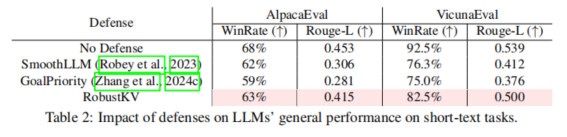
Temporal Fusion Transformer (TFT) 是一种专为时序数据建模而设计的深度学习模型,它结合了Transformer架构和其他技术,旨在有效地处理和预测时序数据中的复杂模式。TFT 于 2020 年由 Google Research 提出,旨在解决传统模型在时序预测中的一些局限性,尤其是在多变量时序数据的应用中。
1. 背景
随着机器学习和深度学习的发展,时序预测(如金融、天气预测、能源消耗等领域)成为了一个重要的研究方向。传统的时序预测方法,如 ARIMA、LSTM 等,虽然有较好的性能,但通常在处理复杂的、包含多种输入特征的时序数据时,表现不佳。Transformer 模型因其在自然语言处理领域的成功而被引入到时序数据建模中,但直接应用 Transformer 在时序数据上会遇到一些挑战,例如如何有效处理不同时间尺度的输入,如何充分利用历史信息等。
TFT 是在 Transformer 的基础上进行了改进,专门针对多变量时序数据的建模需求,提出了一些新技术,使其更适合进行长时间序列的预测,尤其是在金融、医疗和工业领域等应用场景中。
2. 关键特性
TFT 结合了多个创新的设计,使其在时序数据预测中非常强大:
1. 多层次的注意力机制
TFT 采用了 多头注意力机制,并结合了 时间注意力 和 特征选择,可以更好地捕捉到输入数据中不同时间步和不同特征之间的关系。它不仅关注序列中每个时间点的重要性,还能够动态选择哪些特征在某一时刻对预测任务更为关键。
2. 自适应加权编码器
与传统的 LSTM 或 GRU 模型不同,TFT 引入了 自适应加权编码器,通过为每个时间步分配不同的权重来处理输入的多重时间序列。这使得模型可以专注于不同时间点的关键特征,从而捕捉到时序数据的长期和短期依赖关系。
3. 条件可解释性
TFT 具有 可解释性,它通过可视化模型中不同特征的重要性,帮助研究人员理解模型如何做出预测。这对于诸如金融、医疗等需要理解模型决策过程的领域尤为重要。
4. 处理不同类型的输入数据
TFT 能够处理 多种类型的输入数据,包括:
- 已知时变特征(如历史的时间序列数据)。
- 已知静态特征(如类别标签、地理位置等静态信息)。
- 目标变量(即预测的标签)。
它通过不同的输入通道和网络架构将这些特征有效地整合,从而提高了预测的准确性。
5. 集成模型
TFT 模型不仅仅是单一的神经网络,它还结合了其他技术(如 门控机制 和 前馈神经网络)来增强其在复杂任务上的表现。
3. TFT 架构
TFT 的整体架构包括以下几个主要组件:
-
编码器-解码器结构:
- 编码器:接收历史时间序列数据,并通过多头注意力机制和 RNN 层来建模数据中的长期依赖关系。
- 解码器:根据编码器的输出和其他时序信息,生成未来时步的预测。
-
时间嵌入和特征嵌入:
- 时间嵌入:捕捉每个时间点的信息,包括日、月等周期性时间特征。
- 特征嵌入:为每个输入特征(如类别变量和连续变量)生成嵌入表示,以便模型能够理解不同特征的贡献。
-
门控机制:
- 用于动态选择哪些特征在某一时刻对预测任务最为重要。它通过学习一个权重来决定是否使用某个特定特征。
-
注意力机制:
- 时间注意力:帮助模型根据不同的时间步长和历史信息分配不同的权重。
- 特征选择:通过特征选择层来识别哪些特征对预测最有帮助。
4. 应用领域
TFT 在很多领域都有广泛的应用,尤其是需要处理时序数据并且具有多个特征的情况:
- 金融领域:用于股票市场预测、风险评估等。
- 能源领域:预测电力消耗、负荷预测等。
- 医疗健康:预测病人的健康状况、疾病发展等。
- 制造业和工业:设备故障预测、生产过程监控等。
5. TFT 的优势
- 强大的预测能力:能够处理复杂的、多维度的时序数据,适应长短期依赖。
- 高效的特征选择和时间建模:通过自适应权重和注意力机制,能够精确选择最相关的时间步和特征,提高预测的准确性。
- 可解释性:使得预测过程透明,易于理解和分析,尤其适用于需要理解决策过程的应用场景。
6. TFT 的挑战和未来发展
- 计算资源消耗大:尽管 TFT 模型非常强大,但它的计算资源需求较高,特别是在处理大规模数据时。
- 对长序列的处理能力:虽然 TFT 设计考虑了长序列的特性,但在非常长的序列数据(如数年或更长时间跨度的数据)下,性能仍然可能受到限制。
总体来说,TFT 结合了 Transformer 和传统时序建模技术的优点,是一个非常强大的时序预测模型,能够解决复杂、多维度的时序数据问题。