性。与其他基线相比,SARO系统在三维推理和规划能力上具有优势。
-
-
室外实验:
-
实验目标:展示SARO系统在野外环境中的泛化能力。
-
实验设计:在多样化地形条件下进行实验,验证系统的泛化能力。
-
结果分析:SARO系统能够轻松扩展到野外环境,并在多样化地形条件下表现出色。
-
低层次行走控制结果
-
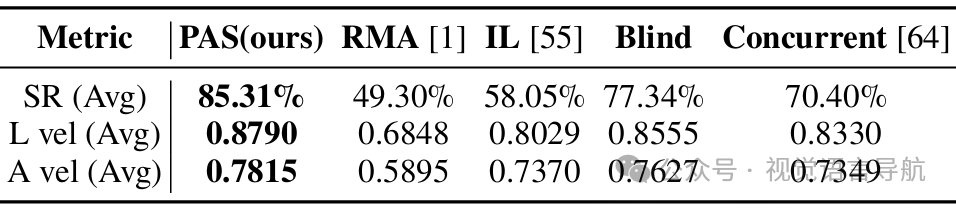
模拟实验:
-
实验目标:评估PAS方法在低层次行走控制中的效果。
-
实验设计:在多种地形上进行实验,测试成功率(SR)和速度跟踪比率。
-
对比基线:与几种基线方法(如RMA、IL、Blind、Concurrent)进行比较。
-
结果分析:PAS方法在模拟实验中显著优于其他基线方法,显示出更高的成功率和更好的速度跟踪性能。
-

-
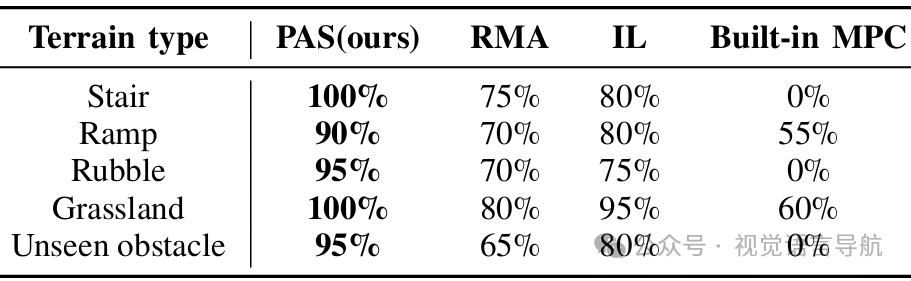
真实世界实验:
-
实验目标:在一系列地形上进行实验,验证PAS方法在实际环境中的效果。
-
实验设计:每种地形连续进行20次试验,记录成功率。
-
结果分析:PAS方法在真实世界实验中表现出色,成功率高于其他方法,显示出较强的竞争力。
-

总结
-
论文提出了一个用于3D环境视觉导航的空间感知机器人系统(SARO)。
-
高层模块通过任务分解和闭环子任务执行模块提高了3D场景理解和运动规划能力。
-
低层控制策略PAS是一种新颖的强化学习方法,能够有效地从oracle策略中学习部分策略,促进四足机器人跨越多样化的3D地形。
-
广泛的仿真和真实世界实验展示了整个系统的有效性和鲁棒性以及运动控制策略的性能。




















