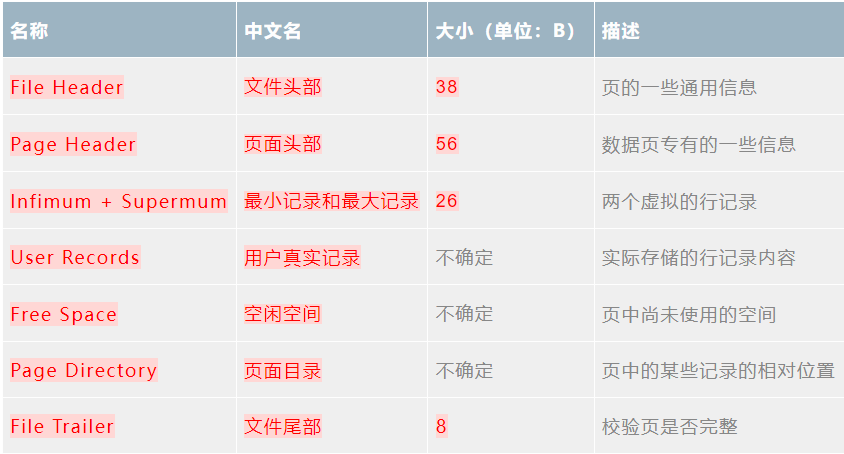
残差网络
1. 引言
在深度学习的快速发展中,模型的深度和复杂性不断增加。然而,随着网络层数的增加,训练过程中的一些问题逐渐显现出来,尤其是梯度消失和梯度爆炸问题。这些问题导致了深层神经网络的性能下降,限制了模型的表达能力。为了解决这一问题,Kaiming He 等人在 2015 年提出了残差网络(ResNet),该架构通过引入残差学习的概念,显著提高了深层神经网络的训练效果。
2. 残差网络的背景
2.1 深度学习的挑战
在传统的深层网络中,随着层数的增加,网络的训练变得更加困难。训练过程中,梯度在反向传播时可能会逐渐消失,导致前面的层无法有效更新。这种现象被称为梯度消失(vanishing gradient),使得深层网络难以学习到有效的特征。
2.2 残差学习的提出
残差网络的核心思想是通过引入跳跃连接(skip connections)来缓解深层网络中的梯度消失问题。具体来说,网络的每一层不仅学习输入 x x x 到输出 F ( x ) F(x) F(x) 的映射,还学习输入与输出之间的残差(即差异):
y = F ( x ) + x y = F(x) + x y=F(x)+x
其中:
- y y y 是残差块的输出。
- F ( x ) F(x) F(x) 是通过多个层(如卷积、激活函数等)计算得到的结果。
- x x x 是输入。
这种结构允许网络在需要时选择不更新某些层的权重,从而实现恒等映射。
2.3 残差网络的公式推导
考虑一个深度网络的输出为 y y y,如果我们希望网络学习到某个目标函数 H ( x ) H(x) H(x),则可以将其表示为:
H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
在这种情况下, F ( x ) F(x) F(x) 是需要学习的残差。通过这种方式,网络可以更容易地学习到恒等映射。假设 H ( x ) H(x) H(x) 是一个恒等映射(即 H ( x ) = x H(x) = x H(x)=x),那么我们可以选择 F ( x ) = 0 F(x) = 0 F(x)=0,这样网络可以直接将输入传递到输出。
3. 简单的计算例子
为了更好地理解残差连接的作用,考虑以下简单的计算例子:
假设我们有一个简单的输入矩阵 x x x:
x = [ 1 2 3 4 ] x = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} x=[1324]
我们希望网络学习到恒等映射。假设网络的结构如下:
- 第一层权重 W 1 = [ 0.5 0.5 0.5 0.5 ] W_1 = \begin{bmatrix} 0.5 & 0.5 \\ 0.5 & 0.5 \end{bmatrix} W1=[0.50.50.50.5],偏置 b 1 = [ 0.5 0.5 ] b_1 = \begin{bmatrix} 0.5 \\ 0.5 \end{bmatrix} b1=[0.50.5]。
- 第二层权重 W 2 = [ 0.5 0.5 0.5 0.5 ] W_2 = \begin{bmatrix} 0.5 & 0.5 \\ 0.5 & 0.5 \end{bmatrix} W2=[0.50.50.50.5],偏置 b 2 = [ − 0.5 − 0.5 ] b_2 = \begin{bmatrix} -0.5 \\ -0.5 \end{bmatrix} b2=[−0.5−0.5]。
计算过程:
-
输入 x x x 经过第一层:
F 1 ( x ) = W 1 ⋅ x + b 1 = [ 0.5 0.5 0.5 0.5 ] ⋅ [ 1 2 ] + [ 0.5 0.5 ] = [ 0.5 ⋅ 1 + 0.5 ⋅ 2 + 0.5 0.5 ⋅ 1 + 0.5 ⋅ 2 + 0.5 ] = [ 2.5 2.5 ] F_1(x) = W_1 \cdot x + b_1 = \begin{bmatrix} 0.5 & 0.5 \\ 0.5 & 0.5 \end{bmatrix} \cdot \begin{bmatrix} 1 \\ 2 \end{bmatrix} + \begin{bmatrix} 0.5 \\ 0.5 \end{bmatrix} = \begin{bmatrix} 0.5 \cdot 1 + 0.5 \cdot 2 + 0.5 \\ 0.5 \cdot 1 + 0.5 \cdot 2 + 0.5 \end{bmatrix} = \begin{bmatrix} 2.5 \\ 2.5 \end{bmatrix} F1(x)=W1⋅x+b1=[0.50.50.50.5]⋅[12]+[0.50.5]=[0.5⋅1+0.5⋅2+0.50.5⋅1+0.5⋅2+0.5]=[2.52.5] -
输入 F 1 ( x ) F_1(x) F1(x) 经过第二层:
F 2 ( F 1 ( x ) ) = W 2 ⋅ F 1 ( x ) + b 2 = [ 0.5 0.5 0.5 0.5 ] ⋅ [ 2.5 2.5 ] + [ − 0.5 − 0.5 ] = [ 0.5 ⋅ 2.5 + 0.5 ⋅ 2.5 − 0.5 0.5 ⋅ 2.5 + 0.5 ⋅ 2.5 − 0.5 ] = [ 2.5 − 0.5 2.5 − 0.5 ] = [ 2.0 2.0 ] F_2(F_1(x)) = W_2 \cdot F_1(x) + b_2 = \begin{bmatrix} 0.5 & 0.5 \\ 0.5 & 0.5 \end{bmatrix} \cdot \begin{bmatrix} 2.5 \\ 2.5 \end{bmatrix} + \begin{bmatrix} -0.5 \\ -0.5 \end{bmatrix} = \begin{bmatrix} 0.5 \cdot 2.5 + 0.5 \cdot 2.5 - 0.5 \\ 0.5 \cdot 2.5 + 0.5 \cdot 2.5 - 0.5 \end{bmatrix} = \begin{bmatrix} 2.5 - 0.5 \\ 2.5 - 0.5 \end{bmatrix} = \begin{bmatrix} 2.0 \\ 2.0 \end{bmatrix} F2(F1(x))=W2⋅F1(x)+b2=[0.50.50.50.5]⋅[2.52.5]+[−0.5−0.5]=[0.5⋅2.5+0.5⋅2.5−0.50.5⋅2.5+0.5⋅2.5−0.5]=[2.5−0.52.5−0.5]=[2.02.0] -
通过残差连接:
y = F 2 ( F 1 ( x ) ) + x = [ 2.0 2.0 ] + [ 1 2 ] = [ 3.0 4.0 ] y = F_2(F_1(x)) + x = \begin{bmatrix} 2.0 \\ 2.0 \end{bmatrix} + \begin{bmatrix} 1 \\ 2 \end{bmatrix} = \begin{bmatrix} 3.0 \\ 4.0 \end{bmatrix} y=F2(F1(x))+x=[2.02.0]+[12]=[3.04.0]
在这个例子中,网络通过学习残差使得输出更接近于输入。
4. 卷积自编码器与残差连接的实现
在实际应用中,残差连接不仅可以用于分类任务,还可以应用于自编码器等结构中。以下是一个卷积自编码器(ConvAutoencoder)和一个带有残差连接的卷积自编码器(ResidualConvAutoencoder)的实现代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
# 检查设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"Using device: {device}")
# 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 归一化
])
# 下载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
# 定义卷积自编码器(不带残差连接)
class ConvAutoencoder(nn.Module):
def __init__(self):
super(ConvAutoencoder, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.Conv2d(16, 4, kernel_size=3, stride=2, padding=1), # 4 x 7 x 7
nn.ReLU()
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(4, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1), # 1 x 28 x 28
nn.Sigmoid() # 使用 Sigmoid 确保输出在 [0, 1] 范围内
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 定义带残差连接的卷积自编码器
class ResidualConvAutoencoder(nn.Module):
def __init__(self):
super(ResidualConvAutoencoder, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.Conv2d(16, 4, kernel_size=3, stride=2, padding=1), # 4 x 7 x 7
nn.ReLU()
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(4, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1) # 1 x 28 x 28
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
# 添加跳跃连接
residual = x # 原始输入
decoded += residual # 将输入添加到解码器的输出
decoded = torch.sigmoid(decoded) # 使用 Sigmoid 确保输出在 [0, 1] 范围内
return decoded
# 训练和获取梯度的函数
def train_and_get_gradients(model, train_loader, criterion, optimizer, epochs=1):
model.train()
gradients = []
for epoch in range(epochs):
for images, _ in train_loader: # 不需要标签
images = images.to(device) # 移动到设备
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, images) # 自编码器的损失是重构损失
loss.backward()
# 收集梯度
grads = [param.grad.clone() for param in model.parameters() if param.grad is not None]
gradients.append(grads)
optimizer.step()
return gradients
# 初始化模型、损失函数和优化器
model_no_residual = ConvAutoencoder().to(device)
model_with_residual = ResidualConvAutoencoder().to(device)
criterion = nn.MSELoss() # 使用均方误差损失
optimizer_no_residual = optim.Adam(model_no_residual.parameters(), lr=0.001)
optimizer_with_residual = optim.Adam(model_with_residual.parameters(), lr=0.001)
# 训练并获取梯度
print("Training ConvAutoencoder without residual connections...")
gradients_no_residual = train_and_get_gradients(model_no_residual, train_loader, criterion, optimizer_no_residual,
epochs=1)
print("Training ResidualConvAutoencoder with residual connections...")
gradients_with_residual = train_and_get_gradients(model_with_residual, train_loader, criterion, optimizer_with_residual,
epochs=1)
# 计算并输出梯度的统计信息
def print_gradient_statistics(gradients, model_name):
first_layer_grad = gradients[0][0] # 获取第一个 batch 的第一个层的梯度
l2_norm = torch.norm(first_layer_grad).item()
min_grad = first_layer_grad.min().item()
max_grad = first_layer_grad.max().item()
mean_grad = first_layer_grad.mean().item()
print(f"\nGradient statistics for {model_name} (first layer):")
print(f"L2 Norm: {l2_norm:.4f}")
print(f"Min: {min_grad:.4f}")
print(f"Max: {max_grad:.4f}")
print(f"Mean: {mean_grad:.4f}")
print_gradient_statistics(gradients_no_residual, "ConvAutoencoder without residual connections")
print_gradient_statistics(gradients_with_residual, "ResidualConvAutoencoder with residual connections")
5. 结果分析
根据训练结果,我们得到了以下梯度统计信息:
-
不带残差连接的自编码器:
- L2 Norm: 0.0038
- Min: -0.0007
- Max: 0.0008
- Mean: 0.0000
-
带残差连接的自编码器:
- L2 Norm: 0.0083
- Min: -0.0014
- Max: 0.0017
- Mean: 0.0001
结果分析
-
梯度的大小:
- 带有残差连接的自编码器的 L2 范数(0.0083)大于不带残差连接的自编码器(0.0038)。这表明带残差连接的模型在训练过程中对参数的更新幅度更大。
-
梯度的分布:
- 带有残差连接的自编码器的梯度范围(从 -0.0014 到 0.0017)相对较宽,说明模型在学习过程中对参数的调整更加积极。
- 梯度的均值为 0.0001,表明在该层的权重更新上,正负梯度几乎相抵消,显示出模型在训练过程中的稳定性。
-
残差连接的影响:
- 残差连接的主要作用是提供一个直接的路径,使得梯度可以在网络中更有效地流动。尽管带有残差连接的自编码器的梯度较大,但这并不一定意味着学习效果更好。较大的梯度可能会导致不稳定的学习过程,特别是在深层网络中。
结论
残差网络通过引入跳跃连接,有效地缓解了深层网络中的梯度消失问题。通过在卷积自编码器中实现残差连接,我们能够观察到模型在训练过程中梯度的变化情况。虽然带有残差连接的模型在某些情况下梯度更大,但这并不一定意味着它的学习效果更好。实际应用中,仍需结合其他指标(如损失、准确率等)来全面评估模型的性能。