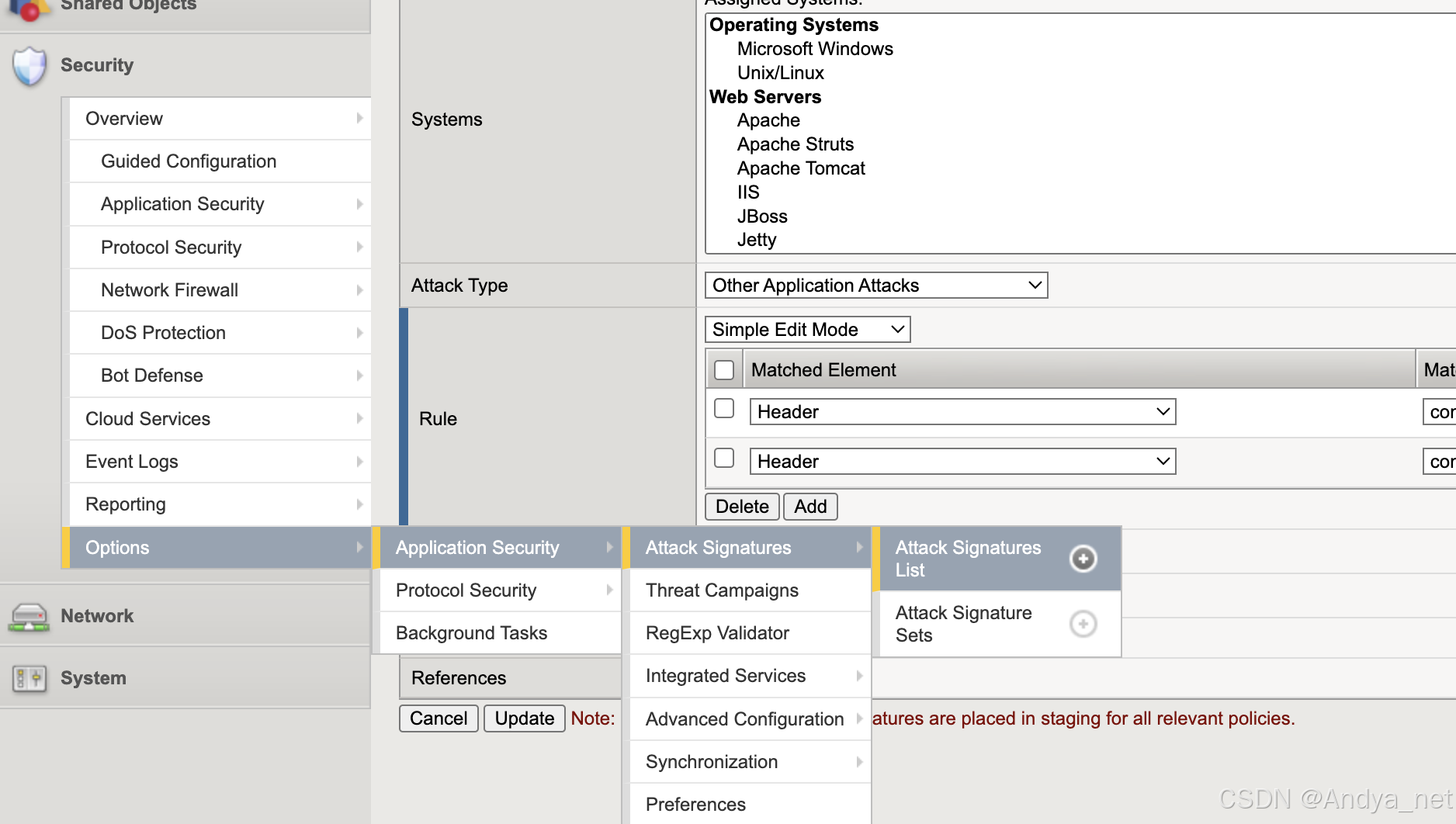
4种重定向
我们有如下的代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FILE_NAME "log.txt"
int main()
{
close(1); // 关闭标准输出
int fd = open(FILE_NAME, O_CREAT | O_WRONLY | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
return 1;
}
printf("fd:%d\n", fd);
printf("stdout->fd: %d\n", stdout->_fileno);
fflush(stdout);
close(fd);
return 0;
}
运行上面的代码之后,我们发现结果如下:


在上面的代码执行之前,文件描述符是这样的:

上面的代码执行时:

然后创建了一个 log.txt 出来,根据文件 fd的分配规则[[文件 fd#📌 fd 的分配规则]]:寻找最小的,没有被使用的数组下标分配给指定的打开文件,这里由于 1 首先被关闭了,所以 1 就是那个最小的没有被使用的数组下标了,它被分配给了 log.txt

好了,这里在说明一下:printf函数是向屏幕上打印的,Linux 下一切皆是文件,也就是说,printf 是向显示器文件里写入内容的。printf 是根据 stdout 来向显示器文件里写入内容的,而stdout这个里面有一个fileno,这个 fileno 的值是等于 1 的,这里也就可解释为什么 printf往 log.txt 里打印内容了,因为此时 log.txt的文件描述符是:1
综上所诉,重定向的本质就是修改特定文件的数组下标的内容。
fflush(stdout)是什么?
上面的代码,如果我们不加 fflush会有什么结果?我们可以试一试。
如果不加fflush 我们会发现,屏幕上不会打印任何内容,log.txt里也没有内容写入。
这个和我们的一个概念有关:用户级缓冲区,语言中提供的缓冲区


输入重定向
我们事先将log.txt中的内容修改成123 456,然后再运行下面的程序:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include<unistd.h>
#define LOG "log.txt"
int main()
{
close(0);
int fd = open(LOG, O_RDONLY);
int a, b;
scanf("%d %d", &a, &b);
printf("a = %d, b = %d\n", a, b);
return 0;
}
原理:
因为我们一开始执行了close(0)关闭文件描述符1对应的文件,其实也就是我们的stdin,那么我们再打开log.txt文件,根据文件描述符的规则:分配的是当前最小的没有被占用的文件描述符!那么我们的log.txt就顺理成章的拿到了fd = 0;这时候printf函数内部肯定是封装了操作系统接口read的,read只会根据文件描述符来区分文件,所以它默认的就是向文件描述符为0的文件中读取,所以就读取到了log.txt中的123 和 456!
输出重定向
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include<unistd.h>
#define LOG "log.txt"
int main()
{
int fd1 = open(LOG, O_CREAT | O_WRONLY | O_TRUNC, 0666);
printf("hello \n");
printf("hello \n");
printf("hello \n");
printf("hello \n");
printf("hello \n");
return 0;
}
运行结果:
我们发现printf函数运行的结果没有出现在屏幕上,而是出现在log.txt文件中。
原理:
因为我们一开始执行了close(1)关闭文件描述符1对应的文件,其实也就是我们的stdout,那么我们再打开log.txt文件,根据文件描述符的规则:分配的是当前最小的没有被占用的文件描述符。那么我们的log.txt就顺理成章的拿到了fd = 1;这时候printf函数内部肯定是封装了操作系统接口write的,write只会根据文件描述符来区分文件,所以它默认的就是向文件描述符为1的文件中写入,所以就写入到了log.txt中
追加重定向
我们只需要修改输出重定向中的代码:在open函数的参数中添加上追加的参数即可
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include<unistd.h>
#define LOG "log.txt"
int main()
{
int fd1 = open(LOG, O_CREAT | O_WRONLY | O_APPEND, 0666);
printf("hello \n");
printf("hello \n");
printf("hello \n");
printf("hello \n");
printf("hello \n");
return 0;
}
运行上面的代码,我们可以知道,内容是追加输出到文件中的。这就叫做我们的追加重定向。
重定向基本原理
根据上面的例子,我们可以知道,上层的fd 不变,底层fd指向的内容在改变,从而导致了我们输入输出的地方的改变,这就是重定向的基本原理
但是,问题来了,你看上面的代码,我们为了实现重定向,还要先close()还要指定文件的打开方式,这样也太麻烦了,有没有简单一点的方法,害,还真有!!


我们的想法是,直接把 3 号数组下标对应的内容直接拷贝到 1 号里面,

然后我们把之前的 3 号关掉,这样就重定向了呀,本来 1 是指向标准输出的,现在指向了 log.txt了

上面的操作其实就是文件描述符表级别的数组内容的拷贝,而且,我们也有这样的接口可以实现上面的功能:dup2
int dup2(int oldfd, int newfd);
dup2(要拷贝的,目的地)
这个时候出现了 2 个问题
一个上面图所示:
这个时候我们有 2 个文件描述符指向log.txt,即使一个正常使用,一个关了,这个时候也会出问题,所以我们如何在有多个指针指向log.txt的时候保证它能够正常工作呢?
所以这个时候我们要引出引用计数的概念:
atomic_long_t f_count;
f_count就是用来计数的,有几个指针指向它,f_count就是 几
以下代码我们什么也没有干,只是将文件打开后,关闭了而已。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FILE_NAME "log.txt"
int main()
{
// 打开了
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
return 1;
}
// 打印
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
// 关闭
close(fd);
return 0;
}
💥 怕你忘记,这里写一下 open 函数里面的参数的意思:
打开文件的标志:
O_WRONLY:以只写模式打开文件。如果文件已存在,可以写入数据;如果文件不存在,打开操作将失败。O_CREAT:如果文件不存在,则创建它。通常与O_WRONLY或O_RDWR一起使用。O_TRUNC:如果文件已存在,并且以写模式打开,则将文件长度截断为 0。这意味着文件中的原有内容将被删除。
文件权限:
0666:这是一个八进制数,表示文件的权限。八进制数0666对应的权限是:6(即110二进制)表示读写权限。- 第一个
6表示文件所有者(owner)的权限。 - 第二个
6表示文件所属组(group)的权限。 - 第三个
6表示其他用户(others)的权限。
因此,0666表示文件所有者、所属组和其他用户都有读写权限。
运行上面的程序,我们可以看到:

好了,基于上面的程序,我们要完成输出重定向:
我们只需要在上面的程序中加入dup2就行了,用 dup2 就可以解决多个指针同时指向 log.txt 还能让它正常工作的问题
dup2(fd, 1);
完整代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FILE_NAME "log.txt"
int main()
{
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0)
{
perror("open");
return 1;
}
dup2(fd, 1); // <-----------------------------------------------------
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
close(fd);
return 0;
}
运行之后,就没有向屏幕中输出了,而是向 log.txt这个文件中输入,因为我们改了输出的文件

文件描述符2 是干什么的?
我们知道,文件描述符 2 对应的是标准错误,标准错误是干什么的,为什么要存在标准错误呢?而且标准错误也是指向的显示器
假设我们有如下程序:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FILE_NAME "log.txt"
int main()
{
fprintf(stdout, "hello stdout\n"); //标准输出
fprintf(stderr, "hello stderr\n"); // 标准错误
return 0;
}
运行结果如下:

这个时候,我们做一个实验,我们重定向一下,把内容输出到 log.txt中:

我们发现结果很神奇:1. stderr 还是往显示器上打印的 2. stdout 的确是往 log.txt 中打印的
为啥?❓
因为,我们重定向的时候仅仅只是将标准输出重定向了,并没有将标准错误重定向。
那我们非要将标准错误也重定向到log.txt中咋办?
我们可以这样写:
./myfile > log.txt 2>&1



还有一件事,其实:./myfile > log.txt 是一种简写,完整的写法是:./myfile 1 > log.txt。
这样一来,我岂不是可以这样操作:
./myflie 1>log001.txt 2>log002.txt
就是把这个内容,一个放进 1 号里,一个放进 2 号里
回到正题,那为什么要有标准错误呢?
在我们写程序的时候,遇到报错是在正常不过的了,但是如果这个程序也有普通的打印任务,比如:要在屏幕上打印一个hello word,这个时候,我们可以将hello word 作为普通输出打印进 log001.txt中,将这个程序的错误输出放入log002.txt 中,这就是标准错误存在的意义。
📌缓冲区
🎹预备知识
什么是缓冲区?
其实就是一部分的内存
这一部分的内存是由谁提供的?
比如,我们自己写代码的时候定义的char bufer 或是 char 数组[ ] ,其实这就是我们自己定义的用户缓冲区。如果这个缓冲区是由c语言提供的,这就叫做c标准库提供的缓冲区 ,如果是操作系统提供的,那么就叫做操作系统缓冲区。我们可以简单的理解为都是
malloc出来的。
为什么要有缓冲区?
我们有这样的一段代码样例:
printf("hello linux");
sleep(3);
在sleep期间,屏幕上是不会打印 hello linux 的,但是c语言是从上往下执行的,所以当在执行sleep(3) 的时候,printf 语句是肯定已经执行过了,这个时候 hello linux 就存在于缓冲区里。
缓冲区的优点:
缓冲区的作用是提高使用者的效率
因为有缓冲区的存在,我们可以积累一部分在统一发送
提高发送的效率
缓冲区因为能够暂存数据,必定要有一定的刷新方式:
- 无缓冲(立即刷新)
- 行缓冲(行刷新)
- 全缓冲(缓冲区满了再刷新)
上面的刷新方式是一般的情况,以下是特殊情况下的刷新方式:
- 强制刷新
- 进程退出的时候,一般要进行刷新缓冲区
一般对于显示器,我们采用的刷新策略是:行刷新(行缓冲)
对于磁盘上的文件,我们采取的刷新策略是:全缓冲(缓冲区满再刷新)
🎹介绍一个样例
现在,我们要准备以下几个文件:
k``makefile``:
```makefile
myfile:myfile.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -rf myfile
myfile.c:
#include <stdio.h>
#include <unistd.h>
kude <string.h>
#include <unistd.h>
int {
fpkmain()
{
fprintf(stdout,"C:hello fprintf\n");
pputs("C: hello fputs\n",stdout);
ckrintf("C: hello printf\n");
fputs("C: hello fputs\n",stdout);
const char *str = "system call: hello wirte\n";
write(1,str,strlen(str));
return 0;
}
运行的操作:

上面,我们写了 4 个向显示器打印的语句。
接下来,我们输出重定向到log.txt 中;

上面的操作做完之后,现在 我们来开始试验,现在,我们在myfile.c 中加上一行代码;
#include <stdio.h>
#include <string.h>
#i
inknclude <unistd.h>
int main()
{
fprintf(stdout,"C:hello fprintf\n");
printf("C: hello printf\n");
fputs("C: hello fputs\n",stdout);
const char *str = "system call: hello wirte\n";
write(1,str,strlen(str));
fork(); // <---------------------------------------- 注意fork的位置
return 0;
}
加上这一句fork(); 之后,我们在把之前的执行流程重新走一遍看看有什么不同。
!k

当我们直接向显示器打印的时候,缓冲区采取的刷新方式是:行刷新,而且上面的代码中,我们每一个打印的字符的后面都是有
\n的,这说明 fork() 执行之前,上面的那些打印的语句都被刷新过了也包括 system call ,所以是一样的
\n是换行,显示器是行刷新,所以有\n就会进行行刷新

观察上面打印的结果,我么发现,只有C语言的接口被打印了2次,而系统调用接口只被打印了1次
这样的结果一定与我们在代码中添加的fork() 有关
问题是,我们的fork() 是放在代码的最后的呀,如果你这个fork()放在的是代码的最前面,这都好解释,因为,fork之后创建子进程,父子进程代码共享,会打印2次,你这里的fork 是放在代码最后的呀,fork() 之后啥都没有了;它咋还打印了呢?
当我们使用
./myfile > log.txt是输出重定向 本质是向磁盘上的文件 进行写入(不再是显示器了),而磁盘上文件默认的刷新策略是:全缓冲刷新 (缓冲区满了再刷新),全缓冲就意味着缓冲区变大,上面我们打印的语句不足以把缓冲区填满,这就意味着,fork() 执行的时候,数据依旧在缓冲区中。
我们发现,系统调用在上面进行的操作过程中都只打印了一次,这说明我们目前系统调用和缓冲区是没有关系的,是和 C 语言有关的(通过我们上面的操作推出),这就说明,我们日常用的最多的缓冲区是c/c++ 提供的语言级别的缓冲区
C/C++ 提供的缓冲区,里面一定保存的是用户的数据,那这些数据属不属于当前进程在运行时自己的数据呢?
属于
如果我们把数据交给了操作系统,那么这个数据就属于操作系统了,而不属于这个进程了
当进程退出的时候一般要进行刷新缓冲区,即使你的缓冲区没有满足刷新的条件,也是会强制刷新的,因为进程退出了。

所以当代码执行到fork()的时候 ,之后已经没有代码了,父进程已经执行结束了,要退了,所以,根据进程退出会强制刷新缓冲区,这个时候的缓冲区会被刷新。这个时候缓冲区里面存着的是前4条我们对应的语句:

问题:这里的刷新缓冲区是指的是“清空” 或是 “写入” 的操作吗?
没错,指的就是清空或者是写入的操作
当我们这里fork() 的时候,父进程要先退出了,所以要刷新缓冲区了,所以就要对缓冲区进行一种类似清空或写入的操作了,根据我们之前的所学的知识,父子进程数据是共享的,当其中一方发生数据改变时,就会发生写时拷贝,所以这个时候数据就会变成 2 份。所以log.txt 中会打印 2 份结果
我们观察一下向log.txt输出的结果

write 接口的结果只打印了一次,说明,write 系统调用接口没有使用C语言的缓冲区,它是直接把数据写入到了操作系统中了,这个时候依照我们上面所说的,这个时候的数据是属于操作系统了,不属于进程了,所以你会发现一个小细节:wirte 系统调用的打印的语句是出现在log.txt的第一行的,尽管它的代码语句是写在最后的。

观察我们之前学的一些输入输出的函数,我们可以看到都有FILE* 这样一个指针,其中FILE是一个结构体,在任何情况下,当我们输入输出的时候,都要有一个FILE 因为FILE 这个结构体里面为我们提供了一段缓冲区。
本章图集:









![83,【7】BUUCTF WEB [MRCTF2020]你传你[特殊字符]呢](https://i-blog.csdnimg.cn/direct/9c9a90c5fe0d429188b9c6a55bba53cb.png)