一、禁用元数据和过滤数据
1、禁用元数据_source
GET product/_search
{
"_source": false,
"query": {
"match_all": {}
}
}
查询结果不显示元数据
禁用之前:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"date" : "2021-06-01",
"price" : 3999,
"tags" : [
"xingjiabi",
"fashao",
"buka"
]
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "xiaomi nfc phone",
"desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji",
"date" : "2021-06-02",
"price" : 4999,
"tags" : [
"xingjiabi",
"fashao",
"gongjiaoka"
]
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "nfc phone",
"desc" : "shouji zhong de hongzhaji",
"date" : "2021-06-03",
"price" : 2999,
"tags" : [
"xingjiabi",
"fashao",
"menjinka"
]
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "xiaomi erji",
"desc" : "erji zhong de huangmenji",
"date" : "2021-04-15",
"price" : 999,
"tags" : [
"low",
"bufangshui",
"yinzhicha"
]
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "hongmi erji",
"desc" : "erji zhong de kendeji 2021-06-01",
"date" : "2021-04-16",
"price" : 399,
"tags" : [
"lowbee",
"xuhangduan",
"zhiliangx"
]
}
}
]
}
}
禁用之后:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0
}
]
}
}
2、数据源过滤器
Including:结果中返回哪些field
Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表索引不存在
两种实现方式,
1:在创建索引的时候,mapping中配置;
这样配置映射,在查询的时候只显示name和price,不显示desc和tags
PUT product2
{
"mappings": {
"_source": {
"includes": [
"name",
"price"
],
"excludes": [
"desc",
"tags"
]
}
}
}
查看映射信息:GET product2/_mapping
{
"product2" : {
"mappings" : {
"_source" : {
"includes" : [
"name",
"price"
],
"excludes" : [
"desc",
"tags"
]
},
"properties" : {
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"owner" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"price" : {
"type" : "long"
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
插入数据:
PUT /product2/_doc/1
{
"owner":{
"name":"zhangsan",
"sex":"男",
"age":18
},
"name": "hongmi erji",
"desc": "erji zhong de kendeji",
"price": 399,
"tags": [
"lowbee",
"xuhangduan",
"zhiliangx"
]
}
查询数据:
GET product2/_search
可以看到查询的结果没有上面excludes的数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"price" : 399,
"name" : "hongmi erji"
}
}
]
}
}
2:在写get search查询的时候指定;
基于上面的测试数据,先DELETE product2删除索引 再重新PUT /product2/_doc/1创建索引直接自动映射。
两种写法:
1.“_source”: 直接写展示的字段,
只展示owner.name和owner.sex
GET product2/_search
{
"_source": ["owner.name","owner.sex"],
"query": {
"match_all": {}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"owner" : {
"sex" : "男",
"name" : "zhangsan"
}
}
}
]
}
}
2.source里用includes和excludes
GET product2/_search
{
"_source": {
"includes": [
"owner.*",
"name"
],
"excludes": [
"name",
"desc",
"price"
]
},
"query": {
"match_all": {}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"owner" : {
"sex" : "男",
"name" : "zhangsan",
"age" : 18
}
}
}
]
}
}
二、query string search
1.查看索引的结构
GET product/_mapping
2.查询索引的数据 默认10条
GET product/_search
3.查询索引的数据 限制条数20条
GET /product/_search?size=20
4.查询name分词后含有nfc的数据
GET /product/_search?q=name:nfc
5.查询前20条数据并且按照价格降序排列
GET /product/_search?from=0&size=20&sort=price:desc
6.createtime的数据类型是date,不会索引,所以这里是精准匹配createtime:2020-08-19的数据
GET /product/_search?q=createtime:2020-08-19
7.查询所有text分词后的词条中包含炮这个单词的
GET /product/_search?q=炮
三、全文检索-Fulltext query
查询模板:
GET index/_search
{
"query": {
"match": {
"field": "searchContent"
}
}
}
造测试数据:
put mapping 就像关系型数据库的表结构:ddl语句
PUT product
{
"mappings" : {
"properties" : {
"createtime" : {
"type" : "date"
},
"date" : {
"type" : "date"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"analyzer":"ik_max_word"
},
"lv" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"analyzer":"ik_max_word",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "long"
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
插入数据:就像关系型数据库的insert
PUT /product/_doc/1
{
"name" : "小米手机",
"desc" : "手机中的战斗机",
"price" : 3999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-10-01T08:00:00Z",
"tags": [ "性价比", "发烧", "不卡顿" ]
}
PUT /product/_doc/2
{
"name" : "小米NFC手机",
"desc" : "支持全功能NFC,手机中的滑翔机",
"price" : 4999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-05-21T08:00:00Z",
"tags": [ "性价比", "发烧", "公交卡" ]
}
PUT /product/_doc/3
{
"name" : "NFC手机",
"desc" : "手机中的轰炸机",
"price" : 2999,
"lv":"高端机",
"type":"手机",
"createtime":"2020-06-20",
"tags": [ "性价比", "快充", "门禁卡" ]
}
PUT /product/_doc/4
{
"name" : "小米耳机",
"desc" : "耳机中的黄焖鸡",
"price" : 999,
"lv":"百元机",
"type":"耳机",
"createtime":"2020-06-23",
"tags": [ "降噪", "防水", "蓝牙" ]
}
PUT /product/_doc/5
{
"name" : "红米耳机",
"desc" : "耳机中的肯德基",
"price" : 399,
"type":"耳机",
"lv":"百元机",
"createtime":"2020-07-20",
"tags": [ "防火", "低音炮", "听声辨位" ]
}
PUT /product/_doc/6
{
"name" : "小米手机10",
"desc" : "充电贼快掉电更快,超级无敌望远镜,高刷电竞屏",
"price" : "",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-27",
"tags": [ "120HZ刷新率", "120W快充", "120倍变焦" ]
}
PUT /product/_doc/7
{
"name" : "挨炮 SE2",
"desc" : "除了CPU,一无是处",
"price" : "3299",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-21",
"tags": [ "割韭菜", "割韭菜", "割新韭菜" ]
}
PUT /product/_doc/8
{
"name" : "XS Max",
"desc" : "听说要出新款12手机了,终于可以换掉手中的4S了",
"price" : 4399,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-08-19",
"tags": [ "5V1A", "4G全网通", "大" ]
}
PUT /product/_doc/9
{
"name" : "小米电视",
"desc" : "70寸性价比只选,不要一万八,要不要八千八,只要两千九百九十八",
"price" : 2998,
"lv":"高端机",
"type":"耳机",
"createtime":"2020-08-16",
"tags": [ "巨馍", "家庭影院", "游戏" ]
}
PUT /product/_doc/10
{
"name" : "红米电视",
"desc" : "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price" : 2999,
"type":"电视",
"lv":"高端机",
"createtime":"2020-08-28",
"tags": [ "大片", "蓝光8K", "超薄" ]
}
PUT /product/_doc/11
{
"name": "红米电视",
"desc": "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price": 2998,
"type": "电视",
"lv": "高端机",
"createtime": "2020-08-28",
"tags": [
"大片",
"蓝光8K",
"超薄"
]
}
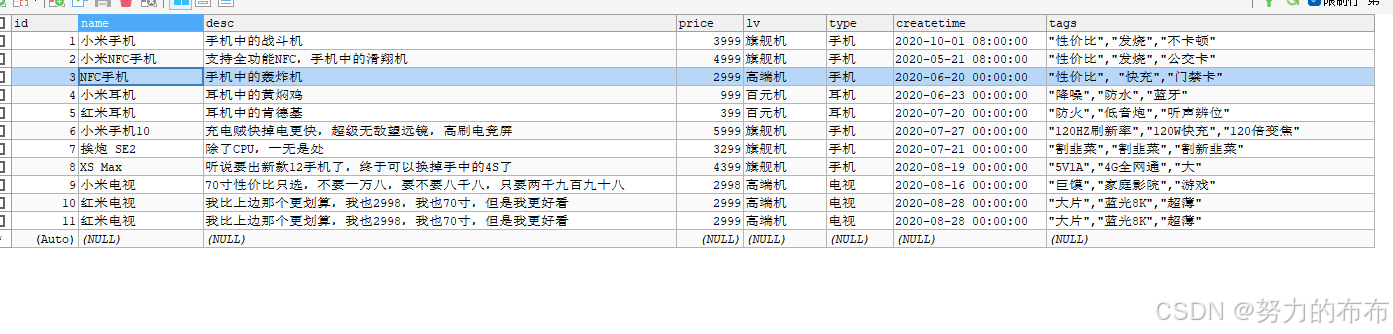
在构造mapping映射的时候,对text类型的字段指定了"analyzer":"ik_max_word"分词器,这里用的是IK分词器,插入数据会对该字段进行分词,建立倒排索引。*“type” : “keyword”*是用来后续精准查询的时候通过field.keyword来精准匹配。
1、query->match->text类型字段
进行全文搜索,会对查询的文本进行分词。
query match 这个name会被分词 name是txt类型 会被分词 所以搜索条件被分词后会和这个查询字段的词项进行匹配 匹配到的都返回
查询条件和索引中的字段数据都会进行分词 后 进行匹配 按照score返回
GET product/_search?_source=false
{
"query": {
"match": {
"name": "NFC手机"
}
}
}
query->match->text.keyword类型字段
name是text类型字段,name.keyword做为查询条件不会进行分词,直接和索引数据中的name进行匹配,id为3的数据可以查询匹配。
GET product/_search
{
"query": {
"match": {
"name.keyword": "NFC手机"
}
}
}
2、query->match_all查询全部数据
默认查询返回10条,这里指定20条,禁用元数据不返回太多
GET product/_search?size=20&_source=false
{
"query": {
"match_all": {
}
}
}
3、query->multi_match 多个字段匹配
多个字段匹配 name或者desc 包含 query中的任意一个就行,name或者desc分词后的数据包含手机就返回
GET product/_search?size=20&_source=false
{
"query": {
"multi_match": {
"query": "手机",
"fields": ["name","desc"]
}
}
}
4、query->match_phrase 短语查询
搜索与指定短语匹配的文档,保留短语中词语的相对位置。
name的分词器是ik_max_word,看下name会被分为哪些词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "小米NFC手机"
}
结果:
{
"tokens" : [
{
"token" : "小米",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "nfc",
"start_offset" : 2,
"end_offset" : 5,
"type" : "ENGLISH",
"position" : 1
},
{
"token" : "手机",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 2
}
]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "NFC手机"
}
结果:
{
"tokens" : [
{
"token" : "nfc",
"start_offset" : 0,
"end_offset" : 3,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "手机",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
}
]
}
短语查询 索引里面name字段要有NFC手机这个短语 顺序不能颠倒,NFC手机会被分为nfc 手机
分词后能和索引字段name分词后的数据匹配到且顺序不乱 就可以做为结果展示
GET product/_search
{
"query": {
"match_phrase": {
"name": "NFC手机"
}
}
}
结果:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.8616219,
"hits" : [
{
"_index" : "product",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.8616219
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.4492486
}
]
}
}
5、Term 对字段进行精确匹配。
GET /my_index/_search
{
"query": { // "query"定义查询条件
"term": { // "term"查询执行精确匹配
"field_name": "exact_value"
// "field_name"是要匹配的字段; "exact_value"是精确查询的精确值,通常用于keyword标签或其他不分析的文本字段
}
}
}
6、Bool 多条件组合查询
组合多个查询条件,支持must(必须)、should(至少一个)和must_not(必须不)关键字。
match支持全文检索,对查询条件分词然后匹配索引中的分词后的词项
term精准查询,不会分词检索,和非text类型或者text.keyword使用
range gte大于等于lte小于等于
minimum_should_match should默认至少满足一个,这里表示至少满足的数量自己控制
GET product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "手机"
}
},
{
"match": {
"desc": "手机"
}
}
],
"should": [
{
"term": {
"type.keyword": {
"value": "手机"
}
}
},
{
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
],
"minimum_should_match": 2,
"must_not": [
{
"range": {
"price": {
"gte": 2999,
"lte": 4500
}
}
}
]
}
}
}
filter:条件过滤查询,过滤满足条件的数据 不计算相关度得分
GET product/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"type.keyword": {
"value": "手机"
}
}
}
]
}
}
}
7、terms
索引中tags含有性价比或者大片任意一个就行
GET product/_search
{
"query": {
"terms": {
"tags.keyword": [ "性价比", "大片" ],
"boost": 2.0
}
}
}
8、constant_score 意为固定得分
避免算分 提高性能
GET product/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"type.keyword": "手机"
}
},
"boost": 1.2
}
}
}
9、(must或者filter)和should组合 这时should满足0也行 如果should单用 要至少满足一个
GET product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 10,
"lte": 4000
}
}
}
],"should": [
{
"match": {
"name": "哈哈哈哈哈哈哈哈哈哈哈哈"
}
},{
"range": {
"price": {
"gte": 4001,
"lte": 9000
}
}
}
],
"minimum_should_match": 1
}
}
}
minimum_should_match不设置或者设置为0,即使should两个条件一个都不符合也可以查出数据