机器学习预处理-表格数据的分析与可视化
最近在做一些模型部署的工作,但是发现对于数据的处理、分析、训练方面还是缺少一些系统的学习,因此抽空余时间分析总结一些使用python进行数据处理的实用案例,希望能够方便自己已经其他人的Ctrl C+V。
之前做稠密(表格)数据的处理都是使用一些现有的分析软件去做(如SPSS),学习成本低但是自由度比较受限,此处介绍使用python的处理。
此处的数据分析部分参考博客:【机器学习】最经典案例:房价预测(完整流程:数据分析及处理、模型选择及微调)
本文的数据集和代码下载:机器学习预处理-表格数据的分析与可视化-数据集和python文件
目录
- 机器学习预处理-表格数据的分析与可视化
- 1、数据下载
- 2、数据查看
- 2.1、查看表格数据头和数据案例
- 2.2、总体查看数据大小、数据类型和空缺情况
- 2.3、查看数值属性列的均值、最小最大值等信息
- 2.4、绘制每列数据的分布情况
- 2.5、绘制多维数据关系
- 2.6、绘制两两间互相关关系图
- 2.7、绘制相关性系数热力图
- 3、代码
- 3.1、01LoadDataSet.py
- 3.2、02DataView.py
1、数据下载
(01LoadDataSet.py)
运行下面代码即可自动下载数据集(经典房价数据),但是由于目标的url在国外地址,可能需要科学上网工具,代码会自动下载数据集并解压:
import os
import tarfile
from urllib import request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"#网址位置
HOUSING_PATH = os.path.join("datasets", "housing")#存储位置
def fetch_housing_data(housing_url = HOUSING_URL, housing_path = HOUSING_PATH):
os.makedirs(housing_path, exist_ok = True)
tgz_path = os.path.join(housing_path, "housing.tgz")
request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path = housing_path)#解压
housing_tgz.close()
fetch_housing_data()
下载得到的为tgz压缩格式,进行解压即可得到原始数据的csv格式

2、数据查看
(02DataView.py)
2.1、查看表格数据头和数据案例
运行下面代码,会打印表格csv数据的表头和5行案例数据,帮我我们快速了解表格数据的大致内容和格式:
import pandas as pd
import os
HOUSING_PATH = os.path.join("datasets", "housing") # 存储位置
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 返回 包含所有数据的pandas DataFrame对象
housing = load_housing_data()
print(housing.head())
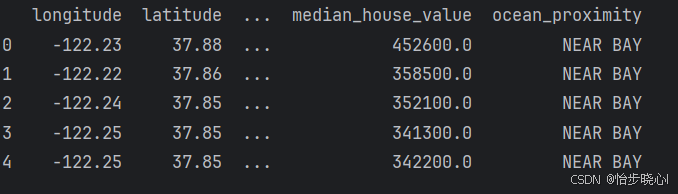
但是,由于表格数据比较大,部分数据不能全部打印出来,推荐直接打开csv的表格文件进行查看,更加方便直观一些。

2.2、总体查看数据大小、数据类型和空缺情况
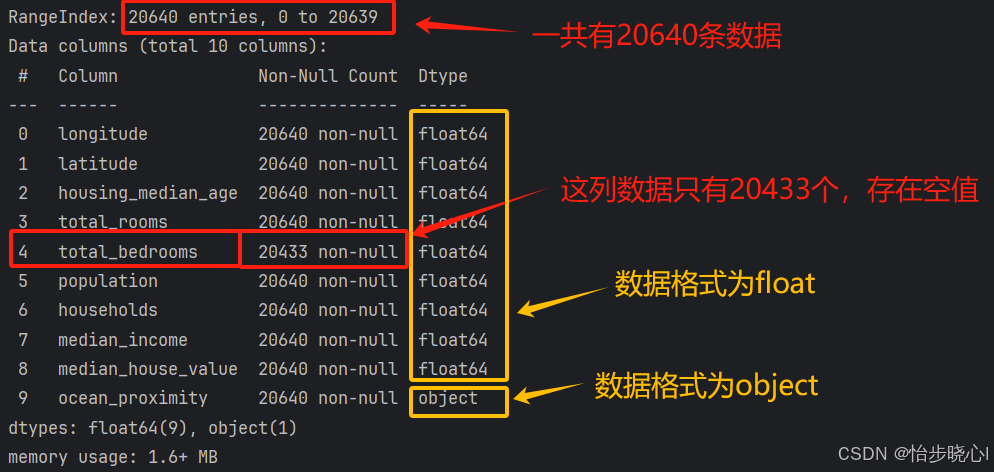
使用下面的代码可以直接打印出数据集的属性描述:
housing.info()#查看数据集属性描述,自动打印
2.3、查看数值属性列的均值、最小最大值等信息
使用下面的命令查看数据集每列的信息,此处直接打印会在输出窗口显示不完全,因此直接把数据输出为xlsx文件查看:
# 查看数值属性列的均值、最小最大值等信息-结果导出为housing_describe.xlsx
housing_describe = housing.describe()
housing_describe.to_excel('housing_describe.xlsx') # 保存到 Excel 文件
生成后的文件信息如下:

文件中各个行的数据解释如下:
- count:非空(非NA/null)值的数量
- mean:平均值,所有非空值的算术平均。
- std:标准差,衡量数据的离散程度
- min:最小值,数据中的最小值。 25%:第25百分位数,也称为下四分位数,表示数据中有25%的数据小于这个值
- 50%(median):中位数,数据排序后位于中间的数。如果数据量是奇数,则中位数就是中间那个数;如果是偶数,则中位数是中间两个数的平均值
- 75%:第75百分位数,也称为上四分位数,表示数据中有75%的数据小于这个
- max:最大值,数据中的最大值。
2.4、绘制每列数据的分布情况
数字形式的数据绘图
实际中,我们往往需要观察每个数据的实际分布的情况,使用下面代码绘制分布图:
import matplotlib.pyplot as plt
housing.hist(bins = 50, figsize = (20,15))#各属性各自的分布:即处于横轴区间(x轴)的样本个数为多少(y轴)
plt.savefig('distribution01.png', dpi=300)#保存图片为png
plt.show()
运行得到的结果如下所示,还是比较美观的:

文字形式的数据显示
我们之前可以分析到“ocean_proximity”这一列的数据为字符串格式,对于字符格式的数据我们可以使用下面代码观察其分布:
print(housing["ocean_proximity"].value_counts())#查看ocean_proximity栏中有多少种分类
运行结果为:

2.5、绘制多维数据关系
三个自变量对应一个因变量
多维度数据关系的绘制需要根据具体情况来具体分析,此处选择影响房价的三个因素为例进行。从之前的原始数据的观察,此处绘制数据的自变量包含经度、纬度、人口密度,绘制数据的因变量就是房价数据:
#房价分布, s-蓝色-人口数量,c-颜色-价格-(蓝-红)
housing.plot(kind = "scatter", x = "longitude", y = "latitude", alpha = 0.4,
s = housing["population"]/100, label = "population", figsize = (10,7),
c = "median_house_value", cmap = plt.get_cmap("jet"), colorbar = True,
)
plt.legend()
plt.savefig('distribution02.png', dpi=300)#保存图片为png
绘制得到的图表如下所示,其中横纵坐标分别为经纬度,图中圆圈大小代表人口的密度,图中的颜色深浅代表房价的具体数值,可以看到美国沿海地区人口密度大,房价更高:

2.6、绘制两两间互相关关系图
说白了就是以其中一个数据为横坐标,另一个数据为纵坐标绘图:
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing[attributes], figsize = (12,8))
plt.savefig('correlation.png', dpi=300)#保存图片为png
从下面的第一列的第二行的图片可以看到,房价数据和收入的绘图有一定的线性关系,其余的数据的关系并不显著:

2.7、绘制相关性系数热力图
上一小节2.6、绘制两两间互相关关系图的绘制不太直观,可以使用相关性系数的热力图对两两变量的相关性进行分析,代码如下:
# 计算相关性系数矩阵
correlation_matrix = housing[['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']].corr()
import seaborn as sns
# 设置 seaborn 样式
sns.set(style="white")
# 绘制相关性热力图
plt.figure(figsize=(8, 6)) # 设置图形大小
heatmap = sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.subplots_adjust(left=0.2, right=0.9, top=0.9, bottom=0.3)
# 添加标题和标签(可选)
plt.title('Correlation Heatmap')
# 显示图形
# plt.show()
# 保存图形为图片文件
plt.savefig('correlation_heatmap.png', dpi=300)
运行结果如下,可见收入和房价间的相关性确实比较大:

3、代码
3.1、01LoadDataSet.py
import os
import tarfile
from urllib import request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"#网址位置
HOUSING_PATH = os.path.join("datasets", "housing")#存储位置
def fetch_housing_data(housing_url = HOUSING_URL, housing_path = HOUSING_PATH):
os.makedirs(housing_path, exist_ok = True)
tgz_path = os.path.join(housing_path, "housing.tgz")
request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path = housing_path)#解压
housing_tgz.close()
fetch_housing_data()
3.2、02DataView.py
import pandas as pd
import os
HOUSING_PATH = os.path.join("datasets", "housing") # 存储位置
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 返回 包含所有数据的pandas DataFrame对象
housing = load_housing_data()
print(housing.head())
housing.info()#查看数据集属性描述
# 查看数值属性列的均值、最小最大值等信息-结果导出为housing_describe.xlsx
housing_describe = housing.describe()
housing_describe.to_excel('housing_describe.xlsx') # 保存到 Excel 文件
import matplotlib.pyplot as plt
housing.hist(bins = 50, figsize = (20,15))#各属性各自的分布:即处于横轴区间(x轴)的样本个数为多少(y轴)
plt.savefig('distribution01.png', dpi=300)#保存图片为png
# plt.show()
print(housing["ocean_proximity"].value_counts())#查看ocean_proximity栏中有多少种分类
#房价分布, s-蓝色-人口数量,c-颜色-价格-(蓝-红)
housing.plot(kind = "scatter", x = "longitude", y = "latitude", alpha = 0.4,
s = housing["population"]/100, label = "population", figsize = (10,7),
c = "median_house_value", cmap = plt.get_cmap("jet"), colorbar = True,
)
plt.legend()
plt.savefig('distribution02.png', dpi=300)#保存图片为png
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing[attributes], figsize = (12,8))
plt.savefig('correlation.png', dpi=300)#保存图片为png
# 计算相关性系数矩阵
correlation_matrix = housing[['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']].corr()
import seaborn as sns
# 设置 seaborn 样式
sns.set(style="white")
# 绘制相关性热力图
plt.figure(figsize=(8, 6)) # 设置图形大小
heatmap = sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.subplots_adjust(left=0.2, right=0.9, top=0.9, bottom=0.3)
# 添加标题和标签(可选)
plt.title('Correlation Heatmap')
# 显示图形
# plt.show()
# 保存图形为图片文件
plt.savefig('correlation_heatmap.png', dpi=300)