电商数据采集可以通过多种方式完成,其中包括人工采集、使用电商平台提供的API接口、以及利用爬虫技术等自动化工具。以下是一些常用的电商数据采集方法:
人工采集:人工采集主要是通过基本的“复制粘贴”的方式在电商平台上进行数据的收集,包括商品排名、产品介绍、评论等。优点是简单直接,无需技术基础,但其缺点是效率低下,难以应对大量数据。
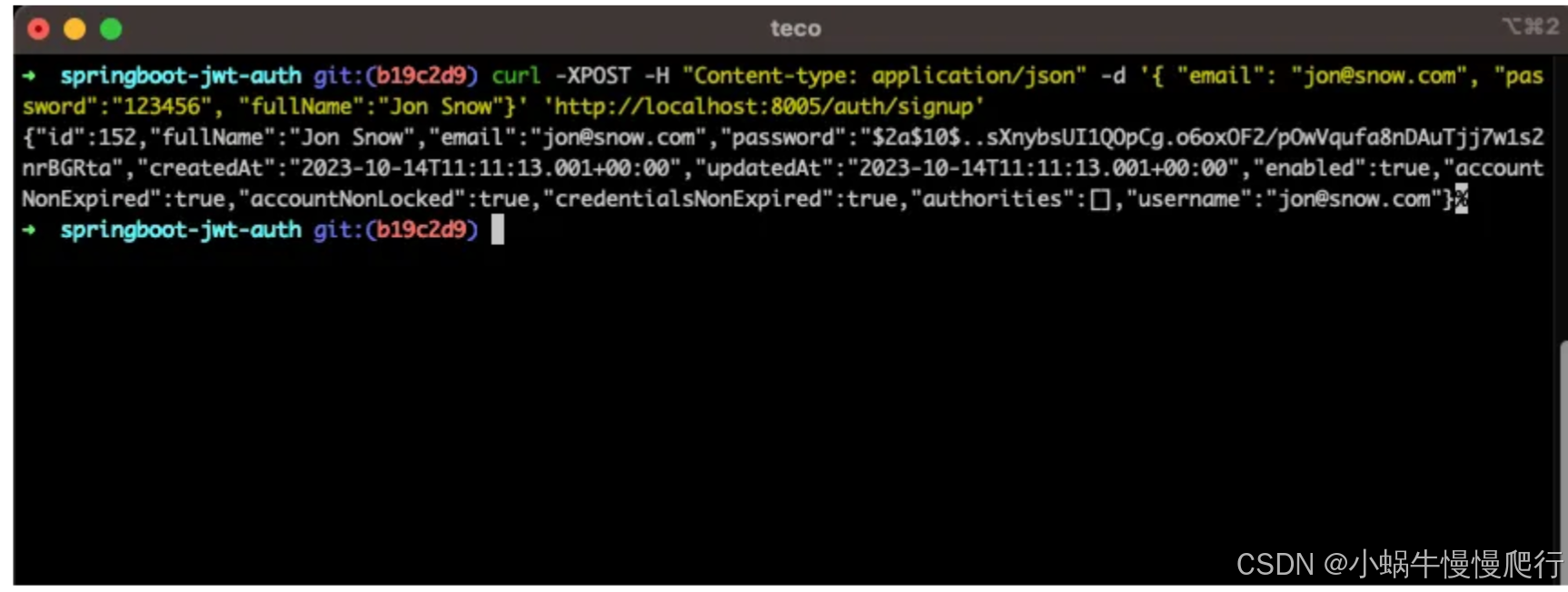
利用API接口:很多电商平台都提供了API接口,通过这些接口可以获取到电商平台上丰富的数据。优点是稳定、安全,且获取到的数据比较完整,但缺点是需要申请并获得平台的授权,流程相对复杂。
自动化采集:通过爬虫技术或RPA(机器人流程自动化)等自动化工具可以自动化地采集电商平台的数据。这种方法的优点是效率高,能够快速地抓取大量的数据,缺点是可能受到电商平台的反爬虫机制的限制,甚至有可能导致IP被封禁。
优秀的爬虫工程师在保障API的稳定性方面,需要综合考虑设计原则、性能优化、安全措施以及可维护性等多个方面。以下是一些具体的做法:
一、遵循设计原则
RESTful设计:遵循RESTful设计原则,使API易于理解、使用和维护。这包括使用统一的资源标识符(URI)来表示资源,通过HTTP动词(如GET、POST、PUT、DELETE)对资源执行操作,以及提供无状态通信等。
版本控制:加入版本控制机制,确保在升级API时不会影响到现有客户端的使用,同时也为未来的扩展提供了灵活性。
二、性能优化
缓存策略:对于频繁访问且数据更新不频繁的资源,实施缓存策略可以显著减少服务器的负载,提高响应速度。可以根据业务需求选择合适的缓存机制,如内存缓存、Redis、CDN等。
异步处理:对于耗时的数据处理任务,采用异步处理模式可以提高API的响应性能。通过异步任务队列(如RabbitMQ、Kafka)处理数据抓取、清洗等任务,主API线程可以立即返回响应给客户端,而不需要等待任务完成。
批量请求:支持批量请求可以减少网络往返次数,提高数据传输效率。设计时,应考虑如何合理地组织批量请求的数据结构,以及如何有效地处理并发请求。
三、安全措施
HTTPS协议:确保数据在传输过程中的保密性和完整性,防止被中间人攻 击和数据泄露。配置服务器使用SSL/TLS证书,强制客户端通过HTTPS进行通信,并确保证书合法并定期更新。
身份验证与授权:使用强身份验证机制,如OAuth2或JWT,确保只有授权用户才能访问API。每个请求都应该进行身份验证,并且API应该能够识别每个用户的操作权限。
数据加密:对敏感数据进行加密,无论是在传输过程中还是在数据库中存储时。使用行业标准的加密算法,如AES,确保即使数据被截获,也无法被未授权用户读取。
签名和时间戳:为每个请求生成签名,并结合时间戳来防止重放攻 击。签名可以基于请求的内容、时间戳和密钥生成,确保请求的完整性和有效性。
输入验证:对所有输入数据进行验证和净化,以防止SQL的注入、XSS和其他注入攻 击。确保输入数据符合预期格式,并清除任何潜在的恶意的代码。
限制请求频率:通过速率限制和配额管理,防止API被滥用。这有助于防止DDoS的攻 击和资源耗尽,确保API的可用性和稳定性。
四、可维护性
清晰的API文档:文档应详细说明每个API的用途、请求参数、响应格式、错误处理等信息,并提供示例代码和测试工具,帮助开发者快速上手。
模块化设计:将API的实现代码进行模块化设计,每个模块负责特定的功能或资源。这样不仅可以提高代码的可读性和可维护性,还有助于实现代码的复用。
全面的监控和日志系统:实时监控API的运行状态,及时发现并处理异常情况。同时,日志记录也为问题排查和性能优化提供了宝贵的数据支持。
综上所述,优秀的爬虫工程师在保障API的稳定性方面需要从多个方面入手,包括遵循设计原则、性能优化、安全措施以及可维护性等。这些措施的实施将有助于提高API的可靠性、安全性和易用性,从而满足业务需求并提升用户体验。