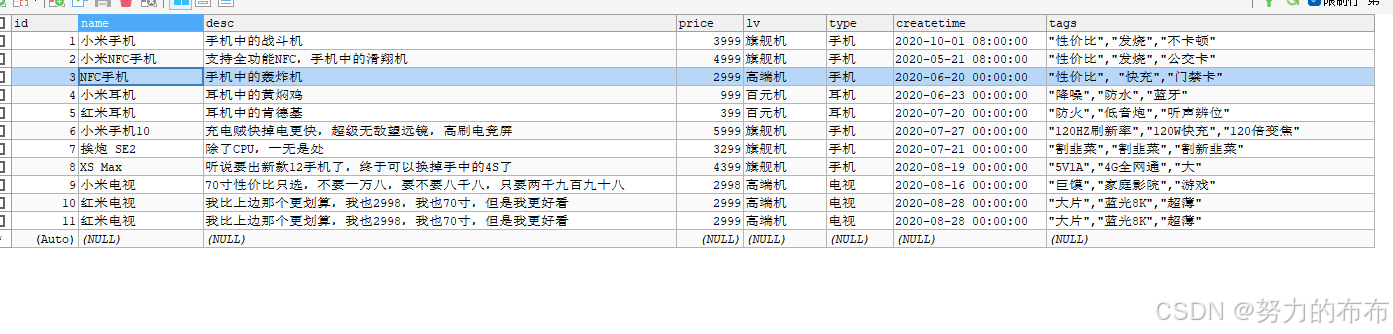
文章目录
- AI芯片常见概念
- 前言
- 常见概念
- AI芯片分类
- 按照芯片的技术架构分
- GPU
- 半定制化的 FPGA
- 全定制化 ASIC
- 神经拟态芯片
- 按应用场景分
- 训练卡
- 推理卡
- 按部署位置分
- 国产AI卡资料汇总
- 封装相关
- Chiplet技术
- 3DIC
- 三星多芯片集成联盟(Samsung Multi-Die Integration Alliance)
- 简介
- 集成方式
- 台积电(TSMC)3D Fabric
- 简介
- TSMC-SoIC
- SoIC-X chip-on-wafer
- SoIC-X wafer-on-wafer
- CoWoS
- CoWoS-S
- CoWoS-R
- CoWoS-L
- InFO
- 简介
- InFO-PoP
- InFO-oS
- Interposer、基板和转接板
- 接口相关
- D2D和C2C
- 芯片间和芯片内连接
- NVLink
- **速度更快的纵向扩展互连已成为当前的迫切需求**
- **借助 NVIDIA NVLink 技术最大化地提升系统吞吐量**
- **使用 NVIDIA NVLink 和 NVLink 交换机完全连接 GPU**
- Infinity Fabric
- UCIe
- 内存接口
- DDR
- LPDDR
- GDDR
- HBM
- 比较
- 与CPU连接
- PCIe
- CXL
- 简介
- CXL技术的三种模式:CXL.io、CXL.cache和CXL.memory
- CXL技术的三种类型
- 存算一体
- 存算一体架构的优势
- 存算一体技术分类
- **数字存算一体与模拟存算一体对比**
- **存算一体的存储介质**
- **国内主要厂商研究进展**
AI芯片常见概念
前言
最近参加了一些AI芯片开发者会议,发现现在公司的热门研究方向集中在Chiplet和存算一体上,而基于Chiplet又衍生出EDA工具、接口技术、先进封装等概念。由于对这些概念不是很清晰,所以专门调研了一下,总结成此文,希望可以为大家提供一些帮助。
常见概念
AI芯片分类
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务通常由CPU负责)。
AI芯片产品种类繁多,通常有三大分类维度: 应用场景、部署位置以及芯片架构 。
按照芯片的技术架构分
GPU
全名叫Graphics Processing Unit,即图形处理单元,在传统的冯·诺依曼结构中, CPU 每执行一条指令都需要从存储器中读取数据, 根据指令对数据进行相应的操作。 从这个特点可以看出, CPU 的主要职责并不只是数据运算, 还需要执行存储读取、 指令分析、 分支跳转等命令。深度学习算法通常需要进行海量的数据处理,用 CPU 执行算法时, CPU 将花费大量的时间在数据/指令的读取分析上, 而 CPU 的频率、 内存的带宽等条件又不可能无限制提高, 因此限制了处理器的性能。 而 GPU 的控制相对简单,大部分的晶体管可以组成各类专用电路、多条流水线,使得 GPU 的计算速度远高于 CPU; 同时,GPU 拥有了更加强大的浮点运算能力,可以缓解深度学习算法的训练难题,释放人工智能的潜能。但 GPU 无法单独工作,必须由 CPU 进行控制调用才能工作, 而且功耗比较高。
半定制化的 FPGA
全名叫Field Programmable Gate Array,即现场可编程门阵列,其基本原理是在FPGA芯片内集成大量的基本门电路以及存储器,用户可以通过更新 FPGA 配置文件来定义这些门电路以及存储器之间的连线。与 GPU 不同, FPGA 同时拥有硬件流水线并行和数据并行处理能力, 适用于以硬件流水线方式处理一条数据,且整数运算性能更高,因此,常用于深度学习算法中的推理阶段。不过 FPGA 通过硬件的配置实现软件算法,因此,在实现复杂算法方面有一定的难度。将 FPGA 和 CPU 对比可以发现两个特点, 一是 FPGA 没有内存和控制所带来的存储和读取部分,速度更快, 二是 FPGA 没有读取指令操作,所以功耗更低。 劣势是价格比较高、编程复杂、整体运算能力不是很高。 目前,国内的 AI 芯片公司如深鉴科技就提供基于 FPGA 的解决方案。
全定制化 ASIC
全名叫Application-Specific Integrated Circuit,即专用集成电路,是专用定制芯片,即为实现特定要求而定制的芯片。定制的特性有助于提高 ASIC 的性能功耗比,缺点是电路设计需要定制,相对开发周期长, 功能难以扩展。 但在功耗、可靠性、 集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。谷歌的 TPU、寒武纪的 GPU,地平线的 BPU 都属于 ASIC 芯片。谷歌的 TPU 比 CPU 和 GPU 的方案快 30 至 80 倍,与 CPU 和 GPU 相比, TPU 把控制电路进行了简化,因此,减少了芯片的面积,降低了功耗。
神经拟态芯片
神经拟态计算是模拟生物神经网络的计算机制。 神经拟态计算从结构层面去逼近大脑,其研究工作还可进一步分为两个层次,一是神经网络层面,与之相应的是神经拟态架构和处理器,如 IBM 的 TrueNorth 芯片,这种芯片把定制化的数字处理内核当作神经元,把内存作为突触。 其逻辑结构与传统冯·诺依曼结构不同:它的内存、CPU 和通信部件完全集成在一起,因此信息的处理在本地进行,克服了传统计算机内存与 CPU 之间的速度瓶颈问题。同时,神经元之间可以方便快捷地相互沟通,只要接收到其他神经元发过来的脉冲(动作电位), 这些神经元就会同时做动作。 二是神经元与神经突触层面,与之相应的是元器件层面的创新。如 IBM 苏黎世研究中心宣布制造出世界上首个人造纳米尺度的随机相变神经元,可实现高速无监督学习。
按应用场景分
根据AI算法步骤,可分为训练(training)和推理(inference)两个环节。训练卡一般都可以作为推理卡使用,而推理卡努努力不在乎时间成本的情况下大部分也能作为训练卡使用,但通常不这么做。训练芯片通常拥有更高的计算能力和内存带宽,以支持训练过程中的大量计算和数据处理。相比之下,推理芯片通常会在计算资源和内存带宽方面受到一定的限制。同时,二者支持的计算精度也通常不同,训练阶段需要高精度计算,因此常用高精度浮点数如:fp32,而推理阶段一般只需要int8就可以保证推理精度。
除了高带宽高并行度外,就片内片外的存储空间而言训练芯片通常比较“大”,这是训练过程中通常需要大量的内存来存储训练数据、中间计算结果以及模型参数。相较而言推理芯片可能无法提供足够的存储容量来支持训练过程。
训练卡
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构, 运算量巨大,需要庞大的计算规模, 对于处理器的计算能力、精度、可扩展性等性能要求很高。目前市场上通常使用英伟达的 GPU 集群来完成, Google 的 TPU 系列 、华为昇腾 910 等 AI 芯片也支持训练环节的深度网络加速。
推理卡
推理环节是指利用训练好的模型,使用新的数据去“推理”出各种结果。与训练阶段不同,推理阶段通常就不涉及参数的调整优化和反向传播了,它主要关注如何高效地将输入映射到输出。这个环节的计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。在推理环节中,除了使用 CPU 或 GPU 进行运算外, FPGA 以及 ASIC 均能发挥重大作用。典型的推理卡包括NVIDIA Tesla T4、NVIDIA Jetson Xavier NX、Intel Nervana NNP-T、AMD Radeon Instinct MI系列、Xilinx AI Engine系列等。
按部署位置分
部署位置:分为云端(数据中心)和边缘端。
云端数据中心具有强大的计算能力和海量的数据,承担模型训练以及推理任务(例如目前爆火的AIGC大模型),对AI芯片要求是高性能和高吞吐量,数据中心是目前高性能计算AI芯片核心应用场景;
边缘端则使用训练好的模型进行直接推理,更加注重实时性和低功耗,主要应用场景包括机器人、智能驾驶、手机、物联网设备等。
参考资料: HiEV洞察 | AI芯片禁令下,本土智驾承压能力全解析_文章_新出行。
国产AI卡资料汇总

封装相关
Chiplet技术
Chiplet技术是一种将不同功能模块集成在同一芯片上的方法。它通过将芯片分解为更小的、可重复使用的模块,可以灵活地组合不同的功能,实现更高效的芯片设计。Chiplet是当前芯片领域的一个热点,Chiplet是一类具有特定功能的晶片(die,也称为裸片)。这些晶片,可以是使用不同工艺节点制造,甚至是不同的半导体公司制造,可以由不同的供应商提供,可以采用不同材质(硅、砷化镣、碳化硅等)。多个Chiplet通过特定设计架构和先进封装技术,集成在一起实现完整功能,能突破目前单一芯片设计的瓶颈。和单一芯片设计模式相比,Chiplet设计模式具有更短的设计周期、更低的设计成本、更高的良率等突出优点。
Chiplet技术的优势:
- 灵活性: 可以根据不同的需求组合不同的Chiplet,实现不同的功能。
- 可重用性: Chiplet可以重复使用,减少开发成本和时间。
- 可扩展性: 可以通过增加或减少Chiplet来扩展芯片的功能。
- 可定制性: 可以根据不同的应用定制Chiplet,实现更优的性能。
Chiplet技术的挑战:
- 互连: Chiplet之间的互连需要高效的接口和协议。
- 集成: Chiplet的集成需要复杂的芯片设计工具和方法。
- 测试: Chiplet的测试需要新的测试方法和技术。

适用场景分析:通过对不同工艺(14nm、7nm、5nm)、数量(2 颗、3 颗、5 颗)、方式(SoC、MCM、InFO、2.5D)的研究,得出结论:200mm² 以下的小芯片,单一规格采用 Chiplet 技术必要性不大;而 800mm² 以上的芯片采用 Chiplet 技术收益明显。因为 800mm² 的单芯片,低良率导致的额外成本占总制造成本的 50% 以上。对于企业而言,自研全部异构小芯片封装成 SoC 可能不划算,但同构芯片合封大算力芯片则较为划算。此外,Chiplet 技术能实现高中低不同配置的芯片产品,通过小芯片的复用摊销一次性投入成本,产生巨大收益。
3DIC
随着芯片制造工艺不断接近物理极限,芯片的布局设计——异构集成的 3DIC 先进封装(以下简称“3DIC”)已经成为延续摩尔定律的最佳途径之一。三维集成电路 (3DIC) 是一种用于半导体封装的芯片堆叠技术,为半导体行业带来了新的效率、功率、性能和外形尺寸优势。3DIC 电路是在单个封装上通过晶圆彼此堆叠或芯片与晶圆堆叠而成,各层之间通过硅通孔 (TSV) 实现互连。
3DIC 将不同工艺制程、不同性质的芯片以三维堆叠的方式整合在一个封装体内,提供性能、功耗、面积和成本的优势,能够为 5G 移动、HPC、AI、汽车电子等领先应用提供更高水平的集成、更高性能的计算和更多的内存访问。然而,3DIC 作为一个新的领域,之前并没有成熟的设计分析解决方案,使用传统的脱节的点工具和流程对设计收敛会带来巨大的挑战,而对信号、电源完整性分析的需求也随着垂直堆叠的芯片设计流行而爆发式增长。

参考资料:什么是 3D-IC?| 3D-IC 技术的优势和概述 | Cadence
三星多芯片集成联盟(Samsung Multi-Die Integration Alliance)
简介
通过与三星先进晶圆代工生态系统多芯片集成(MDI)联盟的合作,三星电子晶圆代工业务(三星晶圆代工)正在建立更强大的2.5D和3D异构集成封装生态系统。
三星晶圆代工结合了EDA、IP、DSP、存储器、OSAT、基板和测试, 为尖端封装技术提供一站式封装服务。
通过该联盟,客户和合作伙伴可以实现硅片和系统级创新,同时创造下一代高性能计算(HPC)、移动和汽车产品。
- DSP: 设计解决方案合作伙伴 (Design Solution Partner)
- OSAT: 外包半导体组装和测试 (Outsourced Semiconductor Assembly and Test)
- HPC: 高性能计算 (High Performance Computing)
参考资料:SAFE™-多芯片集成(MDI)联盟 | Foundry | 三星半导体官网
集成方式
- Horizontal Integration(水平集成):包括 I-Cube 和 H-Cube 两种方式。
- I-Cube 2.5D 封装:2.5D封装技术通过并行水平芯片放置防止热量积存并扩展性能。三星以硅通孔(TSV)和后道工序(BEOL)为技术基石,整合两个以上的(不同)芯片,使之完美协作,让系统发挥1+1 > 2的功能。为现代器件的需求提供强而有力的解决方案。
- I-CUBE S:I-CUBE S 兼具高带宽和高性能的优势,即使在大中介层下,仍具有出色的翘曲控制能力。它不仅具有超低存储损失和高存储密度的特点,同时还大幅改进了热效率控制能力。 此外,I-CUBE S 是一种异构技术,将一块逻辑芯片与一组高带宽存储器 (HBM) 裸片水平放置在一个硅中介层上,实现了高算力、高带宽数据传输和低延迟等特点。
- I-Cube E :I-Cube E 技术采用硅嵌入结构,不仅具有硅桥的精细成像优势,也同时拥有PLP的技术特点:大尺寸、无无硅通孔 (TSV) 结构的RDL 中介层。
- H-Cube:H-Cube 是一种混合基底结构,将精细成像的 ABF(Ajinomoto Build-up Film)基底和 HDI(高密度互连)基底技术相结合,可在 I-Cube 2.5D 封装中实现较大的封装尺寸。




- Vertical Integration(垂直集成):包括 X-Cube 方式。
- X-Cube 3D IC:3D IC封装通过垂直堆叠的方式大幅地节省了芯片上的空间。并藉由压缩芯片之间的距离来提升性能及减少整体面积。3DIC封装技术不仅大幅降低了大芯片在结构上的风险,同时能够保持低成本、高带宽和低能耗等优势。
- X-Cube (微凸块):X-CUBE 是先进封装技术的一个巨大飞跃,这种技术采用 在 Z 轴堆叠逻辑裸片的方法,提高了动态键合能力。 凭借这些创新,三星得以快速推广其 Chip-on-Wafer和铜混合键合技术, 通过增加每个堆栈的芯片密度,进一步提升 X-CUBE 的速度或性能。
- X-Cube(铜混合键合):HCB(铜混合键合):就芯片布局灵活性的观点而言,与传统的芯片堆叠技术相比,铜混合键合技术具有极大的优势。Samsung Foundry 正在开发超精细的铜混合键合技术(例如低于 4 微米的规格)。



参考链接:
- 先进封装 | Foundry | 三星半导体官网
- 先进异构集成 | Foundry | 三星半导体官网
台积电(TSMC)3D Fabric
简介
台积电的3DFabric包括前端和后端技术。TSMC的前端技术,或者叫台积电-SoIC®(系统集成芯片),使用最先进的硅晶圆厂的精确度和方法,用于3D硅堆叠。台积电还拥有多个专门的后端晶圆厂,用于组装和测试硅芯片,包括3D堆叠芯片,并将其处理成封装设备。台积电3DFabric的后端技术包括CoWoS®和InFO系列封装技术。
参考资料:3DFabric - 台湾积体电路制造股份有限公司
TSMC-SoIC
台积电 SoIC® 服务包括半导体、存储芯片、晶圆、集成电路的定制制造,新产品开发的产品研究、定制设计与测试,以及电气和电子产品、半导体、半导体系统、半导体单元库、晶圆和集成电路的技术咨询服务。
SoIC-X chip-on-wafer
台积电 SoIC® 是什么?
台积电 SoIC® 是推进异构小芯片集成的关键技术支柱。这种集成可缩小尺寸并提升性能。台积电 SoIC® 具有超高密度垂直堆叠特性,以实现高性能、低功耗和最小的电阻 - 电感 - 电容(RLC)。
台积电 SoIC® 的主要特点:
- 异构集成(HI):将不同芯片尺寸、功能和晶圆节点技术的已知合格芯片(KGD)进行异构集成。

(a)芯片分割前的片上系统(SoC);(b)、(c)、(d)不同的台积电 SoIC® 分割小芯片及重新集成方案
- 卓越的可扩展性:凭借创新的键合方案,台积电 SoIC® 技术实现了芯片输入 / 输出(I/O)键合间距的强大扩展性,以实现高密度的芯片到芯片互连。键合间距从亚 10 微米规则起。与当前最先进的封装解决方案相比,短的芯片到芯片连接可实现更小的外形尺寸、更高的带宽、更好的电源完整性(PI)、信号完整性(SI)和更低的功耗。

- 整体 3D 系统集成:台积电 SoIC® 技术将同质和异构小芯片集成到单个类似 SoC 的芯片中,具有更小的占位面积和更薄的外形,可整体集成到先进的晶圆级系统集成(WLSI)中,即晶圆基底芯片(CoWoS®)或集成扇出型封装(InFO)。从外部看,集成芯片看起来像普通的 SoC,但内部嵌入了异构集成功能。

SoIC-X wafer-on-wafer
SoIC - X晶圆堆叠技术通过晶圆堆叠工艺实现异构和同质的3D硅集成。紧密的键合间距和薄的硅通孔(TSV)能实现最小的寄生效应,从而获得更好的性能、更低的功耗、更短的延迟以及更小的外形尺寸。SoIC - X晶圆堆叠技术适用于高良率节点以及相同芯片尺寸的应用或设计。

参考资料:TSMC-SoIC® - 台湾积体电路制造股份有限公司
CoWoS
CoWoS-S
CoWoS® - S(带有硅中介层的晶圆基底芯片)平台为人工智能(AI)和超级计算等超高性能计算应用提供了一流的封装技术。这个晶圆级系统集成平台在较大的硅中介层区域上提供高密度互连和深沟槽电容器,以容纳各种功能性顶层芯片/裸片,包括逻辑小芯片,并在其上方堆叠高带宽内存(HBM)立方体。目前,面积达3.3倍掩模版尺寸(或约2700平方毫米)的中介层已可用于生产。对于大于3.3倍掩模版尺寸的中介层,推荐使用CoWoS® - L和CoWoS® - R平台。不同的互连选项提供了更大的集成灵活性,以满足性能目标。

CoWoS-R
CoWoS® - R(带有扇出型再分布层(RDL)中介层的硅中介层晶圆基底芯片)是 CoWoS® 先进封装系列的一员,它利用 RDL 中介层作为片上系统(SoC)和 / 或高带宽内存(HBM)之间的互连来实现异构集成。RDL 中介层由聚合物和铜走线组成,相对灵活。这增强了 C4 焊点的完整性,并使封装能够扩展其尺寸以满足非常复杂的功能需求。

CoWoS® - R 的主要特点包括:
- 多达 6 层铜的 RDL 中介层用于布线,最小间距为 4 微米(线宽 / 间距为 2 微米)。
- RDL 互连通过较低 RC 值的布线提供良好的信号和电源完整性,以实现高数据传输速率。共面的地 - 信号 - 地 - 信号 - 地(GSGSG)结构以及六层 RDL 互连的层间接地屏蔽提供了卓越的电气性能。
- RDL 层和 C4 / 底部填充(UF)层由于 SoC 与相应基板之间的热膨胀系数(CTE)失配而提供了出色的缓冲。C4 凸块区域的应变能密度大大降低。

CoWoS-L
CoWoS® - L 是 CoWoS®(晶圆基底芯片)平台上的后芯片封装之一。它结合了 CoWoS® - S 和 InFO(集成扇出型封装)技术的优点,通过使用带有局部硅互连(LSI)芯片进行芯片到芯片互连以及 RDL 层进行电源和信号传输的中介层,提供了最灵活的集成方式。
CoWoS® - L 的主要特点包括:
- LSI 芯片通过多层亚微米铜线实现高布线密度的芯片到芯片互连。LSI 芯片在每个产品中可以具有多种连接架构,例如片上系统(SoC)到 SoC、SoC 到小芯片、SoC 到高带宽内存,并且可以在多个产品中重复使用。相应的金属类型、层数和间距与 CoWoS® - S 的产品一致。
- 基于模塑的中介层,在正面、背面具有宽间距的 RDL 层以及用于传输信号和电源的穿透扇出型通孔(TIV),在高速传输过程中高频信号的损耗较低。
- 能够在 SoC 芯片下方集成额外的元件,如独立嵌入式深沟槽电容器,以改善电源管理。

参考资料:CoWoS® - 台湾积体电路制造股份有限公司
InFO
简介
InFO 是一个创新的晶圆级系统集成技术平台,具有高密度再分布层(Redistribution Layer,RDL)和穿透扇出型通孔(Through InFO Vias,TI),可在包括移动和高性能计算在内的各种应用中实现高密度互连和高性能。InFO 平台提供针对特定应用优化的 2.5D 和 3D 选项。
InFO-PoP
InFO - PoP 是业界首个 3D 晶圆级扇出型封装,具有高密度 RDL 和 TIV,用于将移动应用处理器与动态随机存取存储器(DRAM)集成。InFO - PoP 比倒装芯片叠层封装具有更好的电气和热性能,且外形更薄,因为它没有有机基板或 C4 凸块。

InFO-oS
InFO - oS利用集成扇出型(InFO)技术,具有更高密度的2/2微米再分布互连(RDL)线宽/间距,用于为5G网络应用集成多个先进逻辑小芯片。它能够在片上系统(SoC)上实现混合焊盘间距,最小输入/输出(I/O)间距为36微米,最小C4铜凸块间距为130微米,并在110x110毫米基板上实现2.5倍掩模版尺寸的InFO。预计在各种下一代产品中会更多地采用小芯片封装。

参考资料:InFO (Integrated Fan-Out) Wafer Level Packaging - 台湾积体电路制造股份有限公司
Interposer、基板和转接板
- Interposer
- 定义:Interposer是一种中介层技术,用于实现芯片之间的水平互连和垂直互连。Interposer是一种中介层,常用于分布式系统中,它可以帮助上层或下层的节点之间进行信息交换(比如连接两个芯片)。Interposer通常可以使用微凸点(ubump)和C4凸点(C4 bump)与芯片、封装基板进行电性能互连,实现芯片与封装基板之间的信息交换。Interposer可以用于提高芯片的性能和带宽,以及使芯片更加紧凑。
- 功能:通常是一个薄型的硅或玻璃基板,上面布满了微凸点和再布线层(RDL),这些微凸点和RDL用于实现芯片之间的互连。
- 基板(Substrate)
- 定义:基板是制造IC的基本材料,主要用于支撑和连接电子元器件。
- 功能:基板具有导电、绝缘和支撑三个方面的功能,是电子设备中电路的重要组成部分。
- 转接板(Adapter Board)
- 定义:转接板是一种用于连接或转换不同接口或电气信号的设备。
- 功能:转接板通常由电路板、连接器和其他电子元件组成,用于将一种接口类型的信号转换为另一种接口类型的信号。
参考链接:
- 硅中介层与封装技术:从Substrate到RDLInterposer和TSV
- 什么是硅中介层 - 知乎
接口相关
D2D和C2C
随着chiplet的兴起,Die2Die的高速互联越来越重要,相比于传统的C2C(Chip2Chip)互联,D2D(Die2Die)的片间距离很近(10mm量级),且这些小的chip(裸片)终形成一个封装,即多芯片模块(MCM)。所以D2D的互联信道短,干扰和损耗小,就出现了串口和并口两种互联总线。而C2C的高速互联都是高速串口。
- C2C 互联: 在不同芯片之间的数据传输,可能位于不同封装实体中,适用于需要在不同芯片或模块间进行数据传输的场景,如服务器节点间的连接、多板卡系统或者大型电子设备中的芯片间通信。 常见的SOC上板级互联高速接口用的PCIE和XGMAC(1G MAC /10GMAC)。特别是XGMAC在车载领域用的较多,用于不同控制域之间的芯片互联,加上以太网的协议可以支持灵活的多个芯片互联。
- D2D 互联: 专注于在同一个封装体内,不同芯片裸片(Die)之间的数据传输。 适用于高性能计算(HPC)、人工智能(AI)和网络应用。D2D现在有并行和串行两种互联方案,业界巨头各有各的互联接口,但是自2022年Universal Chiplet Interconnect Express UCIE的出现【Intel、AMD、ARM、高通、三星、台积电、日月光、Google Cloud、Meta和微软等公司联合推出的Die-to-Die互连标准】,有望统一D2D的接口标准。
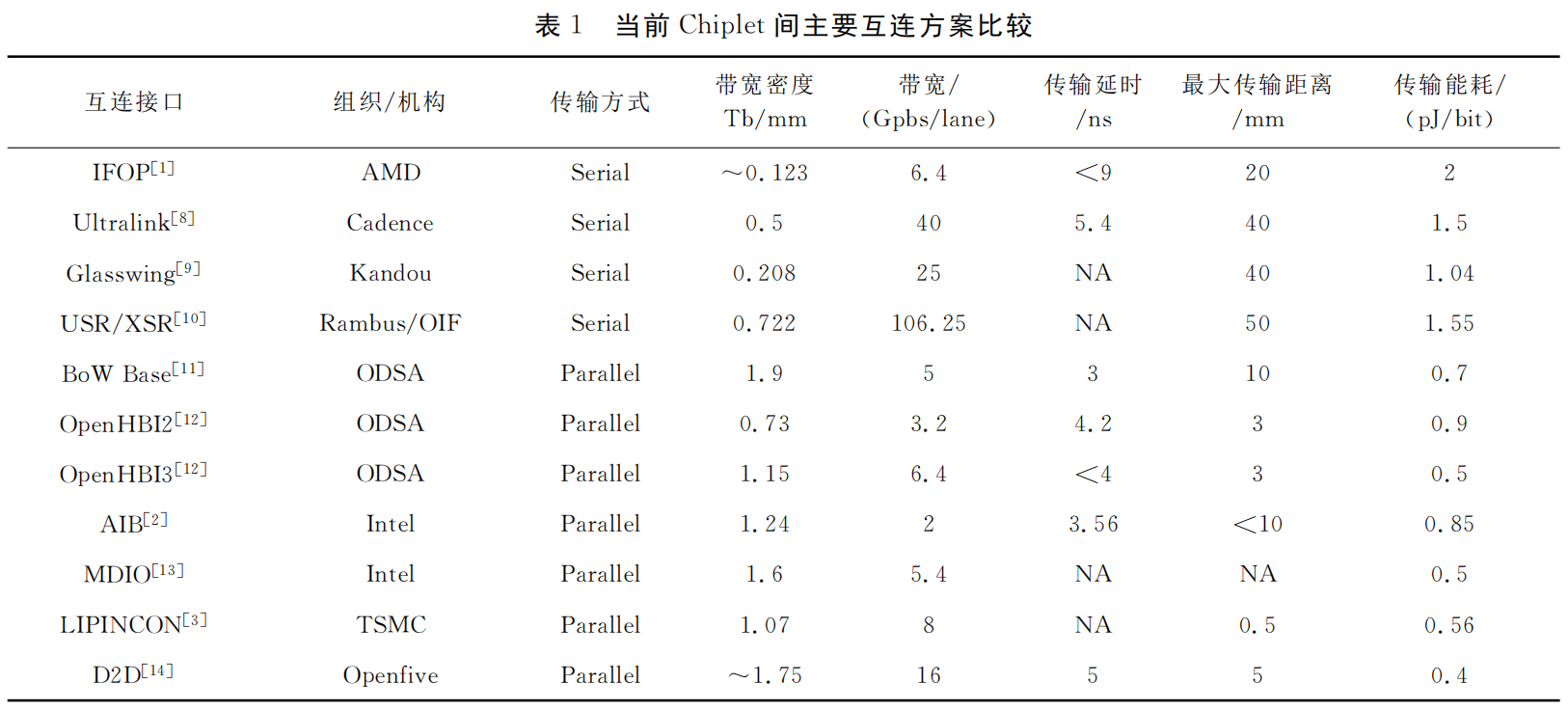
参考资料:Die2Die(D2D)和chip2chip(C2C)之间的高速互联接口
芯片间和芯片内连接
到目前为止,已经成功商用的Die-to-Die互连接口协议多达十几种,主要分为串行接口协议和并行接口协议。串行接口及协议有LR、MR、VSR、XSR、USR、PCIe、NVLink(NVIDIA),用于Cache一致性的CXL、CCIX、TileLink、OpenCAPI等;并行接口及协议有AIB/MDIO(Intel)、LIPINCON(TSMC)、Infinity Fabric(AMD)、OpenHBI(Xilinx)、BoW(OCP ODSA)、INNOLINK(Innosilicon)等。比较而言,串行接口一般延迟比较大,而并行接口可以做到更低延迟,但也会消耗更多的Die-to-Die互连管脚;而且因为要尽量保证多组管脚之间延迟的一致,所以每个管脚不易做到高速率。
NVLink
速度更快的纵向扩展互连已成为当前的迫切需求
是否能释放百亿亿次级 (Exascale) 计算和万亿参数 AI 模型的全部潜力取决于服务器集群中每个 GPU 之间能否快速、顺畅地通信。第五代 NVIDIA® NVLink® 是一种纵向扩展的互连,可为万亿和数万亿参数 AI 模型释放加速性能。
借助 NVIDIA NVLink 技术最大化地提升系统吞吐量
第五代 NVLink 大幅提高了大型多 GPU 系统的可扩展性。单个 NVIDIA Blackwell Tensor Core GPU 支持多达 18 个 NVLink 100 GB/s 连接,总带宽可达 1.8 TB/s,比上一代产品提高了两倍,是 PCIe 5.0 带宽的 14 倍之多。72-GB200 GPU NVLink 域 (NVL72) 等服务器平台利用该技术为当今异常复杂的大型模型提供更高的可扩展性。

使用 NVIDIA NVLink 和 NVLink 交换机完全连接 GPU
NVLink 是一种 GPU 之间的直接互连,双向互连速度达 1.8 TB/s,可扩展服务器内的多 GPU 输入/输出 (IO)。NVIDIA NVLink 交换机 ASIC 可连接多个 NVLink,实现在单个机架内和多个机架间以 NVLink 能够达到的最高速度进行多对多 GPU 通信。
为了支持高速集合运算,每个 NVLink 交换机都配有 NVIDIA SHARP™ 技术引擎,可用于网络内归约和组播加速。



参考资料:NVLink 和 NVSwitch:卓越的 HPC 数据中心平台 | NVIDIA
Infinity Fabric
AMD从Ryzen这代起启用了新的芯片内、外部互连:Infinity Fabric。
Infinity Fabric实际是由传输数据的Infinity Scalable Data Fabric(SDF)和负责控制的Infinity Scalable Control Fabric(SCF)两个系统组成,如果把Infinity SDF比作芯片运输数据的血管,Infinity SCF就是芯片的神经了。

SDF的设计目标是连接很多引擎的情况下,仍能保持传输数据的高拓展性。而SCF则是将不同的SoC纳入同一控制下的系统。这些SoC不仅包括桌面版的CPU Summit Ridge,还包括服务器的CPU Naples、移动版的APU Raven Ridge、以及GPU Vega系列。Ryzen以后的AMD SoC都将基于Infinity Fabric打造。
IF是将数据传输和控制集为一体的AMD自主IP,算得上是内部机密,不会对其他厂商公开规格。因为IF算是AMD为了给自家产品提供互联才开发的,但其他厂商的设计如果想获取授权,集成IF就很容易。
Infinity Fabric SDF在片上(on die)和芯片间连接(off-die**)有两个不同的系统。**片上的SDF在芯片里将CPU核心、GPU核心、IMC等连在一起,而芯片间的SDF负责在封装上将不同的die连在一起,或者多路插槽连接。
这些Infinity Fabric的逻辑层都是通用的,逻辑层协议通用了,on-die和off-die连接协议无需转换。
Infinity Fabric是具有高拓展性的协议,在一定节点数量内能保持高效率,SDF至少在64核内能保持良好的拓展性能(包括off-die)。Papermaster称双路也能带来几乎两倍的性能。
参考资料:AMD 芯片基石:Infinity Fabric解析 - MoePC
UCIe
UCIe, 即Universal Chiplet Interconnect Express,是Intel、AMD、ARM、高通、三星、台积电、日月光、Google Cloud、Meta和微软等公司联合推出的Die-to-Die互连标准,其主要目的是统一Chiplet(芯粒)之间的互连接口标准,打造一个开放性的Chiplet生态系统。UCIe在解决Chiplet标准化方面具有划时代意义。
UCIe全称Universal Chiplet Interconnect Express,协议定义了提供高带宽,低延迟,高功耗效率,低成本的芯粒(Chiplet)或者简称Die间互联的协议。
针对日益增长的高性能计算,存储,存算等领域的高带宽低延迟需求,UCIe协议定义的通用互联协议。各芯片Die间可以通过UCIe接口实现数据互通信。
目前UCIe标准规范已经进化到2.0版本。增强了链路管理,调试和测试的需求,也增加了UCIe-3D互联的支持,进一步降低了pitch间距。
作为标准接口协议,UCIe 互联协议支持多种上层协议及封包模式,包括PCIe,CXL Transaction Layer以及Stream数据模式(RAW Mode)。
UCIe标准协议展示了典型的UCIe package内互联的应用:

参考资料:UCIe 协议和背景介绍-CSDN博客
内存接口
以DDR开头的内存适用于服务器、云计算、网络、笔记本电脑、台式机和消费类应用,支持更宽的通道宽度、更高的密度和不同的形状尺寸。
以LPDDR开头的内存适合面向移动和汽车这些对规格和功耗非常敏感的领域,提供更窄的通道宽度和多种低功耗运行状态。
以GDDR开头代表的是显卡显存的参数,面向需要极高吞吐量的数据密集型应用程序,例如图形相关应用程序、数据中心加速和 AI。图形 DDR (GDDR) 和高带宽存储器 (HBM) 是这一类型的标准。

DDR
DDR是一种技术,中国大陆工程师习惯用DDR称呼用了DDR技术的SDRAM,而在中国台湾以及欧美,工程师习惯用DRAM来称呼。DDR是Double Data Rate的缩写,即“双比特翻转”。
DDR的规范名称应该为DDR SDRAM,英文全称Double Data Rate Synchronous Dynamic Random Access Memory,中文意思为双倍速率同步动态随机存储器,是在SDRAM基础上发展而来的存储器。
LPDDR
LPDDR(Low Power Double Data Rate SDRAM)低功耗双倍速率动态随机存取存储器,是DDR SDRAM的一种,是JEDEC固态技术协会(JEDEC Solid State Technology Association)面向低功耗内存而制定的通信标准,以低功耗著称,主要针对于移动端电子产品。LPDDR拥有比同代DDR内存更低的功耗和更小的体积,该类型芯片主要应用于移动式电子产品等低功耗设备上。
GDDR
GDDR是在DDR的基础上多了G(Graphics)前缀,GDDR是Graphics Double Data Rate的缩写,为显存的一种,GDDR是为了设计高端显卡而特别设计的高性能DDR存储器规格,其有专属的工作频率、时钟频率、电压,因此与市面上标准的DDR存储器有所差异,与普通DDR内存不同且不能共用。一般它比主内存中使用的普通DDR存储器时钟频率更高,发热量更小,所以更适合搭配高端显示芯片。其特点是高带宽、高延时。
当应用程序越来越多要进行3D显示及演算时,频繁地读取在显卡中的SDRAM或SGRAM保存的连续画面图像数据的速度开始不能满足需求,人们研发了GDDR,它是为了代替旧式显存的不足而出现。
HBM
HBM全称High Bandwidth Memory,和GDDR区别是采用垂直堆叠半导体工艺生产的的存储芯片,通过被称为“硅透”(TSV)的线相互连接,实现低功耗、超宽带通信通道,相比GDDR5减少了通信成本,单位带宽能耗更低,制作工艺更高,所以极大减少晶元空间。但加工成本更高。一般一个HBM内存是由4个HBM的Die堆叠形成:

比较
DDR、LPDDR和GDDR性能和功耗比较

GDDR和HBM2比较


HBM更加小巧。两者的带宽:
GDDR5:12 channel ×28GB/s = 336GB/s
HMB: 4 stack × 128 = 512GB/s

参考链接:
- DDR & LPDDR Rank 和Channel区别_lpddr channel-CSDN博客
- GDDR6 vs DDR4 vs HBM2?为什么CPU还不用GDDR?异构内存的未来在哪里?
与CPU连接
PCIe
Peripheral Component Interconnect Express,简称PCI-E,官方简称PCIe,是计算机总线的一个重要分支,它沿用既有的PCI编程概念及信号标准,并且构建了更加高速的串行通信系统标准。
PCIe保证了兼容性,支持PCI的操作系统无需进行任何更改即可支持PCIe总线。这也给用户的升级带来方便。由此可见,PCIe最大的意义在于它的通用性,不仅可以让它用于南桥和其他设备的连接,也可以延伸到芯片组间的连接,甚至也可以用于连接图形处理器,这样,整个I/O系统重新统一起来,将更进一步简化计算机系统,增加计算机的可移植性和模块化。

参考链接:PCI Express - 维基百科,自由的百科全书
CXL
简介
CXL(Compute Express Link)是一种高速串行协议,它允许在计算机系统内部的不同组件之间进行快速、可靠的数据传输。CXL在2020年推出,由英特尔、戴尔和惠普等公司共同设计。它旨在解决高性能计算中的瓶颈问题,包括内存容量、内存带宽和I/O延迟等问题。CXL还可以实现内存扩展和内存共享,并且可与计算加速器(如GPU、FPGA)等外设通信,提供更快、更灵活的数据交换和处理方式。
CXL技术不仅提供了高速传输,还支持内存共享和虚拟化,使设备之间的协作更加紧密和高效。这种技术有助于满足现代数据中心对大规模处理和分析的需求,同时也能够为AI、机器学习、区块链等新兴应用提供更好的支持。
CXL技术的三种模式:CXL.io、CXL.cache和CXL.memory
CXL协议包含三个子协议:
CXL.io:这种模式可以将内存扩展到外部设备,使得数据的传输速度更快。CXL.io通过PCIe总线连接CPU和外部设备,这样CPU就可以与外部设备共享内存,并且可以直接访问外部设备的I/O资源。
CXL.cache:这种模式可以通过将内存缓存到外部设备中来提高性能。CXL.cache模式允许CPU在本地缓存中保留最常用的数据,而将不常用的数据保存在外部设备中。这样可以减少内存访问时间,提高整体系统性能。
CXL.memory:这种模式可以将外部设备作为主内存使用,从而实现更大的内存容量。CXL.memory模式允许CPU将外部设备看作是扩展内存,从而可以存储更多的数据。这种方式可以提高系统的可靠性,因为即使发生了内存故障,CPU仍然可以通过外部设备继续运行。

CXL.io是Compute Express Link(CXL)规范中定义的物理层接口,可以提供比传统PCIe更低的延迟、更高的带宽和更好的可扩展性。
CXL.io通过使用SerDes技术(一种将串行数据转换为并行数据以及反向转换的技术),在单个物理通道上同时传输多个不同的数据流。这些数据流可以包括带宽密集型的数据流、低延迟的命令和控制信息以及配置寄存器和状态信息。CXL.io还支持热插拔和链路训练等高级特性。
CXL.io的物理层规范定义了信号的电气特性、时序要求和连接器接口,以确保高可靠性和高性能。CXL.io采用4x25Gbps或3x32Gbps的信号速率,并支持单向或双向通信。连接器方面,CXL.io采用40个针脚的SMT连接器,其中27个针脚用于数据传输,其余用于电源、地线和时钟信号。
CXL技术的三种类型
Type 1:通过 PCIe 插槽安装的加速卡或附加卡。这些卡可以与现有系统集成,并通过 CXL 接口与 CPU 直接通信以提供更快的数据传输速度。用于网卡这类高速缓存设备。
Type 2:具有所有 Type 1 设备的功能,通常用于具有高密度计算的场景。比如 GPU 加速器。
Type 3:一种专用的存储设备,与主机处理器直接通信,并且可以使用 CXL 协议来实现低延迟、高吞吐量的数据传输。用作内存缓冲器,用于扩展内存带宽和内存容量。

参考链接:什么是CXL(Compute Express Link)技术?一文读懂CXL - 知乎
存算一体
存算一体架构的优势
存算一体技术有助于解决传统冯·诺依曼架构下的“存储墙”和“功耗墙”问题。冯·诺依曼架构要求数据在存储器单元和处理单元之间不断地“读写”,这样数据在两者之间来回传输就会消耗很多的传输功耗。
根据英特尔的研究表明,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的63.7%。数据传输造成的功耗损失越来越严重,限制了芯片发展的速度和效率,形成了“功耗墙”问题。
“存储墙”是指由于存储器的性能跟不上 CPU 的性能,导致 CPU 需要花费大量的时间等待存储器完成读写操作,从而降低了系统的整体性能。“存储墙”成为了数据计算应用的一大障碍。特别是,深度学习加速的最大挑战就是数据在计算单元和存储单元之间频繁的移动。
存算一体的优势便是打破存储墙,消除不必要的数据搬移延迟和功耗,并使用存储单元提升算力,成百上千倍的提高计算效率,降低成本。
存算一体属于非冯·诺伊曼架构,在特定领域可以提供更大算力(1000TOPS以上)和更高能效(超过10-100TOPS/W),明显超越现有ASIC算力芯片。除了用于AI计算外,存算技术也可用于感存算一体芯片和类脑芯片,代表了未来主流的大数据计算芯片架构。
存算一体技术分类
目前,存算一体的技术路径尚未形成统一的分类,目前主流的划分方法是依照计算单元与存储单元的距离,将其大致分为近存计算(PNM)、存内处理(PIM)、存内计算(CIM)。
近存计算是一种较为成熟的技术路径。它利用先进的封装技术,将计算逻辑芯片和存储器封装到一起,通过减少内存和处理单元之间的路径,实现高I/O密度,进而实现高内存带宽以及较低的访问开销。近存计算主要通过2.5D、3D堆叠等技术来实现,广泛应用于各类CPU和GPU上。
存内处理则主要侧重于将计算过程尽可能地嵌入到存储器内部。这种实现方式旨在减少处理器访问存储器的频率,因为大部分计算已经在存储器内部完成。这种设计有助于消除冯·诺依曼瓶颈带来的问题,提高数据处理速度和效率。
存内计算同样是将计算和存储合二为一的技术。它有两种主要思路。第一种思路是通过电路革新,让存储器本身就具有计算能力。这通常需要对SRAM或者MRAM等存储器进行改动,以在数据读出的decoder等地方实现计算功能。这种方法的能效比通常较高,但计算精度可能受限。另一种思路是在存储器内部集成额外的计算单元,以支持高精度计算。这种思路主要针对DRAM等主处理器访问开销大的存储器,但DRAM工艺对计算逻辑电路不太友好,因此集成计算单元的挑战较大。
存内计算也就是国内大部分初创公司所说的存算一体。
值得注意的是,不同的公司在这一领域的研发与实践中,各自选择了不同的赛道进行押注。有的公司侧重于优化存储与计算之间的协同效率,力求在大数据处理上实现质的飞跃;而另一些公司则更注重架构的灵活性和扩展性,以适应不断变化的市场需求。
此外,存算一体依托的存储介质也呈现多样化,比如以SRAM、DRAM为代表的易失性存储器、以Flash为代表的非易失性存储器等。综合来看,不同存储介质各有各的优点和短板。
数字存算一体与模拟存算一体对比
存算一体的计算方式分为数字计算和多比特模拟计算。
数字存算一体主要以SRAM和RRAM作为存储器件,采用先进逻辑工艺,具有高性能高精度的优势,且具备很好的抗噪声能力和可靠性。
而模拟存算一体通常使用FLASH、RRAM、PRAM等非易失性介质作为存储器件,存储密度大,并行度高,但是对环境噪声和温度非常敏感。例如Intel和NVIDIA的算力芯片,尽管也可采用模拟计算技术提升能效,但从未有一颗大算力芯片采用模拟计算技术。
数字存算一体适合大算力高能效的商用场景,而模拟存算一体适合小算力、不需要可靠性的民用场景。
存算一体的存储介质
目前可用于存算一体的成熟存储器有NOR FLASH、SRAM、DRAM、RRAM、MRAM等NVRAM。
早期创业企业所用FLASH属于非易失性存储介质,具有低成本、高可靠性的优势,但在工艺制程有明显的瓶颈。
SRAM在速度方面和能效比方面具有优势,特别是在存内逻辑技术发展起来之后具有明显的高能效和高精度特点。
DRAM成本低,容量大,但是速度慢,且需要电力不断刷新。
适用存算一体的新型存储器有PCAM、MRAM、RRAM和FRAM等。其中忆阻器RRAM在神经网络计算中具有特别的优势,是除了SRAM存算一体之外的,下一代存算一体介质的主流研究方向。目前RRAM距离工艺成熟还需要2-5年,材料不稳定,但RRAM具有高速、结构简单的优点,有希望成为未来发展最快的新型存储器。
从学术界和工业界的研发趋势上看,SRAM和RRAM都是未来主流的存算一体介质。
| 存储器类型 | 优势 | 不足 | 适合场景 |
|---|---|---|---|
| SRAM(数字模式) | 能效比高,高速高精度,对噪声不敏感,工艺成熟先进,适合IP化 | 存储密度略低 | 大算力、云计算、边缘计算 |
| SRAM(模拟模式) | 能效比高,工艺成熟先进 | 对PVT变化敏感,对信噪比敏感,存储密度略低 | 小算力、端侧、不要求待机功耗 |
| 各类NVRAM(包括RRAM/MRAM等) | 能效比高,高密度,非易失,低漏电 | 对 PVT变化敏感,有限写次数,相对低速,工艺良率尚在爬坡中 | 小算力、端侧/边缘Inference、待机时间长的场景 |
| Flash | 高密度低成本,非易失,低漏电 | 对 PVT变化敏感,精度不高,工艺迭代时间长 | 小算力、端侧、低成本、待机时间长的场景 |
| DRAM | 高存储密度,整合方案成熟 | 只能做近存计算,速度略低,工艺迭代慢 | 适合现有冯氏架构向存算过渡 |

国内主要厂商研究进展


参考资料:
- 存算一体芯片,实打实的火了 - 与非网
- 存算一体技术是什么?发展史、优势、应用方向、主要介质-知乎