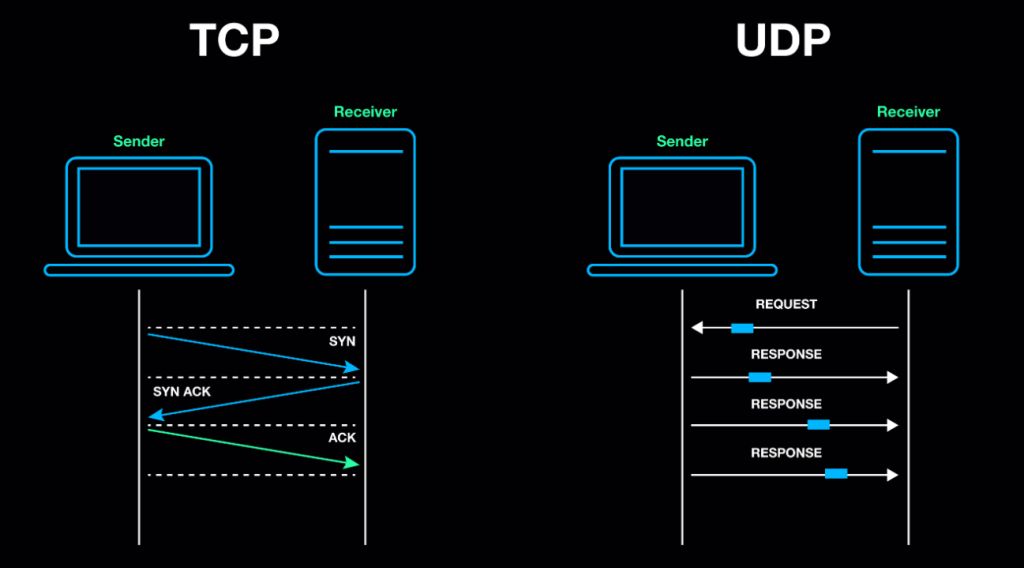
反向传播(Backpropagation)
- 引言
- 1. 分类交叉熵损失导数(Categorical Cross-Entropy loss derivative)
- 2. 分类交叉熵损失导数 - 代码实现
- 3. Softmax激活函数导数(Softmax activation derivative)
- 4. Softmax激活函数导数 - 代码实现
- 5. 常见的分类交叉熵损失和Softmax激活函数导数
- 6. 常见的分类交叉熵损失和Softmax激活函数导数 - 代码实现
引言
现在我们已经知道如何测量变量对函数输出的影响,我们可以开始编写代码来计算这些偏导数,以了解它们在最小化模型损失中的作用。在将这应用于完整的神经网络之前,让我们从一个简化的前向传递开始,只涉及一个神经元。我们不从完整神经网络的损失函数进行反向传播,而是从单个神经元的ReLU函数进行反向传播,就好像我们打算最小化这个单一神经元的输出一样。我们首先这样做只是为了简化解释,因为最小化ReLU激活神经元的输出除了作为一个练习外没有其他任何目的。最小化损失值是我们的最终目标,但在这种情况下,我们将首先展示如何利用链式法则以及导数和偏导数来计算每个变量对ReLU激活输出的影响。
我们还将从最小化这个更基本的输出开始,然后再跳转到完整网络和整体损失。
让我们快速回顾一下这个单一神经元及其ReLU激活所需执行的前向传递和原子操作。我们将使用一个具有3个输入的示例神经元,这意味着它也有3个权重和一个偏置:
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
然后我们从第一个输入 x[0] 和相关权重 w[0] 开始:

我们必须将输入乘以权重:
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
x0w0 = x[0] * w[0]
print(x0w0)
>>>
-3.0

我们对 x1、w1 和 x2、w2 对重复此操作:
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
print(x1w1, x2w2)
>>>
2.0 6.0

x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
print(x0w0, x1w1, x2w2, b)
>>>
-3.0 2.0 6.0
下一步要执行的操作是对所有带有偏差的加权输入进行求和:
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
print(x0w0, x1w1, x2w2, b)
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
print(z)
>>>
-3.0 2.0 6.0 1.0
6.0

这构成了神经元的输出。最后一步是在此输出上应用 ReLU 激活函数:
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
print(x0w0, x1w1, x2w2, b)
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
print(z)
# ReLU activation function
y = max(z, 0)
print(y)
>>>
-3.0 2.0 6.0 1.0
6.0
6.0

这是通过单个神经元和ReLU激活函数的完整前向传递。让我们将所有这些链式函数视为一个大函数,它接受输入值(x)、权重(w)和偏置(b)作为输入,并输出y。这个大函数由多个更简单的函数组成——有输入值和权重的乘法,这些值与偏置的求和,以及作为ReLU激活的max函数——总共3个链式函数:
第一步是通过计算相对于我们每个参数和输入的导数和偏导数来反向传播我们的梯度。为此,我们将使用链式法则。回顾一下,一个函数的链式法则规定了像 f ( g ( x ) ) f(g(x)) f(g(x))这样的嵌套函数的导数解为:

我们刚刚提到的这个大函数,在我们的神经网络的上下文中,可以被大致解释为:

或者以更精确匹配代码的形式:

我们当前的任务是计算每个输入、权重和偏置对输出的影响。我们将从考虑计算权重 w 0 w_0 w0的偏导数所需的内容开始。但首先,让我们重写我们的方程式,使其形式能够让我们更容易地确定如何计算导数:

上述方程包含3个嵌套函数:ReLU、加权输入与偏置的求和,以及输入与权重的乘法。要计算示例权重
w
0
w_0
w0对输出的影响,链式法则告诉我们需要计算ReLU相对于其参数(即求和)的导数,然后将其乘以求和操作相对于其
m
u
l
(
x
0
,
w
0
)
mul(x_0, w_0)
mul(x0,w0)输入的偏导数,因为该输入包含了相关的参数。然后,将其与乘法操作相对于
x
0
x_0
x0输入的偏导数相乘。让我们在一个简化的方程中看到这一点:

为了便于阅读,我们没有标注ReLU()的参数,即完整的求和,以及求和的参数,即所有输入和权重的乘法。我们排除了这些内容,因为方程将会更长、更难以阅读。这个方程表明我们必须计算所有原子操作的导数和偏导数,并将它们相乘,以获得
x
0
x_0
x0对输出的影响。然后我们可以重复这一过程,计算所有其他剩余的影响。关于权重和偏置的导数将告诉我们它们的影响,并将被用来更新这些权重和偏置。关于输入的导数被用来通过将它们传递给链中的前一个函数,以链接更多的层。
我们的神经网络模型将有多个链式的神经元层,后面跟着损失函数。我们想知道给定的权重或偏置对损失的影响。这意味着我们将不得不计算损失函数的导数(我们将在本章后面进行)并应用链式法则,以及所有连续层中所有激活函数和神经元的导数。与层的输入的导数相对,与权重和偏置的导数不用于更新任何参数。相反,它用于链接到另一层(这就是为什么我们要在链中向前一层反向传播)。
在反向传递过程中,我们将计算损失函数的导数,并使用它与输出层激活函数的导数相乘,然后使用这个结果与输出层的导数相乘,以此类推,通过所有隐藏层和激活函数。在这些层内,与权重和偏置相关的导数将形成我们用来更新权重和偏置的梯度。与输入相关的导数将形成与前一层链接的梯度。这一层可以计算其权重和偏置对损失的影响,并在输入上进一步反向传播梯度。
在这个例子中,假设我们的神经元从下一层接收到一个梯度为1的输入。我们为了演示目的编造了这个值,且1的值不会改变值,这意味着我们可以更容易地展示所有的过程。我们将使用红色来表示导数:

回想一下,如果ReLU()函数的输入大于0,其相对于输入的导数是1,否则是0:

我们可以用 Python 写成:
drelu_dsum = (1. if z > 0 else 0.)
这里的 drelu_dsum 表示 ReLU 函数相对于 z 的导数——我们使用 z 而不是方程中的 x,因为该方程表示的是一般的 max 函数,我们将其应用于神经元的输出,即 z(z <=> sum)。
这里
drelu_dsum就是: ∂ R e L U ( ) ∂ s u m ( ) \frac{\partial ReLU()}{\partial sum()} ∂sum()∂ReLU()

ReLU 函数的输入值是 6,因此导数等于 1。我们必须使用链式法则,并将这个导数与从下一层接收到的导数相乘,出于这个示例的目的,这个导数是 1:
# Forward pass
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print("y:", y)
drelu_dsum = (1. if z > 0 else 0.)
print("First drelu_dsum :", drelu_dsum)
# Backward pass
# The derivative from the next layer
dvalue = 1.0
# Derivative of ReLU and the chain rule
drelu_dsum = dvalue * drelu_dsum
print("Second drelu_dsum:", drelu_dsum)
>>>
y: 6.0
First drelu_dsum : 1.0
Second drelu_dsum: 1.0

结果是 1 的导数:

在我们神经网络中向后传播时,在执行激活函数之前,立即出现的函数是什么?
那就是加权输入和偏置的求和:sum(mul(x0,w0), mul(x1,w1), mul(x2,w2), b)。这意味着我们想要计算求和函数的偏导数,然后使用链式法则,将其乘以随后的外部函数的偏导数,即ReLU。我们将这些结果称为:
drelu_dx0w0—ReLU相对于第一个加权输入 w 0 x 0 w_0x_0 w0x0的偏导数,drelu_dx1w1—ReLU相对于第二个加权输入 w 1 x 1 w_1x_1 w1x1的偏导数,drelu_dx2w2—ReLU相对于第三个加权输入 w 2 x 2 w_2x_2 w2x2的偏导数,drelu_db—ReLU相对于偏置 b b b的偏导数。
这里我们把
mul(x0,w0),mul(x1,w1),mul(x2,w2),b分别看成"x","y","z","z+1"(这个只是一个随便的变量,只是假设。英文字母一共就26个,最后一位是z,没有第27个了,所以无奈写了z+1。但是我们要清楚,这只是化繁为简,为了更方便去)。
求和操作的偏导数总是1,无论输入如何:

在这个阶段,加权输入和偏置被求和。因此,我们将计算求和操作相对于每一个这些变量的偏导数,并乘以后续函数的偏导数(使用链式法则),后续函数是ReLU函数,表示为 drelu_dsum。
对于第一个偏导数:
dsum_dx0w0 = 1
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
为了清楚起见,上面的 dsum_dx0w0 指的是求和(sum())相对于第0对输入和权重的
x
x
x(输入)加权的偏导数。这个偏导数的值是1,我们使用链式法则将其与后续函数的导数相乘,后续函数是ReLU函数。
这里
dsum_dx0w0就是: ∂ s u m ( ) ∂ m u l ( x 0 , w 0 ) \frac{\partial sum()}{\partial mul(x_0,w_0)} ∂mul(x0,w0)∂sum()
再次,我们必须应用链式法则,并将ReLU函数的导数与相对于第一个加权输入的求和的偏导数相乘:
# Forward pass
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print("y:", y)
drelu_dsum = (1. if z > 0 else 0.)
print("First drelu_dsum :", drelu_dsum)
# Backward pass
# The derivative from the next layer
dvalue = 1.0
# Derivative of ReLU and the chain rule
drelu_dsum = dvalue * drelu_dsum
print("Second drelu_dsum:", drelu_dsum)
# Partial derivatives of the multiplication, the chain rule
dsum_dx0w0 = 1
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
print("drelu_dx0w0:", drelu_dx0w0)
>>>
y: 6.0
First drelu_dsum : 1.0
Second drelu_dsum: 1.0
drelu_dx0w0: 1.0

其结果再次是 1 的偏导数:

然后,我们可以对下一个权重输入执行相同的操作:
dsum_dx1w1 = 1
drelu_dx1w1 = drelu_dsum * dsum_dx1w1
print("drelu_dx1w1:", drelu_dx1w1)
>>>
drelu_dx1w1: 1.0

从而得出下一次计算的偏导数:

最后是加权输入:
dsum_dx2w2 = 1
drelu_dx2w2 = drelu_dsum * dsum_dx2w2
print("drelu_dx2w2:", drelu_dx2w2)
>>>
drelu_dx2w2: 1.0


然后是偏差:
dsum_db = 1
drelu_db = drelu_dsum * dsum_db
print("drelu_db:", drelu_db)
>>>
drelu_db: 1.0


让我们利用链式法则将这些偏导数添加到我们的代码中:
# Forward pass
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print("y:", y)
drelu_dsum = (1. if z > 0 else 0.)
print("First drelu_dsum :", drelu_dsum)
# Backward pass
# The derivative from the next layer
dvalue = 1.0
# Derivative of ReLU and the chain rule
drelu_dsum = dvalue * drelu_dsum
print("Second drelu_dsum:", drelu_dsum)
# Partial derivatives of the multiplication, the chain rule
dsum_dx0w0 = 1
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
print("drelu_dx0w0:", drelu_dx0w0)
dsum_dx1w1 = 1
drelu_dx1w1 = drelu_dsum * dsum_dx1w1
print("drelu_dx1w1:", drelu_dx1w1)
dsum_dx2w2 = 1
drelu_dx2w2 = drelu_dsum * dsum_dx2w2
print("drelu_dx2w2:", drelu_dx2w2)
dsum_db = 1
drelu_db = drelu_dsum * dsum_db
print("drelu_db:", drelu_db)
>>>
y: 6.0
First drelu_dsum : 1.0
Second drelu_dsum: 1.0
drelu_dx0w0: 1.0
drelu_dx1w1: 1.0
drelu_dx2w2: 1.0
drelu_db: 1.0
继续往回推,“和(sum)”之前的函数是权重与输入的乘积。乘积的导数是输入乘以的任何值。回想一下:

函数 f f f关于 x x x的偏导数等于 y y y,关于 y y y的偏导数等于 x x x。根据这个规则,第一个加权输入相对于输入的偏导数等于权重(这个函数的另一个输入)。然后,我们必须应用链式法则,并将这个偏导数与后续函数的偏导数相乘,后续函数是求和(我们在本章前面已经计算了它的偏导数):
dmul_dx0 = w[0]
drelu_dx0 = drelu_dx0w0 * dmul_dx0
print("drelu_dx0:", drelu_dx0)
>>>
drelu_dx0: -3.0
这意味着我们正在计算相对于输入
x
0
x_0
x0的偏导数,其值为
w
0
w_0
w0,并且我们正在应用链式法则与后续函数的导数,即drelu_dx0w0。
这里
dmul_dx0就是: ∂ m u l ( x 0 , w 0 ) ∂ x 0 \frac{\partial mul(x_0,w_0)}{\partial x_0} ∂x0∂mul(x0,w0)
现在是一个很好的时机来指出,当我们以这种方式应用链式法则时——通过取ReLU()的导数,取求和操作的导数,将两者相乘等等,这个过程称为使用链式法则的反向传播。正如其名字所示,结果输出函数的梯度被通过神经网络反向传递,使用后续函数的梯度与当前函数的梯度相乘。让我们将这个偏导数添加到代码中,并在图表上显示它:
# Forward pass
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print("y:", y)
drelu_dsum = (1. if z > 0 else 0.)
print("First drelu_dsum :", drelu_dsum)
# Backward pass
# The derivative from the next layer
dvalue = 1.0
# Derivative of ReLU and the chain rule
drelu_dsum = dvalue * drelu_dsum
print("Second drelu_dsum:", drelu_dsum)
# Partial derivatives of the multiplication, the chain rule
dsum_dx0w0 = 1
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
dsum_dx1w1 = 1
drelu_dx1w1 = drelu_dsum * dsum_dx1w1
dsum_dx2w2 = 1
drelu_dx2w2 = drelu_dsum * dsum_dx2w2
dsum_db = 1
drelu_db = drelu_dsum * dsum_db
print("drelu_dx0w0: %.1f, drelu_dx1w1: %.1f, drelu_dx2w2: %.1f, drelu_db: %.1f." % (drelu_dx0w0, drelu_dx1w1, drelu_dx2w2, drelu_db))
dmul_dx0 = w[0] # dmul_dx0 <=> dmul(x0w0)_dx0
drelu_dx0 = drelu_dx0w0 * dmul_dx0
print("drelu_dx0:", drelu_dx0)
>>>
y: 6.0
First drelu_dsum : 1.0
Second drelu_dsum: 1.0
drelu_dx0w0: 1.0, drelu_dx1w1: 1.0, drelu_dx2w2: 1.0, drelu_db: 1.0.
drelu_dx0: -3.0


我们对其他输入和权重执行相同的操作:
# Forward pass
x = [1.0, -2.0, 3.0] # input values
w = [-3.0, -1.0, 2.0] # weights
b = 1.0 # bias
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding weighted inputs and a bias
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print("y:", y)
drelu_dsum = (1. if z > 0 else 0.)
print("First drelu_dsum :", drelu_dsum)
# Backward pass
# The derivative from the next layer
dvalue = 1.0
# Derivative of ReLU and the chain rule
drelu_dsum = dvalue * drelu_dsum
print("Second drelu_dsum:", drelu_dsum)
# Partial derivatives of the multiplication, the chain rule
dsum_dx0w0 = 1
dsum_dx1w1 = 1
dsum_dx2w2 = 1
dsum_db = 1
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
drelu_dx1w1 = drelu_dsum * dsum_dx1w1
drelu_dx2w2 = drelu_dsum * dsum_dx2w2
drelu_db = drelu_dsum * dsum_db
print("drelu_dx0w0: %.1f, drelu_dx1w1: %.1f, drelu_dx2w2: %.1f, drelu_db: %.1f." % (drelu_dx0w0, drelu_dx1w1, drelu_dx2w2, drelu_db))
# Partial derivatives of the multiplication, the chain rule
dmul_dx0 = w[0]
dmul_dx1 = w[1]
dmul_dx2 = w[2]
dmul_dw0 = x[0]
dmul_dw1 = x[1]
dmul_dw2 = x[2]
drelu_dx0 = drelu_dx0w0 * dmul_dx0
drelu_dw0 = drelu_dx0w0 * dmul_dw0
drelu_dx1 = drelu_dx1w1 * dmul_dx1
drelu_dw1 = drelu_dx1w1 * dmul_dw1
drelu_dx2 = drelu_dx2w2 * dmul_dx2
drelu_dw2 = drelu_dx2w2 * dmul_dw2
print("drelu_dx0: %.1f, drelu_dw0: %.1f." % (drelu_dx0, drelu_dw0))
print("drelu_dx1: %.1f, drelu_dw1: %.1f." % (drelu_dx1, drelu_dw1))
print("drelu_dx2: %.1f, drelu_dw2: %.1f." % (drelu_dx2, drelu_dw2))
>>>
y: 6.0
First drelu_dsum : 1.0
Second drelu_dsum: 1.0
drelu_dx0w0: 1.0, drelu_dx1w1: 1.0, drelu_dx2w2: 1.0, drelu_db: 1.0.
drelu_dx0: -3.0, drelu_dw0: 1.0.
drelu_dx1: -1.0, drelu_dw1: -2.0.
drelu_dx2: 2.0, drelu_dw2: 3.0.

代码的可视化:https://nnfs.io/pro
这是激活神经元对输入、权重和偏差的偏导数的完整集合。
回想一下本章开头的等式:

既然我们已经有了完整的代码,并且正在从这个方程应用链式法则,让我们看看在这些计算中我们可以优化些什么。我们应用链式法则来计算ReLU激活函数相对于第一个输入
x
0
x_0
x0的偏导数。在我们的代码中,让我们提取相关的代码行并简化它们:
drelu_dx0 = drelu_dx0w0 * dmul_dx0
其中
dmul_dx0 = w[0]
然后
drelu_dx0 = drelu_dx0w0 * w[0]
其中
drelu_dx0w0 = drelu_dsum * dsum_dx0w0
然后
drelu_dx0 = drelu_dsum * dsum_dx0w0 * w[0]
其中
dsum_dx0w0 = 1
然后
drelu_dx0 = drelu_dsum * 1 * w[0] = drelu_dsum * w[0]
其中
drelu_dsum = dvalue * (1. if z > 0 else 0.)
然后
drelu_dx0 = dvalue * (1. if z > 0 else 0.) * w[0]


代码的可视化:https://nnfs.io/com
在这个方程中,从左边开始,是在下一层相对于其输入计算的导数——这是反向传播到当前层的梯度,即ReLU函数的导数,以及神经元函数相对于
x
0
x_0
x0输入的偏导数。这一切都通过应用链式法则来计算输入对整个函数输出的影响而相乘。
神经元函数的偏导数,相对于权重,是与该权重相关的输入;而相对于输入,则是相关的权重。神经元函数相对于偏置的偏导数始终是1。我们将它们与后续函数的导数(在这个例子中是1)相乘,以得到最终的导数。我们将在Dense层的类和ReLU激活类中编码所有这些导数,用于反向传播步骤。
综上所述,上述偏导数组合成一个向量,构成了我们的梯度。我们的梯度可以表示为:
dx = [drelu_dx0, drelu_dx1, drelu_dx2] # gradients on inputs
dw = [drelu_dw0, drelu_dw1, drelu_dw2] # gradients on weights
db = drelu_db # gradient on bias...just 1 bias here.
在这个单个神经元的例子中,我们也不需要我们的dx。在有多层的情况下,我们将继续用相对于我们输入的偏导数向前一层进行反向传播。
继续这个单个神经元的例子,我们现在可以将这些梯度应用到权重上,希望能最小化输出。这通常是优化器的目的(将在下一章讨论),但我们可以通过直接将梯度的负分数应用到我们的权重上来展示这个任务的简化版本。我们对这个梯度应用负分数是因为我们希望减少最终的输出值,而梯度显示了最陡峭的上升方向。例如,我们当前的权重和偏置是:
print(w, b)
>>>
[-3.0, -1.0, 2.0] 1.0
然后我们可以将一部分梯度应用到这些值上:
w[0] += -0.001 * dw[0]
w[1] += -0.001 * dw[1]
w[2] += -0.001 * dw[2]
b += -0.001 * db
print(w, b)
>>>
[-3.001, -0.998, 1.997] 0.999
现在,我们稍微改变了权重和偏差,以便在一定程度上智能地降低输出。我们可以通过另一次前向传递来查看调整对输出的影响:
# Multiplying inputs by weights
x0w0 = x[0] * w[0]
x1w1 = x[1] * w[1]
x2w2 = x[2] * w[2]
# Adding
z = x0w0 + x1w1 + x2w2 + b
# ReLU activation function
y = max(z, 0)
print(y)
>>>
5.985
我们已经成功将这个神经元的输出从6.000降低到了5.985。请注意,在真实的神经网络中减少神经元的输出是没有意义的;我们这样做纯粹是为了比完整网络更简单的练习。我们想要减少的是损失值,这是前向传递计算链中的最后一个计算,也是反向传播中第一个计算梯度的。我们只是为了这个示例的目的最小化了单个神经元的ReLU输出,以展示我们实际上是如何使用导数、偏导数和链式法则智能地减少链式函数的值的。现在,我们将把这个单神经元的例子应用到样本列表上,并将其扩展到整个神经元层。首先,让我们设置一个包含3个样本的输入列表,每个样本包含4个特征。在这个例子中,我们的网络将由一个单一的隐藏层组成,包含3个神经元(3组权重和3个偏置)。我们不会再次描述前向传递,但这种情况下的反向传递需要进一步的解释。
到目前为止,我们已经用一个单个神经元执行了一个示例反向传递,它接收到一个单一的导数以应用链式法则。让我们考虑下一层的多个神经元。当前层的一个神经元连接到它们所有人——它们都接收到这个神经元的输出。在反向传播过程中会发生什么?下一层的每个神经元将返回其函数相对于此输入的偏导数。当前层的神经元将接收一个由这些导数组成的向量。我们需要这个向量为一个单一的值。为了继续反向传播,我们需要将这个向量求和。
现在,让我们用一层神经元替换当前的单一神经元。与单一神经元不同,一层输出一个值向量而不是单一值。层中的每个神经元都连接到下一层的所有神经元。在反向传播期间,当前层的每个神经元将以我们为单个神经元描述的方式接收一个偏导数向量。对于一层神经元,它将采取这些向量的列表或2D数组的形式。我们知道我们需要进行求和,但我们应该求和什么,结果应该是什么?每个神经元将输出相对于其所有输入的偏导数的梯度,所有神经元将形成这些向量的列表。我们需要沿着输入求和——对所有神经元的第一个输入,第二个输入等进行求和。我们将不得不求和列。
为了计算相对于输入的偏导数,我们需要权重——相对于输入的偏导数等于相关的权重。这意味着相对于所有输入的偏导数数组等于权重数组。由于这个数组是转置的,我们将需要对其行而不是列进行求和。要应用链式法则,我们需要将它们乘以后续函数的梯度。
在代码中展示这一点,我们取转置的权重,这些权重是相对于输入的导数的转置数组,并将它们乘以各自的梯度(与给定神经元相关)来应用链式法则。然后我们沿着输入求和。然后我们为反向传播中的下一层计算梯度。反向传播中的“下一层”是模型创建顺序中的前一层:
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# a vector of 1s
dvalues = np.array([[1., 1., 1.]])
# We have 3 sets of weights - one set for each neuron
# we have 4 inputs, thus 4 weights
# recall that we keep weights transposed
weights = np.array([[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]).T
# sum weights of given input
# and multiply by the passed in gradient for this neuron
dx0 = sum(weights[0])*dvalues[0]
dx1 = sum(weights[1])*dvalues[0]
dx2 = sum(weights[2])*dvalues[0]
dx3 = sum(weights[3])*dvalues[0]
dinputs = np.array([dx0, dx1, dx2, dx3])
print(dinputs)
>>>
[[ 0.44 0.44 0.44]
[-0.38 -0.38 -0.38]
[-0.07 -0.07 -0.07]
[ 1.37 1.37 1.37]]
dinputs 是神经元函数相对于输入的梯度。
我们定义了后续函数的梯度(dvalues)为一个行向量,我们将很快解释这一点。从NumPy的角度来看,由于权重和dvalues都是NumPy数组,我们可以简化dx0到dx3的计算。由于权重数组的格式是这样的:每一行包含与每个输入相关的权重(给定输入的所有神经元的权重),我们可以直接将它们与梯度向量相乘:
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# a vector of 1s
dvalues = np.array([[1., 1., 1.]])
# We have 3 sets of weights - one set for each neuron
# we have 4 inputs, thus 4 weights
# recall that we keep weights transposed
weights = np.array([[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]).T
# sum weights of given input
# and multiply by the passed in gradient for this neuron
# sum weights of given input
# and multiply by the passed in gradient for this neuron
dx0 = sum(weights[0]*dvalues[0])
dx1 = sum(weights[1]*dvalues[0])
dx2 = sum(weights[2]*dvalues[0])
dx3 = sum(weights[3]*dvalues[0])
dinputs = np.array([dx0, dx1, dx2, dx3])
print(dinputs)
>>>
[ 0.44 -0.38 -0.07 1.37]
我们还需要考虑另一件事——一批样本。到目前为止,我们一直在使用单个样本,负责在层之间反向传播的单个梯度向量。我们为dvalues创建的行向量是为了准备一批数据。有了更多样本,层将返回一个梯度列表,我们几乎已经正确处理了。让我们将单一梯度dvalues[0]替换为完整的梯度列表dvalues,并向这个列表中添加更多示例梯度:
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# an array of an incremental gradient values
dvalues = np.array([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]])
# We have 3 sets of weights - one set for each neuron
# we have 4 inputs, thus 4 weights
# recall that we keep weights transposed
weights = np.array([[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]).T
# sum weights of given input
# and multiply by the passed in gradient for this neuron
dinputs = np.dot(dvalues, weights.T)
print(dinputs)
[[ 0.44 -0.38 -0.07 1.37]
[ 0.88 -0.76 -0.14 2.74]
[ 1.32 -1.14 -0.21 4.11]]
计算相对于权重的梯度在操作上非常类似,但在这种情况下,我们将使用梯度来更新权重,因此我们需要匹配权重的形状,而不是输入的形状。由于相对于权重的导数等于输入,权重被转置,所以我们需要转置输入以获得相对于权重的神经元的导数。然后我们将这些转置输入作为点积的第一个参数——点积将通过输入乘以行,其中每行(因为它被转置)包含所有样本的给定输入的数据,与dvalues的列相乘。这些列与所有样本的单个神经元的输出相关,所以结果将包含一个具有权重形状的数组,包含相对于输入的梯度,乘以批次中所有样本的传入梯度:
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# an array of an incremental gradient values
dvalues = np.array([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]])
# We have 3 sets of inputs - samples
inputs = np.array([[1, 2, 3, 2.5],
[2., 5., -1., 2],
[-1.5, 2.7, 3.3, -0.8]])
# sum weights of given input
# and multiply by the passed in gradient for this neuron
dweights = np.dot(inputs.T, dvalues)
print(dweights)
>>>
[[ 0.5 0.5 0.5]
[20.1 20.1 20.1]
[10.9 10.9 10.9]
[ 4.1 4.1 4.1]]
因为我们对每个权重的输入进行了求和,然后将它们乘以输入梯度,所以这个输出的形状与权重的形状相匹配。dweights 是神经元函数相对于权重的梯度。
对于偏置及其相关的导数,导数来自求和操作并且总是等于1,然后乘以传入的梯度以应用链式法则。由于梯度是梯度的列表(每个神经元对所有样本的梯度向量),我们只需沿着轴0列方向将它们与神经元求和。
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# an array of an incremental gradient values
dvalues = np.array([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]])
# One bias for each neuron
# biases are the row vector with a shape (1, neurons)
biases = np.array([[2, 3, 0.5]])
# dbiases - sum values, do this over samples (first axis), keepdims
# since this by default will produce a plain list -
# we explained this in the chapter 4
dbiases = np.sum(dvalues, axis=0, keepdims=True)
print(dbiases)
>>>
[[6. 6. 6.]]
keepdims 允许我们保持梯度作为行向量 —— 回想一下偏置数组的形状。
这里要讨论的最后一件事是ReLU函数的导数。如果输入大于0,则等于1;否则等于0。在前向传递过程中,层通过ReLU()激活函数传递其输出。对于反向传递,ReLU()接收一个相同形状的梯度。ReLU函数的导数将形成一个相同形状的数组,当相关输入大于0时填充1,否则填充0。要应用链式法则,我们需要将这个数组与后续函数的梯度相乘:
import numpy as np
# Example layer output
z = np.array([[1, 2, -3, -4],
[2, -7, -1, 3],
[-1, 2, 5, -1]])
dvalues = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# ReLU activation's derivative
drelu = np.zeros_like(z)
drelu[z > 0] = 1
print(drelu)
# The chain rule
drelu *= dvalues
print(drelu)
>>>
[[1 1 0 0]
[1 0 0 1]
[0 1 1 0]]
[[ 1 2 0 0]
[ 5 0 0 8]
[ 0 10 11 0]]
为了计算ReLU的导数,我们创建了一个填充有零的数组。np.zeros_like是一个NumPy函数,它根据其参数(在我们的例子中是神经元的一个示例输出z数组)的形状创建一个填充有零的数组。按照ReLU()的导数,然后我们将与大于0的输入相关的值设为1。接下来我们打印这个表格,以便查看并与梯度进行比较。最后,我们将这个数组与后续函数的梯度相乘,并打印结果。
我们现在可以简化这个操作。由于ReLU()导数数组填充有1,这些1不会改变与它们相乘的值,而0会使乘数值变为零,这意味着我们可以取后续函数的梯度,并将所有对应于ReLU()输入且小于等于0的值设为0:
import numpy as np
# Example layer output
z = np.array([[1, 2, -3, -4],
[2, -7, -1, 3],
[-1, 2, 5, -1]])
dvalues = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# ReLU activation's derivative
# with the chain rule applied
drelu = dvalues.copy()
drelu[z <= 0] = 0
print(drelu)
>>>
[[ 1 2 0 0]
[ 5 0 0 8]
[ 0 10 11 0]]
复制 dvalues 可以确保我们在计算 ReLU 导数时不会修改它。
让我们将单个神经元的前向和后向传递与全层和基于批处理的部分导数结合起来。我们将再次最小化 ReLU 的输出,仅适用于本示例:
import numpy as np
# Passed in gradient from the next layer
# for the purpose of this example we're going to use
# an array of an incremental gradient values
dvalues = np.array([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]])
# We have 3 sets of inputs - samples
inputs = np.array([[1, 2, 3, 2.5],
[2., 5., -1., 2],
[-1.5, 2.7, 3.3, -0.8]])
# We have 3 sets of weights - one set for each neuron
# we have 4 inputs, thus 4 weights
# recall that we keep weights transposed
weights = np.array([[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]).T
# One bias for each neuron
# biases are the row vector with a shape (1, neurons)
biases = np.array([[2, 3, 0.5]])
# Forward pass
layer_outputs = np.dot(inputs, weights) + biases # Dense layer
relu_outputs = np.maximum(0, layer_outputs) # ReLU activation
# Let's optimize and test backpropagation here
# ReLU activation - simulates derivative with respect to input values
# from next layer passed to current layer during backpropagation
drelu = relu_outputs.copy()
drelu[layer_outputs <= 0] = 0
# Dense layer
# dinputs - multiply by weights
dinputs = np.dot(drelu, weights.T)
# dweights - multiply by inputs
dweights = np.dot(inputs.T, drelu)
# dbiases - sum values, do this over samples (first axis), keepdims
# since this by default will produce a plain list -
# we explained this in the chapter 4
dbiases = np.sum(drelu, axis=0, keepdims=True)
# Update parameters
weights += -0.001 * dweights
biases += -0.001 * dbiases
print(weights)
print(biases)
>>>
[[ 0.179515 0.5003665 -0.262746 ]
[ 0.742093 -0.9152577 -0.2758402]
[-0.510153 0.2529017 0.1629592]
[ 0.971328 -0.5021842 0.8636583]]
[[1.98489 2.997739 0.497389]]
在这段代码中,我们用NumPy的变体替换了普通的Python函数,创建了示例数据,计算了前向传递和反向传递,并更新了参数。现在我们将使用一个反向方法(用于反向传播)更新密集层和ReLU激活代码,我们将在模型的反向传播阶段调用此方法。
import numpy as np
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
self.output = np.dot(inputs, self.weights) + self.biases
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
self.output = np.maximum(0, inputs)
在我们的Layer_Dense类的前向方法中,我们需要记住输入是什么(回想一下,我们在反向传播时计算相对于权重的偏导数时需要它们),这可以通过使用对象属性(self.inputs)轻松实现:
import numpy as np
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
self.inputs = inputs
self.output = np.dot(inputs, self.weights) + self.biases
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
self.output = np.maximum(0, inputs)
接下来,我们将把之前开发的反向传递(反向传播)代码添加到图层类中的一个新方法中,我们将其称为 backward:
import numpy as np
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
self.inputs = inputs
self.output = np.dot(inputs, self.weights) + self.biases
# Backward pass
def backward(self, dvalues):
# Gradients on parameters
self.dweights = np.dot(self.inputs.T, dvalues)
self.dbiases = np.sum(dvalues, axis=0, keepdims=True)
# Gradient on values
self.dinputs = np.dot(dvalues, self.weights.T)
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
self.output = np.maximum(0, inputs)
然后我们对 ReLU 类执行相同的操作:
import numpy as np
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
self.inputs = inputs
self.output = np.dot(inputs, self.weights) + self.biases
# Backward pass
def backward(self, dvalues):
# Gradients on parameters
self.dweights = np.dot(self.inputs.T, dvalues)
self.dbiases = np.sum(dvalues, axis=0, keepdims=True)
# Gradient on values
self.dinputs = np.dot(dvalues, self.weights.T)
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
# Remember input values
self.inputs = inputs
self.output = np.maximum(0, inputs)
# Backward pass
def backward(self, dvalues):
# Since we need to modify the original variable,
# let's make a copy of the values first
self.dinputs = dvalues.copy()
# Zero gradient where input values were negative
self.dinputs[self.inputs <= 0] = 0
到目前为止,我们已经涵盖了执行反向传播所需的所有内容,除了 Softmax 激活函数的导数和交叉熵损失函数的导数。
1. 分类交叉熵损失导数(Categorical Cross-Entropy loss derivative)
如果你对分类交叉熵损失的数学推导不感兴趣,可以直接跳到代码实现部分,因为常见的损失函数的导数是已知的,你不一定需要知道如何求解它们。不过,如果你计划创建自定义损失函数,这将是一个很好的练习。
正如我们在第5章中学到的,分类交叉熵损失函数的公式是:
其中 k 是 “真实 ”概率的指数

其中 L i L_i Li 表示样本损失值, i i i —— 表示数据集中的第 i i i 个样本, k k k —— 目标标签(真实标签)的索引, y y y —— 目标值, y ^ \hat{y} y^ —— 预测值。
这个公式在计算损失值本身时非常方便,因为我们所需要的只是在正确类别索引处的Softmax激活函数的输出。为了导数的计算,我们将使用第5章中提到的完整方程:

其中 L i L_i Li 表示样本损失值, i i i —— 表示数据集中的第 i i i 个样本, j j j —— 标签/输出索引, y y y —— 目标值, y ^ \hat{y} y^ —— 预测值。
我们将使用这个完整的函数,因为我们当前的目标是计算梯度,梯度由损失函数相对于每个输入(即Softmax激活函数的输出)的偏导数组成。这意味着我们不能使用只取正确类别索引处的值的方程(上面的第一个方程)。为了计算相对于每个输入的偏导数,我们需要一个将所有这些输入作为参数的方程,因此选择使用完整方程。
首先,让我们定义梯度方程:

我们在这里定义的方程是损失函数相对于每个输入的偏导数。我们已经学习了,求和的导数等于导数的求和。我们还学习了我们可以移动常数。例如 y i , j y_{i,j} yi,j,因为它不是我们正在计算导数的对象。让我们应用这些转换:

现在我们需要求解对数函数的导数,该导数是其参数的倒数,乘以(使用链式法则)该参数的偏导数——使用拉格朗日(也称为Lagrange)记法表示:

我们可以进一步求解(在这种情况下使用莱布尼兹符号):

让我们应用这个导数:

一个值相对于这个值的偏导数等于 1:

由于我们计算的是相对于给定 j j j 的 y y y 的偏导数,因此对单个元素的求和可以省略:

完整:

这个损失函数相对于其输入(第
i
i
i 个样本的预测值,因为我们关注的是相对于预测值的梯度)的导数等于负的真实值向量,除以预测值向量(这也是Softmax函数的输出向量)。
2. 分类交叉熵损失导数 - 代码实现
由于我们已经推导出这个方程,并且发现它解决了两个值的简单除法操作,我们知道,使用NumPy,我们可以将这个操作扩展到样本级的真实值和预测值向量,进一步扩展到批量数组。从编码的角度来看,我们需要向Loss_CategoricalCrossentropy类添加一个反向方法。我们需要将预测值数组和真实值数组传入其中,并计算它们的负除法:
# Common loss class
class Loss:
# Calculates the data and regularization losses
# given model output and ground truth values
def calculate(self, output, y):
# Calculate sample losses
sample_losses = self.forward(output, y)
# Calculate mean loss
data_loss = np.mean(sample_losses)
# Return loss
return data_loss
# Cross-entropy loss
class Loss_CategoricalCrossentropy(Loss):
# Forward pass
def forward(self, y_pred, y_true):
# Number of samples in a batch
samples = len(y_pred)
# Clip data to prevent division by 0
# Clip both sides to not drag mean towards any value
y_pred_clipped = np.clip(y_pred, 1e-7, 1 - 1e-7)
# Probabilities for target values -
# only if categorical labels
if len(y_true.shape) == 1:
correct_confidences = y_pred_clipped[range(samples), y_true]
# Mask values - only for one-hot encoded labels
elif len(y_true.shape) == 2:
correct_confidences = np.sum(y_pred_clipped * y_true, axis=1)
# Losses
negative_log_likelihoods = -np.log(correct_confidences)
return negative_log_likelihoods
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# Number of labels in every sample
# We'll use the first sample to count them
labels = len(dvalues[0])
# If labels are sparse, turn them into one-hot vector
if len(y_true.shape) == 1: # check whether they are one-dimensional
y_true = np.eye(labels)[y_true]
# Calculate gradient
self.dinputs = -y_true / dvalues
# Normalize gradient
self.dinputs = self.dinputs / samples
除了偏导数的计算,我们还进行了两个额外的操作。首先,我们将数值标签转换为独热编码(one-hot encoded)向量——在此之前,我们需要检查y_true由多少维组成。如果标签的形状返回单一维度(这意味着它们的形状像列表而不是数组),它们由离散数字组成并需要被转换为独热编码向量列表——一个二维数组。如果是这种情况,我们需要将它们转换为独热编码向量。我们将使用np.eye方法,给定一个数字n,返回一个nxn的数组,在对角线上填充1,在其他地方填充0。例如:
import numpy as np
np.eye(5)
>>>
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
然后,我们就可以用数字标签对该表进行索引,从而得到表示该标签的单击编码向量:
np.eye(5)[1]
>>>
array([0., 1., 0., 0., 0.])
np.eye(5)[4]
>>>
array([0., 0., 0., 0., 1.])
如果y_true已经是独热编码的,我们就不执行这个步骤。
第二个操作是梯度归一化。正如我们将在下一章中学习的那样,优化器会在通过学习率(或其他因素)乘以它们之前,对每个权重和偏置相关的所有梯度求和。在我们的情况下,这意味着数据集中样本越多,我们在这一步收到的梯度集合就越多,这个和就会变得越大。因此,我们将不得不根据每组样本调整学习率。为了解决这个问题,我们可以将所有的梯度除以样本数量。元素之和除以它们的数量就是它们的平均值(正如我们提到的,优化器将执行求和)——通过这种方式,我们将有效地归一化梯度,并使它们的和的大小不受样本数量的影响。
3. Softmax激活函数导数(Softmax activation derivative)
我们需要进行的下一个计算是Softmax函数的偏导数,这比分类交叉熵损失的导数更为复杂。让我们回顾一下Softmax激活函数的方程,并定义其导数:

其中
S
i
,
j
S_{i,j}
Si,j 表示第
i
i
i 个样本的第
j
j
j 个Softmax的输出,
z
z
z —— 输入数组,是一个输入向量列表(来自前一层的输出向量),
z
i
,
j
z_{i,j}
zi,j —— 第
i
i
i 个样本的第
j
j
j 个Softmax的输入,
L
L
L —— 输入数量,
z
i
,
k
z_{i,k}
zi,k —— 第
i
i
i 个样本的第
k
k
k 个Softmax的输入。
正如我们在第4章中描述的那样,Softmax函数等于指数化的输入除以所有指数化输入的总和。换句话说,我们需要先指数化所有的值,然后将每个值除以它们的总和来进行归一化。Softmax的每个输入都会影响每个输出,我们需要计算每个输出相对于每个输入的偏导数。从编程的角度来看,如果我们计算一个列表对另一个列表的影响,我们将得到一个值矩阵作为结果。这正是我们将要计算的 —— 我们将计算向量的雅可比矩阵(我们稍后将解释),我们将很快更深入地探讨这个问题。
要计算这个导数,我们首先需要定义除法操作的导数(背下来):

为了计算除法操作的导数,我们需要取分子乘以分母的导数,从中减去分子乘以分母导数的结果,然后将该结果除以分母的平方。
我们现在可以开始求解导数:

让我们应用除法运算的导数:

在这一步,方程中有两个偏导数。分子右侧(减法运算符右侧)的偏导数是:

我们需要计算常数 e e e(欧拉数)的幂 z i , l z_{i,l} zi,l(其中 l l l表示从1到Softmax输出数 L L L的连续索引)的和相对于 z i , k z_{i,k} zi,k的导数。求和操作的导数是导数的和,常数 e e e的幂 n n n( e n e^n en)相对于 n n n的导数等于 e n e^n en:

当指数函数的导数等于该指数函数本身时,这是一个特殊情况,因为其指数正是我们所求导的对象,因此其导数等于1。我们还知道范围 1... L 1...L 1...L 中包含 k k k( k k k 是该范围中的一个索引)恰好一次,在这种情况下,如果 j j j等于 k k k,导数将等于 e e e的 z i , k z_{i,k} zi,k次幂;否则(当 j j j不等于 k k k时, z i , l z_{i,l} zi,l不会包含 z i , k z_{i,k} zi,k,将被视为常数——常数的导数等于0)导数将等于0:

分母中减法算子左侧的导数情况略有不同:

它并不包含我们刚才解决的导数中所有元素的总和,因此如果 j ≠ k j \neq k j=k它可以变为0,或者如果 j = k j = k j=k,它可以变为 e e e的 z i , j z_{i,j} zi,j次幂。这意味着,从这一步开始,我们需要分别为这两种情况计算导数。让我们从 j = k j = k j=k的情况开始。
在 j = k j = k j=k的情况下,左边的导数将等于 e e e的 z i , j z_{i,j} zi,j次幂,而右边的导数在两种情况下解出的值相同。让我们进行替换:

在减法操作中,分子包含常数 e e e的 z i , j z_{i,j} zi,j次幂,这出现在被减数(我们要减去的值)和减数(从被减数中减去的值)中。因此,我们可以重组分子,使其包含这个值乘以它们当前乘数的差。我们也可以将分母写成值的乘积,而不是使用2的幂:

然后让我们将整个等式分成两部分:

我们将分子中的 e e e和分母中的和移到了它自己的分数中,分子中括号内的内容和分母中的另一个和作为另一个分数,两者通过乘法操作连接。现在我们可以进一步将“右边”的分数分成两个单独的分数:

在这种情况下,由于是减法操作,我们将分子中的两个值分开,将它们都除以分母,并在新的分数之间应用减法操作。如果我们仔细观察,左边的分数变成了Softmax函数的方程式,右边的分数也是,中间的分数因为分子和分母是相同的值而解为1:

请注意,“左 ”Softmax 函数带有 j j j 参数 ,而 “右 ”Softmax 函数带有 k k k 参数 ,这两个参数 分别来自它们的分子。
完整解决方案:

现在,我们必须回头求解 j ≠ k j≠k j=k 情况下的导数。在这种情况下,原方程的 “左 ”导数解为0,因为整个表达式被视为常数:

不同之处在于,现在整个减数都解为 0,分子中只剩下被减数:

现在,与之前完全一样,我们可以将分母写为值的乘积,而不是使用 2 的幂:

这样我们就可以使用乘法运算将该分数分成两个分数:

现在两个分数都代表 Softmax 函数:

请注意,左侧 Softmax 函数带有 j j j 参数,而“右侧”函数带有 k k k — 两者分别来自其分子。
完整解决方案:

总而言之,Softmax 函数关于其输入的导数的解是:

我们在这里的计算还没有结束。如果以这种形式保留,我们将有两个单独的方程式需要在代码中实现并在不同情况下使用,这对计算速度来说并不方便。然而,我们可以进一步变换导数的第二种情况的结果:

在第一步中,我们将第二个Softmax连同减号一起移入括号内,这样我们可以在这个值之前的括号内添加一个零。这不会改变解决方案,但现在:

两个解决方案看起来非常相似,它们只在单一值上有差异。方便地,存在克罗内克德尔塔函数(我们很快会解释),其方程是:

我们可以在这里应用它,进一步简化我们的方程式:

这是 Softmax 函数输出对其每个输入的导数的最终数学解。为了更容易使用 NumPy 在 Python 中实现,让我们最后一次转换方程:

我们基本上将 S i , j S_{i,j} Si,j 乘以括号中减法运算的两边。
4. Softmax激活函数导数 - 代码实现
这样我们就可以仅使用两个 NumPy 函数来编写解决方案,我们现在将逐步解释:
让我们制作一个样本:
softmax_output = [0.7, 0.1, 0.2]
并将其塑造成一个样本列表:
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
softmax_output = np.array(softmax_output).reshape(-1, 1)
print(softmax_output)
>>>
array([[0.7],
[0.1],
[0.2]])
方程的左边是Softmax输出乘以克罗内克德尔塔(Kronecker delta)函数。当两个输入相等时,克罗内克德尔塔函数等于1,否则为0。如果我们将其视为一个数组,我们将得到一个对角线上为1其余为0的数组 —— 你可能记得我们已经使用np.eye方法实现了这样的解决方案:
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
softmax_output = np.array(softmax_output).reshape(-1, 1)
print(np.eye(softmax_output.shape[0]))
>>>
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
现在我们将方程部分的两个值相乘:
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
softmax_output = np.array(softmax_output).reshape(-1, 1)
print(softmax_output * np.eye(softmax_output.shape[0]))
>>>
array([[0.7, 0. , 0. ],
[0. , 0.1, 0. ],
[0. , 0. , 0.2]])
事实证明,我们可以用 np.diagflat 方法调用替换它来提高速度,该方法计算相同的解决方案——diagflat 方法使用输入向量作为对角线创建一个数组:
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
print(np.diagflat(softmax_output))
>>>
array([[0.7, 0. , 0. ],
[0. , 0.1, 0. ],
[0. , 0. , 0.2]])
方程的另一部分是
S
i
,
j
S
i
,
k
S_{i,j}S_{i,k}
Si,jSi,k —— Softmax输出的乘积,分别迭代
j
j
j和
k
k
k索引。由于对于每个样本(
i
i
i索引),我们将不得不乘以Softmax函数输出的值(所有组合),我们可以使用点积操作。为此,我们只需要将第二个参数转置,以获得其行向量形式(如第2章所述):
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
# print(np.diagflat(softmax_output))
softmax_output = np.array(softmax_output).reshape(-1, 1)
# print(softmax_output * np.eye(softmax_output.shape[0]))
print(np.dot(softmax_output, softmax_output.T))
>>>
array([[0.49, 0.07, 0.14],
[0.07, 0.01, 0.02],
[0.14, 0.02, 0.04]])
最后,我们可以对两个数组进行减法运算(按照下列公式):
import numpy as np
softmax_output = [0.7, 0.1, 0.2]
print(np.diagflat(softmax_output))
softmax_output = np.array(softmax_output).reshape(-1, 1)
print(np.dot(softmax_output, softmax_output.T))
print(np.diagflat(softmax_output) - np.dot(softmax_output, softmax_output.T))
>>>
array([[ 0.21, -0.07, -0.14],
[-0.07, 0.09, -0.02],
[-0.14, -0.02, 0.16]])
方程的矩阵结果和代码提供的数组解决方案称为雅可比矩阵(Jacobian matrix)。在我们的情况下,雅可比矩阵是一个包含所有输入向量组合的偏导数的数组。请记住,我们正在计算Softmax函数的每个输出相对于每个输入的偏导数。我们这样做是因为由于归一化过程(取所有指数化输入的和),每个输入都会影响每个输出。在一批样本上执行此操作的结果是雅可比矩阵列表,有效地形成了一个3D矩阵 —— 你可以将其视为一个列,其级别是作为Softmax函数的按样本梯度的雅可比矩阵。
这就引出了一个问题 —— 如果按样本梯度是雅可比矩阵,我们如何用从损失函数反向传播的梯度进行链式法则,因为它对每个样本是一个向量?另外,我们如何处理前一层,即密集层,将期望梯度是一个2D数组的事实?目前,我们有一个偏导数的3D数组 —— 雅可比矩阵列表。Softmax函数相对于任何输入的导数返回一个偏导数向量(雅可比矩阵的一行),因为这个输入影响了所有输出,因此也影响了它们每一个的偏导数。我们需要将这些向量中的值求和,以便每个样本的每个输入都返回一个单独的偏导数值。因为每个输入都影响了所有输出,返回的偏导数向量必须求和以得到最终的相对于此输入的偏导数。我们可以直接在每个雅可比矩阵上执行此操作,同时应用链式法则(应用来自损失函数的梯度),使用np.dot() —— 对每个样本,它将从雅可比矩阵中取一行并将其与损失函数梯度的相应值相乘。结果,这些向量和值的点积将返回一个单一值,形成一个按样本的偏导数向量和一个按批次的2D数组(结果向量列表)。
# Softmax activation
class Activation_Softmax:
# Forward pass
def forward(self, inputs):
# Get unnormalized probabilities
exp_values = np.exp(inputs - np.max(inputs, axis=1,
keepdims=True))
# Normalize them for each sample
probabilities = exp_values / np.sum(exp_values, axis=1,
keepdims=True)
self.output = probabilities
# Backward pass
def backward(self, dvalues):
# Create uninitialized array
self.dinputs = np.empty_like(dvalues)
# Enumerate outputs and gradients
for index, (single_output, single_dvalues) in enumerate(zip(self.output, dvalues)):
# Flatten output array
single_output = single_output.reshape(-1, 1)
# Calculate Jacobian matrix of the output and
jacobian_matrix = np.diagflat(single_output) - np.dot(single_output, single_output.T)
# Calculate sample-wise gradient
# and add it to the array of sample gradients
self.dinputs[index] = np.dot(jacobian_matrix, single_dvalues)
首先,我们创建了一个空数组(这将成为最终的梯度数组),其形状与我们接收的用于应用链式法则的梯度相同。np.empty_like方法创建了一个空的未初始化数组。未初始化意味着我们可以预期它包含无意义的值,但无论如何我们很快就会设置所有这些值,因此没有初始化的必要(例如,使用np.zeros()来代替初始化为零)。在下一步中,我们将按样本迭代输出和梯度的配对,如前所述计算偏导数,并计算雅可比矩阵和梯度向量(从传入的梯度数组中)的最终乘积(应用链式法则),将结果向量存储为dinput数组中的一行。我们将在迭代时将每个向量存储在每一行中,形成输出数组。
5. 常见的分类交叉熵损失和Softmax激活函数导数
目前,我们已经计算了分类交叉熵损失和Softmax激活函数的偏导数,我们终于可以使用它们了,但仍有一个步骤可以执行以加快计算速度。不同的书籍和教程通常提到损失函数相对于Softmax输入的导数,甚至是输出层的权重和偏置的直接导数,而不详细讨论这些函数的偏导数。这部分原因是因为这两个函数的导数结合起来可以解决一个简单的方程 — 整个代码实现更简单,执行速度更快。当我们看看我们当前的代码时,我们执行了多个操作来计算梯度,甚至在激活函数的反向步骤中包含了一个循环。
让我们应用链规则来计算分类交叉熵损失函数相对于Softmax函数输入的偏导数。首先,让我们通过应用链规则来定义这个导数:

这个偏导数等于损失函数相对于其输入的偏导数,乘以(使用链规则)激活函数相对于其输入的偏导数。现在我们需要系统化语义 — 我们知道损失函数的输入, y ^ i , j \hat{y}_{i,j} y^i,j,是激活函数的输出, S i , j S_{i,j} Si,j。

这意味着我们可以将方程更新为以下形式:

现在我们可以代入分类交叉熵函数的偏导数方程,但是,由于我们正在计算相对于Softmax输入的偏导数,我们将使用包含对所有输出求和操作的那个方程 — 很快就会明白为什么。导数为:

代入综合导数方程后:

现在,就像我们之前计算的那样,先计算 Softmax 激活的偏导数,然后再计算 Kronecker delta:

让我们在这里也用 y ^ i , j \hat{y}_{i,j} y^i,j 来代替 S i , j S_{i,j} Si,j:

解决方案因 j = k j=k j=k 或 j ≠ k j≠k j=k 而异。为了处理这种情况,我们必须根据这些情况分割当前的偏导数 — 当它们匹配时和不匹配时:

对于 j ≠ k j≠k j=k 的情况,我们只需更新求和算子,将 k k k 排除在外,这就是唯一的变化:

对于 j = k j=k j=k 的情况,我们不需要求和运算符,因为它只会对索引 k k k 的一个元素求和。出于同样的原因,我们也用 k k k 替换 j j j 的索引:

回到主方程:

现在,我们可以用新定义的解来替代两种情况下激活函数的偏导数:

我们可以把等式中减法两边的y-hati,k 去掉–两边的乘法运算和分母中都含有 y ^ i , k \hat{y}_{i,k} y^i,k 。然后,在等式的 “右 ”边,我们可以用加号替换两个减号,并去掉括号:

现在,让我们把 − y i , k -y_{i,k} −yi,k 与等式 “左边 ”括号中的内容相乘:

现在让我们来看看求和运算——它将所有可能的 j j j 索引值(除了等于 k k k 时)的 y i , j y_{i,j} yi,j y ^ i , k \hat{y}_{i,k} y^i,k 相加。然后,在方程的这一部分的左边,我们有 y i , k y_{i,k} yi,k y ^ i , k \hat{y}_{i,k} y^i,k,它包含 y i , k y_{i,k} yi,k —— 正是从求和中排除的那个元素。我们可以将这两个表达式合并:

现在求和运算符遍历 j j j 的所有可能值,因为我们知道对于每个 i i i, y i , j y_{i,j} yi,j 是真实值的一维热编码向量,其所有元素的总和等于 1。换句话说,根据本章早先的解释——这个求和会将 0 与 y ^ i , k \hat{y}_{i,k} y^i,k 相乘,除了一个特殊情况,即真实标签,那里它会将 1 与这个值相乘。我们可以进一步简化为:

我们可以看到,当我们将链式法则应用于两个偏导数时,整个方程显著简化为预测值和真实值的差值。这样计算的速度也快了很多倍。
6. 常见的分类交叉熵损失和Softmax激活函数导数 - 代码实现
在编码这个解决方案时,前向传播没有变化——我们仍然需要在激活函数上执行它以得到输出,然后在损失函数上计算损失值。对于反向传播,我们将创建一个包含新方程实现的反向步骤,该方程计算损失和激活函数的组合梯度。我们将这个解决方案作为一个单独的类编码,该类初始化Softmax激活和分类交叉熵对象,在前向传播期间分别调用它们的前向方法。然后新的反向传播将包含新的代码:
# Softmax classifier - combined Softmax activation
# and cross-entropy loss for faster backward step
class Activation_Softmax_Loss_CategoricalCrossentropy():
# Creates activation and loss function objects
def __init__(self):
self.activation = Activation_Softmax()
self.loss = Loss_CategoricalCrossentropy()
# Forward pass
def forward(self, inputs, y_true):
# Output layer's activation function
self.activation.forward(inputs)
# Set the output
self.output = self.activation.output
# Calculate and return loss value
return self.loss.calculate(self.output, y_true)
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# If labels are one-hot encoded,
# turn them into discrete values
if len(y_true.shape) == 2:
y_true = np.argmax(y_true, axis=1)
# Copy so we can safely modify
self.dinputs = dvalues.copy()
# Calculate gradient
self.dinputs[range(samples), y_true] -= 1
# Normalize gradient
self.dinputs = self.dinputs / samples
为了实现解决方案
y
^
i
,
k
−
y
i
,
k
\hat{y}_{i,k} - y_{i,k}
y^i,k−yi,k,我们不是对完整数组进行减法运算,而是利用一个事实:代码中的
y
y
y 即 y_true 由一组独热编码向量组成,这意味着对于每个样本,这些向量中只有一个具体位置的值为1,其余位置填充为0。
这意味着我们可以使用 NumPy 通过样本编号和其真实值索引来索引预测数组,然后从这些值中减去1。这种操作需要离散的真实标签而不是独热编码的标签,因此需要额外的代码来执行转换(如果需要的话)——如果地面真实数组的维度等于2,这意味着它是由一组独热编码向量组成的矩阵。我们可以使用 np.argmax(),它返回最大值的索引(在这种情况下是1的索引),但我们需要逐样本地执行此操作以获得索引向量:
import numpy as np
y_true = np.array([[1,0,0],[0,0,1],[0,1,0]])
print(np.argmax(y_true))
print(np.argmax(y_true, axis=1))
>>>
0
[0 2 1]
最后一步,我们以与之前描述的类别交叉熵梯度归一化相同的方式和原因对梯度进行归一化。
让我们总结一下我们更新的每个类的代码:
import numpy as np
from timeit import timeit
import nnfs
nnfs.init()
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
self.inputs = inputs
self.output = np.dot(inputs, self.weights) + self.biases
# Backward pass
def backward(self, dvalues):
# Gradients on parameters
self.dweights = np.dot(self.inputs.T, dvalues)
self.dbiases = np.sum(dvalues, axis=0, keepdims=True)
# Gradient on values
self.dinputs = np.dot(dvalues, self.weights.T)
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
# Remember input values
self.inputs = inputs
self.output = np.maximum(0, inputs)
# Backward pass
def backward(self, dvalues):
# Since we need to modify the original variable,
# let's make a copy of the values first
self.dinputs = dvalues.copy()
# Zero gradient where input values were negative
self.dinputs[self.inputs <= 0] = 0
# Softmax activation
class Activation_Softmax:
# Forward pass
def forward(self, inputs):
# Get unnormalized probabilities
exp_values = np.exp(inputs - np.max(inputs, axis=1,
keepdims=True))
# Normalize them for each sample
probabilities = exp_values / np.sum(exp_values, axis=1,
keepdims=True)
self.output = probabilities
# Backward pass
def backward(self, dvalues):
# Create uninitialized array
self.dinputs = np.empty_like(dvalues)
# Enumerate outputs and gradients
for index, (single_output, single_dvalues) in enumerate(zip(self.output, dvalues)):
# Flatten output array
single_output = single_output.reshape(-1, 1)
# Calculate Jacobian matrix of the output and
jacobian_matrix = np.diagflat(single_output) - np.dot(single_output, single_output.T)
# Calculate sample-wise gradient
# and add it to the array of sample gradients
self.dinputs[index] = np.dot(jacobian_matrix, single_dvalues)
# Common loss class
class Loss:
# Calculates the data and regularization losses
# given model output and ground truth values
def calculate(self, output, y):
# Calculate sample losses
sample_losses = self.forward(output, y)
# Calculate mean loss
data_loss = np.mean(sample_losses)
# Return loss
return data_loss
# Cross-entropy loss
class Loss_CategoricalCrossentropy(Loss):
# Forward pass
def forward(self, y_pred, y_true):
# Number of samples in a batch
samples = len(y_pred)
# Clip data to prevent division by 0
# Clip both sides to not drag mean towards any value
y_pred_clipped = np.clip(y_pred, 1e-7, 1 - 1e-7)
# Probabilities for target values -
# only if categorical labels
if len(y_true.shape) == 1:
correct_confidences = y_pred_clipped[range(samples), y_true]
# Mask values - only for one-hot encoded labels
elif len(y_true.shape) == 2:
correct_confidences = np.sum(y_pred_clipped * y_true, axis=1)
# Losses
negative_log_likelihoods = -np.log(correct_confidences)
return negative_log_likelihoods
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# Number of labels in every sample
# We'll use the first sample to count them
labels = len(dvalues[0])
# If labels are sparse, turn them into one-hot vector
if len(y_true.shape) == 1: # check whether they are one-dimensional
y_true = np.eye(labels)[y_true]
# Calculate gradient
self.dinputs = -y_true / dvalues
# Normalize gradient
self.dinputs = self.dinputs / samples
# Softmax classifier - combined Softmax activation
# and cross-entropy loss for faster backward step
class Activation_Softmax_Loss_CategoricalCrossentropy():
# Creates activation and loss function objects
def __init__(self):
self.activation = Activation_Softmax()
self.loss = Loss_CategoricalCrossentropy()
# Forward pass
def forward(self, inputs, y_true):
# Output layer's activation function
self.activation.forward(inputs)
# Set the output
self.output = self.activation.output
# Calculate and return loss value
return self.loss.calculate(self.output, y_true)
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# If labels are one-hot encoded,
# turn them into discrete values
if len(y_true.shape) == 2:
y_true = np.argmax(y_true, axis=1)
# Copy so we can safely modify
self.dinputs = dvalues.copy()
# Calculate gradient
self.dinputs[range(samples), y_true] -= 1
# Normalize gradient
self.dinputs = self.dinputs / samples
我们现在可以测试,与我们分别通过两个函数反向传播梯度相比,合并的反向步骤是否返回相同的值。在这个例子中,让我们构造一个Softmax函数的输出和一些目标值。接下来,让我们使用两种解决方案来反向传播它们:
softmax_outputs = np.array([[0.7, 0.1, 0.2],
[0.1, 0.5, 0.4],
[0.02, 0.9, 0.08]])
class_targets = np.array([0, 1, 1])
softmax_loss = Activation_Softmax_Loss_CategoricalCrossentropy()
softmax_loss.backward(softmax_outputs, class_targets)
dvalues1 = softmax_loss.dinputs
activation = Activation_Softmax()
activation.output = softmax_outputs
loss = Loss_CategoricalCrossentropy()
loss.backward(softmax_outputs, class_targets)
activation.backward(loss.dinputs)
dvalues2 = activation.dinputs
print('Gradients: combined loss and activation:')
print(dvalues1)
print('Gradients: separate loss and activation:')
print(dvalues2)
>>>
Gradients: combined loss and activation:
[[-0.1 0.03333333 0.06666667]
[ 0.03333333 -0.16666667 0.13333333]
[ 0.00666667 -0.03333333 0.02666667]]
Gradients: separate loss and activation:
[[-0.09999999 0.03333334 0.06666667]
[ 0.03333334 -0.16666667 0.13333334]
[ 0.00666667 -0.03333333 0.02666667]]
结果是相同的。两个数组中值的微小差异来源于原生Python和NumPy中浮点数的精度。为了回答这个解决方案快了多少倍的问题,我们可以利用Python的timeit模块,多次运行这两个解决方案并合并执行时间。对于timeit模块以及此处使用的代码的完整描述超出了本书的范围,但我们纯粹包含这些代码是为了展示速度差异:
def f1():
softmax_loss = Activation_Softmax_Loss_CategoricalCrossentropy()
softmax_loss.backward(softmax_outputs, class_targets)
dvalues1 = softmax_loss.dinputs
def f2():
activation = Activation_Softmax()
activation.output = softmax_outputs
loss = Loss_CategoricalCrossentropy()
loss.backward(softmax_outputs, class_targets)
activation.backward(loss.dinputs)
dvalues2 = activation.dinputs
t1 = timeit(lambda: f1(), number=10000)
t2 = timeit(lambda: f2(), number=10000)
print(t2/t1)
>>>
3.804017990902363
单独计算梯度大约慢了4倍。这个因素可能因机器而异,但这明显表明,投入额外的努力来计算并编码合并损失和激活函数导数的优化解决方案是值得的。
让我们拿出模型的代码,并初始化新的组合精度和损失类对象:
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
而不是以前:
# Create Softmax activation (to be used with Dense layer):
activation2 = Activation_Softmax()
# Create loss function
loss_function = Loss_CategoricalCrossentropy()
然后在这些对象上替换前向传递调用:
# Perform a forward pass through activation function
# takes the output of second dense layer here
activation2.forward(dense2.output)
...
# Calculate sample losses from output of activation2 (softmax activation)
loss = loss_function.forward(activation2.output, y)
对新对象进行前向传递调用:
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
最后添加后退一步和打印梯度:
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Print gradients
print(dense1.dweights)
print(dense1.dbiases)
print(dense2.dweights)
print(dense2.dbiases)
完整代码:
import numpy as np
from timeit import timeit
import nnfs
from nnfs.datasets import spiral_data
nnfs.init()
# Dense layer
class Layer_Dense:
# Layer initialization
def __init__(self, inputs, neurons):
# Initialize weights and biases
self.weights = 0.01 * np.random.randn(inputs, neurons)
self.biases = np.zeros((1, neurons))
# Forward pass
def forward(self, inputs):
# Remember input values
self.inputs = inputs
# Calculate output values from inputs, weights and biases
self.output = np.dot(inputs, self.weights) + self.biases
# Backward pass
def backward(self, dvalues):
# Gradients on parameters
self.dweights = np.dot(self.inputs.T, dvalues)
self.dbiases = np.sum(dvalues, axis=0, keepdims=True)
# Gradient on values
self.dinputs = np.dot(dvalues, self.weights.T)
# ReLU activation
class Activation_ReLU:
# Forward pass
def forward(self, inputs):
# Remember input values
self.inputs = inputs
# Calculate output values from inputs
self.output = np.maximum(0, inputs)
# Backward pass
def backward(self, dvalues):
# Since we need to modify the original variable,
# let's make a copy of the values first
self.dinputs = dvalues.copy()
# Zero gradient where input values were negative
self.dinputs[self.inputs <= 0] = 0
# Softmax activation
class Activation_Softmax:
# Forward pass
def forward(self, inputs):
# Remember input values
self.inputs = inputs
# Get unnormalized probabilities
exp_values = np.exp(inputs - np.max(inputs, axis=1,
keepdims=True))
# Normalize them for each sample
probabilities = exp_values / np.sum(exp_values, axis=1,
keepdims=True)
self.output = probabilities
# Backward pass
def backward(self, dvalues):
# Create uninitialized array
self.dinputs = np.empty_like(dvalues)
# Enumerate outputs and gradients
for index, (single_output, single_dvalues) in enumerate(zip(self.output, dvalues)):
# Flatten output array
single_output = single_output.reshape(-1, 1)
# Calculate Jacobian matrix of the output and
jacobian_matrix = np.diagflat(single_output) - np.dot(single_output, single_output.T)
# Calculate sample-wise gradient
# and add it to the array of sample gradients
self.dinputs[index] = np.dot(jacobian_matrix, single_dvalues)
# Common loss class
class Loss:
# Calculates the data and regularization losses
# given model output and ground truth values
def calculate(self, output, y):
# Calculate sample losses
sample_losses = self.forward(output, y)
# Calculate mean loss
data_loss = np.mean(sample_losses)
# Return loss
return data_loss
# Cross-entropy loss
class Loss_CategoricalCrossentropy(Loss):
# Forward pass
def forward(self, y_pred, y_true):
# Number of samples in a batch
samples = len(y_pred)
# Clip data to prevent division by 0
# Clip both sides to not drag mean towards any value
y_pred_clipped = np.clip(y_pred, 1e-7, 1 - 1e-7)
# Probabilities for target values -
# only if categorical labels
if len(y_true.shape) == 1:
correct_confidences = y_pred_clipped[range(samples), y_true]
# Mask values - only for one-hot encoded labels
elif len(y_true.shape) == 2:
correct_confidences = np.sum(y_pred_clipped * y_true, axis=1)
# Losses
negative_log_likelihoods = -np.log(correct_confidences)
return negative_log_likelihoods
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# Number of labels in every sample
# We'll use the first sample to count them
labels = len(dvalues[0])
# If labels are sparse, turn them into one-hot vector
if len(y_true.shape) == 1: # check whether they are one-dimensional
y_true = np.eye(labels)[y_true]
# Calculate gradient
self.dinputs = -y_true / dvalues
# Normalize gradient
self.dinputs = self.dinputs / samples
# Softmax classifier - combined Softmax activation
# and cross-entropy loss for faster backward step
class Activation_Softmax_Loss_CategoricalCrossentropy():
# Creates activation and loss function objects
def __init__(self):
self.activation = Activation_Softmax()
self.loss = Loss_CategoricalCrossentropy()
# Forward pass
def forward(self, inputs, y_true):
# Output layer's activation function
self.activation.forward(inputs)
# Set the output
self.output = self.activation.output
# Calculate and return loss value
return self.loss.calculate(self.output, y_true)
# Backward pass
def backward(self, dvalues, y_true):
# Number of samples
samples = len(dvalues)
# If labels are one-hot encoded,
# turn them into discrete values
if len(y_true.shape) == 2:
y_true = np.argmax(y_true, axis=1)
# Copy so we can safely modify
self.dinputs = dvalues.copy()
# Calculate gradient
self.dinputs[range(samples), y_true] -= 1
# Normalize gradient
self.dinputs = self.dinputs / samples
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 3 output values
dense1 = Layer_Dense(2, 3)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 3 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(3, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Let's see output of the first few samples:
print(loss_activation.output[:5])
# Print loss value
print('loss:', loss)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
# Print accuracy
print('acc:', accuracy)
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Print gradients
print(dense1.dweights)
print(dense1.dbiases)
print(dense2.dweights)
print(dense2.dbiases)
>>>
[[0.33333334 0.33333334 0.33333334]
[0.3333332 0.3333332 0.33333364]
[0.3333329 0.33333293 0.3333342 ]
[0.3333326 0.33333263 0.33333477]
[0.33333233 0.3333324 0.33333528]]
loss: 1.0986104
acc: 0.34
[[ 1.5766357e-04 7.8368583e-05 4.7324400e-05]
[ 1.8161038e-04 1.1045573e-05 -3.3096312e-05]]
[[-3.60553473e-04 9.66117223e-05 -1.03671395e-04]]
[[ 5.44109462e-05 1.07411419e-04 -1.61822361e-04]
[-4.07913431e-05 -7.16780924e-05 1.12469446e-04]
[-5.30112993e-05 8.58172934e-05 -3.28059905e-05]]
[[-1.0729185e-05 -9.4610732e-06 2.0027859e-05]]
至此,多亏了梯度和使用链式法则的反向传播,我们能够调整权重和偏差,目的是降低损失,但我们的做法非常基础。这个过程,即使用梯度调整权重和偏差以减少损失,是优化器的工作,这将是下一章的主题。
本章的章节代码、更多资源和勘误表:https://nnfs.io/ch9