超越共享存储:使用 Apache Iceberg 中的 AutoMQ Table Topic 实现流处理与分析的统一
自 2023 年底官宣以来,AutoMQ 成功地将 Apache Kafka 从“Shared Nothing architecture”转变为“Shared Storage architecture”,这为京东、知乎、小红书等大型企业带来了至少 50%的成本节约。AutoMQ 的优势不仅在于成本节约,通过统一格式存储在 S3 中的数据,简化 ETL 流程,解决数据互操作性问题,特别是 2024 年 re:Invent 大会上发布的 AWS S3 Table,更提供了强力支持。本文探讨了 AutoMQ Table Topic 如何整合 AWS S3 Table 和 Apache Iceberg,实现流处理与分析的无缝统一。这一新特性帮助企业简化数据管理,提升效率,解锁数据潜力。赶快阅读本文,深入了解吧!
自 2023 年底官宣以来,AutoMQ 成功地将 Apache Kafka 从“Shared Nothing architecture”转变为“Shared Storage architecture”。这一演变利用了云计算的可扩展性、弹性和成本效益,为京东(JD.US)、知乎(ZH.US)、小红书、得物和吉利汽车(0175.HK)等大型公司带来了至少 50%的显著成本节约。共享存储架构的优势显而易见且影响深远。
然而,共享存储的好处是否仅限于成本节约?在当今数据密集型的软件环境中,数据最终存储在对象存储中。尽管在存储层上实现了收敛,不同系统由于存储格式不一致,常常在数据互操作性上遇到困难。这就需要复杂的 ETL(Extract, Transform, Load)流程来打破数据孤岛,充分利用大规模数据的潜力。
幸运的是,Apache Iceberg 已成为表格格式的事实标准,为存储在 S3(Simple Storage Service)上的数据提供了统一格式。这种标准化使不同系统间的数据交互和使用变得顺畅无阻。今天,我们正站在从共享存储到共享数据的新范式转变的边缘。
在本文中,我们探讨了 AutoMQ Table Topic 如何与 AWS(Amazon Web Services)S3 Table 和 Apache Iceberg 一起推动这一转变。通过统一流处理和分析,我们可以在数据管理中解锁前所未有的效率和能力。
Table Topic:从共享存储到共享数据的演变
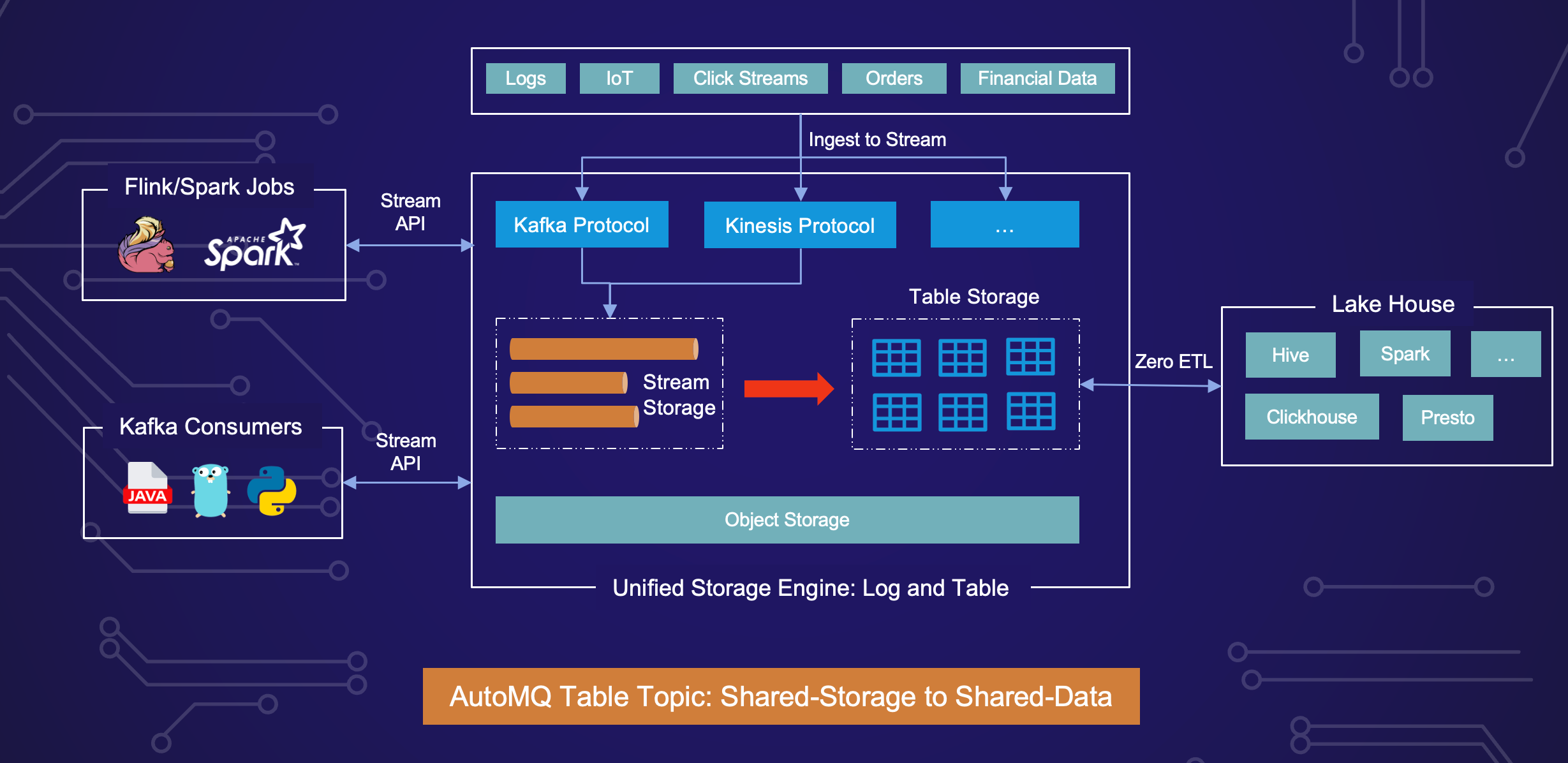
数据密集型系统的格局在这些年里发生了显著变化,通过各种架构范式的演变,以满足日益增长的数据处理和管理需求。这一演变可以大致分为三个关键阶段:无共享架构、共享存储架构和共享数据架构。
无共享架构
大约十年前,许多本地数据管理系统是采用无共享架构设计的。在这种架构中,每个节点独立运行,拥有自己的内存和磁盘,消除了任何单点争用。这种设计特别适用于需要高扩展性和故障隔离的本地环境。
无共享系统的主要优势在于其水平扩展能力,通过增加节点来处理增加的数据负载。然而,随着系统规模的扩大,确保数据一致性和协调多个节点间的操作可能变得复杂且低效。
共享存储架构
随着数据量的增加,共享无存储架构的局限性逐渐显现,促使了共享存储系统的兴起。基于云的对象存储(如 Amazon S3、Azure Blob Storage 和 Google Cloud Storage)的成熟在这一演变中起到了关键作用。
对象存储提供了巨大的可扩展性、持久性和成本效益。它能够自动将数据复制到多个位置,确保高可用性,并且几乎可以无限扩展。相比传统存储解决方案,每千兆字节的成本更低,使其成为大规模数据存储的经济选择。
这些优势推动了各行业基础软件基于共享存储架构的发展。例如,像 AutoMQ 和 WarpStream 这样的流平台,以及 Grafana 的 Tempo、Loki 和 Mimir 这样的可观测工具,都是基于对象存储构建的。这使它们能够高效管理和处理海量数据,为现代数据密集型应用提供强大、可扩展且具有成本效益的解决方案。
共享数据架构的崛起
共享数据架构是最新的演变,解决了共享无存储和共享存储架构的局限性。共享数据系统利用分布式存储和处理框架,提供即时的数据访问,使实时分析和决策成为可能。
推动这一转变的关键创新是集成了如 Apache Iceberg 这样的先进数据格式。Iceberg 支持模式演进、分区和时间旅行,使其成为管理大规模数据湖的理想选择。支持 Iceberg 的系统可以无缝处理批量和流数据,打破了实时与历史数据处理之间的壁垒。
AutoMQ 通过其 Table Topic 功能,完美展示了共享数据架构。这一功能原生支持 Apache Iceberg,使流数据可以直接被摄取到数据湖中,并实时转换为结构化的、可查询的表。Table Topic 功能弥合了批处理和流处理之间的差距,使企业能够在数据生成的同时进行分析和决策。
深入探讨 Table Topic 架构
Table Topic 是 AutoMQ 内置的一项重要功能,利用 AutoMQ 核心架构的简便性,无需额外节点。这与亚马逊 CTO Werner Vogels 提出的“简单复合性”理念完美契合。Table Topic 包含多个子模块:
模式管理:包含一个内置的 Kafka Schema Registry(一个提供 RESTful 接口用于存储和检索 Avro 模式的服务)。Kafka 客户端可以直接使用 Schema Registry 端点,它会自动与 Iceberg 的目录服务(如 AWS Glue、AWS Table Bucket 和 Iceberg Rest Catalog Service)同步 Kafka 模式。用户无需担心模式变更,因为 Table Topic 支持自动模式演进。
表协调器:每个主题都有一个表协调器,负责集中协调所有节点的 Iceberg Snapshot 提交。这显著减少了提交频率,避免了冲突和潜在的性能影响。系统的主题 __automq.table.control 会定期广播 CommitRequest 消息给工作节点。工作节点上传数据文件后,协调器执行提交并将数据提交到目录。
表工作节点:每个 AutoMQ 节点都有一个嵌入式表工作节点,负责将该节点上所有分区的数据写入 Iceberg。通过监听 CommitRequest 事件,表工作节点将表主题数据上传到数据文件。
数据提交到 Iceberg 的时间间隔是可配置的,允许用户在实时处理和成本效率之间找到平衡。建议将这个间隔设置为几分钟,以便通过 Iceberg 兼容的计算引擎进行查询。
与使用 Kafka Connect 将数据流式传输到数据湖相比,表主题具有以下主要优势:
只需一次点击:只需一次点击,即可启用 AutoMQ 表主题,轻松地将数据流传输到你的 Iceberg 表中,实现连续的实时分析。
内置 Schema Registry:内置的 Kafka Schema Registry 开箱即用。Table Topic 利用已注册的 schema 自动在您的目录服务中创建 Iceberg 表,例如 AWS Glue,并且还支持自动 schema 演进。
零 ETL:传统的数据湖引入方法通常需要 Kafka Connect 或 Flink 等工具作为中介。Table Topic 消除了这一 ETL 流水线,显著降低了成本和运营复杂性。
自动扩展:AutoMQ 本身是一种无状态且弹性的架构,允许代理无缝地扩展或缩减并动态重新分配分区。Table Topic 充分利用这一框架,轻松处理从数百 MiB/s 到数 GiB/s 的数据引入速率。
与 AWS S3 Tables 的无缝集成:Table Topic 无缝集成 S3 Tables,利用其目录服务和维护功能,如压缩、快照管理和未引用文件删除。此集成还通过 AWS Athena 促进大规模数据分析。
在 AWS Marketplace 上开始使用 Table Topic。
在本节中,我们将引导您在 AWS Marketplace 上设置和使用 AutoMQ Table Topic。我们将重点构建一个使用 AWS S3 Tables 和 AWS Athena 优化的点击流数据架构。借助 AutoMQ,我们将数据直接摄取到 S3 Table Bucket 中,免去了 ETL(提取、转换、加载)的需求,使得在 Athena 中的查询更加简便。以下是开始的步骤:
步骤 1:订阅 AutoMQ
首先,导航到[AWS Marketplace 上的 AutoMQ 页面],点击“订阅”按钮以订阅 AutoMQ。按照说明在您的 VPC(虚拟私有云)中使用 BYOC(自带云)模式安装最新版本的 AutoMQ。此过程的详细说明可在[此处]找到。
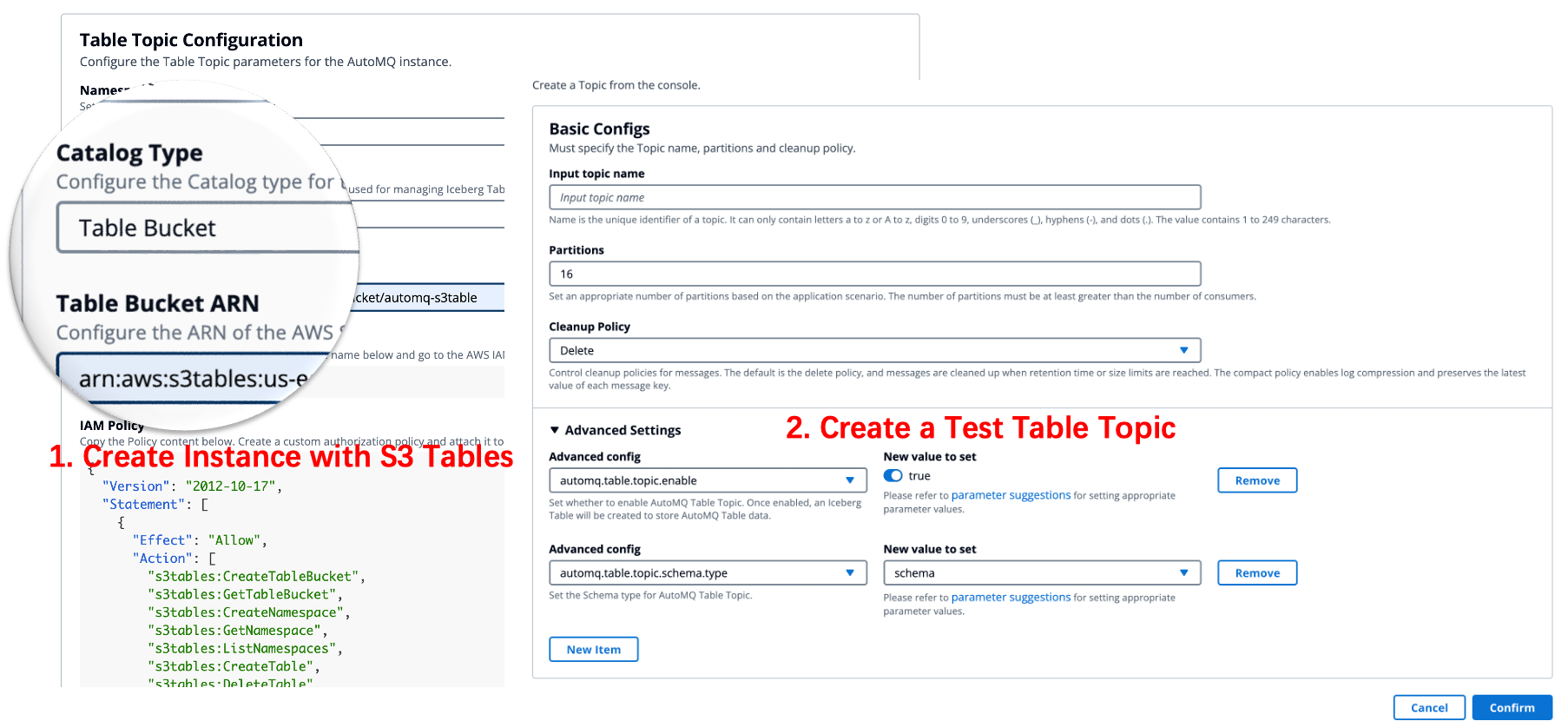
步骤 2:创建启用 Table Topic 的 AutoMQ 实例
首先,启动 AWS 管理控制台并转到 S3 服务。为存储表数据创建一个新的 S3 table bucket,并记录其 ARN(Amazon 资源名称)。
然后,使用提供的 URL 和你的凭证登录 AutoMQ BYOC 控制台。在最新版本的 AutoMQ 中,设置一个新实例,并在设置过程中将其链接到你 S3 存储桶的 ARN(Amazon Resource Name)。
实例准备好后,进入 AutoMQ BYOC 的主题部分,创建一个测试主题,并为其激活表主题功能。
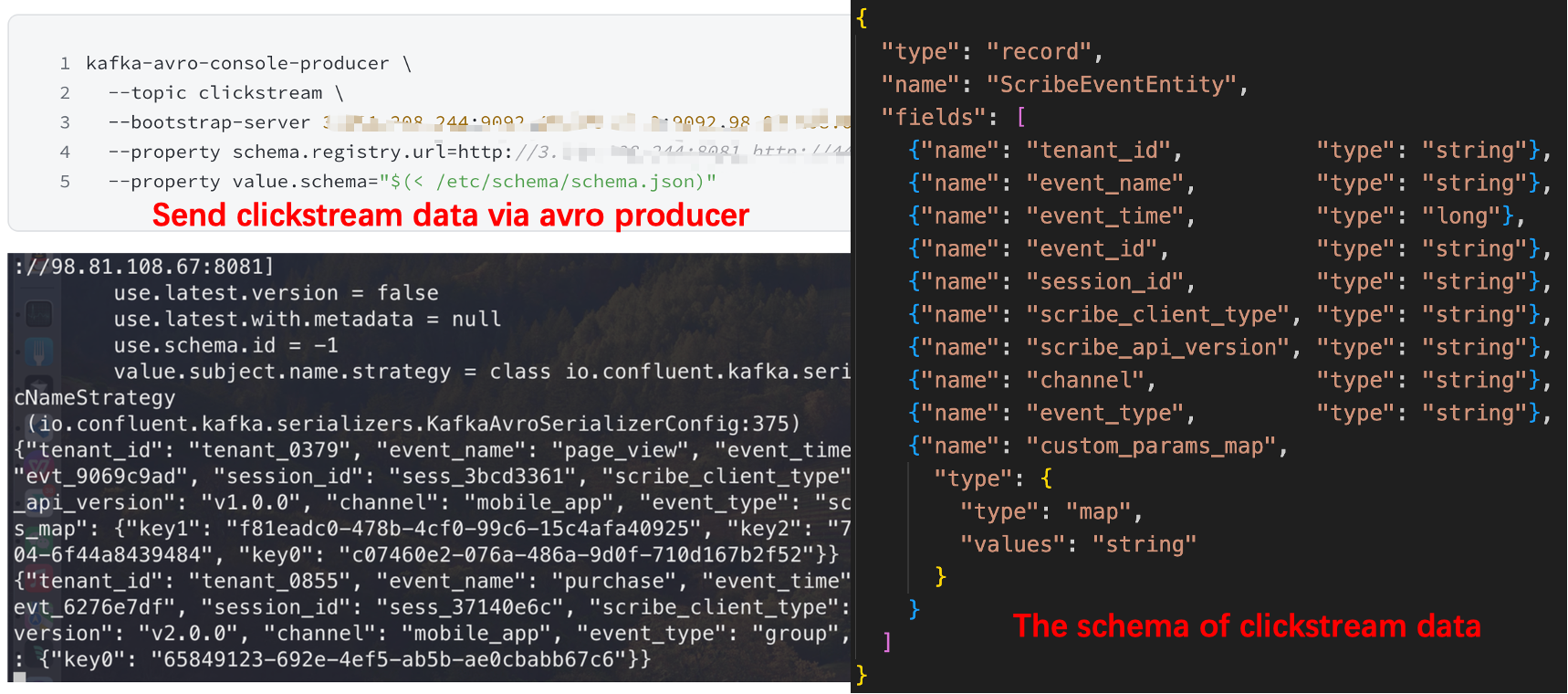
步骤三:通过 Schema 向表主题发送点击流数据
从 AutoMQ BYOC 控制台获取你的 AutoMQ 实例和 Schema Registry 的端点。使用 Kafka 客户端连接到你的 AutoMQ 实例,并将点击流数据发送到你在前一步创建的表主题。
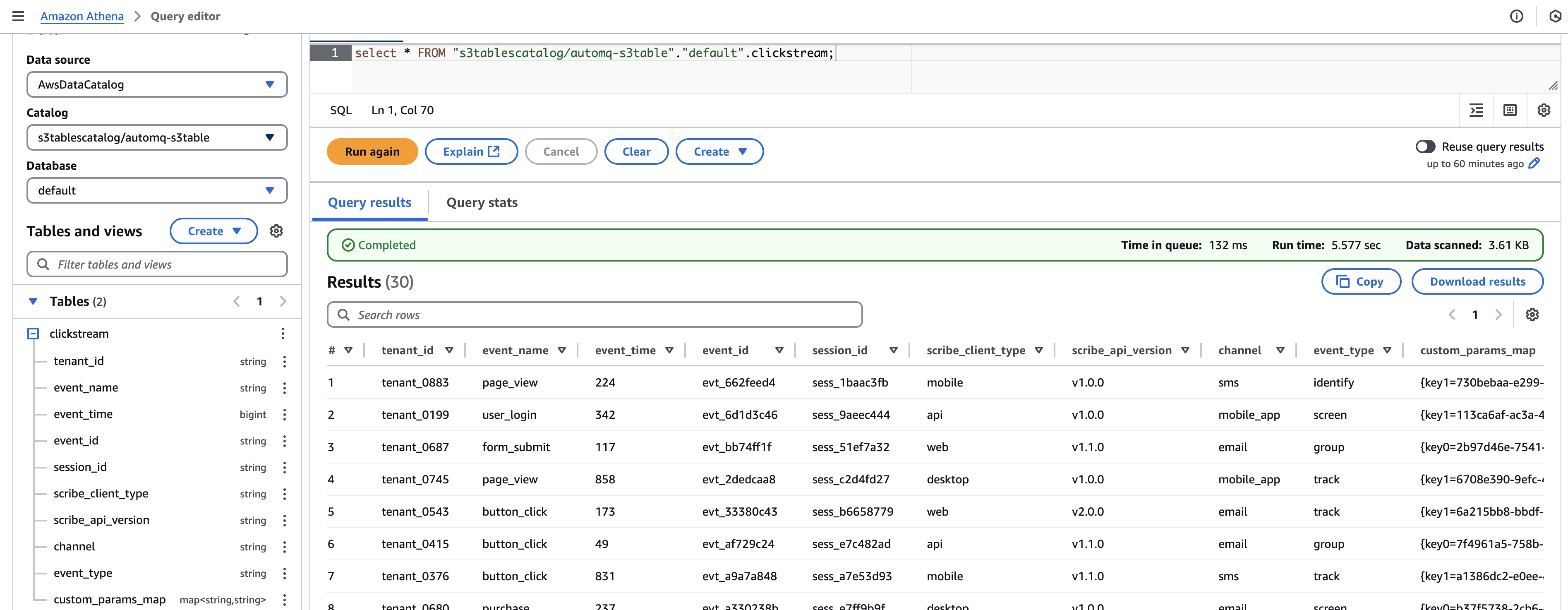
步骤四:从 AWS Athena 查询表数据
AutoMQ Table Topic 将自动在您的 AWS S3 表桶中创建表。要查询这些数据,请在 AWS Management Console 中打开 AWS Athena。使用 Athena 查询 AutoMQ 创建的表中存储的 Clickstream 数据。
结论
在本文中,我们探讨了 AutoMQ Table Topic 与 AWS S3 Tables 及 Iceberg 的无缝集成。这一强大的组合简化了数据的摄取、存储和查询,消除了复杂的 ETL(提取、转换、加载)过程的需求。
通过利用 AutoMQ 和 AWS 服务,您可以高效地管理大量数据,并轻松获得实时洞察。这种集成为您的数据需求提供了可扩展且可靠的解决方案。
我们希望本指南对您有所帮助。欲了解更多信息,请参阅“AutoMQ 文档”。感谢阅读!



















