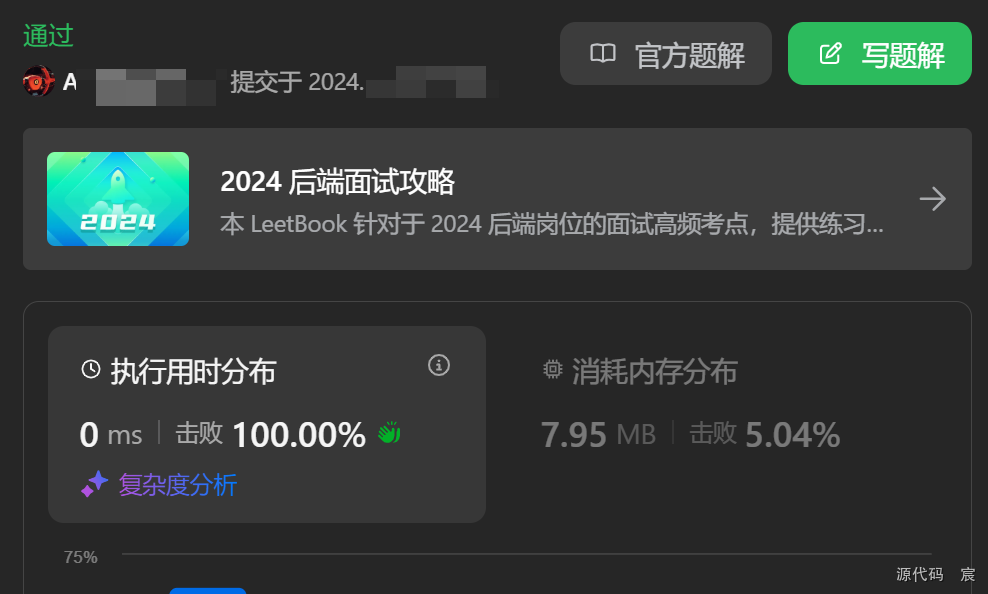
复习一下排序算法吧,数据结构有点难,虽然我已经看过一遍了,重温一遍还是很有收获!
本文会出一系列(主讲算法排序),欢迎订阅!!!
Python中常用的排序算法有以下几种:
-
冒泡排序(Bubble Sort):通过相邻元素的比较和交换来进行排序。时间复杂度为O(n^2)。
-
选择排序(Selection Sort):每次从待排序的元素中选择最小(或最大)的元素放到已排序的末尾。时间复杂度为O(n^2)。
-
插入排序(Insertion Sort):将待排序的元素逐步插入已排序的序列中,通过比较和交换来进行排序。时间复杂度为O(n^2)。
-
快速排序(Quick Sort):通过分治的思想将待排序的序列划分为左右两个子序列,再对子序列进行递归排序。时间复杂度为O(nlogn)。
-
归并排序(Merge Sort):将待排序的序列逐步划分为更小的子序列,再将子序列两两合并并排序。时间复杂度为O(nlogn)。
-
堆排序(Heap Sort):利用堆数据结构来进行排序,通过构建最大(或最小)堆,并逐步取出堆顶元素来排序。时间复杂度为O(nlogn)。
-
希尔排序(Shell Sort):将待排序的序列分组进行排序,然后逐步减小分组的间隔直到为1,最后再进行一次完整的插入排序。时间复杂度为O(nlogn)。
-
计数排序(Counting Sort):统计待排序序列中每个元素出现的次数,根据计数结果重新排序。时间复杂度为O(n+k),其中k为序列中的最大值。
-
桶排序(Bucket Sort):将待排序的元素根据某个映射函数分到不同的桶中,对每个桶中的元素进行排序,再依次取出桶中的元素。时间复杂度为O(n+k),其中k为桶的个数。
-
基数排序(Radix Sort):将待排序的元素按照位数从低到高依次进行排序,根据每个元素的该位数字进行桶排序,最后得到排序结果。时间复杂度为O(d*(n+k)),其中d为位数,k为桶的个数。
以上是Python中常见的排序算法,不同的排序算法适用于不同的场景,选择合适的排序算法可以提高排序效率。
目录
1.顺序查找(Linear Search)
Linear Search
for i,v in enumerate(li)
2.二分查找(必须是有序的)
3.排序的介绍
列表排序
常见的排序算法
LOW B三人组:
4.冒泡排序(Bubble sort)
Bubble sort(原地排序)
改进
5.选择排序
select_sort(时间复杂度O(n^2))
改进版:时间复杂度O(n^2)
6.插入排序(O(n^2))
NB三人组:
7.快速排序(O(nlogn))
8.堆排序(O(nlogn))
堆排序前传:二叉树的存储方式
堆排序前传堆和堆的向下调整
堆排序以及内置模块(heapq)
归并排序:
归并条件、定义、代码
归并排序:(O(nlogn))
总结:
1.顺序查找(Linear Search)
Linear Search
也称线性查找,也就是遍历,从列表首个元素开始,顺序进行搜索,直到找到元素或搜索到列表最后一个元素为止。
时间复杂度为O(n)
# 顺序查找
def Linear_search(li,value):
for i,v in enumerate(li):
if v == value:
return i
else:
return Nonefor i,v in enumerate(li)
Python 线性查找错误 - 豆包
2.二分查找(必须是有序的)
因为:存在循环减半的情况,所以复杂度是O(logn)
while left <= right: mid = (left + right) // # 二分查找
def erfen_reach(li, value):
left = 0
right = len(li) - 1
# mid = (left+right)//2
while left <= right:
mid = (left + right) // 2
if li[mid] == value:
return mid
elif value > li[mid]:
left = mid + 1
else:
right = mid - 1
else:
return None
li = [1, 2, 3, 4, 5, 6]
print(erfen_reach(li,3))3.排序的介绍
low B三人组的时间复杂度都是O(n^2),都是原地排序
列表排序
内置排序函数:sort()
常见的排序算法

LOW B三人组:
4.冒泡排序(Bubble sort)
Bubble sort(原地排序)
循环一次选出最大的数
升序:时间复杂度是O(n^2)
# 冒泡排序
import random
def Bubble_sort(li):
for i in range(len(li)-1): # i表示趟数
for j in range(len(li)-i-1): # j表示箭头
if li[j] > li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
li = [random.randint(0,1000)for i in range(1000)]
print(li)
Bubble_sort(li)
print(li)改进
如果我的无序区一趟下来没有发生交换说明我的列表已经是有序的了,所以可以进行改进:
设置一个标志位
# 冒泡排序
import random
def Bubble_sort(li):
for i in range(len(li)-1): # i表示趟数
exchange = False # 标示位
for j in range(len(li)-i-1): # j表示箭头
if li[j] > li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
exchange = True
print(li)
if not exchange:
return
# li = [random.randint(0,1000)for i in range(1000)]
li = [1,2,3,4,5,6,7]
# print(li)
Bubble_sort(li)
print(li)5.选择排序
select_sort(时间复杂度O(n^2))
需要另外开辟空间
# 选择列表
def select_sort(li):
new_li = []
for i in range(len(li)):
min_ele = min(li)
new_li.append(min_ele)
li.remove(min_ele)
return new_li
li = [5,4,7,9,6,3,21]
print(select_sort(li))改进版:时间复杂度O(n^2)
但是不需要另外开辟空间
算法关键点:有序区位置和无序区位置,记录无序区的最小值的位置
def select_sort(li):
for i in range(len(li)-1): # i表示趟数
min_xiaiao = i # 假定无序区第一个元素是最小值
for j in range(i+1,len(li)):
if li[min_xiaiao] > li[j]:
# 位置发生交换
min_xiaiao = j
# 值交换
li[i],li[min_xiaiao] = li[min_xiaiao],li[i]
li = [5,4,7,9,6,3,21]
select_sort(li)
print(li)6.插入排序(O(n^2))
类似于摸牌然后将其插入到手中的牌

# 插入排序
def insert_search(li):
for i in range(1,len(li)): # i 表示趟数,也表示未排序的数的下标
temp = li[i] # 用于存储将要排序的数
j = i-1 # 表示已排序好的数下标
while j >= 0 and li[j] > temp: # 找出能够插入的位置
li[j+1] = li[j] # 向右移动 空出位置放置li[i]
j -= 1 # 下标向前指 继续比较
li[j+1] = temp
li = [5,2,4,6,9,8,5]
insert_search(li)
print(li)NB三人组:
7.快速排序(O(nlogn))


思想:有一个数将列表分为左右两部分,使得左边的数都比这个数小,右边的数都比这个数大,递归思想继续循环“列表”。
# 快速排序
def quick_sort(li,left,right):
if left < right: # 说明至少有两个元素需要排列
mid = partition(li,left,right) # 返回的是中间值的下标
quick_sort(li,left,mid-1)
quick_sort(li,mid+1,right)
def partition(li,left,right):
temp = li[left] # 用于存储将列表划分为两部分的那个数
while left < right:
while left < right and li[right] >= temp: # 找出右边比temp小的值放在左边
right -= 1
li[left] = li[right]
while left < right and li[left] <= temp: # 找出左边比temp大的值放在右边
left += 1
li[right] = li[left]
li[left] = temp # 归位
return left
li = [5,2,3,6,8,9,4,2]
quick_sort(li,0,len(li)-1)
print(li)缺点:
1.递归
2.最坏情况:选择的是最大的数
8.堆排序(O(nlogn))

堆排序前传:二叉树的存储方式
链式存储
顺序存储

堆排序前传堆和堆的向下调整
堆:一种特殊的完全二叉树
大根堆:满足任一节点都比其孩子节点大
小根堆:满足任一节点都比其孩子节点小
堆的向下调整:
假设:节点的左右子树都是堆,但自身不是堆
当根节点的左右子树都是堆时,可以通过一次向下的调整来将其换成一个堆。
堆排序:

堆排序以及内置模块(heapq)
# 堆排序
def sift(li,low,high):
"""
:param li: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return:
"""
i = low # 开始指向根节点
j = low * 2 + 1 # j开始是左孩子
temp = li[low] # temp 把堆顶存储起来
while j <= high: # 保证不越界
if j+1 <= high and li[j+1] > li[j]: # 右孩子比左孩子大,还得保证有右孩子否则存在越界的情况
j = j+1 # j指向右孩子
if li[j] > temp:
li[i] = li[j]
i = j
j = 2*i+1
else:
li[i] = temp # 把temp放到某一个根节点上,但是没有考虑到循环到最后,放置到最后的位置上
break
else:
li[i] = temp # 把temp放到叶子结点上
def heap_sort(li):
n = len(li)
# 建堆 农村包围城市 从最后一个根节点开始构建堆 i表示根节点下标
# 最后一个非叶子节点下标是n-1 由父亲找孩子下标(n-1-1)//2
for i in range((n-2)//2,-1,-1):
sift(li,i,n-1)
# 建堆完成
print(li)
# 挨个出数
for i in range(n-1,-1,-1): # i指向当前堆的最后一个元素
li[0],li[i] = li[i],li[0]
sift(li,0,i-1) # i-1是新的high
li = [i for i in range(100)]
import random
random.shuffle(li) # 打乱
print(li)
heap_sort(li)
print(li)[55, 14, 76, 69, 61, 30, 7, 88, 2, 83, 60, 77, 40, 58, 87, 16, 78, 53, 62, 46, 94, 22, 79, 37, 59, 4, 96, 50, 92, 85, 80, 6, 25, 97, 68, 29, 32, 42, 66, 74, 86, 47, 99, 17, 52, 56, 67, 57, 8, 81, 45, 26, 38, 13, 0, 41, 10, 21, 35, 84, 98, 49, 31, 36, 70, 33, 15, 65, 43, 34, 91, 93, 48, 89, 9, 63, 75, 11, 28, 24, 73, 5, 12, 90, 95, 44, 39, 3, 51, 72, 23, 64, 27, 1, 54, 18, 19, 82, 71, 20]
[99, 97, 98, 93, 95, 96, 92, 91, 89, 94, 79, 82, 40, 76, 87, 70, 88, 55, 75, 86, 90, 72, 67, 77, 81, 38, 30, 50, 58, 85, 80, 36, 33, 78, 69, 53, 32, 63, 66, 74, 46, 83, 61, 51, 52, 64, 60, 57, 71, 59, 45, 26, 4, 13, 0, 41, 10, 21, 35, 84, 7, 49, 31, 16, 6, 25, 15, 65, 43, 34, 68, 29, 48, 2, 9, 62, 42, 11, 28, 24, 73, 5, 12, 14, 47, 44, 39, 3, 17, 22, 23, 56, 27, 1, 54, 18, 19, 8, 37, 20]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
# 堆排序的内置模块
import heapq # q优先队列(小的先出或者大的先出)
import random
li = list(range(100))
random.shuffle(li)
print(li)
heapq.heapify(li) # 创建堆
n = len(li)
# 默认是小根堆
for i in range(n):
print(heapq.heappop(li),end=',')[77, 36, 60, 69, 24, 49, 99, 35, 92, 53, 68, 15, 19, 43, 4, 45, 87, 89, 18, 10, 5, 30, 63, 54, 21, 16, 13, 3, 29, 88, 17, 76, 67, 64, 85, 52, 41, 84, 75, 62, 1, 28, 72, 11, 26, 25, 33, 9, 81, 6, 56, 74, 51, 97, 98, 20, 70, 22, 59, 94, 2, 32, 66, 55, 14, 58, 42, 34, 82, 23, 83, 39, 8, 31, 37, 47, 40, 96, 50, 0, 48, 57, 46, 71, 65, 38, 80, 78, 44, 79, 91, 93, 86, 90, 61, 95, 27, 73, 12, 7] 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99, 进程已结束,退出代码为 0
归并排序:
归并条件、定义、代码

# 归并:
def merge(li,low,mid,high):
i = low
j = mid + 1
heap = []
while i <= mid and j <= high:
if li[i] < li[j]:
heap.append(li[i])
i += 1
else:
heap.append(li[j])
j += 1
while i <= mid:
heap.append(li[i])
i += 1
while j <= high:
heap.append(li[j])
j += 1
li[low:high+1] = heap
li = [2,5,7,8,9,1,3,4,6,10]
merge(li,0,4,9)
print(li)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
归并排序:(O(nlogn))
空间复杂度是:O(n)
# 归并:
def merge(li,low,mid,high):
i = low
j = mid + 1
heap = []
while i <= mid and j <= high:
if li[i] < li[j]:
heap.append(li[i])
i += 1
else:
heap.append(li[j])
j += 1
while i <= mid:
heap.append(li[i])
i += 1
while j <= high:
heap.append(li[j])
j += 1
li[low:high+1] = heap
def merge_sort(li,low,high):
if low < high: # 至少有两个元素
mid = (low+high)//2
merge_sort(li,low,mid)
merge_sort(li,mid+1,high)
merge(li,low,mid,high)
li = list(range(100))
import random
random.shuffle(li)
print(li)
merge_sort(li,0,len(li)-1)
print(li)[72, 79, 74, 75, 93, 83, 2, 57, 56, 43, 20, 24, 19, 14, 89, 11, 3, 88, 34, 66, 58, 52, 68, 38, 47, 99, 15, 7, 31, 86, 10, 64, 40, 41, 12, 33, 18, 62, 54, 42, 70, 30, 1, 49, 51, 92, 53, 46, 87, 32, 6, 16, 73, 78, 59, 98, 26, 39, 44, 23, 22, 5, 69, 77, 85, 94, 80, 50, 9, 63, 45, 8, 91, 97, 29, 0, 4, 96, 48, 60, 36, 35, 67, 13, 65, 25, 81, 27, 55, 95, 21, 82, 28, 71, 17, 37, 76, 61, 90, 84] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
总结:
稳定性:挨个移动位置的都是稳定的,不挨个飞着换的都是不稳定的。